Guava中Lists.partition(List, size) 方法懒划分/懒分区
Guava中Lists.partition(List, size) 方法懒划分/懒分区
背景
前几天有同事使用这个方法,不小心点进去查看源码,源码如下,然他通过idea工具debug发现执行完Lists.partition(List, size) 这一行直接就现实了个size大小如下图:看了源码后根本就没有显示的调用size这些啊,就在那思考不知道为什么?
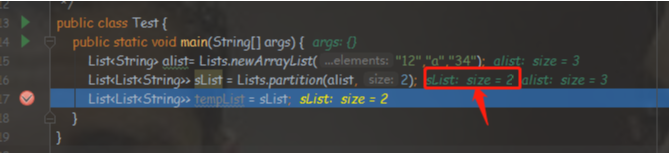
Lists.partition(List, size)源码如下:
@GwtCompatible(emulated = true)
public final class Lists {
.....
public static <T> List<List<T>> partition(List<T> list, int size) {
checkNotNull(list);
checkArgument(size > 0);
return (list instanceof RandomAccess)
? new RandomAccessPartition<>(list, size)
: new Partition<>(list, size);
}
private static class Partition<T> extends AbstractList<List<T>> {
final List<T> list;
final int size;
Partition(List<T> list, int size) {
this.list = list;
this.size = size;
}
@Override
public List<T> get(int index) {
checkElementIndex(index, size());
int start = index * size;
int end = Math.min(start + size, list.size());
return list.subList(start, end);
}
@Override
public int size() {
return IntMath.divide(list.size(), size, RoundingMode.CEILING);
}
@Override
public boolean isEmpty() {
return list.isEmpty();
}
}
private static class RandomAccessPartition<T> extends Partition<T> implements RandomAccess {
RandomAccessPartition(List<T> list, int size) {
super(list, size);
}
}
.....
}
分析
发现了问题,我们就应该分析为什么会出现这情况?
通过上面贴出来的代码以及Guava的源码,发现就是创建了一个Partition类过后啥都没做。为什么?
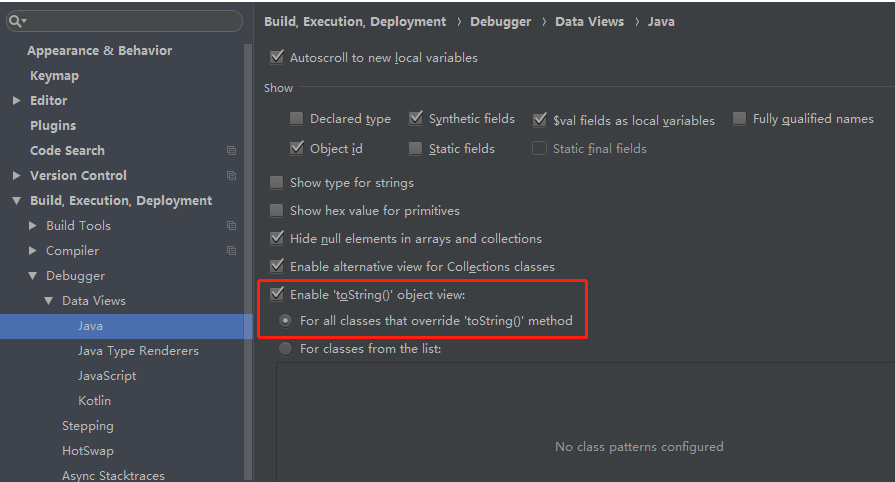
显示为什么调用toString?
通过查看idea--setting--Debugger--java可以看到。
那我们跟进代码后发现在AbstractCollection类中重写了toString方法,代码如下:
public String toString() {
Iterator<E> it = iterator();
if (! it.hasNext())
return "[]";
StringBuilder sb = new StringBuilder();
sb.append('[');
for (;;) {
E e = it.next();
sb.append(e == this ? "(this Collection)" : e);
if (! it.hasNext())
return sb.append(']').toString();
sb.append(',').append(' ');
}
}
刚才不是说会调用toString方法么?那问题来了应该显示一个数组,不应该显示size ?
