spark教程(11)-sparkSQL 数据抽象
数据抽象
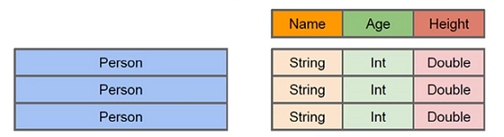
sparkSQL 的数据抽象是 DataFrame,df 相当于表格,它的每一行是一条信息,形成了一个 Row
Row
它是 sparkSQL 的一个抽象,用于表示一行数据,从表现形式上看,相当于一个 tuple 或者 表中的一行;
from pyspark.sql import Row ##### 创建 Row
#### method 1
row = Row(name="Alice", age=11)
print row # Row(age=11, name='Alice')
print row['name'], row['age'] # ('Alice', 11)
print row.name, row.age # ('Alice', 11)
print 'name' in row # True
print 'wrong_key' in row # False #### method 2
Person = Row("name", "age")
print Person # <Row(name, age)>
print 'name' in Person # True
print 'wrong_key' in Person # False
print Person("Alice", 11) # Row(name='Alice', age=11)
DataFrame (DF)
与 RDD 类似,df 也是分布式的数据容器,不同的是,df 更像一个 二维数据表,除了数据本身外,还包含了数据的结构信息,即 schema;
df 的 API 提供了更高层的关系操作,比函数式的 RDD API 更加友好;
df 的底层仍是 RDD,所以 df 也是惰性执行的,但值得注意的是,它比 RDD 性能更高;
问题来了:为什么底层实现是 RDD,却比 RDD 更快,不合常理啊
其实是这样的,因为 df 是由 spark 自己转换成 RDD 的,那么 spark 自然会用最合适的、最优化的方式转换成 RDD,因为它比任何人都清楚怎么才能更高效,
对比我们自己操作 RDD 去实现各种功能,大部分情况下我们的作法可能不是最优,自己玩不如作者玩,所以说 df 性能高于 RDD
举个简单例子:
data1 = sc.parallelize([('','a'), ('', 'b'), ('', 'c')])
data2 = sc.parallelize([('',''), ('', ''), ('', '')])
### 找到两个list中 key 为 1 的对应值的集合
## 自己写可能这么写
data1.join(data2).collect() # [('1', ('a', '1')), ('3', ('c', '3')), ('2', ('b', '2'))]
data1.join(data2).filter(lambda x: x[0] == '').collect() # [('1', ('a', '1'))]
## spark 可能这么写
data1.filter(lambda x: x[0] == '').join(data2.filter(lambda x: x[0] == '')).collect() # [('1', ('a', '1'))]
为什么 spark 这么写快呢?这里简单解释下
join 是把 两个元素做 笛卡尔內积,生成了 3x3=9 个元素,然后 shuffle,每个分区分别比较 key 是否相同,如果相同,合并,然后合并分区结果;
我们自己写的就是这样,shuffle 了 9 个元素;
而 spark 是先 filter,每个 list 变成了 一个元素,然后 join,join 的结果直接就是所需,不用 shuffle;
shuffle 本身是耗时的,而 filter 无需 shuffle,所以效率高 【join 是个 低效方法的原因】
小结
1. df 也是一个查询优化的手段
2. df 允许我们像操作数据库一样操作它
DataSet
DataSet 是 DataFrame 的扩展,是 spark 最新的数据抽象;
dataSet 像个对象,允许我们像操作类一样操作它,通过属性查看数据;
实际上 DataSet 是在 df 的基础上增加了数据类型;
df 只指定了字段名,而没有指定字段类型,sparkSQL 需要自动推断数据集的格式,这也是一种消耗,而 dataSet 直接指定了字段名和字段属性,效率更高
python 目前不支持 dataSet,所以后续支持了再说
SparkSession
在老版本中,sparkSQL 提供了两种 SQL 查询的起始点:
SQLContext,用于 spark 自己提供的 SQL 查询;
HiveContext,用于连接 hive 的查询
sparkSession 是新版的 SQL 查询起始点,实质上是组合了 SQLContext 和 HiveContext;
sparkSession 只是封装了 sparkContext,sparkContext 包含 SQLContext 和 HiveContext;
所以 sparkSession 实际上还是 依靠 sparkContext 实现了 SQLContext 和 HiveContext,故老版本用法也适用新版本。
DataFrame 的创建
sparkSession 直接生成 df
df 的创建有 3 种方式
从 spark 的数据源创建:读取 spark 支持的文件
从内部 RDD 创建:RDD 转换成 df
从 hive 创建:hive 查询
spark 数据源创建 DF
spark 支持的文件格式都有统一的入口
>>> dir(spark.read)
[ 'csv', 'format', 'jdbc', 'json', 'load', 'option', 'options', 'orc', 'parquet', 'schema', 'table', 'text']
sparkSQL 定义了一个 DataFrameReader 的类,在这个类中定义了所有数据源的接口,spark.read 是这个类的入口
创建 df 的方法也是惰性的
json
json 文件必须每行是一个 json 对象
