HashMap 在高并发下引起的死循环
HashMap 基本实现(JDK 8 之前)
HashMap 通常会用一个指针数组(假设为 table[])来做分散所有的 key,当一个 key 被加入时,会通过 Hash 算法通过 key 算出这个数组的下标 i,然后就把这个 <key, value> 插到 table[i] 中,如果有两个不同的 key 被算在了同一个 i,那么就叫冲突,又叫碰撞,这样会在 table[i] 上形成一个链表
如果 table[] 的尺寸很小,比如只有 2 个,如果要放进 10 个 keys 的话,那么碰撞非常频繁,于是一个 O(1) 的查找算法,就变成了链表遍历,性能变成了 O(n),这是 Hash 表的缺陷
所以,Hash 表的尺寸和容量非常的重要。一般来说,Hash 表这个容器当有数据要插入时,都会检查容量有没有超过设定的 threshold,如果超过,需要增大 Hash 表的尺寸,但是这样一来,整个 Hash 表里的元素都需要被重算一遍。这叫 rehash,这个成本相当的大
HashMap 的 rehash 源代码
Put 一个 Key, Value 对到 Hash 表中:
public V put(K key, V value) {
......
// 计算 Hash 值
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
// 如果该 key 已被插入,则替换掉旧的 value(链接操作)
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 该 key 不存在,需要增加一个结点
addEntry(hash, key, value, i);
return null;
}
检查容量是否超标
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
//查看当前的 size 是否超过了设定的阈值 threshold,如果超过,需要 resize
if (size++ >= threshold)
resize(2 * table.length);
}
新建一个更大尺寸的 hash 表,然后把数据从老的 Hash 表中迁移到新的 Hash 表中
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
......
// 创建一个新的 Hash Table
Entry[] newTable = new Entry[newCapacity];
// 将 Old Hash Table 上的数据迁移到 New Hash Table 上
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
迁移的源代码
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
//下面这段代码的意思是:
// 从OldTable里摘一个元素出来,然后放到NewTable中
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
该方法实现的机制就是将每个链表转化到新链表,并且链表中的位置发生反转,而这在多线程情况下是很容易造成链表回路,从而发生 get() 死循环。所以只要保证建新链时还是按照原来的顺序的话就不会产生循环(JDK 8 的改进)
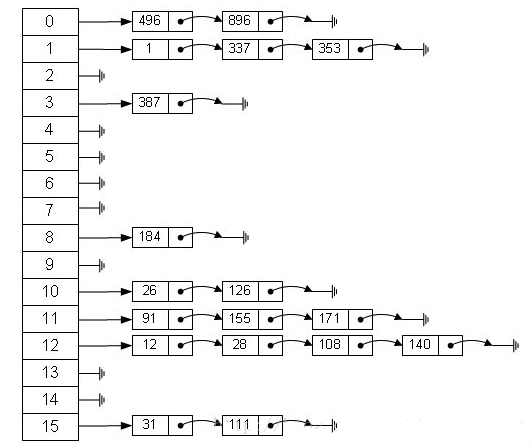
正常的 ReHash 的过程
- 假设我们的 hash 算法就是简单的用 key mod 一下表的大小(也就是数组的长度)
