【BZOJ】1085: [SCOI2005]骑士精神(A*启发式搜索)
http://www.lydsy.com/JudgeOnline/problem.php?id=1085

囧啊囧,看了题解后写了个程序,但是样例总过不了T+T,调试了不下于1个小时,肉眼对拍看了根本看不出orz。原来y打成了x。。。。。。。。。。。。。。。。。。
这种错误赛场上犯就离滚粗不远了。
这题是用启发式搜索中的A*做,嗯。我蒟蒻当然不会A*,特地去了解了下。。2篇博文有介绍(初识A*算法)(深入A*算法)
估价函数f(i)=g(i)+h(i)。g是已知代价,h是估计代价。
本题因为只有一个空格,因此所有不与答案匹配的点,至少需要动1步才可能走到答案,那么,我们就能估价,有多少个位置上的点与答案的点不同,那么估价函数h(i)就为这些不同的点的数量。
(此处很多口胡,等自己强大了再来解释,,)
- #include <cstdio>
- #include <cstring>
- #include <string>
- #include <iostream>
- #include <cmath>
- #include <algorithm>
- using namespace std;
- #define rep(i, n) for(int i=0; i<(n); ++i)
- #define for1(i,a,n) for(int i=(a);i<=(n);++i)
- #define for2(i,a,n) for(int i=(a);i<(n);++i)
- #define for3(i,a,n) for(int i=(a);i>=(n);--i)
- #define for4(i,a,n) for(int i=(a);i>(n);--i)
- #define CC(i,a) memset(i,a,sizeof(i))
- #define max(a,b) ((a)>(b)?(a):(b))
- #define min(a,b) ((a)<(b)?(a):(b))
- #define read(a) a=getnum()
- #define print(a) printf("%d", a)
- inline int getnum() { int ret=0; char c; for(c=getchar(); c<'0' || c>'9'; c=getchar()); for(; c>='0' && c<='9'; c=getchar()) ret=ret*10+c-'0'; return ret; }
- inline void swap(int &a, int &b) { int c=b; b=a; a=c; }
- const int dx[8]={1,2,2,1,-1,-2,-2,-1}, dy[8]={2,1,-1,-2,-2,-1,1,2};
- int mb[6][6]=
- {
- {0,0,0,0,0,0},
- {0,1,1,1,1,1},
- {0,0,1,1,1,1},
- {0,0,0,2,1,1},
- {0,0,0,0,0,1},
- {0,0,0,0,0,0}
- };
- int s[6][6], ans, flag;
- inline bool check() {
- for1(i, 1, 5) for1(j, 1, 5) if(s[i][j]!=mb[i][j]) return false;
- return true;
- }
- inline bool f(const int &g) {
- int h=0;
- for1(i, 1, 5) for1(j, 1, 5) if(s[i][j]!=mb[i][j]) {
- ++h;
- if(h+g>ans) return false;
- }
- return true;
- }
- void dfs(const int &x, const int &y, const int &g) {
- if(g==ans) {
- if(check()) flag=1;
- return;
- }
- if(flag) return;
- rep(i, 8) {
- int fx=x+dx[i], fy=y+dy[i];
- if(fx<1 || fy<1 || fx>5 || fy>5) continue;
- swap(s[x][y], s[fx][fy]);
- if(f(g)) dfs(fx, fy, g+1);
- swap(s[x][y], s[fx][fy]);
- }
- }
- int main() {
- int t=getnum();
- char c;
- int x, y;
- while(t--) {
