最简单之安装hadoop单机版
一,hadoop下载
(前提:先安装java环境)
下载地址:http://hadoop.apache.org/releases.html(注意是binary文件,source那个是源码)
二,解压配置
tar xzvf hadoop-2.10..tar.gz
[root@--- hadoop-2.10.]# echo $JAVA_HOME
/usr/java/jdk1..0_231-amd64
[root@--- hadoop-2.10.]# vi /home/hadoop-2.10./etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1..0_231-amd64
[root@192-168-22-220 hadoop-2.10.0]# vi /home/hadoop-2.10.0/etc/hadoop/yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_231-amd64
[root@--- hadoop-2.10.]# hostname
---
[root@--- ~]# mkdir /home/hadoop-2.10./tmp
[root@--- ~]# vi /home/hadoop-2.10./etc/hadoop/core-site.xml
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop-2.10./tmp</value>
</property>
</configuration>
[root@--- hadoop-2.10.]# mkdir /home/hadoop-2.10./hdfs
[root@--- hadoop-2.10.]# mkdir /home/hadoop-2.10./hdfs/name
[root@--- hadoop-2.10.]# mkdir /home/hadoop-2.10./hdfs/data
[root@--- hadoop-2.10.]# vi /home/hadoop-2.10./etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/home/hadoop-2.10./hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property> <property>
<name>dfs.data.dir</name>
<value>/home/hadoop-2.10./hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property> <property>
<name>dfs.replication</name>
<value></value>
<description>副本个数,配置默认是3,应小于datanode机器数量</description>
</property>
</configuration>
