POJ1988(Cube Stacking)--并查集
题目链接:http://poj.org/problem?id=1988
#include<iostream>
#include<stdio.h>
#include<cstring>
#include<cmath>
#include<vector>
#include<stack>
#include<map>
#include<set>
#include<list>
#include<queue>
#include<string>
#include<algorithm>
#include<iomanip>
using namespace std; struct node
{
int parent;
int date;
}; int * total;
int * under; class DisJoinSet
{
protected:
int n; node * tree;
public:
DisJoinSet(int n);
~DisJoinSet();
void Init();
int Find(int x);
void Union(int x,int y);
}; DisJoinSet::DisJoinSet(int n)
{
this->n = n;
tree = new node[n+];
total = new int[n+];
under = new int[n+];
Init();
}
DisJoinSet::~DisJoinSet()
{
delete[] under;
delete[] total;
delete[] tree;
} void DisJoinSet::Init()
{
for(int i = ;i <= n ;i ++)
{
tree[i].date = i;
tree[i].parent = i;
total[i] = ;
under[i] = ;
}
}
int DisJoinSet::Find(int x)
{
//int temp = tree[x].parent;
if(x != tree[x].parent)
{
int par = Find(tree[x].parent);
under[x] += under[tree[x].parent];//把父亲结点下面的个数加到自己头上
tree[x].parent = par;
return tree[x].parent;
}
else
{
return x;
}
} void DisJoinSet::Union(int x,int y)
{
int pa = Find(x);
int pb = Find(y);
if(pa == pb)return ;
else
{
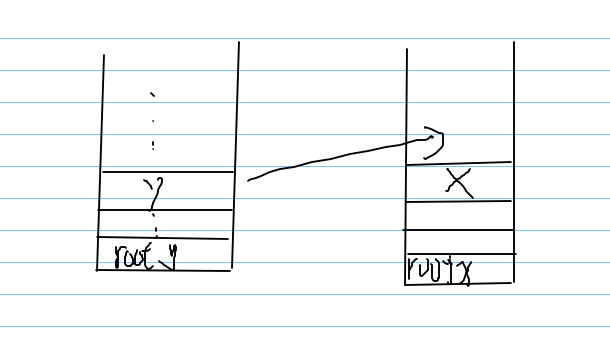
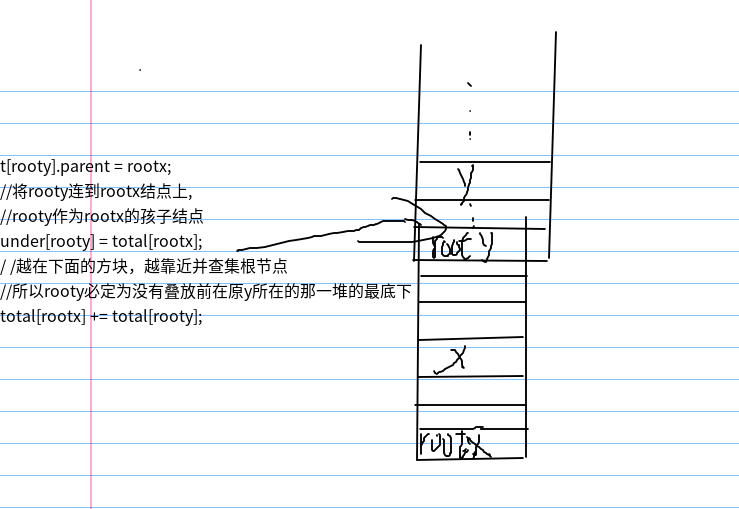
tree[pa].parent = pb;//x的根变为y的根 即把x所在的堆放在y所在的堆上面
under[pa] = total[pb];//pa下的数量即原来y所在栈里的元素total
total[pb] += total[pa];//更新y的totoal
}
} int main()
{
int p;
while(scanf("%d",&p) != EOF)
{
if(p == )break;
DisJoinSet dis(p);
char s1[];
for(int i = ;i < p ;i++)
{ int s2;
int s3;
scanf("%s",s1);
if(s1[] == 'M')
{
scanf("%d%d",&s2,&s3);
int pa = dis.Find(s2);
int pb = dis.Find(s3);
if(pa != pb)
{
dis.Union(s2,s3);
}
}
if(s1[] == 'C')
{
scanf("%d",&s2);
dis.Find(s2);
cout<<under[s2]<<endl;
}
}
dis.~DisJoinSet();
}
return ;
}
POJ1988(Cube Stacking)--并查集的更多相关文章
- poj.1988.Cube Stacking(并查集)
Cube Stacking Time Limit:2000MS Memory Limit:30000KB 64bit IO Format:%I64d & %I64u Submi ...