- 最上面的是 old hash 表,其中的 Hash 表的 size = 2,所以 key = 3, 7, 5,在 mod 2 以后都冲突在 table[1] 这里了
- 接下来的三个步骤是 Hash 表 resize 成 4,然后所有的 <key, value> 重新 rehash 的过程
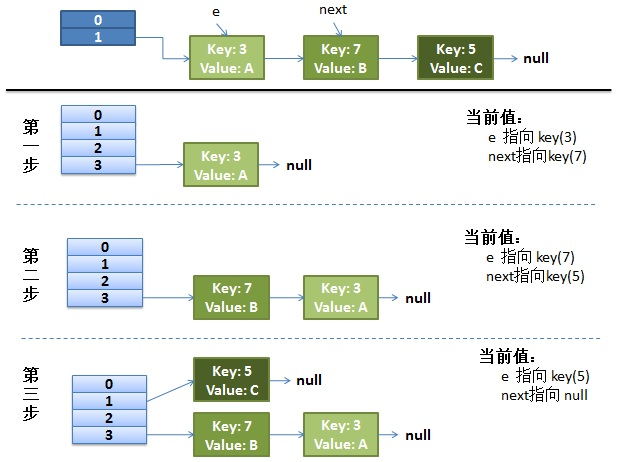
并发下的 Rehash
1)假设有两个线程
do {
Entry<K,V> next = e.next; // 假设线程一执行到这里就被调度挂起了
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
而线程二执行完成了。于是有下面的这个样子
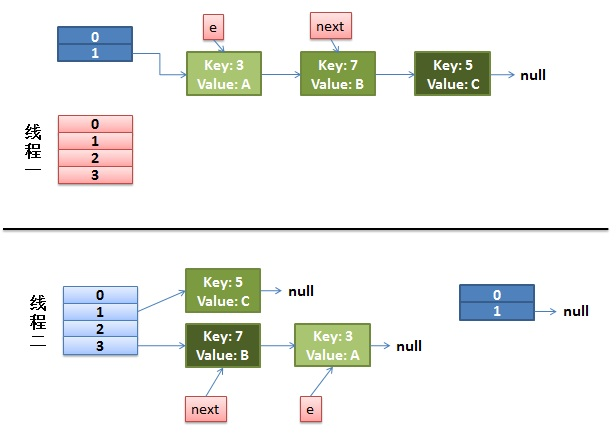
注意,因为 Thread1 的 e 指向了 key(3),而 next 指向了 key(7),其在线程二 rehash 后,指向了线程二重组后的链表。可以看到链表的顺序被反转
2)线程一被调度回来执行
- 先是执行 newTalbe[i] = e;
- 然后是 e = next,导致了 e 指向了 key(7)
- 而下一次循环的 next = e.next 导致了 next 指向了 key(3)
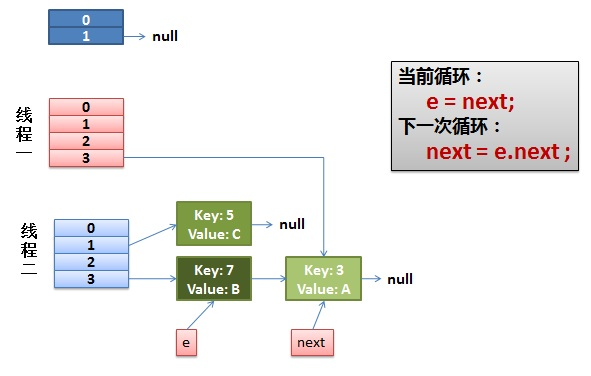
3)线程一接着工作。把 key(7) 摘下来,放到 newTable[i] 的第一个,然后把 e 和 next 往下移
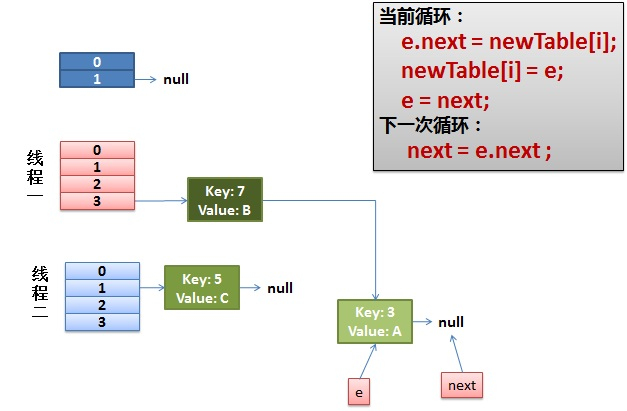
4)环形链接出现
e.next = newTable[i] 导致 key(3).next 指向了 key(7)
此时的 key(7).next 已经指向了 key(3), 环形链表就这样出现了
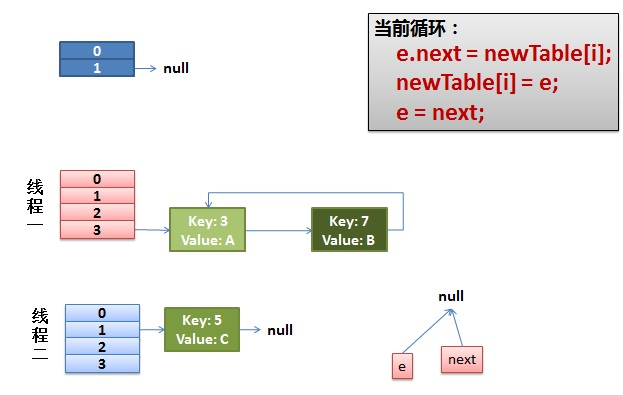
JDK 8 的改进
JDK 8 中采用的是位桶 + 链表/红黑树的方式,当某个位桶的链表的长度超过 8 的时候,这个链表就将转换成红黑树
HashMap 不会因为多线程 put 导致死循环(JDK 8 用 head 和 tail 来保证链表的顺序和之前一样;JDK 7 rehash 会倒置链表元素),但是还会有数据丢失等弊端(并发本身的问题)。因此多线程情况下还是建议使用 ConcurrentHashMap
为什么线程不安全
HashMap 在并发时可能出现的问题主要是两方面:
如果多个线程同时使用 put 方法添加元素,而且假设正好存在两个 put 的 key 发生了碰撞(根据 hash 值计算的 bucket 一样),那么根据 HashMap 的实现,这两个 key 会添加到数组的同一个位置,这样最终就会发生其中一个线程 put 的数据被覆盖
如果多个线程同时检测到元素个数超过数组大小 * loadFactor,这样就会发生多个线程同时对 Node 数组进行扩容,都在重新计算元素位置以及复制数据,但是最终只有一个线程扩容后的数组会赋给 table,也就是说其他线程的都会丢失,并且各自线程 put 的数据也丢失
作者:杰哥长得帅
链接:https://www.jianshu.com/p/619a8efcf589
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
HashMap 在高并发下引起的死循环的更多相关文章
- HashMap在高并发下引起的死循环
HashMap事实上并非线程安全的,在高并发的情况下,是非常可能发生死循环的,由此造成CPU 100%,这是非常可怕的.所以在多线程的情况下,用HashMap是非常不妥当的行为,应採用线程安全类Con ...