[root@--- hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@--- hadoop]# vi /home/hadoop-2.10./etc/hadoop/mapred-site.xml <configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
[root@--- hadoop]#vi /home/hadoop-2.10./etc/hadoop/yarn-site.xml
<configuration>
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
三,环境变量
vi /etc/profile
export HADOOP_HOME=/home/hadoop-2.10.0
export PATH=$PATH:$HADOOP_HOME/bin
source /etc/profile
四,免密登陆
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
chmod ~/.ssh/authorized_keys
五,第一次先格式化hdfs
[root@--- hadoop-2.10.]# pwd
/home/hadoop-2.10.
[root@--- hadoop-2.10.]# ./bin/hdfs namenode -format #或者 hadoop namenode -format
六,启动hdfs
./sbin/start-dfs.sh #启动命令
./sbin/stop-dfs.sh #停止命令
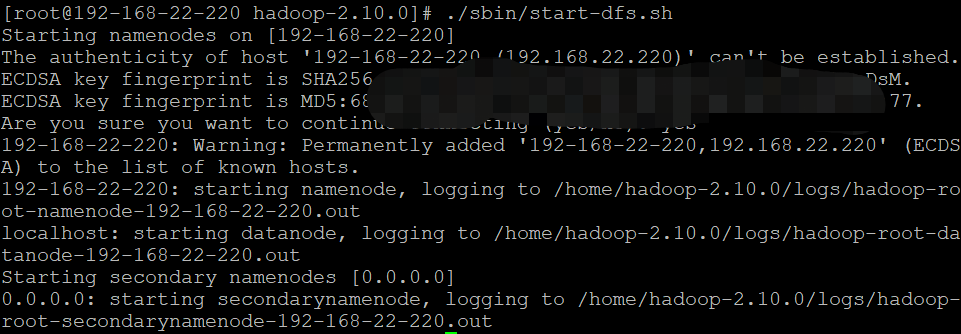
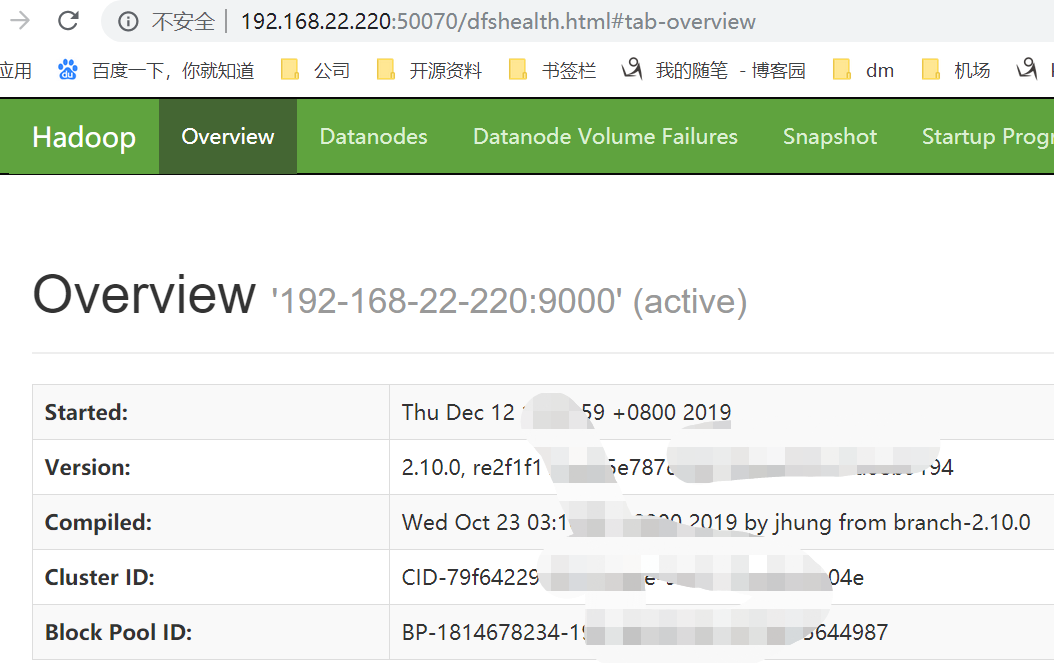
七,启动yarn
[root@--- hadoop-2.10.]# pwd
/home/hadoop-2.10.
[root@--- hadoop-2.10.]# ./sbin/start-yarn.sh # 关闭命令:./sbin/stop-yarn.sh
starting yarn daemons
resourcemanager running as process . Stop it first.
localhost: starting nodemanager, logging to /home/hadoop-2.10./logs/yarn-root-n
odemanager----.out
[root@--- hadoop-2.10.]# jps
NameNode
ResourceManager
Jps
DataNode
SecondaryNameNode
NodeManager
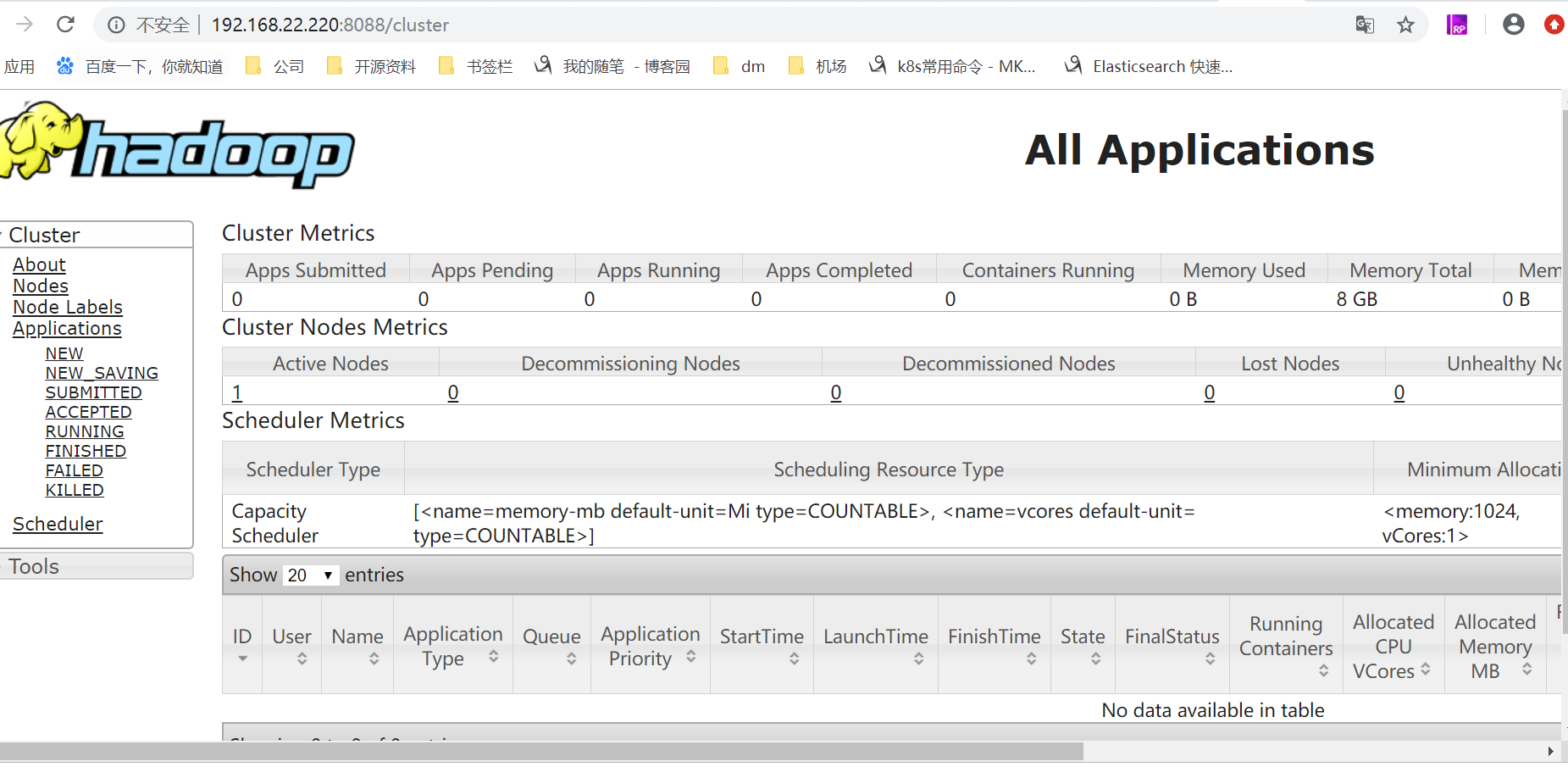
八,批量启动和停止
[root@--- hadoop-2.10.]# ./sbin/stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [---]
---: stopping namenode
localhost: stopping datanode