- for1(i, 1, 5) for1(j, 1, 5) { for(c=getchar(); c!='*' && (c<'0' || c>'9'); c=getchar()); if(c=='*') s[i][j]=2, x=i, y=j; else s[i][j]=c-'0'; }
- flag=0;
- for(ans=1; ans<=15; ++ans) {
- dfs(x, y, 0);
- if(flag) break;
- }
- if(flag) printf("%d\n", ans);
- else printf("-1\n");
- }
- return 0;
- }
在这里我引用那两篇文章吧,防止他们崩了。。
初识A*算法
写这篇文章的初衷是应一个网友的要求,当然我也发现现在有关人工智能的中文站点实在太少,我在这里抛砖引玉,希望大家都来热心的参与。
还是说正题,我先拿A*算法开刀,是因为A*在游戏中有它很典型的用法,是人工智能在游戏中的代表。
A*算法在人工智能中是一种典型的启发式搜索算法,为了说清楚A*算法,我看还是先说说何谓启发式算法。
一、何谓启发式搜索算法
在说它之前先提提状态空间搜索。状态空间搜索,如果按专业点的说法就是将问题求解过程表现为从初始状态到目标状态寻找这个路径的过程。通俗点说,就是在解一个问题时,找到一条解题的过程可以从求解的开始到问题的结果(好象并不通俗哦)。由于求解问题的过程中分枝有很多,主要是求解过程中求解条件的不确定性,不完备性造成的,使得求解的路径很多这就构成了一个图,我们说这个图就是状态空间。问题的求解实际上就是在这个图中找到一条路径可以从开始到结果。这个寻找的过程就是状态空间搜索。
常用的状态空间搜索有深度优先和广度优先。广度优先是从初始状态一层一层向下找,直到找到目标为止。深度优先是按照一定的顺序前查找完一个分支,再查找另一个分支,以至找到目标为止。这两种算法在数据结构书中都有描述,可以参看这些书得到更详细的解释。
前面说的广度和深度优先搜索有一个很大的缺陷就是他们都是在一个给定的状态空间中穷举。这在状态空间不大的情况下是很合适的算法,可是当状态空间十分大,且不预测的情况下就不可取了。他的效率实在太低,甚至不可完成。在这里就要用到启发式搜索了。
启发式搜索就是在状态空间中的搜索对每一个搜索的位置进行评估,得到最好的位置,再从这个位置进行搜索直到目标。这样可以省略大量无畏的搜索路径,提到了效率。在启发式搜索中,对位置的估价是十分重要的。采用了不同的估价可以有不同的效果。我们先看看估价是如何表示的。
启发中的估价是用估价函数表示的,如:
f(n) = g(n) + h(n)
其中f(n)是节点n的估价函数,g(n)实在状态空间中从初始节点到n节点的实际代价,h(n)是从n到目标节点最佳路径的估计代价。在这里主要是h(n)体现了搜索的启发信息,因为g(n)是已知的。如果说详细点,g(n)代表了搜索的广度的优先趋势。但是当h(n)>>g(n)时,可以省略g(n),而提高效率。这些就深了,不懂也不影响啦!我们继续看看何谓A*算法。
二、初识A*算法
启发式搜索其实有很多的算法,比如:局部择优搜索法、最好优先搜索法等等。当然A*也是。这些算法都使用了启发函数,但在具体的选取最佳搜索节点时的策略不同。象局部择优搜索法,就是在搜索的过程中选取“最佳节点”后舍弃其他的兄弟节点,父亲节点,而一直得搜索下去。这种搜索的结果很明显,由于舍弃了其他的节点,可能也把最好的节点都舍弃了,因为求解的最佳节点只是在该阶段的最佳并不一定是全局的最佳。最好优先就聪明多了,他在搜索时,便没有舍弃节点(除非该节点是死节点),在每一步的估价中都把当前的节点和以前的节点的估价值比较得到一个“最佳的节点”。这样可以有效的防止“最佳节点”的丢失。那么A*算法又是一种什么样的算法呢?其实A*算法也是一种最好优先的算法。只不过要加上一些约束条件罢了。由于在一些问题求解时,我们希望能够求解出状态空间搜索的最短路径,也就是用最快的方法求解问题,A*就是干这种事情的!我们先下个定义,如果一个估价函数可以找出最短的路径,我们称之为可采纳性。A*算法是一个可采纳的最好优先算法。A*算法的估价函数可表示为:
f'(n) = g'(n) + h'(n)
这里,f'(n)是估价函数,g'(n)是起点到终点的最短路径值,h'(n)是n到目标的最断路经的启发值。由于这个f'(n)其实是无法预先知道的,所以我们用前面的估价函数f(n)做近似。g(n)代替g'(n),但g(n)>=g'(n)才可(大多数情况下都是满足的,可以不用考虑),h(n)代替h'(n),但h(n)<=h'(n)才可(这一点特别的重要)。可以证明应用这样的估价函数是可以找到最短路径的,也就是可采纳的。我们说应用这种估价函数的最好优先算法就是A*算法。哈!你懂了吗?肯定没懂!接着看!
