基于Hadoop伪分布式集群搭建Spark
一、前置安装
1)JDK
2)Hadoop伪分布式集群
二、Scala安装
1)解压Scala安装包
2)环境变量
SCALA_HOME = C:\ProgramData\scala-2.10.6
Path = %SCALA_HOME%\bin
3)测试
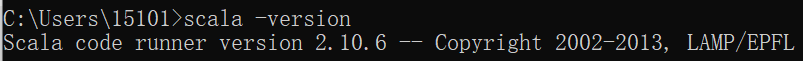
三、Spark安装
1)解压Spark安装包
2)环境变量
SPARK_HOME = C:\ProgramData\spark-1.6.-bin-hadoop2.
Path = %SPARK_HOME%\bin
3)测试
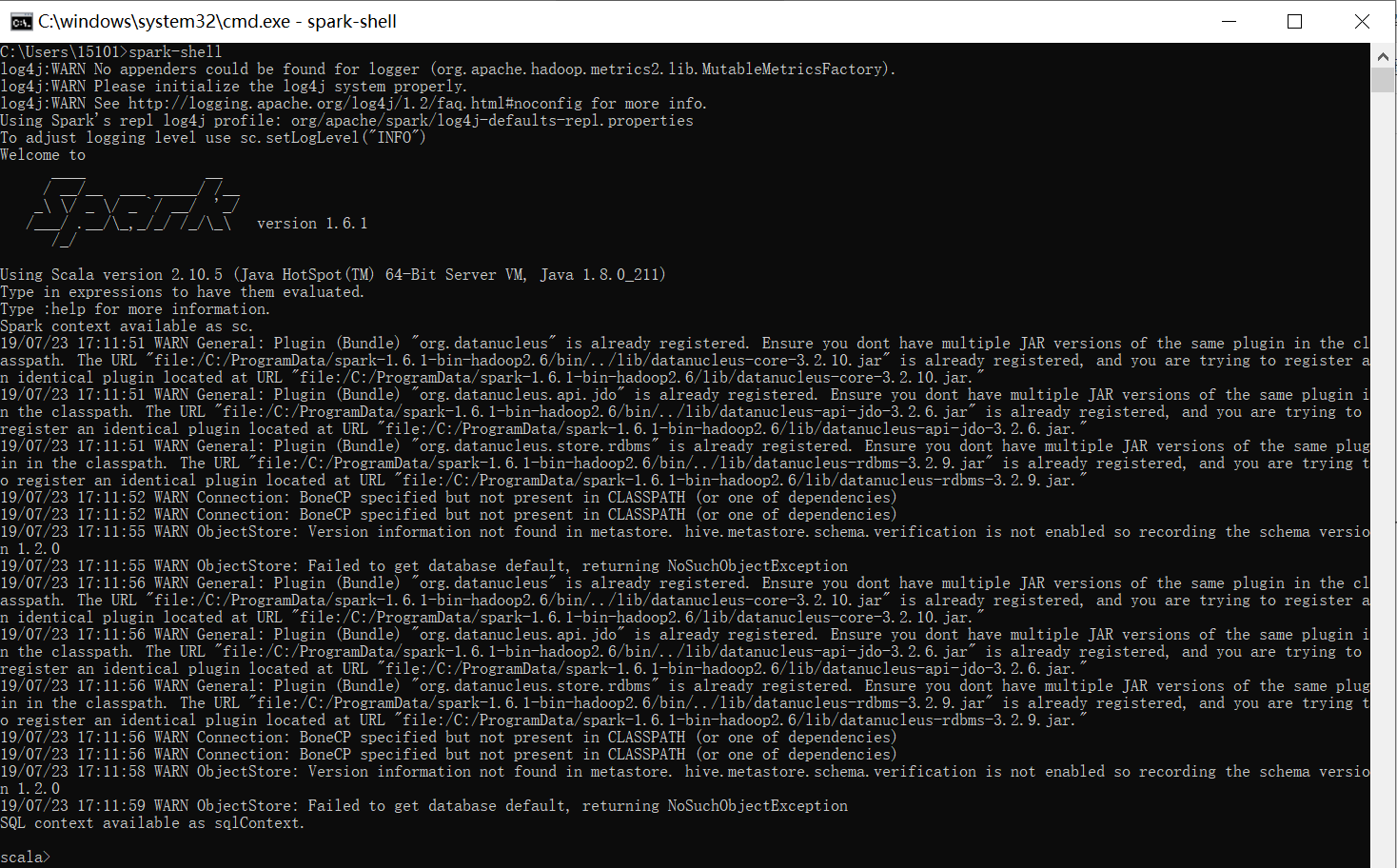
http://localhost:4040/jobs/

