正确理解这四个重要且容易混乱的知识点:异步,同步,阻塞,非阻塞,5种IO模型
本文讨论的背景是Linux环境下的network IO,同步IO和异步IO,阻塞IO和非阻塞IO分别是什么
概念说明
在进行解释之前,首先要说明几个概念:
- 用户空间和内核空间
- 进程切换
- 进程的阻塞
- 文件描述符
- 缓存 I/O
用户空间与内核空间
现在操作系统都是采用虚拟存储器,那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为4G(2的32次方)。操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操心系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。针对linux操作系统而言,将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF),供内核使用,称为内核空间,而将较低的3G字节(从虚拟地址0x00000000到0xBFFFFFFF),供各个进程使用,称为用户空间。
进程切换
为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行。这种行为被称为进程切换。因此可以说,任何进程都是在操作系统内核的支持下运行的,是与内核紧密相关的。
从一个进程的运行转到另一个进程上运行,这个过程中经过下面这些变化:
1. 保存处理机上下文,包括程序计数器和其他寄存器。
2. 更新PCB信息。
3. 把进程的PCB移入相应的队列,如就绪、在某事件阻塞等队列。
4. 选择另一个进程执行,并更新其PCB。
5. 更新内存管理的数据结构。
6. 恢复处理机上下文。
进程的阻塞
正在执行的进程,由于期待的某些事件未发生,如请求系统资源失败、等待某种操作的完成、新数据尚未到达或无新工作做等,则由系统自动执行阻塞原语(Block),使自己由运行状态变为阻塞状态。可见,进程的阻塞是进程自身的一种主动行为,也因此只有处于运行态的进程(获得CPU),才可能将其转为阻塞状态。当进程进入阻塞状态,是不占用CPU资源的。
文件描述符fd
文件描述符(File descriptor)是计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。
文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统。
缓存 I/O
缓存 I/O 又被称作标准 I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。在 Linux 的缓存 I/O 机制中,操作系统会将 I/O 的数据缓存在文件系统的页缓存( page cache )中,也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。
缓存 I/O 的缺点:
数据在传输过程中需要在应用程序地址空间和内核进行多次数据拷贝操作,这些数据拷贝操作所带来的 CPU 以及内存开销是非常大的。
五种IO模型
在一次IO访问中(以read举例)
1.数据会先被拷贝到操作系统内核的缓冲区中
2.然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间