举一个例子,其实广度优先算法就是A*算法的特例。其中g(n)是节点所在的层数,h(n)=0,这种h(n)肯定小于h'(n),所以由前述可知广度优先算法是一种可采纳的。实际也是。当然它是一种最臭的A*算法。
再说一个问题,就是有关h(n)启发函数的信息性。h(n)的信息性通俗点说其实就是在估计一个节点的值时的约束条件,如果信息越多或约束条件越多则排除的节点就越多,估价函数越好或说这个算法越好。这就是为什么广度优先算法的那么臭的原因了,谁叫它的h(n)=0,一点启发信息都没有。但在游戏开发中由于实时性的问题,h(n)的信息越多,它的计算量就越大,耗费的时间就越多。就应该适当的减小h(n)的信息,即减小约束条件。但算法的准确性就差了,这里就有一个平衡的问题。可难了,这就看你的了!
好了我的话也说得差不多了,我想你肯定是一头的雾水了,其实这是写给懂A*算法的同志看的。哈哈!你还是找一本人工智能的书仔细看看吧!我这几百字是不足以将A*算法讲清楚的。只是起到抛砖引玉的作用,希望大家热情参与嘛!
预知A*算法的应用,请看姊妹篇《深入A*算法》。
深入A*算法
深入A*算法
一、前言
在这里我将对A*算法的实际应用进行一定的探讨,并且举一个有关A*算法在最短路径搜索的例子。值得注意的是这里并不对A*的基本的概念作介绍,如果你还对A*算法不清楚的话,请看姊妹篇《初识A*算法》。
这里所举的例子是参考AMIT主页中的一个源程序,使用这个源程序时,应该遵守一定的公约。
二、A*算法的程序编写原理
我在《初识A*算法》中说过,A*算法是最好优先算法的一种。只是有一些约束条件而已。我们先来看看最好优先算法是如何编写的吧。
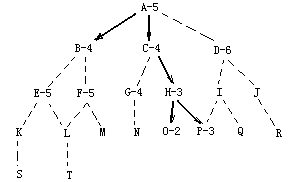
如图有如下的状态空间:(起始位置是A,目标位置是P,字母后的数字表示节点的估价值)
搜索过程中设置两个表:OPEN和CLOSED。OPEN表保存了所有已生成而未考察的节点,CLOSED表中记录已访问过的节点。算法中有一步是根据估价函数重排OPEN表。这样循环中的每一步只考虑OPEN表中状态最好的节点。具体搜索过程如下:
1)初始状态:
OPEN=[A5];CLOSED=[];
2)估算A5,取得搜有子节点,并放入OPEN表中;
OPEN=[B4,C4,D6];CLOSED=[A5]
3)估算B4,取得搜有子节点,并放入OPEN表中;
OPEN=[C4,E5,F5,D6];CLOSED=[B4,A5]
4)估算C4;取得搜有子节点,并放入OPEN表中;
OPEN=[H3,G4,E5,F5,D6];CLOSED=[C4,B4,A5]
5)估算H3,取得搜有子节点,并放入OPEN表中;
OPEN=[O2,P3,G4,E5,F5,D6];CLOSED=[H3,C4,B4,A5]
6)估算O2,取得搜有子节点,并放入OPEN表中;
OPEN=[P3,G4,E5,F5,D6];CLOSED=[O2,H3,C4,B4,A5]
7)估算P3,已得到解;看了具体的过程,再看看伪程序吧。算法的伪程序如下:
Best_First_Search()
{
Open = [起始节点];
Closed = [];
while (Open表非空)
{
从Open中取得一个节点X,并从OPEN表中删除。
if (X是目标节点)
{
求得路径PATH;
返回路径PATH;