四、运行wordcounut程序
1)启动Hadoop集群
cd C:\ProgramData\hadoop-2.7.\sbin
C:\ProgramData\hadoop-2.7.\sbin>start-all.cmd
C:\ProgramData\hadoop-2.7.\sbin>jps
2)创建word.txt

3.1)读取Hadoop的HDFS文件运行WordCount
1、上传word.txt到Hdfs
hadoop fs -put C:\Projects\WordCount\word.txt /Demo/word.txt
2、启动spark-shell
3、输入Scala命令
sc.textFile("hdfs://localhost:9000/Demo/word.txt").flatMap(x => x.split("\t")).map(x=>(x,1)).reduceByKey(_+_).collect()



3.2)读取本地文件运行WordCount
1、启动spark-shell
2、输入Scala命令
sc.textFile("file:///C:/Projects/WordCount/word.txt").flatMap(x => x.split("\t")).map(x=>(x,)).reduceByKey(_+_).collect()


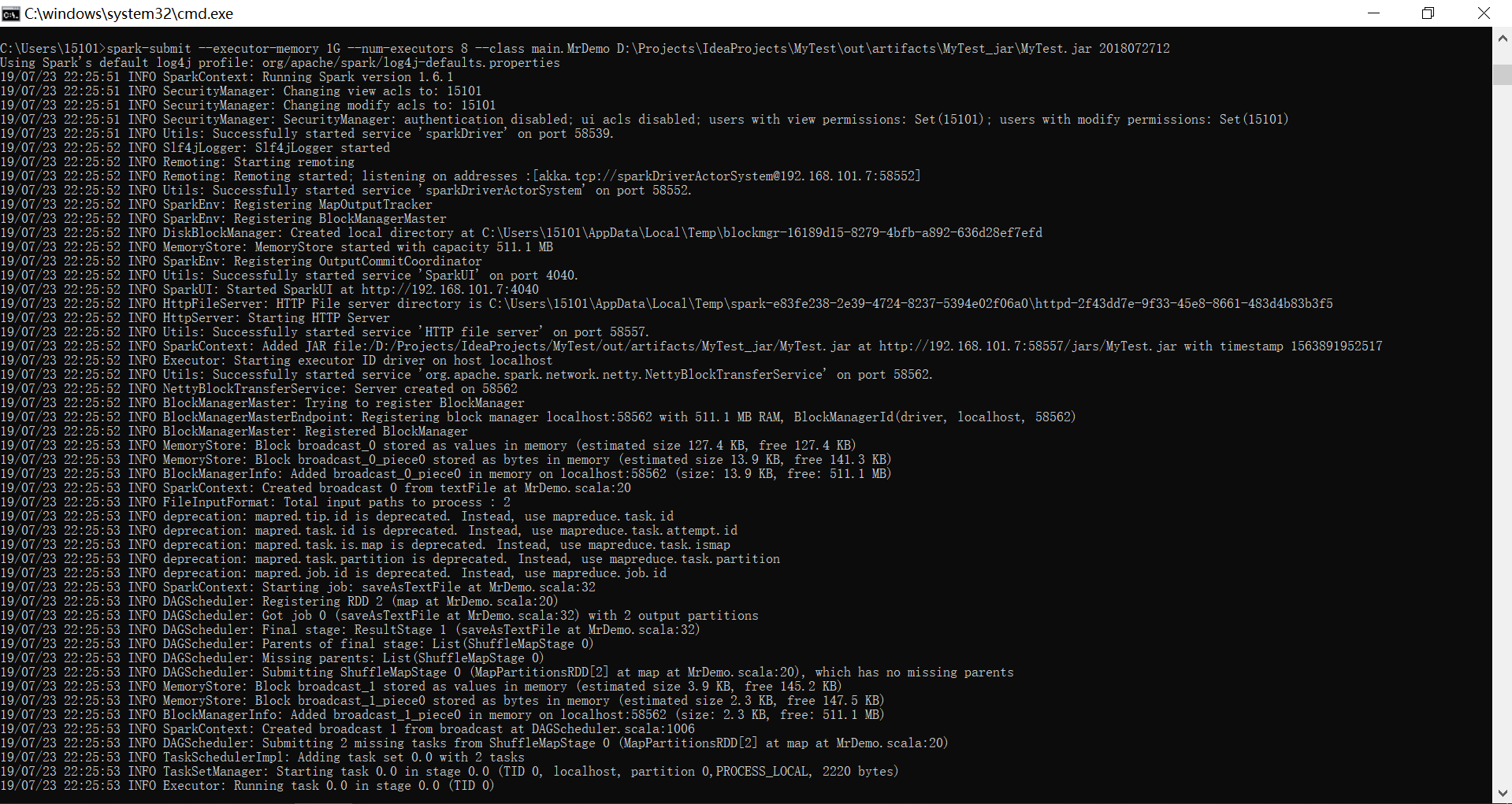
五、Spark部署运行
cmd --> spark-submit(无需spark-shell)
spark-submit --executor-memory 1G --num-executors 8 --class main.MrDemo D:\Projects\IdeaProjects\MyTest\out\artifacts\MyTest_jar\MyTest.jar 2018072712