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: stopping secondarynamenode
stopping yarn daemons
stopping resourcemanager
localhost: stopping nodemanager
localhost: nodemanager did not stop gracefully after seconds: killing with kill -
no proxyserver to stop
[root@--- hadoop-2.10.]# ./sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [---]
---: starting namenode, logging to /home/hadoop-2.10./logs/hadoop-root-namenode----.out
localhost: starting datanode, logging to /home/hadoop-2.10./logs/hadoop-root-datanode----.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /home/hadoop-2.10./logs/hadoop-root-secondarynamenode----.out
starting yarn daemons
starting resourcemanager, logging to /home/hadoop-2.10./logs/yarn-root-resourcemanager----.out
localhost: starting nodemanager, logging to /home/hadoop-2.10./logs/yarn-root-nodemanager----.out
最简单之安装hadoop单机版的更多相关文章
- ambari快速安装hadoop
资源下载http://www.cnblogs.com/bfmq/p/6027202.html 大家都知道hadoop包含很多的组件,虽然很多都是下载后解压简单配置下就可以用的,但是还是耐不住我是一个懒 ...
- Hadoop单机版安装,配置,运行
Hadoop是最近非常流行的东东啦,但是乍一看都觉得是集群的东东,其实在单机版上安装Hadoop也是可以的,并且安装好以后可以很方便的进行程序的调试,调试好程序以后再丢到集群中,放心的算吧,呵呵.. ...
- hadoop单机版安装及基本功能演示
本文所使用的Linux发行版本为:CentOS Linux release 7.4.1708 (Core) hadoop单机版安装 准备工作 创建用户 useradd -m hadoop passwd ...
- CentOS下安装hadoop
CentOS下安装hadoop 用户配置 添加用户 adduser hadoop passwd hadoop 权限配置 chmod u+w /etc/sudoers vi /etc/sudoers 在 ...
