hiho47 : 拓扑排序·一
描述
由于今天上课的老师讲的特别无聊,小Hi和小Ho偷偷地聊了起来。
小Ho:小Hi,你这学期有选什么课么?
小Hi:挺多的,比如XXX1,XXX2还有XXX3。本来想选YYY2的,但是好像没有先选过YYY1,不能选YYY2。
小Ho:先修课程真是个麻烦的东西呢。
小Hi:没错呢。好多课程都有先修课程,每次选课之前都得先查查有没有先修。教务公布的先修课程记录都是好多年前的,不但有重复的信息,好像很多都不正确了。
小Ho:课程太多了,教务也没法整理吧。他们也没法一个一个确认有没有写错。
小Hi:这不正是轮到小Ho你出马的时候了么!
小Ho:哎??
我们都知道大学的课程是可以自己选择的,每一个学期可以自由选择打算学习的课程。唯一限制我们选课是一些课程之间的顺序关系:有的难度很大的课程可能会有一些前置课程的要求。比如课程A是课程B的前置课程,则要求先学习完A课程,才可以选择B课程。大学的教务收集了所有课程的顺序关系,但由于系统故障,可能有一些信息出现了错误。现在小Ho把信息都告诉你,请你帮小Ho判断一下这些信息是否有误。错误的信息主要是指出现了"课程A是课程B的前置课程,同时课程B也是课程A的前置课程"这样的情况。当然"课程A是课程B的前置课程,课程B是课程C的前置课程,课程C是课程A的前置课程"这类也是错误的。
输入
第1行:1个整数T,表示数据的组数T(1 <= T <= 5)
接下来T组数据按照以下格式:
第1行:2个整数,N,M。N表示课程总数量,课程编号为1..N。M表示顺序关系的数量。1 <= N <= 100,000. 1 <= M <= 500,000
第2..M+1行:每行2个整数,A,B。表示课程A是课程B的前置课程。
输出
第1..T行:每行1个字符串,若该组信息无误,输出"Correct",若该组信息有误,输出"Wrong"。
- 样例输入
-
2
2 2
1 2
2 1
3 2
1 2
1 3 - 样例输出
-
Wrong
Correct提示:拓扑排序
小Ho拿出纸笔边画边说道:如果把每一门课程看作一个点,那么顺序关系也就是一条有向边了。错误的情况也就是出现了环。我知道了!这次我们要做的是判定一个有向图是否有环。
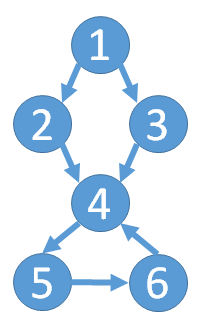
小Hi:小Ho你有什么想法么?
<小Ho思考了一会儿>
小Ho:一个直观的算法就是每次删除一个入度为0的点,直到没有入度为0的点为止。如果这时还有点没被删除,这些没被删除的点至少组成一个环;反之如果所有点都被删除了,则有向图中一定没有环。
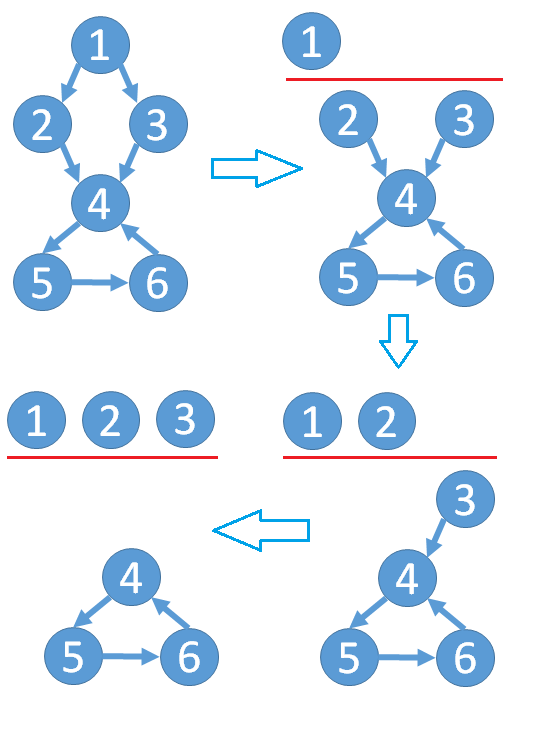
小Hi:Good Job!那赶快去写代码吧!