应该显示一个数组,不应该显示size
在上面的截图中我们可以看到复选框勾选了好几个,其中有个Enable alternative view for Collections classes.好现在我们将这个去掉。看看执行的结果如下图:

通过结果,我们发现现在显示的是数组了。看来Enable alternative view for Collections classes这个选项是专门针对集合来显示的。
如何是懒划分/懒分区
懒划分/懒分区意思就是当我们真正使用的时候才会去划分。下面分析下如何来懒划分的。验证demo如下:
public class Test {
public static void main(String[] args) {
List<String> alist= Lists.newArrayList("12","a","34");
List<List<String>> sList = Lists.partition(alist, 2);
sList.forEach(e -> {
System.out.println(sList);
});
}
}
我们看下forEach的源码如下:
public interface Iterable<T> {
....
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
....
}
看到这里是否有点懵逼。这里套了一层循环,没有显示调用分区呢?这个需要对for循环深入研究才行。我们可以通过简单写一个for循环后查看字节码看看底层到底是如何实现循环的。简单的for循环如下:
public class Test2 {
public static void main(String[] args) {
List<Integer> il = Lists.newArrayList(12,1,3,4);
for (Integer i : il) {}
}
}
通过javap -c Test2.class反解析字节码后如下图:
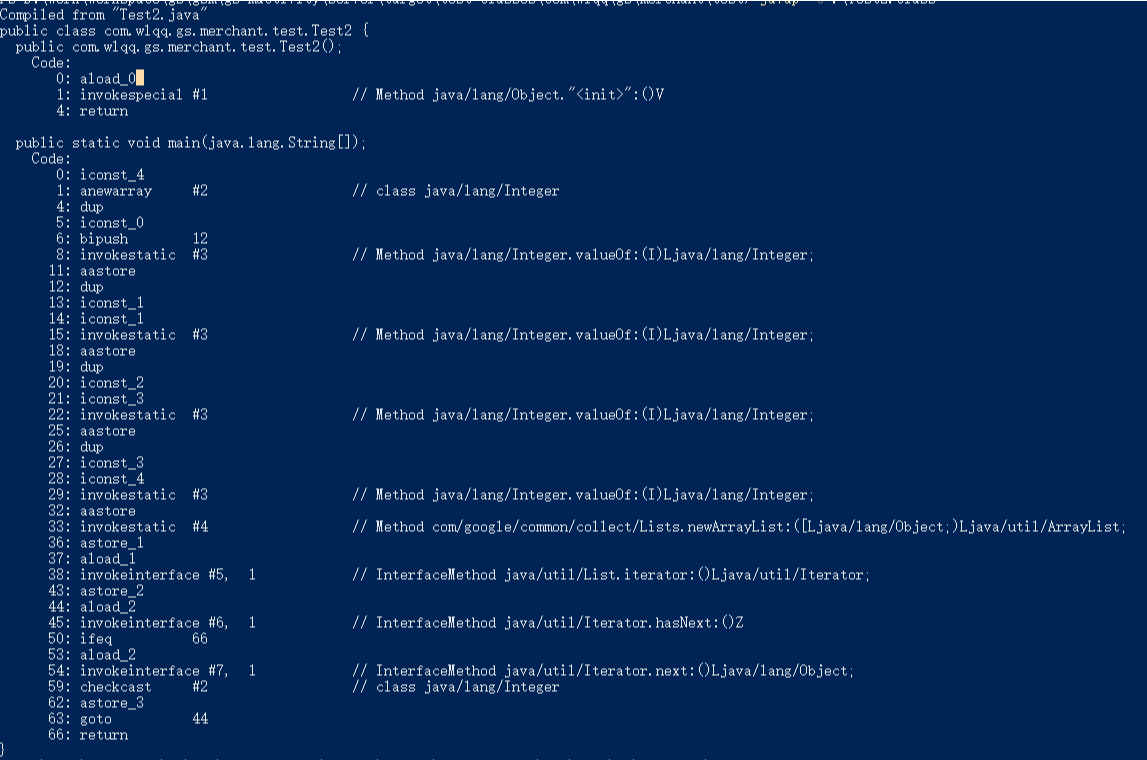
从图中这些关键字信息
38: invokeinterface #5, 1 // InterfaceMethod java/util/List.iterator:()Ljava/util/Iterator;
45: invokeinterface #6, 1 // InterfaceMethod java/util/Iterator.hasNext:()Z
54: invokeinterface #7, 1 // InterfaceMethod java/util/Iterator.next:()Ljava/lang/Object;
这说明了我们for循环底层上还是通过迭代器来实现的。我们也可以看出依次调用iterator()->hasNext()->next()。
从开篇源码看出Guava中Partition的继承关系,发现当底层循环的时候调用iterator()方法是其实是调用AbstractList#iterator()方法,AbstractList#iterator()涉及源码如下
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {
...
public Iterator<E> iterator() {
return new Itr();
}
...
private class Itr implements Iterator<E> {
int cursor = 0;
int lastRet = -1;
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size();
}
public E next() {
checkForComodification();