- Linux下安装Hadoop完全分布式(Ubuntu12.10)
Hadoop的安装非常简单,可以在官网上下载到最近的几个版本,最好使用稳定版.本例在3台机器集群安装.hadoop版本如下: 工具/原料 hadoop-0.20.2.tar.gz Ubuntu12.1 ...
- Ubuntu安装Hadoop与Spark
更新apt 用 hadoop 用户登录后,我们先更新一下 apt,后续我们使用 apt 安装软件,如果没更新可能有一些软件安装不了.按 ctrl+alt+t 打开终端窗口,执行如下命令: sudo a ...
- 在Ubuntu上单机安装Hadoop
最近大数据比较火,所以也想学习一下,所以在虚拟机安装Ubuntu Server,然后安装Hadoop. 以下是安装步骤: 1. 安装Java 如果是新机器,默认没有安装java,运行java –ver ...
- [Hadoop]如何安装Hadoop
Hadoop是一个分布式系统基础架构,他使得用户可以在不了解分布式底层细节的情况下,开发分布式程序. Hadoop的重要核心:HDFS和MapReduce.HDFS负责储存,MapReduce负责计算 ...
- Ubuntu 安装hadoop 伪分布式
一.安装JDK : http://www.cnblogs.com/E-star/p/4437788.html 二.配置SSH免密码登录1.安装所需软件 sudo apt-get ins ...
随机推荐
- USACO 1.3 Name That Number【暴搜】
裸的穷举搜索. 研究了好久怎么输入$dict.txt$,$USACO$好像对$freopen$的顺序还有要求? /* ID: Starry21 LANG: C++ TASK: namenum */ # ...
- 【并行计算-CUDA开发】#pragma unroll伪编译指令的使用
#pragma宏命令主要是改变编译器的编译行为,其他的参数网上资料比较多,我只想简单说下#pragma unroll的用法,因为网上的资料比较少,而且说的比较笼统,请看下面的一段代码 int main ...
- vue 基础介绍
0.MVVM 什么是MVVM?就是Model-View-ViewModel. ViewModel是Vue.js的核心,它是一个Vue实例. 1.基础示例 代码: <!DOCTYPE html&g ...
- python tarfile模块
TarFile类对于就是tar压缩包实例. 其由member块组成, member块则包括header块和data块. 每个member以TarInfo对象形式描述. 所以TarFile就是TarIn ...
- [bzoj3162]独钓寒江雪_树hash_树形dp
独钓寒江雪 题目链接:https://www.lydsy.com/JudgeOnline/problem.php?id=3162 题解: 首先,如果没有那个本质相同的限制这就是个傻逼题. 直接树形dp ...
- Oracle通过正则表达式分割字符串 REGEXP_SUBSTR
REGEXP_SUBSTR函数格式如下: function REGEXP_SUBSTR(string, pattern, position, occurrence, modifier) string ...
- 洛谷 P4198 楼房重建 题解
题面 首先你要知道题问的是什么:使用一种数据结构,动态地维护以1为起点地最长上升子序列(把楼房的高度转化成斜率地序列)的长度: 怎么做?线段树! 我们在线段树上维护两个东西:1.这个区间内斜率的最大值 ...
- 初遇PHP(一)
因为想给自己弄一个微信公众号,顺便提升一下自己,所以有了以下内容,本次学习的最终目标是能用php制作套微信公众号,然后转成Java.为什么要这么麻烦呢,其一是买的资料书是php的,其二是顺水推舟刚好可 ...
- nginx-consul-template
概述Consul-template 是 HashiCorp 基于 Consul 所提供的可扩展的工具,通过监听 Consul中的数据变化,动态地修改一些配置文件中地模板.常用于在 Nginx.HAPr ...
- 交替方向乘子法(ADMM)的原理和流程的白话总结
交替方向乘子法(ADMM)的原理和流程的白话总结 2018年08月27日 14:26:42 qauchangqingwei 阅读数 19925更多 分类专栏: 图像处理 作者:大大大的v链接:ht ...