## json 文件如下
# {'age': '10','name': 'zhangsan'}
# {'age': '20','name': 'lisi'} #### method 1
df1 = spark.read.json('data.json') # 相对路径
# >>> df1 # DataFrame[age: string, name: string] 可以看到 df 具备了字段名和字段属性 df1.show()
# +---+--------+
# |age| name|
# +---+--------+
# | 10|zhangsan|
# | 20| lisi|
# +---+--------+ df2 = spark.read.json('file:///usr/lib/spark/data.json') # 绝对路径 #### method 2
spark.read.format('json').load('/data.json').show()
其他文件读取方式与 json 完全相同
jdbc
spark.read.jdbc('jdbc:postgresql://172.16.89.80:5432/postgres', 'subtable', 'max_lng', 5, 10, 3, properties={'user':'postgres', 'password':'postgres'}).show()
注意
sparkSQL 会自动推断数据集的格式,以 json 为例,sparkSQL 会扫描数据集的每一项从而推断数据格式,
如果我们已经知道数据格式,可以在创建 df 时指定数据格式,从而加速创建过程且避免扫描数据集
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
schema = StructType([StructField("age", StringType(), True),
StructField("name", StringType(), True)])
spark.read.schema(schema).json('/data.json').show()
RDD 创建 DF
见下面的格式互转
hive 创建 DF
有两种方式从 hive 创建 df
1. 使用 DataFrameReader 中定义的 table 方法
注意这种方式不只适用于 hive,也用于其他表
spark.read.table('hive1101.person').show()
2. 使用 HiveContext 或者 SparkSession 中的 sql 方法,直接运行 hql
DF 操作
sparkSQL 对 DF 的操作有两种风格,一种是类 sql 的方式,一种是 领域专属语言 DSL
SQL 风格操作 DF
df 并不是一张数据表,而 sql 风格需要一张表;
如果有 hive 环境,可以直接用 hive 中的表,
如果没有,需要把 df 当成一个临时表注册到应用上,而且只有注册到的应用正在运行,这个临时表才可以使用
注册方法不止一种,比如 createTempView、registerTempTable、
### 创建临时视图
df1.createTempView('student')
# df1.createOrReplaceTempView('student') # ok
spark.sql('select * from student').show()
# +---+--------+
# |age| name|
# +---+--------+
# | 10|zhangsan|
# | 20| lisi|
# +---+--------+ spark.sql('select age from student').show()
spark.sql('select avg(age) from student').show()
# +------------------------+
# |avg(CAST(age AS DOUBLE))|
# +------------------------+
# | 15.0|
# +------------------------+
关闭 SparkSession 后这张表无法使用
session
这里穿插讲下 session 的概念;
session 的本意是会话,我们在多个场合都见过 session,如 web,如 tensorflow,但是在 web 中貌似不是 会话啊;
其实是这样的,session 有广义和狭义之分
广义 session:就是我们说的会话
狭义 session:它是一个存储位置,和 cookie 相对,cookie 是把某个信息存在客户度,session 是把 某个信息存在服务器上
全局表
临时表是在 session 范围内的,session 关闭后,临时表失效,如果想应用范围内有效,可以使用全局表,
全局表需要全路径访问
### 为了在应用范围内使用数据表,创建全局表
df1.createGlobalTempView('people')
## 查询
spark.sql('select * from global_temp.people').show() # global_temp.people 全路径访问表 ## 在另一个 session 中查询该表
spark.newSession().sql('select * from global_temp.people').show()
DSL 风格操作 DF
df 知道每列的名字和数据类型,可以提供用于数据处理的领域专属语言DSL 【这种方式不常用】
df1.printSchema() # 打印表结构
# root
# |-- age: string (nullable = true)
# |-- name: string (nullable = true) df1.select('name').show() # 查询name字段
df1.select("name", df1.age + 1).show() # age 字段的值都 加1,scala 中是用 $'age' 代替 df.age