所以说,当一个read操作发生时,它会经历两个阶段:
1. 等待数据准备 (Waiting for the data to be ready)
2. 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
正式因为这两个阶段,linux系统产生了下面五种网络模式的方案。
- 阻塞 I/O(blocking IO)
- 非阻塞 I/O(nonblocking IO)
- I/O 多路复用( IO multiplexing)
- 信号驱动 I/O( signal driven IO)
- 异步 I/O(asynchronous IO)
注:由于signal driven IO在实际中并不常用,所以我这只提及剩下的四种IO Model。
阻塞 I/O(blocking IO)
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
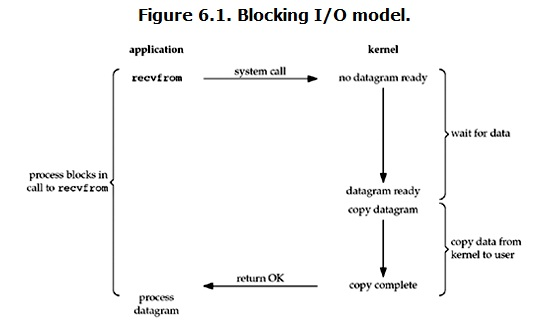
当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据(对于网络IO来说,很多时候数据在一开始还没有到达。比如,还没有收到一个完整的UDP包。这个时候kernel就要等待足够的数据到来)。这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区中是需要一个过程的。而在用户进程这边,整个进程会被阻塞(当然,是进程自己选择的阻塞)。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
所以,阻塞IO的特点是“直到用户进程内存有数据之前都阻塞”
优点:
阻塞式I/O很容易上手,一般程序按照read-process的顺序进行处理就好。通常来说我们编写的第一个TCP的C/S程序就是阻塞式I/O模型的。并且该模型定位错误,在阻塞时整个进程将被挂起,基本不会占用CPU资源。
缺点:
该模型的缺点也十分明显。作为服务器,需要处理同时多个的套接字,使用该模型对具有多个的客户端并发的场景时就显得力不从心。
当然也有补救方法,我们使用多线程技术来弥补这个缺陷。但是多线程在具有大量连接时,多线程技术带来的资源消耗也不容小看:
如果我们现在有1000个连接时,就需要开启1000个线程来处理这些连接,于是就会出现下面的情况
- 线程有内存开销,假设每个线程需要512K的存放栈,那么1000个连接就需要月512M的内存。当并发量高的时候,这样的内存开销是无法接受的。
- 线程切换有CPU开销,这个CPU开销体现在上下文切换上,如果线程数越多,那么大多数CPU时间都用于上下文切换,这样每个线程的时间槽会非常短,CPU真正处理数据的时间就会少了非常多。
非阻塞 I/O(nonblocking IO)
linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:
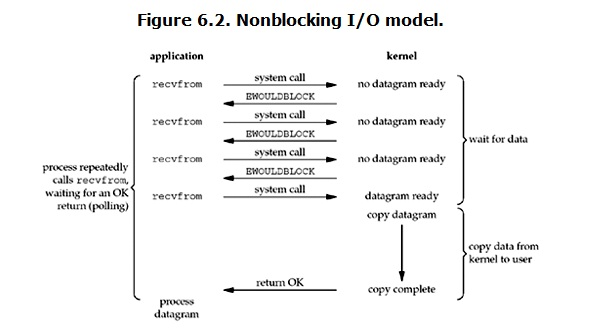
当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。