小Ho又思考了一会儿,挠了挠头说:每次删除一个点之后都要找出当前入度为0的点,这一步我没想到高效的方法。通过扫描一遍剩余的边可以找所有出当前入度为0的点,但是每次删除一个节点之后都扫描一遍的话复杂度很高。
小Hi赞许道:看来你已经养成写代码前分析复杂度的意识了!这里确实需要一些实现技巧,才能把复杂度降为O(N+M),其中N和M分别代表点数和边数。我给你一个提示:如果我们能维护每个点的入度值,也就是在删除点的同时更新受影响的点的入度值,那么是不是就能快速找出入度为0的点了呢?
小Ho:我明白了,这个问题可以这样来解决:
1. 计算每一个点的入度值deg[i],这一步需要扫描所有点和边,复杂度O(N+M)。
2. 把入度为0的点加入队列Q中,当然有可能存在多个入度为0的点,同时它们之间也不会存在连接关系,所以按照任意顺序加入Q都是可以的。
3. 从Q中取出一个点p。对于每一个未删除且与p相连的点q,deg[q] = deg[q] - 1;如果deg[q]==0,把q加入Q。
4. 不断重复第3步,直到Q为空。
最后剩下的未被删除的点,也就是组成环的点了。
小Hi:没错。这一过程就叫做拓扑排序。
小Ho:我懂了。我这就去实现它!
< 十分钟之后 >
小Ho:小Hi,不好了,我的程序写好之后编译就出诡异错误了!
小Hi:诡异错误?让我看看。
小Hi凑近电脑屏幕看了看小Ho的源代码,只见小Ho写了如下的代码:
int edge[ MAXN ][ MAXN ];
小Hi:小Ho,你有理解这题的数据范围么?
小Ho:N最大等于10万啊,怎么了?
小Hi:你的数组有10万乘上10万,也就是100亿了。算上一个int为4个字节,这也得400亿字节,将近40G了呢。
小Ho:啊?!那我应该怎么?QAQ
小Hi:这里就教你一个小技巧好了:
这道题目中N的数据范围在10万,若采用邻接矩阵的方式来储存数据显然是会内存溢出。而且每次枚举一个点时也可能会因为枚举过多无用的而导致超时。因此在这道题目中我们需要采用邻接表的方式来储存我们的数据:
常见的邻接表大多是使用的指针来进行元素的串联,其实我们可以通过数组来模拟这一过程。
int head[ MAXN + 1] = {0}; // 表示头指针,初始化为0
int p[ MAXM + 1]; // 表示指向的节点
int next[ MAXM + 1] = {0}; // 模拟指针,初始化为0
int edgecnt; // 记录边的数量 void addedge(int u, int v) { // 添加边(u,v)
++edgecnt;
p[ edgecnt ] = v;
next[ edgecnt ] = head[u];
head[u] = edgecnt;
} // 枚举边的过程,u为起始点
for (int i = head[u]; i; i = next[i]) {
v = p[i];
...
}小Ho:原来还有这种办法啊?好咧。我这就去改进我的算法=v=
#include <iostream>
#include <queue>
#include <vector>
using namespace std; bool isTuopu(vector<vector<int> >& Graph) //拓扑排序
{
queue<int> Hq; //记录入度为0的结点
vector<int> rudu(Graph.size(), ); //记录结点的入度
for(int i=; i<Graph.size(); i++)
{
for (int j=; j<Graph[i].size(); j++)
{
rudu[Graph[i][j]]++;
} } for (int i=; i<rudu.size(); i++)
{
if(rudu[i]==)
Hq.push(i);
} if(Hq.empty())
return false; while(!Hq.empty())
{
int tmp = Hq.front();
Hq.pop();
for(int i=; i<Graph[tmp].size(); i++)
{
rudu[ Graph[tmp][i] ]--;
if( rudu[ Graph[tmp][i] ]== )
Hq.push(Graph[tmp][i]);
}
} for(int i=; i<rudu.size(); i++)
if(rudu[i]!=)
return false;
return true;
} int main()
{
vector<int> edge;
//vector<vector<int> > Graph(100000, edge); vector<bool> res; int T, N, M;
cin>>T;
while(T--)
{
cin>>N>>M;
vector<vector<int> > Graph(N, edge); //边表 while(M--)
{
int a, b;
cin>>a>>b;
a--; //顶点数从0开始
b--;
Graph[a].push_back(b);
}
res.push_back(isTuopu(Graph));
} for (int i=; i<res.size(); i++)
{
if(res[i])
cout<<"Correct"<<endl;
else
cout<<"Wrong"<<endl;
} return ; }
hiho47 : 拓扑排序·一的更多相关文章
- 算法与数据结构(七) AOV网的拓扑排序
今天博客的内容依然与图有关,今天博客的主题是关于拓扑排序的.拓扑排序是基于AOV网的,关于AOV网的概念,我想引用下方这句话来介绍: AOV网:在现代化管理中,人们常用有向图来描述和分析一项工程的计划 ...
