Innodb关键特性之自适用Hash索引
一、索引的资源消耗分析
1、索引三大特点
1、小:只在一个到多个列建立索引
2、有序:可以快速定位终点
3、有棵树:可以定位起点,树高一般小于等于3
2、索引的资源消耗点
1、树的高度,顺序访问索引的数据页,索引就是在列上建立的,数据量非常小,在内存中;
2、数据之间跳着访问
1、索引往表上跳,可能需要访问表的数据页很多;
2、通过索引访问表,主键列和索引的有序度出现严重的不一致时,可能就会产生大量物理读;
资源消耗最厉害:通过索引访问多行,需要从表中取多行数据,如果无序的话,来回跳着找,跳着访问,物理读会很严重。
二、自适应hash索引原理
1、原理过程
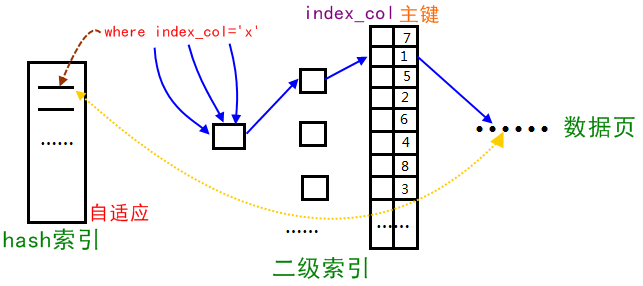
Innodb存储引擎会监控对表上二级索引的查找,如果发现某二级索引被频繁访问,二级索引成为热数据,建立哈希索引可以带来速度的提升,则:
1、自适应hash索引功能被打开
mysql> show variables like '%ap%hash_index';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| innodb_adaptive_hash_index | ON |
+----------------------------+-------+
1 row in set (0.01 sec)
2、经常访问的二级索引数据会自动被生成到hash索引里面去(最近连续被访问三次的数据),自适应哈希索引通过缓冲池的B+树构造而来,因此建立的速度很快。
2、特点
1、无序,没有树高
2、降低对二级索引树的频繁访问资源
索引树高<=4,访问索引:访问树、根节点、叶子节点
3、自适应
3、缺陷
1、hash自适应索引会占用innodb buffer pool;
2、自适应hash索引只适合搜索等值的查询,如select * from table where index_col='xxx',而对于其他查找类型,如范围查找,是不能使用的;
3、极端情况下,自适应hash索引才有比较大的意义,可以降低逻辑读。
三、监控与关闭
1、状态监控
mysql> show engine innodb status\G
……
Hash table size 34673, node heap has 0 buffer(s)
0.00 hash searches/s, 0.00 non-hash searches/s
1、34673:字节为单位,占用内存空间总量
2、通过hash searches、non-hash searches计算自适应hash索引带来的收益以及付出,确定是否开启自适应hash索引
2、限制
1、只能用于等值比较,例如=, <=>,in
2、无法用于排序
3、有冲突可能
4、MySQL自动管理,人为无法干预。
3、自适应哈希索引的控制
由于innodb不支持hash索引,但是在某些情况下hash索引的效率很高,于是出现了adaptive hash index功能,但是通过上面的状态监控,可以计算其收益以及付出,控制该功能开启与否。
默认开启,建议关掉,意义不大。可以通过 set global innodb_adaptive_hash_index=off/on 关闭和打开该功能。
Innodb关键特性之自适用Hash索引的更多相关文章
- InnoDB关键特性之自适应hash索引
一.索引的资源消耗分析 1.索引三大特点 1.小:只在一个到多个列建立索引 2.有序:可以快速定位终点 3.有棵树:可以定位起点,树高一般小于等于3 2.索引的资源消耗点 1.树的高度,顺序访问索引的 ...
- InnoDB关键特性学习笔记
插入缓存 Insert Buffer Insert Buffer是InnoDB存储引擎关键特性中最令人激动与兴奋的一个功能.不过这个名字可能会让人认为插入缓冲是缓冲池中的一个组成部分.其实不然,Inn ...