- HashMap在高并发下如果没有处理线程安全会有怎样的安全隐患,具体表现是什么
Hashmap在并发环境下,可能出现的问题: 1.多线程put时可能会导致get无限循环,具体表现为CPU使用率100%: 原因:在向HashMap put元素时,会检查HashMap的容量是否足够, ...
- HashMap高并发下存在的问题
原文链接:https://blog.csdn.net/bjwfm2011/article/details/81076736 1.什么是HashMap? HashMap底层原理 HashMap是存储键值 ...
- 对HashMap的理解(二):高并发下的HashMap
在分析hashmap高并发场景之前,我们要先搞清楚ReHash这个概念.ReHash是HashMap在扩容时的一个步骤.HashMap的容量是有限的.当经过多次元素插入,使得HashMap达到一定饱和 ...
- JDK1.7 ConcurrentHashMap--解决高并发下的HashMap使用问题
高并发下也可以使用HashTable .Collections.synchronizedMap因为他们是线程安全的,但是却牺牲了性能,无论是读操作.写操作都是给整个集合加锁,导致同一时间内其他操作均为 ...
- JDK1.7 高并发下的HashMap
HashMap的容量是有限的.当经过多次元素插入,使得HashMap达到一定饱和度时,Key映射位置发生冲突的几率会逐渐提高. 这时候,HashMap需要扩展它的长度,也就是进行Resize. 影响发 ...
- 高并发下,HashMap会产生哪些问题?
HashMap在高并发环境下会产生的问题 HashMap其实并不是线程安全的,在高并发的情况下,会产生并发引起的问题: 比如: HashMap死循环,造成CPU100%负载 触发fail-fast 下 ...
- 高并发下的Java数据结构(List、Set、Map、Queue)
由于并行程序与串行程序的不同特点,适用于串行程序的一些数据结构可能无法直接在并发环境下正常工作,这是因为这些数据结构不是线程安全的.本节将着重介绍一些可以用于多线程环境的数据结构,如并发List.并发 ...
- Java高并发下多线程编程
1.创建线程 Java中创建线程主要有三种方式: 继承Thread类创建线程类: 定义Thread类的子类,并重写该类的run方法,该run方法的方法体就代表了线程要完成的任务.因此也把run方法称为 ...
随机推荐
- vue实现一个评论列表
<!DOCTYPE html> <html> <head> <title>简易评论列表</title> <meta charset=& ...
- linux配置sftp简单过程
首先疑惑是, 他需要的是上级的目录权限必须为root, 这点我有点不明白 环境是centos7.6 ssh 首先开整/etc/ssh/sshd_config # override default o ...
- IP地址简介及Linux网络管理工具
IP地址简介 IP地址又叫网络地址也称逻辑地址,由32位2进制数组成,分4段每段8位,由10进制数表示,范围0~,段与段之间用点隔开采用点分十进制的表示法,在一个网络中ip地址是唯一的,IP地址最主要 ...
- c++混合使用不同标准编译潜在的问题
最近项目使用的C++的版本到C++11了,但是由于有些静态库(.a)没有源码,因此链接时还在使用非C++11版本的库文件.目前跑了几天,似乎是没出什么问题,但是我还是想说一下这样做有哪些潜在的风险. ...
- ERROR: Cannot uninstall 'wrapt'. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall.
pip install imagededup 时,报错:Cannot uninstall 'wrapt'. It is a distutils installed project and thus w ...
- 提速1000倍,预测延迟少于1ms,百度飞桨发布基于ERNIE的语义理解开发套件
提速1000倍,预测延迟少于1ms,百度飞桨发布基于ERNIE的语义理解开发套件 11月5日,在『WAVE Summit+』2019 深度学习开发者秋季峰会上,百度对外发布基于 ERNIE 的语义理解 ...
- P2746 P2812 [USACO5.3]校园网Network of Schools[SCC缩点]
题目描述 一些学校连入一个电脑网络.那些学校已订立了协议:每个学校都会给其它的一些学校分发软件(称作"接受学校").注意即使 B 在 A 学校的分发列表中, A 也不一定在 B 学 ...
- webpack 配置react脚手架(三):eslint 及优化
首先谨记 eslint的官网: http://eslint.cn/ 1 安装eslint npm i eslint -D 2.在根目录下新建文件 .eslintrc { "extends ...
- Spring Boot 项目在 IntelliJ IDEA 中配置 DevTools 实现热部署(macOS 系统)
要配置的内容: 1.Preference -> Build, Execution, Deployment -> Complier -> Build project automatic ...
- 哇!吐槽!oh shit
一个jsp写了5000行,我尼玛醉了,看晕了-2017年10月12日10:19:40