SSTable and Log Structured Storage: LevelDB
If Protocol Buffers is the lingua franca of individual data record at Google, then the Sorted String Table (SSTable) is one of the most popular outputs for storing, processing, and exchanging datasets. As the name itself implies, an SSTable is a simple abstraction to efficiently store large numbers of key-value pairs while optimizing for high throughput, sequential read/write workloads.
Unfortunately, the SSTable name itself has also been overloaded by the industry to refer to services that go well beyond just the sorted table, which has only added unnecessary confusion to what is a very simple and a useful data structure on its own. Let's take a closer look under the hood of an SSTable and how LevelDB makes use of it.
SSTable: Sorted String Table
Imagine we need to process a large workload where the input is in Gigabytes or Terabytes in size. Additionally, we need to run multiple steps on it, which must be performed by different binaries - in other words, imagine we are running a sequence of Map-Reduce jobs! Due to size of input, reading and writing data can dominate the running time. Hence, random reads and writes are not an option, instead we will want to stream the data in and once we're done, flush it back to disk as a streaming operation. This way, we can amortize the disk I/O costs. Nothing revolutionary, moving right along.

A "Sorted String Table" then is exactly what it sounds like, it is a file which contains a set of arbitrary, sorted key-value pairs inside. Duplicate keys are fine, there is no need for "padding" for keys or values, and keys and values are arbitrary blobs. Read in the entire file sequentially and you have a sorted index. Optionally, if the file is very large, we can also prepend, or create a standalone key:offset index for fast access. That's all an SSTable is: very simple, but also a very useful way to exchange large, sorted data segments.
SSTable and BigTable: Fast random access?
Once an SSTable is on disk it is effectively immutable because an insert or delete would require a large I/O rewrite of the file. Having said that, for static indexes it is a great solution: read in the index, and you are always one disk seek away, or simply memmap the entire file to memory. Random reads are fast and easy.
Random writes are much harder and expensive, that is, unless the entire table is in memory, in which case we're back to simple pointer manipulation. Turns out, this is the very problem that Google's BigTable set out to solve: fast read/write access for petabyte datasets in size, backed by SSTables underneath. How did they do it?
SSTables and Log Structured Merge Trees
We want to preserve the fast read access which SSTables give us, but we also want to support fast random writes. Turns out, we already have all the necessary pieces: random writes are fast when the SSTable is in memory (let's call it MemTable), and if the table is immutable then an on-disk SSTable is also fast to read from. Now let's introduce the following conventions:
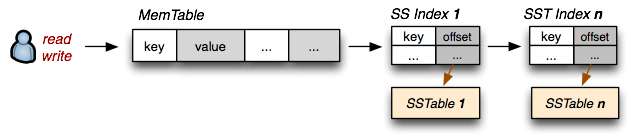
- On-disk
SSTableindexes are always loaded into memory - All writes go directly to the
MemTableindex - Reads check the MemTable first and then the SSTable indexes
- Periodically, the MemTable is flushed to disk as an SSTable
- Periodically, on-disk SSTables are "collapsed together"
What have we done here? Writes are always done in memory and hence are always fast. Once the MemTable reaches a certain size, it is flushed to disk as an immutable SSTable. However, we will maintain all the SSTable indexes in memory, which means that for any read we can check the MemTable first, and then walk the sequence of SSTable indexes to find our data. Turns out, we have just reinvented the "The Log-Structured Merge-Tree" (LSM Tree), described by Patrick O'Neil, and this is also the very mechanism behind "BigTable Tablets".
LSM & SSTables: Updates, Deletes and Maintenance
This "LSM" architecture provides a number of interesting behaviors: writes are always fast regardless of the size of dataset (append-only), and random reads are either served from memory or require a quick disk seek. However, what about updates and deletes?
Once the SSTable is on disk, it is immutable, hence updates and deletes can't touch the data. Instead, a more recent value is simply stored in MemTable in case of update, and a "tombstone" record is appended for deletes. Because we check the indexes in sequence, future reads will find the updated or the tombstone record without ever reaching the older values! Finally, having hundreds of on-disk SSTables is also not a great idea, hence periodically we will run a process to merge the on-disk SSTables, at which time the update and delete records will overwrite and remove the older data.
SSTables and LevelDB
Take an SSTable, add a MemTable and apply a set of processing conventions and what you get is a nice database engine for certain type of workloads. In fact, Google's BigTable, Hadoop's HBase, and Cassandra amongst others are all using a variant or a direct copy of this very architecture.
Simple on the surface, but as usual, implementation details matter a great deal. Thankfully, Jeff Dean and Sanjay Ghemawat, the original contributors to the SSTable and BigTable infrastructure at Google released LevelDB earlier last year, which is more or less an exact replica of the architecture we've described above:
- SSTable under the hood, MemTable for writes
- Keys and values are arbitrary byte arrays
- Support for Put, Get, Delete operations
- Forward and backward iteration over data
- Built-in Snappy compression
Designed to be the engine for IndexDB in WebKit (aka, embedded in your browser), it is easy to embed, fast, and best of all, takes care of all the SSTable and MemTable flushing, merging and other gnarly details.
Working with LevelDB: Ruby
LevelDB is a library, not a standalone server or service - although you could easily implement one on top. To get started, grab your favorite language bindings (ruby), and let's see what we can do:
require 'leveldb' # gem install leveldb-ruby
db = LevelDB::DB.new "/tmp/db"
db.put "b", "bar"
db.put "a", "foo"
db.put "c", "baz"
puts db.get "a" # => foo
db.each do |k,v|
p [k,v] # => ["a", "foo"], ["b", "bar"], ["c", "baz"]
end
db.to_a # => [["a", "foo"], ["b", "bar"], ["c", "baz"]]We can store keys, retrieve them, and perform a range scan all with a few lines of code. The mechanics of maintaining the MemTables, merging the SSTables, and the rest is taken care for us by LevelDB - nice and simple.