六、Python下Spark开发环境搭建(PySpark)
Blog:https://www.cnblogs.com/guozw/p/10046156.html
1)安装Anaconda3-2019.03-Windows-x86_64(python 3.7.3)
2)下载spark-2.4.2-bin-hadoop2.7.tgz,解压,然后将spark目录下的pyspark文件夹(C:\ProgramData\spark-2.4.2-bin-hadoop2.7\python\pyspark)复制到python安装目录(C:\ProgramData\Anaconda3\Lib\site-packages)里
注意:Spark与Python版本要对应 - Python 2.7.5/3.5.2 + Spark 2.2.1 (pip install pyspark==2.2.1);Python 3.7.3 + spark-2.4.2-bin-hadoop2.7.tgz (pyspark 2.4.2)
3)安装py4j:Anaconda Prompt --> 安装py4j库
pip install py4j
4)新建一个PYTHONPATH的系统变量
PATHONPATH=%SPARK_HOME%\python;%SPARK_HOME%\python\lib\py4j-0.9-src.zip
5)PyCharm-->File-->Settings-->Project Interpreter-->Show All-->+-->System Interpreter-->选择:C:\ProgramData\Anaconda3\python.exe
6)PyCharm下编写WordCount测试
1、创建Session
from pyspark.sql import SparkSession
# appName中的内容不能有空格,否则报错
spark = SparkSession.builder.master("local[*]").appName("WordCount").getOrCreate()
#获取上下文
sc = spark.sparkContext
带有空格报错情况如下:

2、创建上下文
# 第一种方式
conf = SparkConf().setAppName('test').setMaster('local')
sc = SparkContext(conf=conf)
# 第二种方式
sc=SparkContext('local','test')
3、实例
# 实例1 - 读取文件并打印
from pyspark import SparkContext, SparkConf conf = SparkConf().setAppName('test').setMaster('local')
sc = SparkContext(conf=conf) rdd = sc.textFile('d:/scala/log.txt')
print(rdd.collect())