- poj1988 Cube Stacking 带权并查集
题目链接:http://poj.org/problem?id=1988 题意:有n个方块,编号为1-n,现在存在两种操作: M i j 将编号为i的方块所在的那一堆方块移到编号为j的方块所在的那 ...
- POJ1988 Cube Stacking 【并查集】
题目链接:http://poj.org/problem?id=1988 这题是教练在ACM算法课上讲的一道题,当时有地方没想明白,现在彻底弄懂了. 题目大意:n代表有n个石头,M a, b代表将a石头 ...
- poj1988 Cube Stacking(并查集
题目地址:http://poj.org/problem?id=1988 题意:共n个数,p个操作.输入p.有两个操作M和C.M x y表示把x所在的栈放到y所在的栈上(比如M 2 6:[2 4]放到[ ...
- poj1988 Cube Stacking
并查集的高效之处在于路径压缩和延迟更新. 在本题中需要额外维护子树的规模以及当前子树节点到跟的距离两个数组. 由于一个新的数必然是两棵树拼接而成,对于子树规模的更新直接相加即可, 对于节点到跟的距离: ...
- POJ1988 Cube stacking(非递归)
n有N(N<=30,000)堆方块,开始每堆都是一个方块.方块编号1 – N. 有两种操作: nM x y : 表示把方块x所在的堆,拿起来叠放到y所在的堆上. nC x : 问方块x下面有多少 ...
- POJ 1988 Cube Stacking(并查集+路径压缩)
题目链接:id=1988">POJ 1988 Cube Stacking 并查集的题目 [题目大意] 有n个元素,開始每一个元素自己 一栈.有两种操作,将含有元素x的栈放在含有y的栈的 ...
- bzoj3376/poj1988[Usaco2004 Open]Cube Stacking 方块游戏 — 带权并查集
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id=3376 题目大意: 编号为1到n的n(1≤n≤30000)个方块正放在地上.每个构成一个立方 ...
- POJ 1988 Cube Stacking( 带权并查集 )*
POJ 1988 Cube Stacking( 带权并查集 ) 非常棒的一道题!借鉴"找回失去的"博客 链接:传送门 题意: P次查询,每次查询有两种: M x y 将包含x的集合 ...
随机推荐
- vue项目中 favicon.ico不能正确显示的问题
方法一:修改index.html文件 <link rel="shortcut icon" type="image/x-icon" href="f ...
- openwrt环境中某个运行在host端的软件如何安装到openwrt的$(STAGING_DIR_HOST)/bin下
可参考示例:见'git grep host-build.mk package/{system,utils}'
- SQL-W3School-函数:SQL SUM() 函数
ylbtech-SQL-W3School-函数:SQL SUM() 函数 1.返回顶部 1. SUM() 函数 SUM 函数返回数值列的总数(总额). SQL SUM() 语法 SELECT SUM( ...
- myadmin不需要路劲提权之法
//觉得很典型的案例,就转载过来了.很多时候phpmyadmin都需要路劲才能写shell.否则拿到了myadmin也是无奈. 查看mysql版本 select version(); 版本是5.1 大 ...
- ELK 二进制安装并收集nginx日志
对于日志来说,最常见的需求就是收集.存储.查询.展示,开源社区正好有相对应的开源项目:logstash(收集).elasticsearch(存储+搜索).kibana(展示),我们将这三个组合起来的技 ...
- 阶段5 3.微服务项目【学成在线】_day09 课程预览 Eureka Feign_03-Eureka注册中心-搭建Eureka高可用环境
1.3.2.2 高可用环境搭建 Eureka Server 高可用环境需要部署两个Eureka server,它们互相向对方注册.如果在本机启动两个Eureka需要 注意两个Eureka Server ...
- kafka和zookeeper的配置文件优化配置
zookeeper的配置 日志自动清理这两个参数都是在zoo.cfg中配置的: autopurge.purgeInterval 这个参数指定了清理频率,单位是小时,需要填写一个1或更大的整数,默 ...
- Python基于正则表达式实现文件内容替换的方法
Python基于正则表达式实现文件内容替换的方法 本文实例讲述了Python基于正则表达式实现文件内容替换的方法.分享给大家供大家参考,具体如下: 最近因为有一个项目需要从普通的服务器移植到SAE,而 ...
- .net mvc网站集成adfs(ws-fed协议)
网站地址(本地开发测试):https://localhost:9000 第一步,adfs配置 配置要声明颁发策略(adfs要发送给网站的声明) 选择刚添加的依赖方信任,编辑颁发策略 配置完成 第二步, ...
- python:解析requests返回的response(json格式)
import requests, json r = requests.get('http://192.168.207.160:9000/api/qualitygates/project_status? ...