- 有向无环图的应用—AOV网 和 拓扑排序
有向无环图:无环的有向图,简称 DAG (Directed Acycline Graph) 图. 一个有向图的生成树是一个有向树,一个非连通有向图的若干强连通分量生成若干有向树,这些有向数形成生成森林 ...
- 【BZOJ-2938】病毒 Trie图 + 拓扑排序
2938: [Poi2000]病毒 Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 609 Solved: 318[Submit][Status][Di ...
- BZOJ1565 [NOI2009]植物大战僵尸(拓扑排序 + 最大权闭合子图)
题目 Source http://www.lydsy.com/JudgeOnline/problem.php?id=1565 Description Input Output 仅包含一个整数,表示可以 ...
- 图——拓扑排序(uva10305)
John has n tasks to do. Unfortunately, the tasks are not independent and the execution of one task i ...
- Java排序算法——拓扑排序
package graph; import java.util.LinkedList; import java.util.Queue; import thinkinjava.net.mindview. ...
- poj 3687(拓扑排序)
http://poj.org/problem?id=3687 题意:有一些球他们都有各自的重量,而且每个球的重量都不相同,现在,要给这些球贴标签.如果这些球没有限定条件说是哪个比哪个轻的话,那么默认的 ...
- 拓扑排序 - 并查集 - Rank of Tetris
Description 自从Lele开发了Rating系统,他的Tetris事业更是如虎添翼,不久他遍把这个游戏推向了全球. 为了更好的符合那些爱好者的喜好,Lele又想了一个新点子:他将制作一个全球 ...
- *HDU1285 拓扑排序
确定比赛名次 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Subm ...
随机推荐
- Sonar+Hudson+Maven构建系列之二:迁移Sonar
摘要:由于昨天在一台机器上安装的东西太多了,导致Linux机器上非常卡,一台Linux负担了jira, fisheye, confluence, sonar, hudson, mysql 等等,本来已 ...
- FFmpeg源代码结构图
转自:http://blog.csdn.net/leixiaohua1020/article/details/44220151 FFmpeg的库函数源代码分析文章列表: [架构图] FFmpeg源代码 ...
- CC2540开发板学习笔记(六)——AD控制(自带温度计)
一.实验目的 将采集的内部温度传感器信息通过串口发送到上位机 二.实验过程 1.寄存器配置 ADCCON1(0XB4)ADC控制寄存器1 BIT7:EOC ADC结束标志位0:AD转换进行中 ...
- 个人电脑配置FTP服务器,四张图搞定。项目需要,并自己写了个客户端实现下载和上传的功能!
测试结果:
- IDEA中如何使用Maven进行打包。 IDEA版本是14
说实话,找了好半天的资料,也许是我的IDEA版本太高了网上资料稀缺,所以愣是没有找到打包的方法,只是自己瞎琢磨了,还好搞出来了,记录一下. 说文字说一下大概流程,其实很简单: 创建配置文件->创 ...
- mvc-3模型和数据(2)
寻址引用 源代码现存的问题:当保存或通过find()查找记录时,所返回的实例并没有复制一份,因此对任何属性的修改都会影响原始资源:这里我们只想当调用update()方法时才会修改资源 //由于Mode ...
- 常见的文件上传方法有哪些?Ajax文件上传原理是什么?
Ajaxfileupload,Ajaxupload,JqueryUploadify无刷新式的文件上传,在一个页面里嵌入一个Iframe,然后在Iframe使用原生的Post表单提交.
- LCS(打印路径) POJ 2250 Compromise
题目传送门 题意:求单词的最长公共子序列,并要求打印路径 分析:LCS 将单词看成一个点,dp[i][j] = dp[i-1][j-1] + 1 (s1[i] == s2[j]), dp[i][j] ...
- asp.net 未能写入输出文件--“拒绝访问”的解决办法
概述 将网部署在IIS 7 上,访问本地磁盘路径的时候,提示"**文件拒绝访问". 解决办法 将需要访问的文件夹赋于IIS_IUSRS完全控制的权限即可,不用添加NET ...
- BZOJ1834 [ZJOI2010]network 网络扩容(最小费用最大流)
挺直白的构图..最小费用最大流的定义. #include<cstdio> #include<cstring> #include<queue> #include< ...