- InnoDB关键特性之change buffer
一.关于IOT:索引组织表 表在存储的时候按照主键排序进行存储,同时在主键上建立一棵树,这样就形成了一个索引组织表,一个表的存储方式以索引的方式来组织存储的. 所以,MySQL表一定要加上主键,通过主 ...
- innodb关键特性之double write
# 脏页刷盘的风险 两次写的原理机制 1.解决问题 2.使用场景 3.doublewrite的工作流程 4.崩溃恢复 # doublewrite的副作用 1.监控doublewrite负载 2.关闭d ...
- innodb 关键特性(两次写与自适应哈希索引)
两次写: 场景: 当发生数据库宕机时,可能innodb存储引擎正在写入某个页到表中,而这个页只写了一部分,这种情况被称为部分写失效,如果发生,可以通过重做日志进行恢复,重做日志中记录的是对页的物理操作 ...
- InnoDB关键特性之insert buffer
insert buffer 是InnoDB存储引擎所独有的功能.通过insert buffer,InnoDB存储引擎可以大幅度提高数据库中非唯一辅助索引的插入性能. 数据库对于自增主键值的插入是顺序的 ...
- InnoDB关键特性之刷新邻接页-异步IO
Flush neighbor page 1.工作原理 2.参数控制 AIO 1.开启异步IO 一.刷新邻接页功能 1.工作原理 当刷新一个脏页时,innodb存储引擎会检测该页所在区(extent)的 ...
- innodb 关键特性(insert buffer)
一.insert buffer 性能改善 insert buffer和数据页一样,也是物理页的一个组成部分. 在innodb存储引擎中,主键是行唯一的标识符.通常应用程序中行记录的插入顺序是按照主键递 ...
- InnoDB关键特性之doublewrite
部分写失效 想象这么一个场景,当数据库正在从内存向磁盘写一个数据页时,数据库宕机,从而导致这个页只写了部分数据,这就是部分写失效,它会导致数据丢失.这时是无法通过重做日志恢复的,因为重做日志记录的是对 ...
随机推荐
- JAVA视频压缩
https://www.cnblogs.com/chuanyueinlife/p/9014627.html
- 基于C#在WPF中使用斑马打印机进行打印【转】——不支持XPS的打印机
https://www.cnblogs.com/zhaobl/p/4666002.html
- 正则表达式\s空格,\d数字,量词+*?测试
之前的博文中: 有正则表达式的\b.i.\g,本文再测试了空格数字和量词的匹配.这篇只测试匹配,不替换或其他处理.\s空格:测试实际写空格也能识别,但是不利于看出空了几个空格,可以用\s代表空格.\d ...
- SET IDENTITY_INSERT的用法,具体去体验一下
如果将值插入到表的标识列中,需要启用 SET IDENTITY_INSERT. 举例如下: 创建表Orders.Products,Orders表与Products表分别有标识列OrderID与Prod ...
- 03点睛Spring MVC 4.1-REST
转发:https://www.iteye.com/blog/wiselyman-2214290 3.1 REST REST:Representational State Transfer; REST是 ...
- 【ARTS】01_41_左耳听风-201900819~201900825
ARTS: Algrothm: leetcode算法题目 Review: 阅读并且点评一篇英文技术文章 Tip/Techni: 学习一个技术技巧 Share: 分享一篇有观点和思考的技术文章 Algo ...
- zabbix4.2+grafana搭建骚气的监控运维平台
Zabbix 是一个企业级分布式开源监控解决方案,其监控与告警功能十分强大.Grafana是一款开源的可视化软件,可以搭配数据源实现一个数据的展示和分析:Grafana功能强大,有着丰富的插件.两者结 ...
- 使用plotrix做韦恩图
color <- c("#E41A1C","#377EB8","#FDB462") color_transparent <- a ...
- 037 Android Glide图片加载开源框架使用
1.Glide简单介绍 Glide是一款由Bump Technologies开发的图片加载框架,使得我们可以在Android平台上以极度简单的方式加载和展示图片.Glide是一个快速高效的Androi ...
- Web基础和servlet基础
TomCat的目录结构 Bin:脚本目录(存放启动.关闭这些命令) Conf:存放配置文件的目录 Lib:存放jar包 Logs: 存放日志文件 Temp: 临时文件 Webapps: 项目发布目录 ...