LevelDB in WebKit and Beyond
SSTable is a very simple and useful data structure - a great bulk input/output format. However, what makes the SSTable fast (sorted and immutable) is also what exposes its very limitations. To address this, we've introduced the idea of a MemTable, and a set of "log structured" processing conventions for managing the many SSTables.
All simple rules, but as always, implementation details matter, which is why LevelDB is such a nice addition to the open-source database engine stack. Chances are, you will soon find LevelDB embedded in your browser, on your phone, and in many other places. Check out the LevelDB source, scan the docs, and take it for a spin.
SSTable and Log Structured Storage: LevelDB的更多相关文章
- The storage wars: Shadow Paging, Log Structured Merge and Write Ahead Logging
The storage wars: Shadow Paging, Log Structured Merge and Write Ahead Logging previous: Seek, and yo ...
- Log Structured Merge Trees (LSM)
1 概念 LSM = Log Structured Merge Trees 来源于google的bigtable论文. 2 解决问题 传统的数据库如MySql采用B+树存放数据,B ...
- Log Structured Merge Trees(LSM) 算法
十年前,谷歌发表了 “BigTable” 的论文,论文中很多很酷的方面之一就是它所使用的文件组织方式,这个方法更一般的名字叫 Log Structured-Merge Tree. LSM是当前被用在许 ...
- Managing IIS Log File Storage
Managing IIS Log File Storage You can manage the amount of server disk space that Internet Informa ...
- LSM(Log Structured Merge Trees ) 笔记
目录 一.大幅度制约存储介质吞吐量的原因 二.传统数据库的实现机制 三.LSM Tree的历史由来 四.提高写吞吐量的思路 4.1 一种方式是数据来后,直接顺序落盘 4.2 另一种方式,是保证落盘的数 ...
- Log Structured Merge Trees(LSM) 原理
http://www.open-open.com/lib/view/open1424916275249.html
- 分布式学习材料Distributed System Prerequisite List
接下的内容按几个大类来列:1. 文件系统a. GFS – The Google File Systemb. HDFS1) The Hadoop Distributed File System2) Th ...
- sstable, bigtable,leveldb,cassandra,hbase的lsm基础
先看懂文献1和2 1. 先了解sstable.SSTable: Sorted String Table [2] [10] WiscKey: 类似myisam, key value分离, 根据ssd优 ...
- leveldb - log格式
log文件在LevelDb中的主要作用是系统故障恢复时,能够保证不会丢失数据.因为在将记录写入内存的Memtable之前,会先写入Log文件,这样即使系统发生故障,Memtable中的数据没有来得及D ...
随机推荐
- 【10_169】Majority Element
今天遇到的题都挺难的,不容易有会做的. 下面是代码,等明天看看Discuss里面有没有简单的方法~ Majority Element My Submissions Question Total Acc ...
- 给“.Net工资低”争论一个了结吧!
昨天我写了一篇<工资低的.Net程序员,活该你工资低>,底下的支持.争吵.骂娘的评论依旧像之前几篇园友的博客一样繁荣.公说公有理,婆说婆有理,这样争吵下去永远没有尽头.数据没有情绪,是公正 ...
- ASP.NET MVC 4源码分析之如何定位控制器
利用少有的空余时间,详细的浏览了下ASP.NET MVC 4的源代码.照着之前的步伐继续前进(虽然博客园已经存在很多大牛对MVC源码分析的博客,但是从个人出发,还是希望自己能够摸索出这些).首先有一个 ...
- Gatling->次时代性能测试利器
Gatling作为一款开源免费的性能测试工具越来越受到广大程序员的欢迎.免费当然是好的,最缺钱的就是程序员了;开源更好啊,缺啥功能.想做定制化的可以自己动手,丰衣足食.其实我最喜欢的原因是其提供了简洁 ...
- Atitit.人力资源管理原理与概论
Atitit.人力资源管理原理与概论 1. 人力资源管理 第一章 人力资源管理概述 第二章 人力资源理论基础与发展演变 第三章 人力资源规划 第四章工作分析与工作设计 第五章 员工招聘与录用 第六章 ...
- atitit.js 各版本 and 新特性跟浏览器支持报告
atitit.js 各版本 and 新特性跟浏览器支持报告 一个完整的JavaScript实现是由以下3个不同部分组成的 •核心(ECMAScript)--JavaScript的核心ECMAScrip ...
- paip.web数据绑定 下拉框的api设计 选择框 uapi python .net java swing jsf总结
paip.web数据绑定 下拉框的api设计 选择框 uapi python .net java swing jsf总结 ====总结: 数据绑定下拉框,Uapi 1.最好的是默认绑定..Map(k ...
- Cento OS 6.5 YUM 安装 R 的方法
(1)配置yum (2)安装EPEL YUM源 yum install epel-release 修改源配置文件/etc/yum.repos.d/epel.repo ,把基础的恢复,镜像的地址注释掉 ...
- HTTP协议和几种常见的状态码
前言:明知山有釜,偏向釜山行-----电影<釜山行> ------------------------------------------------------------------- ...
- hdu 1864 01背包 最大报销额
http://acm.hdu.edu.cn/showproblem.php?pid=1864 New~ 欢迎“热爱编程”的高考少年——报考杭州电子科技大学计算机学院关于2015年杭电ACM暑期集训队的 ...