}
for (每一个X的子节点Y)
{
if (Y不在OPEN表和CLOSE表中)
{
求Y的估价值;
并将Y插入OPEN表中;
}
//还没有排序
else if (Y在OPEN表中)
{
if (Y的估价值小于OPEN表的估价值)
更新OPEN表中的估价值;
}
else //Y在CLOSE表中
{
if (Y的估价值小于CLOSE表的估价值)
{
更新CLOSE表中的估价值;
从CLOSE表中移出节点,并放入OPEN表中;
}
}
将X节点插入CLOSE表中;
按照估价值将OPEN表中的节点排序;
}//end for
}//end while
}//end func啊!伪程序出来了,写一个源程序应该不是问题了,依葫芦画瓢就可以。A*算法的程
序与此是一样的,只要注意估价函数中的g(n)的h(n)约束条件就可以了。不清楚的可以看看《初识A*算法》。好了,我们可以进入另一个重要的话题,用
A*算法实现最短路径的搜索。在此之前你最好认真的理解前面的算法。不清楚可以找我。我的Email在文章尾。三、用A*算法实现最短路径的搜索
在游戏设计中,经常要涉及到最短路径的搜索,现在一个比较好的方法就是用A*算法进行设计。他的好处我们就不用管了,反正就是好!^_*
注意下面所说的都是以ClassAstar这个程序为蓝本,你可以在这里下载这个程序。这个程序是一个完整的工程。里面带了一个EXE文件。可以先看看。
先复习一下,A*算法的核心是估价函数f(n),它包括g(n)和h(n)两部
分。g(n)是已经走过的代价,h(n)是n到目标的估计代价。在这个例子中g(n)表示在状态空间从起始节点到n节点的深度,h(n)表示n节点所在地
图的位置到目标位置的直线距离。啊!一个是状态空间,一个是实际的地图,不要搞错了。再详细点说,有一个物体A,在地图上的坐标是(xa,ya),A所要
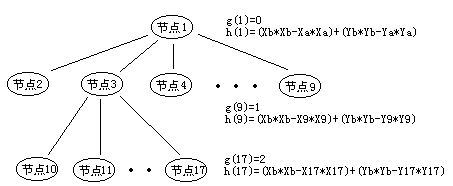
到达的目标b的坐标是(xb,yb)。则开始搜索时,设置一个起始节点1,生成八个子节点2-
9 因为有八个方向。如图:
仔细看看节点1、9、17的g(n)和h(n)是怎么计算的。现在应该知道了下面
程序中的f(n)是如何计算的吧。开始讲解源程序了。其实这个程序是一个很典型的教科书似的程序,也就是说只要你看懂了上面的伪程序,这个程序是十分容易
理解的。不过他和上面的伪程序有一些的不同,我在后面会提出来。先看搜索主函数:
- void AstarPathfinder::FindPath(int sx, int sy, int dx, int dy)
- {
- NODE *Node, *BestNode;
- int TileNumDest;
- //得到目标位置,作判断用
- TileNumDest = TileNum(sx, sy);
- //生成Open和Closed表
- OPEN = ( NODE* )calloc(1,sizeof( NODE ));
- CLOSED=( NODE* )calloc(1,sizeof( NODE ));
- //生成起始节点,并放入Open表中
- Node=( NODE* )calloc(1,sizeof( NODE ));
- Node->g = 0;
- //这是计算h值
- // should really use sqrt().