# +--------+---------+
# | name|(age + 1)|
# +--------+---------+
# |zhangsan| 11.0|
# | lisi| 21.0|
# +--------+---------+ df1.filter(df1.age > 15).show() # 查看 age 大于 15
# +---+----+
# |age|name|
# +---+----+
# | 20|lisi|
# +---+----+
RDD-DF-dataSet
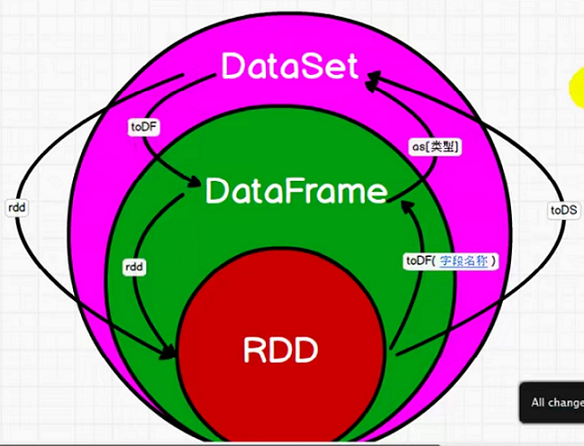
rdd、dataFrame、dataSet 相当于 spark 中三种数据类型,简单总结几点:
1. rdd 是 df、ds 的底层实现
2. df 在 rdd 的基础上添加了结构,可以像数据表一个进行字段操作,易用,且高效
3. ds 在 df 的基础上添加了数据类型,并且可以像操作类一样进行属性操作,目前 python 不支持
4. 三者可互相转换
5. df、ds 是 sparkSQL 中的数据类型,准确的说叫数据抽象,在 sparkSQL 中他们被转换成 table,进行 sql 操作
6. 三者的计算逻辑并无差异,也就是说相同的数据,结果是相同的
7. 三者的计算效率和执行方式不同
8. 在未来 spark 演进过程中, ds 会逐步取代 df、rdd
发展历程
RDD(spark1.0) ===> DataFrame(spark1.3) ===> DataSet(spark1.6)
转换逻辑
rdd + 表结构 = df
rdd + 表结构 + 数据类型 = ds
df + 数据类型 = ds
ds - 数据类型 - 表结构 = rdd
ds - 数据类型 = df
df - 表结构 = rdd
转换方法
RDD to DF 之 toDF
dataFrame 类似于数据表,数据表有行的概念,df 也有 Row 的概念,也就是说 df 必须是有行有列,二维的概念;
如果 RDD 不是二维,或者说没有 Row 的概念,需要显示的构建 Row 的格式;
## 手动构建 Row 的概念
rdd1 = sc.parallelize(range(5))
df1_1 = rdd1.map(lambda x: Row(id = x)).toDF() # 先加入结构,即字段,或者说 key,然后调用 toDF
# >>> df1
# DataFrame[id: bigint]
RDD to DF 之 spark.createDataFrame
该方法有两个输入:一个由行构成的RDD,一个数据格式;
数据格式可以是一个 StructType 类实例;
一个 StructType 对象包含一个 StructField 对象序列;
一个StructField 对象用于指定一列的名字、数据类型,并可选择的指定这一列是否包含空值及其元数据
### 方法2
rdd1 = sc.parallelize([range(5)]) # 注意必须是 二维 的,sc.parallelize(range(5)) 是不行的
df2_1 = spark.createDataFrame(rdd1).collect() # 没有显示地添加字段,以 默认值为 字段名
# [Row(_1=0, _2=1, _3=2, _4=3, _5=4)] rdd2 = sc.parallelize([('a', 1), ('b', 2)]) # 二维数据
df2_2 = spark.createDataFrame(rdd2, ['label', 'num']).collect() # 显示地添加字段
# [Row(label=u'a', num=1), Row(label=u'b', num=2)] ### 方法3
rdd3 = sc.parallelize([('zhangsan', 20), ('lisi', 30)])
Person = Row('name', 'age') # 格式化 Row,每行代表一个 Person
person = rdd3.map(lambda x: Person(*x)) # 把 RDD 格式化成 新的 RDD,并加入 Row 的概念
df3_1 = spark.createDataFrame(person).show()
# +--------+---+
# | name|age|
# +--------+---+
# |zhangsan| 20|
# | lisi| 30|
# +--------+---+ ### 方法4
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
schema = StructType([StructField("name", StringType(), True),
StructField("age", IntegerType(), True)])
df3 = spark.createDataFrame(rdd3, schema).collect()
# [Row(name=u'zhangsan', age=20), Row(name=u'lisi', age=30)]
toDF() vs createDataFrame()
1. 前者需要自己推断数据集的数据格式,因为并没有指定,后者则需要指定数据格式;
2. 前者易用;
3. 后者更加灵活,可以根据需要对同一数据设定多个数据格式,满足不同需求
DF to RDD
只需调用 rdd 属性即可
rdd = sc.parallelize([('a', 1), ('b', 2)]) # 二维数据
df = spark.createDataFrame(rdd2, ['label', 'num'])
df.rdd.collect()
# [Row(label=u'a', num=1), Row(label=u'b', num=2)]
参考资料:
https://spark.apache.org/docs/latest/api/python/pyspark.sql.html#pyspark.sql.SQLContext 官网 rdd to df
spark教程(11)-sparkSQL 数据抽象的更多相关文章
- spark教程(18)-sparkSQL 自定义函数
sparkSQL 也允许用户自定义函数,包括 UDF.UDAF,但没有 UDTF 官方 API class pyspark.sql.UDFRegistration(sparkSession)[sour ...