所以,非阻塞IO的特点是“在kernel还准备数据的情况下会立刻返回,用户进程需要不断的主动询问kernel数据好了没有”
非阻塞式I/O的优缺点
优点:
这种I/O方式也有明显的优势,即不会阻塞在内核的等待数据过程,每次发起的I/O请求可以立即返回,不用阻塞等待。在数据量收发不均,等待时间随机性极强的情况下比较常用。
缺点
轮询这一个特征就已近暴露了这个I/O模型的缺点。轮询将会不断地询问内核,这将占用大量的CPU时间,系统资源利用率较低。同时,该模型也不便于使用,需要编写复杂的代码。
I/O 多路复用( IO multiplexing)
在出现大量的链接时,使用多线程+阻塞I/O的编程模型会占用大量的内存。那么I/O复用技术在内存占用方面,就有着很好的控制。
当前的高性能反向代理服务器Nginx使用的就是I/O复用模型(epoll),它以高性能和低资源消耗著称,在大规模并发上也有着很好的表现。
IO multiplexing就是我们说的select,poll,epoll,select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。
它的基本原理就是select,poll,epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。
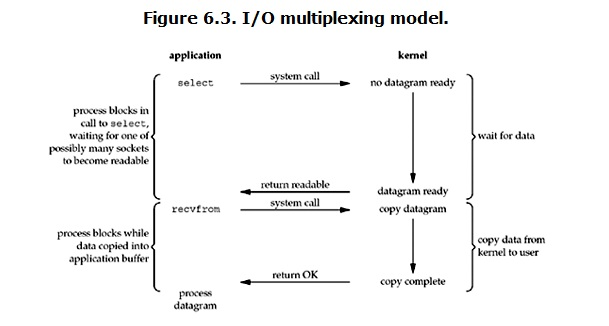
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
所以,I/O 多路复用的特点是“通过一种机制一个进程能同时等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,select()函数就可以返回”
I/O复用模型的优缺点
优点
I/O复用技术的优势在于,只需要使用一个线程就可以管理多个connection,系统不需要建立新的进程或者线程,也不必维护这些线程和进程,所以它也是很大程度上减少了资源占用。
另外I/O复用技术还可以同时监听不同协议的套接字
缺点
在只处理连接数较小的场合,使用select的服务器不一定比多线程+阻塞I/O模型效率高,可能延迟更大,因为单个连接处理需要2次系统调用,占用时间会有增加。因为这里需要使用两个system call (select 和 recvfrom),而blocking IO只调用了一个system call (recvfrom)。
所以,如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。
信号驱动式 I/O(SIG IO)
当然你可能会想到使用信号这一机制来避免I/O时线程陷入阻塞状态。那么内核开发者怎么可能会想不到。那么我们来看看信号驱动式I/O模型的具体流程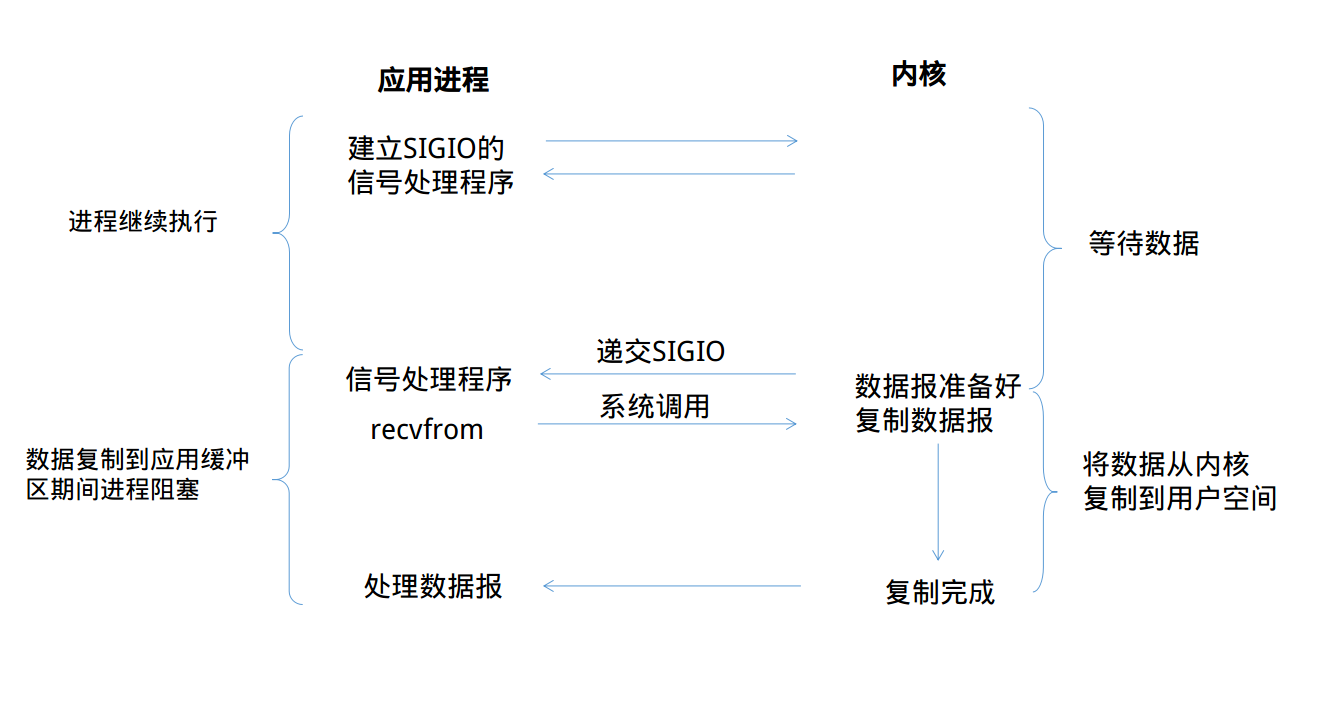
从上图可以看到,我们首先开启套接字的信号驱动式I/O功能,并通过sigaction系统调用来安装一个信号处理函数,我们进程不会被阻塞。
当数据报准备好读取时,内核就为该进程产生一个SIGIO信号,此时我们可以在信号处理函数中调用recvfrom读取数据报,并通知数据已经准备好,正在等待处理。
特点是”当数据已经在内核准备好时,触发信号,信号触发系统调用recvfrom接收数据到用户态“