- Node->h = (dx-sx)*(dx-sx) + (dy-sy)*(dy-sy);
- //这是计算f值,即估价值
- Node->f = Node->g+Node->h;
- Node->NodeNum = TileNum(dx, dy);
- Node->x = dx; Node->y = dy;
- // make Open List point to first node
- OPEN->NextNode=Node;
- for (;;)
- {
- //从Open表中取得一个估价值最好的节点
- BestNode=ReturnBestNode();
- //如果该节点是目标节点就退出
- // if we've found the end, break and finish break;
- if (BestNode->NodeNum == TileNumDest)
- //否则生成子节点
- GenerateSuccessors(BestNode,sx,sy);
- }
- PATH = BestNode;
- }
再看看生成子节点函数:
- void AstarPathfinder::GenerateSuccessors(NODE *BestNode, int dx, int dy)
- {
- int x, y;
- //哦!依次生成八个方向的子节点,简单!
- // Upper-Left
- if ( FreeTile(x=BestNode->x-TILESIZE, y=BestNode->y-TILESIZE) )
- GenerateSucc(BestNode,x,y,dx,dy);
- // Upper
- if ( FreeTile(x=BestNode->x, y=BestNode->y-TILESIZE) )
- GenerateSucc(BestNode,x,y,dx,dy);
- // Upper-Right
- if ( FreeTile(x=BestNode->x+TILESIZE, y=BestNode->y-TILESIZE) )
- GenerateSucc(BestNode,x,y,dx,dy);
- // Right
- if ( FreeTile(x=BestNode->x+TILESIZE, y=BestNode->y) )
- GenerateSucc(BestNode,x,y,dx,dy);
- // Lower-Right
- if ( FreeTile(x=BestNode->x+TILESIZE, y=BestNode->y+TILESIZE) )
- GenerateSucc(BestNode,x,y,dx,dy);
- // Lower
- if ( FreeTile(x=BestNode->x, y=BestNode->y+TILESIZE) )
- GenerateSucc(BestNode,x,y,dx,dy);
- // Lower-Left
- if ( FreeTile(x=BestNode->x-TILESIZE, y=BestNode->y+TILESIZE) )
- GenerateSucc(BestNode,x,y,dx,dy);
- // Left
- if ( FreeTile(x=BestNode->x-TILESIZE, y=BestNode->y) )
- GenerateSucc(BestNode,x,y,dx,dy);
- }
看看最重要的函数:
- void AstarPathfinder::GenerateSucc(NODE *BestNode,int x, int y, int dx, int dy)
- {
- int g, TileNumS, c = 0;
- NODE *Old, *Successor;
- //计算子节点的 g 值
- // g(Successor)=g(BestNode)+cost of getting from BestNode to Successor
- g = BestNode->g+1;
- // identification purposes
- TileNumS = TileNum(x,y);
- //子节点再Open表中吗?
- // if equal to NULL then not in OPEN list, else it returns the Node in Old
- if ( (Old=CheckOPEN(TileNumS)) != NULL )
- {
- //若在
- for( c = 0; c < 8; c++)
- // Add Old to the list of BestNode's Children (or Successors).
- if( BestNode->Child[c] == NULL )
- break;
- BestNode->Child[c] = Old;
- //比较Open表中的估价值和当前的估价值(只要比较g值就可以了)
- // if our new g value is < Old's then reset Old's parent to point to BestNode
- if ( g < Old->g )
- {
- //当前的估价值小就更新Open表中的估价值
- Old->Parent = BestNode;
- Old->g = g;
- Old->f = g + Old->h;
- }
- }
- else
- //在Closed表中吗?
- // if equal to NULL then not in OPEN list, else it returns the Node in Old
- if ( (Old=CheckCLOSED(TileNumS)) != NULL )
- {
- //若在
- for( c = 0; c< 8; c++)
- // Add Old to the list of BestNode's Children (or Successors).
- if ( BestNode->Child[c] == NULL )
- break;
- BestNode->Child[c] = Old;
- //比较Closed表中的估价值和当前的估价值(只要比较g值就可以了)
- // if our new g value is < Old's then reset Old's parent to point to BestNode
- if ( g < Old->g )
- {
- //当前的估价值小就更新Closed表中的估价值
- Old->Parent = BestNode;
- Old->g = g;
- Old->f = g + Old->h;
- //再依次更新Old的所有子节点的估价值
- // Since we changed the g value of Old, we need
- // to propagate this new value downwards, i.e.