try {
int i = cursor;
E next = get(i);
lastRet = i;
cursor = i + 1;
return next;
} catch (IndexOutOfBoundsException e) {
checkForComodification();
throw new NoSuchElementException();
}
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
AbstractList.this.remove(lastRet);
if (lastRet < cursor)
cursor--;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException e) {
throw new ConcurrentModificationException();
}
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
}
通过上面的源码,发现当调用hasNext()方法的时候会调用size()方法。然size()方法就是我们Guava中这段代码
public int size() {
return IntMath.divide(list.size(), size, RoundingMode.CEILING);
}
当调用next()方法的时候,先是调用子类实现的get(i)方法,子类也就是Guava中这段代码
public List<T> get(int index) {
checkElementIndex(index, size());
int start = index * size;
int end = Math.min(start + size, list.size());
return list.subList(start, end);
}
到此已基本分析完成了。
总结
我们在学习任何知识点的时候都要好好分析,想想,为什么要这样设计?设计的好处是什么?还有就是知识的串联。
比如for 循环。如果不深入研究,你也不知道为啥会调用iterator等一系列的方法。
Guava中Lists.partition(List, size) 方法懒划分/懒分区的更多相关文章
- Guava中Predicate的常见用法
Guava中Predicate的常见用法 1. Predicate基本用法 guava提供了许多利用Functions和Predicates来操作Collections的工具,一般在 Iterabl ...
- ConcurrentHashMap的size方法是线程安全的吗?
前言 之前在面试的过程中有被问到,ConcurrentHashMap的size方法是线程安全的吗? 这个问题,确实没有答好.这次来根据源码来了解一下,具体是怎么一个实现过程. ConcurrentHa ...
- ConcurrentHashmap中的size()方法简单解释
本文所有的源码都是基于JDK1.8 ConcurrentHashmap中的size()方法源码: public int size() { long n = sumCount(); return ((n ...
- 使用size()方法输出列表中的元素数量。需要注意的是,这个方法返回的值可能不是真实的,尤其当有线程在添加数据或者移除数据时,这个方法需要遍历整个列表来计算元素数量,而遍历过的数据可能已经改变。仅当没有任何线程修改列表时,才能保证返回的结果是准确的。
使用size()方法输出列表中的元素数量.需要注意的是,这个方法返回的值可能不是真实的,尤其当有线程在添加数据或者移除数据时,这个方法需要遍历整个列表来计算元素数量,而遍历过的数据可能已经改变.仅当没 ...