信号驱动式I/O模型的优缺点
优点
很明显,我们的线程并没有在等待数据时被阻塞,可以提高资源的利用率
缺点
信号I/O在大量IO操作时可能会因为信号队列溢出导致没法通知——这个是一个非常严重的问题。
异步 I/O(asynchronous IO)
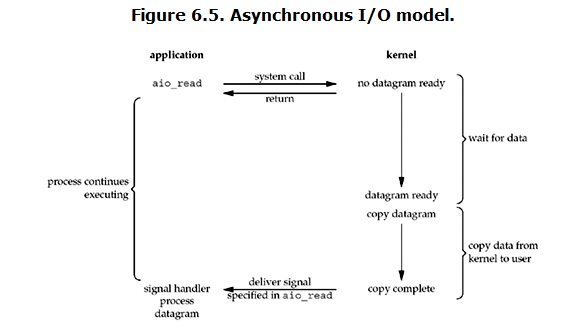
异步I/O,是由POSIX规范定义的。这个规范定义了一些函数,这些函数的工作机制是:告知内核启动某个操作,并让内核在整个操作完成后再通知我们。(包括将数据从内核复制到我们进程的缓冲区)
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。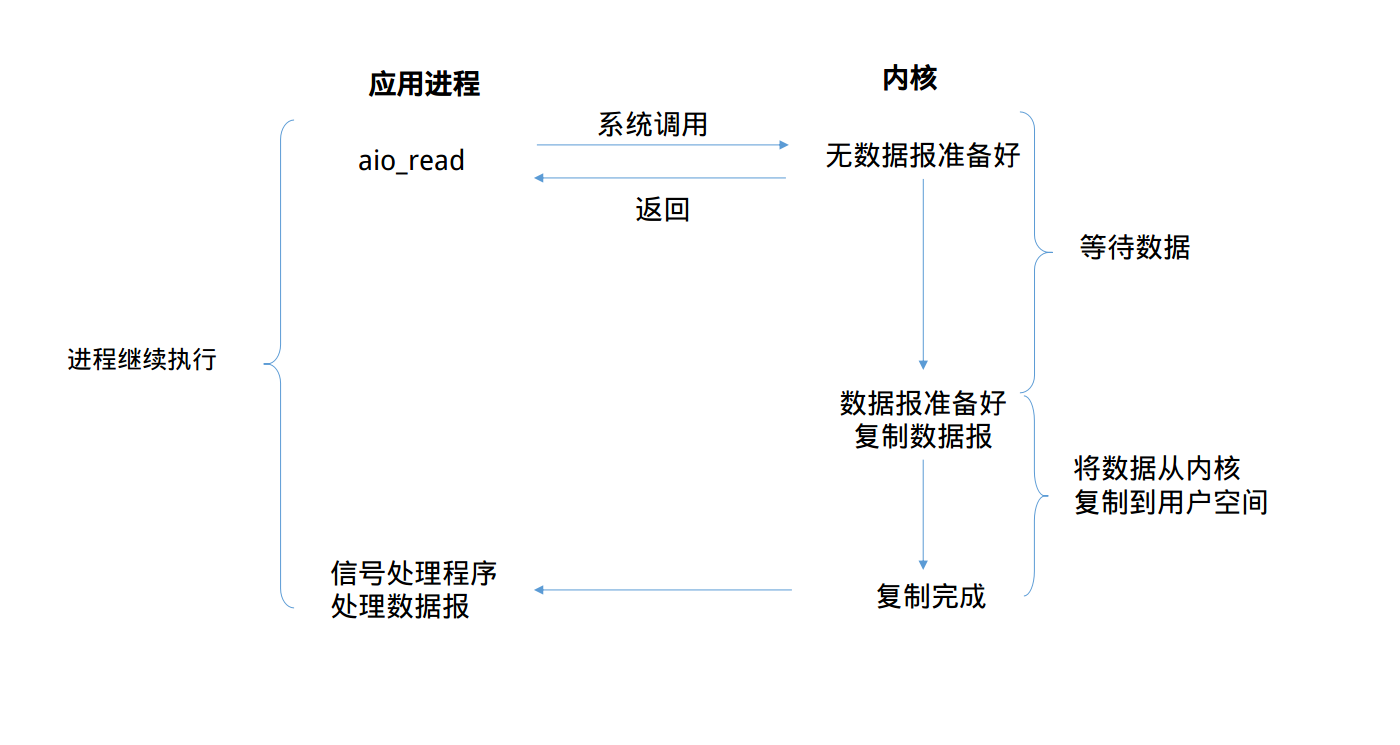

通过上面的图片,可以发现non-blocking IO和asynchronous IO的区别还是很明显的。在non-blocking IO中,虽然进程大部分时间都不会被block,但是它仍然要求进程去主动的check,并且当数据准备完成以后,也需要进程主动的再次调用recvfrom来将数据拷贝到用户内存。
而asynchronous IO则完全不同。它就像是用户进程将整个IO操作交给了他人(kernel)完成,然后他人做完后发信号通知。在此期间,用户进程不需要去检查IO操作的状态,也不需要主动的去拷贝数据。
异步I/O模型的优缺点
优点
全程没有阻塞,真正做到了异步
缺点
理想很美好,现实很骨感。现在的异步IO底层设施还不是很成熟(glibc 的 aio 有 bug , kernel 的 aio 只能以 O_DIRECT 方式做直接 IO),而epoll已经非常成熟了。
I/O 多路复用之select、poll、epoll
select,poll,epoll都是IO多路复用的机制。I/O多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
直接说下重点:select/poll的lO的效率会随着监视fd的数量的增长而下降。
而epoll不会,因为其原理不是轮询,而是通过每个fd定义的回调函数来实现的。只有就绪的fd才会执行回调函数
select
select 函数监视的文件描述符分3类,分别是writefds、readfds、和exceptfds。
调用后select函数会阻塞,直到有描述副就绪(有数据 可读、可写、或者有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。
当select函数返回后,可以 通过遍历fdset,来找到就绪的描述符。
优点:select目前几乎在所有的平台上支持,其良好跨平台支持。
缺点:在于单个进程能够监视的文件描述符的数量存在最大限制(在Linux上一般为1024,可以通过修改宏定义甚至重新编译内核的方式提升这一限制,但 是这样也会造成效率的降低)
这对 于连接数量比较大的服务器来说根本不能满足。虽然也可以选择多进程的解决方案( Apache就是这样实现的),不过虽然linux上面创建进程的代价比较小,但仍旧是不可忽视的,
加上进程间数据同步远比不上线程间同步的高效,所以也不是一种完美的方案。
poll
相比select,主要是把最大链接数提高了。