- // do a Depth-First traversal of the tree!
- PropagateDown(Old);
- }
- }
- //不在Open表中也不在Close表中
- else
- {
- //生成新的节点
- Successor = ( NODE* )calloc(1,sizeof( NODE ));
- Successor->Parent = BestNode;
- Successor->g = g;
- // should do sqrt(), but since we don't really
- Successor->h = (x-dx)*(x-dx) + (y-dy)*(y-dy);
- // care about the distance but just which branch looks
- Successor->f = g+Successor->h;
- // better this should suffice. Anyayz it's faster.
- Successor->x = x;
- Successor->y = y;
- Successor->NodeNum = TileNumS;
- //再插入Open表中,同时排序。
- // Insert Successor on OPEN list wrt f
- Insert(Successor);
- for( c =0; c < 8; c++)
- // Add Old to the list of BestNode's Children (or Successors).
- if ( BestNode->Child[c] == NULL )
- break;
- BestNode->Child[c] = Successor;
- }
- }
哈哈!A*算法我懂了!当然,我希望你有这样的感觉!不过我还要再说几句。仔细看 看这个程序,你会发现,这个程序和我前面说的伪程序有一些不同,在GenerateSucc函数中,当子节点在Closed表中时,没有将子节点从 Closed表中删除并放入Open表中。而是直接的重新的计算该节点的所有子节点的估价值(用PropagateDown函数)。这样可以快一些!另当 子节点在Open表和Closed表中时,重新的计算估价值后,没有重新的对Open表中的节点排序,我有些想不通,为什么不排呢?:-(,会不会是一个 小小的BUG。你知道告诉我好吗?
好了!主要的内容都讲完了,还是完整仔细的看看源程序吧!希望我所的对你有一点帮助,一点点也可以。如果你对文章中的观点有异议或有更好的解释都告诉我。我的email在文章最后!
Description
在 一个5×5的棋盘上有12个白色的骑士和12个黑色的骑士, 且有一个空位。在任何时候一个骑士都能按照骑士的走法(它可以走到和它横坐标相差为1,纵坐标相差为2或者横坐标相差为2,纵坐标相差为1的格子)移动到 空位上。 给定一个初始的棋盘,怎样才能经过移动变成如下目标棋盘: 为了体现出骑士精神,他们必须以最少的步数完成任务。

Input
第一行有一个正整数T(T<=10),表示一共有N组数据。接下来有T个5×5的矩阵,0表示白色骑士,1表示黑色骑士,*表示空位。两组数据之间没有空行。
Output
对于每组数据都输出一行。如果能在15步以内(包括15步)到达目标状态,则输出步数,否则输出-1。
Sample Input
10110
01*11
10111
01001
00000
01011
110*1
01110
01010
00100
Sample Output
-1
HINT
Source
【BZOJ】1085: [SCOI2005]骑士精神(A*启发式搜索)的更多相关文章
- Bzoj 1085: [SCOI2005]骑士精神 (dfs)
Bzoj 1085: [SCOI2005]骑士精神 题目链接:https://www.lydsy.com/JudgeOnline/problem.php?id=1085 dfs + 剪枝. 剪枝方法: ...
- BZOJ 1085 [SCOI2005]骑士精神 【A*启发式搜索】
1085: [SCOI2005]骑士精神 Time Limit: 10 Sec Memory Limit: 162 MB Submit: 2838 Solved: 1663 [Submit][St ...
- BZOJ 1085: [SCOI2005]骑士精神( IDDFS + A* )
一开始写了个 BFS 然后就 T 了... 这道题是迭代加深搜索 + A* -------------------------------------------------------------- ...
- [BZOJ 1085] [SCOI2005] 骑士精神 [ IDA* 搜索 ]
题目链接 : BZOJ 1085 题目分析 : 本题中可能的状态会有 (2^24) * 25 种状态,需要使用优秀的搜索方式和一些优化技巧. 我使用的是 IDA* 搜索,从小到大枚举步数,每次 DFS ...