- Google Guava中的前置条件
前置条件:让方法调用的前置条件判断更简单. Guava在Preconditions类中提供了若干前置条件判断的实用方法,我们建议[在Eclipse中静态导入这些方法]每个方法都有三个变种: check ...
- 使用Lists.partition切分性能优化
项目实战 影拓邦电影同步中,使用Lists.partition按500条长度进行切分,来实现es的同步. 切分的List为 使用介绍及示例 将list集合按指定长度进行切分,返回新的List<L ...
- Guava中这些Map的骚操作,让我的代码量减少了50%
原创:微信公众号 码农参上,欢迎分享,转载请保留出处. Guava是google公司开发的一款Java类库扩展工具包,内含了丰富的API,涵盖了集合.缓存.并发.I/O等多个方面.使用这些API一方面 ...
- 解析Jquery取得iframe中元素的几种方法
iframe在复合文档中经常用到,利用jquery操作iframe可以大幅提高效率,这里收集一些基本操作,需要的朋友可以参考下 DOM方法:父窗口操作IFRAME:window.frames[&q ...
- Java小知识--length,length(),size()方法详细介绍
Java中length,length(),size()区别 length属性:用于获取数组长度. eg: int ar[] = new int{1,2,3} /** * 数组用length属性取得长度 ...
随机推荐
- 服务器上office不能正常使用?
(1)确保dll版本和服务器上office版本一致 (2)配置dcom (3)项目配置文件中添加用户模拟语句 <system.web> <identity impersonate=& ...
- 有趣的"=="与"==="
console.log([]==![]);//true //"=="会进行类型转换,转换成统一类型进行比较 // !符号优于==,[]boolean值为TRUE,所以![]就是FA ...
- 报错处理(UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position 2: ill egal multibyte sequence)
参照文[https://blog.csdn.net/Dillon2015/article/details/53204955]的说法, 第一个错 [UnicodeEncodeError:'gbk' co ...
- 阿里云Ubuntu下tomcat8.5配置SSL证书
环境 阿里云ubuntu(18.04)服务器 阿里云申请的域名 Tomcat8.5.7 jdk1.8 免费型SSL证书 SSL证书申请 登录阿里云的官网,登录后在菜单中选择SSL证书(应用安全) 进入 ...
- vim技巧总结
自动补齐CTRL+N/CTRL+P vim 自动补全 颜色设置 hi Pmenu ctermfg=black ctermbg=gray guibg=#444444 hi PmenuSel ctermf ...
- SQLite3学习笔记(2)
SQLite 创建表 SQLite 的CREATE TABLE 语句用于在任何指定的数据库创建一个新表. 创建新表,涉及到命名表.定义列及每一行的数据类型. CREATE TABLE 的基本语法如 ...
- OSI七层协议和TCP/IP四层协议
1. OSI七层和TCP/IP四层的关系 1.1 OSI引入了服务.接口.协议.分层的概念,TCP/IP借鉴了OSI的这些概念建立TCP/IP模型. 1.2 OSI先有模型,后有协议,先有标准,后进行 ...
- 洛谷 P3119 [USACO15JAN]草鉴定Grass Cownoisseur (SCC缩点,SPFA最长路,枚举反边)
P3119 [USACO15JAN]草鉴定Grass Cownoisseur 题目描述 In an effort to better manage the grazing patterns of hi ...
- Java&Selenium借助AutoIt 实现非Input类型自动化上传文件
通常情况下实现自动化上传文件,都是通过sendKeys函数直接将文件全路径传给页面空间就能完成,然而这种情况只能对Input类型的控件有效,对于非Input类型的控件可以借助AutoIt来完成 下载地 ...
- HDU 6052 - To my boyfriend | 2017 Multi-University Training Contest 2
说实话不是很懂按题解怎么写,思路来源于 http://blog.csdn.net/calabash_boy/article/details/76272704?yyue=a21bo.50862.2018 ...