很少使用,主要是用于select到poll的过度阶段
从上面看,select和poll都需要在返回后,
通过遍历文件描述符来获取已经就绪的socket。事实上,同时连接的大量客户端在一时刻可能只有很少的处于就绪状态,因此随着监视的描述符数量的增长,其效率也会线性下降。
epoll
epoll是在2.6内核中提出的,是之前的select和poll的增强版本。相对于select和poll来说,epoll更加灵活,没有描述符限制。epoll使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。
select/poll工作机制:进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描。
epoll工作机制:epoll事先通过epoll_ctl()来注册一 个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait() 时便得到通知。(此处去掉了遍历文件描述符,而是通过监听回调的的机制)
优点:监视的描述符数量不受限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左 右,具体数目可以cat /proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。
在“功能”领域的异步与阻塞
我们在谈及ajax等技术时,最常提及的就是“异步非阻塞”更新。但这里的异步和阻塞指的是“功能”上而不是指socket层面上的
调用者的异步与同步
同步:就是我客户端(c端调用者)调用一个功能,该功能没有结束前,我(c端调用者)死等结果。
异步:就是我(c端调用者)调用一个功能,不需要知道该功能结果,该功能有结果后通知我(c端调用者)即回调通知。
同步/异步主要针对C端, 但是跟S端不是完全没有关系,同步/异步机制必须S端配合才能实现. 同步/异步是由c端自己控制, 但是S端是否阻塞/非阻塞, C端完全不需要关心.
被调用者的阻塞与非阻塞
阻塞:就是调用我(s端被调用者,函数),我(s端被调用者,函数)没有接收完数据或者没有得到结果之前,我不会返回。
非阻塞:就是调用我(s端被调用者,函数),我(s端被调用者,函数)立即返回,通过select通知调用者
正确理解这四个重要且容易混乱的知识点:异步,同步,阻塞,非阻塞,5种IO模型的更多相关文章
- 谈谈对不同I/O模型的理解 (阻塞/非阻塞IO,同步/异步IO)
一.关于I/O模型的问题 最近通过对ucore操作系统的学习,让我打开了操作系统内核这一黑盒子,与之前所学知识结合起来,解答了长久以来困扰我的关于I/O的一些问题. 1. 为什么redis能以单工作线 ...
- 图解四种 IO 模型
最近越来越认为,在讲解技术相关问题时,大白话固然很重要,通俗易懂,让人有想读下去的欲望.但几乎所有的事,都有两面性,在看到其带来好处时,不妨想想是否也引入了不好的地方. 例如在博客中,过于大白话的语言 ...
- (四)五种IO模型
基本概念 我们之前编写的套接字程序都是阻塞式的,其实这也是默认的形式.现在我们需要明确一些概念: 用户空间和内核空间 首先要明确,用户启动的应用程序在系统中以一个进程的形式存在,而无论对于网络数据还是 ...