- bzoj 1085: [SCOI2005]骑士精神
Description 在一个5×5的棋盘上有12个白色的骑士和12个黑色的骑士,且有一个空位.在任何时候一个骑士都能按照骑士的走法(它可以走到和它横坐标相差为1,纵坐标相差为2或者横坐标相差为2,纵 ...
- [BZOJ 1085][SCOI2005]骑士精神(IDA*)
题目:http://www.lydsy.com:808/JudgeOnline/problem.php?id=1085 分析: 首先第一感觉是宽搜,但是空间需要8^15*5*5,明显不够,又鉴于最大深 ...
- BZOJ.1085.[SCOI2005]骑士精神(迭代加深搜索)
题目链接 最小步数这类,适合用迭代加深搜索. 用空格走代替骑士. 搜索时记录上一步防止来回走. 不需要每次判断是否都在位置,可以计算出不在对应位置的骑士有多少个.而且每次复原一个骑士至少需要一步. 空 ...
- bzoj 1085 [SCOI2005]骑士精神——IDA*
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=1085 迭代加深搜索. 估价函数是为了预计步数来剪枝,所以要优于实际步数. 没错,不是为了确定 ...
- bzoj 1085: [SCOI2005]骑士精神 IDA*
题目链接 给一个图, 目标位置是确定的, 问你能否在15步之内达到目标位置. 因为只有15步, 所以直接ida* #include<bits/stdc++.h> using namespa ...
- BZOJ 1085: [SCOI2005]骑士精神(A*算法)
第一次写A*算法(这就是A*?如果这就是A*的话,那不就只是搜索的一个优化了= =,不过h函数如果弄难一点真的有些难设计) 其实就是判断t+h(x)(t为当前步数,h(x)为达到当前状态的最小步数) ...
随机推荐
- 【OpenStack】OpenStack系列15之OpenStack高可用详解
高可用 概念 级别 陈本 如何实现 分类 Openstack的HA 虚拟机的HA 虚拟机HA 比较 应用级别HA,Heat的HA模板 组件的HA 示意图 Mysql的HA 三种方式之一——主从同步 ...
- 深入学习微框架:Spring Boot - NO
http://blog.csdn.net/hengyunabc/article/details/50120001 Our primary goals are: Provide a radically ...
- 2.16 最长递增子序列 LIS
[本文链接] http://www.cnblogs.com/hellogiser/p/dp-of-LIS.html [分析] 思路一:设序列为A,对序列进行排序后得到B,那么A的最长递增子序列LIS就 ...
- Android 中“TabBar”的背景拉伸问题
在最近的一个工程中,要求有一个在上方了tabbar,上面有并排的3个方形按钮,每个按钮都有背景图.问题来了,如何让图片在不同尺寸的屏幕上不失真呢?(由于我们的项目比较小,工时很短,不能为每一个屏幕尺寸 ...
- Java for LeetCode 141 Linked List Cycle
Given a linked list, determine if it has a cycle in it. Follow up: Can you solve it without using ex ...
- 【JAVA、C++】 LeetCode 008 String to Integer (atoi)
Implement atoi to convert a string to an integer. Hint: Carefully consider all possible input cases. ...
- c标签设置jsp页面的绝对路径
<%@ page language="java" pageEncoding="UTF-8"%><%@ taglib prefix=" ...
- [Android Pro] 通过IMSI判断手机是移动、联通、电信
TelephonyManager telManager = (TelephonyManager) getSystemService(Context.TELEPHONY_SERVICE); /** 获取 ...
- MySQL和PHP基础考试错题回顾
13.关于exit( )与die( )的说法正确的是( B) C A.当exit( )函数执行会停止执行下面的脚本,而die()无法做到 B.当die()函数执行会停止执行下面的脚本,而exit( ) ...
- mac平台下面ruby环境搭建
一.安装xcode 先安装 [Xcode](http://developer.apple.com/xcode/) 开发工具,它将帮你安装好 Unix 环境需要的开发包 二.安装 RVM curl -L ...