- spark教程(10)-sparkSQL
sparkSQL 的由来 我们知道最初的计算框架叫 mapreduce,他的缺点是计算速度慢,还有一个就是代码比较麻烦,所以有了 hive: hive 是把类 sql 的语句转换成 mapreduce ...
- spark教程(19)-sparkSQL 性能优化之谓词下推
在 sql 语言中,where 表示的是过滤,这部分语句被 sql 层解析后,在数据库内部以谓词的形式出现: 在 sparkSQL 中,如果出现 where,它会现在数据库层面进行过滤,一般数据库会有 ...
- Spark教程——(11)Spark程序local模式执行、cluster模式执行以及Oozie/Hue执行的设置方式
本地执行Spark SQL程序: package com.fc //import common.util.{phoenixConnectMode, timeUtil} import org.apach ...
- node-webkit教程(11)Platform Service之shell
node-webkit教程(11)Platform Service之shell 文/玄魂 目录 node-webkit教程(10)Platform Service之shell 前言 11.1 She ...
- 【译】ASP.NET MVC 5 教程 - 11:Details 和 Delete 方法详解
原文:[译]ASP.NET MVC 5 教程 - 11:Details 和 Delete 方法详解 在教程的这一部分,我们将研究一下自动生成的 Details 和Delete 方法. Details ...
- spark教程
某大神总结的spark教程, 地址 http://litaotao.github.io/introduction-to-spark?s=inner
- Expression Blend实例中文教程(11) - 视觉管理器快速入门Visual State Manager(VSM)
Expression Blend实例中文教程(11) - 视觉管理器快速入门Visual State Manager(V 时间:2010-04-12 16:06来源:SilverlightChina. ...
- [转帖]Linux教程(11)- linux中的计划作业
Linux教程(11)- linux中的计划作业 2018-08-21 17:13:36 钱婷婷 阅读数 160更多 分类专栏: Linux教程与操作 Linux教程与使用 版权声明:本文为博主原 ...
随机推荐
- $\LaTeX$数学公式大全4
$4\ Standard\ Function\ Names$将英文转化为罗马文$\arccos$ \arccos$\cos$ \cos$\csc$ \csc$\exp$ \exp$\ker$ \ker ...
- IP输出 之 ip_output、ip_finish_output、ip_finish_output2
概述 ip_output-设置输出设备和协议,然后经过POST_ROUTING钩子点,最后调用ip_finish_output: ip_finish_output-对skb进行分片判断,需要分片,则分 ...
- 20165207 Exp9 Web安全基础
目录 20165207 Exp9 Web安全基础 一.实验过程 1.环境配置 2.代理工具burpsuite 2.1 Http proxies -> Use the intercept 3.sq ...
- Oracle Stream 同步数据
1 引言 Oracle官方网: http://www.stanford.edu/dept/itss/docs/oracle/10g/server.101/b10727/strmover.htm ...
- 前端Ajax跨域解决方案
业务场景: 前后端分离需要对接数据接口. 接口测试是在postman做的,今天才开始和前端对接,由于这是我第一次做后端接口开发(第一次嘛,问题比较多)所以在此记录分享我的踩坑之旅,以便能更好的理解,应 ...
- DevOps - Scrum
1 - DevOps与敏捷开发 在采用敏捷开发的情况下,所有成员都对服务和产品负责,理解彼此的业务,符合DevOps的组织和文化. 以商业需求为核心,在较短期间内确定开发方针,并持续进行改善,从而逐步 ...
- WinRar制作安装包
这次研究了下WinRar制作程序安装包,我使用的是5.21版本. 选中要打包的文件,先压缩为RAR文件,然后双击打开文件 输入目录时可以选择前两项,输入绝对路径时,则为第三项. 配置解压前运行的解压后 ...
- /etc/passwd字段信息
root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nol ...
- Shell脚本中的shebang到底是什么
使用类Unix系统的同学可能都对"#!"这个符号并不陌生,但是你真的了解它吗? 这个符号的名称,叫做"Shebang"或者"Sha-bang" ...
- Microsoft Visual Studio 中工具箱不显示DevExpress控件的解决办法
我安装的是DevExpress15.2 1.找到安装目录D:\Program Files\DevExpress15.2\Components\Tools, 运行控制台 内容换成cmd 2.执行下面的命 ...