- 理解同步,异步,阻塞,非阻塞,多路复用,事件驱动IO
以下是IO的一个基本过程 先理解一下用户空间和内核空间,系统为了保护内核数据,会将寻址空间分为用户空间和内核空间,32位机器为例,高1G字节作为内核空间,低3G字节作为用户空间.当用户程序读取数据的时 ...
- JAVA 中BIO,NIO,AIO的理解以及 同步 异步 阻塞 非阻塞
在高性能的IO体系设计中,有几个名词概念常常会使我们感到迷惑不解.具体如下: 序号 问题 1 什么是同步? 2 什么是异步? 3 什么是阻塞? 4 什么是非阻塞? 5 什么是同步阻塞? 6 什么是同步 ...
- Netty基础系列(2) --彻底理解阻塞非阻塞与同步异步的区别
引言 在进行I/O学习的时候,阻塞和非阻塞,同步和异步这几个概念常常被提及,但是很多人对这几个概念一直很模糊.要想学好Netty,这几个概念必须要掌握清楚. 同步和异步 同步与异步的区别在于,异步基于 ...
- 四种IO模型
四种 IO 模型: 首先需要明确,IO发生在 用户进程 与 操作系统 之间.可以是客户端IO也可以是服务器端IO. 阻塞IO(blocking IO): 在linux中,默认情况下 ...
- 阻塞I/O、非阻塞I/O和I/O多路复用、怎样理解阻塞非阻塞与同步异步的区别?
“阻塞”与"非阻塞"与"同步"与“异步"不能简单的从字面理解,提供一个从分布式系统角度的回答.1.同步与异步 同步和异步关注的是消息通信机制 (syn ...
- 🍛 餐厅吃饭版理解 IO 模型:阻塞 / 非阻塞 / IO 复用 / 信号驱动 / 异步
IO 概念 一个基本的 IO,它会涉及到两个系统对象,一个是调用这个 IO 的进程对象,另一个就是系统内核 (kernel).当一个 read 操作发生时,它会经历两个阶段: 通过 read 系统调用 ...
随机推荐
- oc 执行shell 脚本
-(id) InvokingShellScriptAtPath :(NSString*) shellScriptPath { NSTask *shellTask = [[NSTask alloc]in ...
- [ML] Machine Learning in the Common Infrastructure ecosystem
一.CogNet架构 下图,可见Kafka的作用. Partial code: Machine Learning in the Common Infrastructure ecosystem Rele ...
- [ZT]Enhancement-01
Enhancement(1)--BTEs 最近一个同事碰到一个FI的增强,要用BTEs实现,我也是第一次接触到这种增强,所以跟着他一起做了一下.写一个这方面的小节. BTEs(Business ...
- Delphi使用TADOQuery的RowsAffected属性时需要注意的一个点
测试环境是:Delphi 6.Oracle.PLSQL 先创建一个模拟测试的数据表,并且添加几条模拟的数据 create table practice(uno varchar(8), uname va ...
- jenkins常用插件安装
1.常用jenkins插件 插件相关下载地址:http://updates.jenkins-ci.org/download/plugins/ git.hpi git-client.hpi gitlab ...
- jenkins中使用shell脚本必须切换jenkins用户
https://blog.csdn.net/cdnight/article/details/81078191 安装这篇解决的 正确使用脚本的方式: 1.脚本必须使用jenknins用户,且所有命令必须 ...
- 树莓派搭建bt下载机、即是安装transmission
Transmission是一种BitTorrent客户端, 安装:sudo apt-get install transmission-daemon 给用户授权:sudo usermod -a -G p ...
- Nmap之用法
简介 Nmap是一款开源免费的网络发现(Network Discovery)和安全审计(Security Auditing)工具.软件名字Nmap是Network Mapper的简称. 功能架构图 N ...
- web代码审计题
@题名:code i春秋https://www.ichunqiu.com/battalion wp:https://www.ichunqiu.com/writeup/detail/4139
- 【VS开发】VSTO 学习笔记(十)Office 2010 Ribbon开发
微软的Office系列办公套件从Office 2007开始首次引入了Ribbon导航菜单模式,其将一系列相关的功能集成在一个个Ribbon中,便于集中管理.操作.这种Ribbon是高度可定制的,用户可 ...