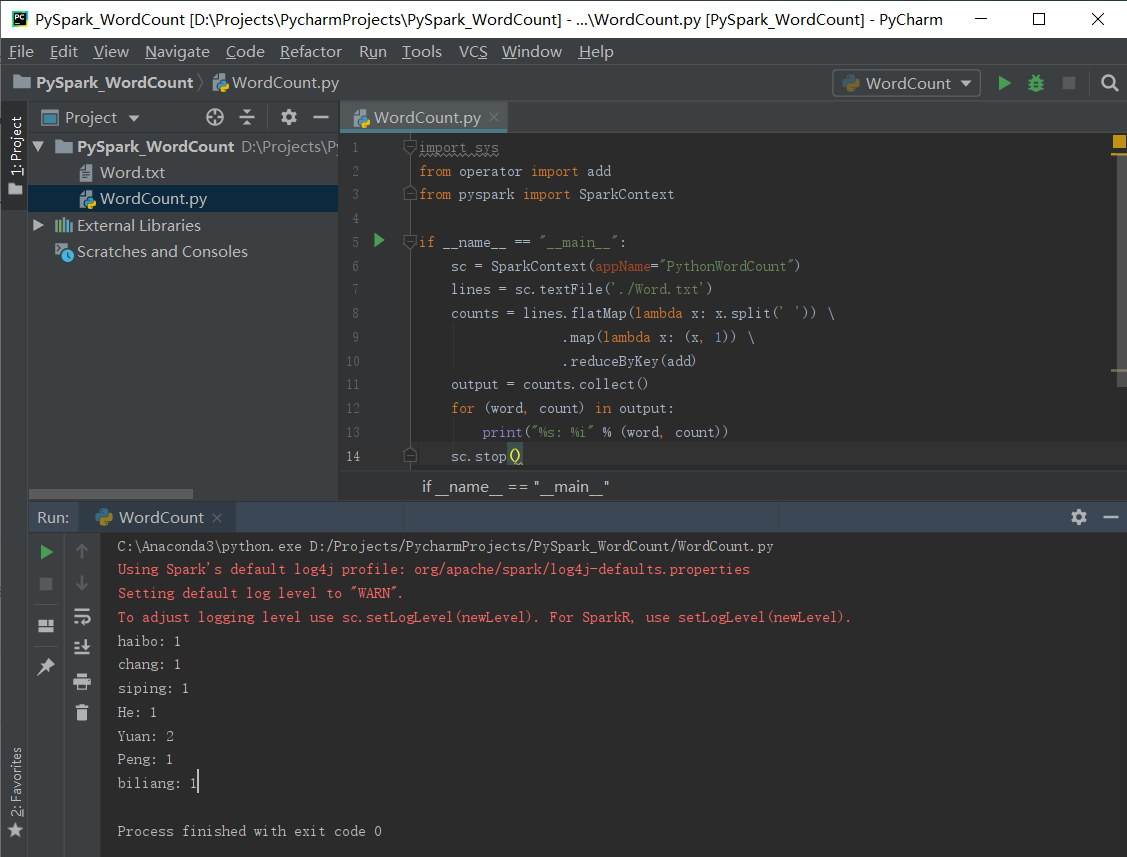
# 实例2 - WordCount
import sys
from operator import add
from pyspark import SparkContext if __name__ == "__main__":
sc = SparkContext(appName="PythonWordCount")
lines = sc.textFile('./Word.txt')
counts = lines.flatMap(lambda x: x.split(' ')) \
.map(lambda x: (x, )) \
.reduceByKey(add)
output = counts.collect()
for (word, count) in output:
print("%s: %i" % (word, count))
sc.stop()
问题:
Java.util.NoSuchElementException: key not found: _PYSPARK_DRIVER_CALLBACK_HOST
原因:版本不兼容,PySpark的版本与Spark不匹配
解决:查看Spark版本,例如为2.1.0,则使用Pip安装PySpark时,带上版本号
pip install pyspark==2.1.2 # 皆为2.1版本
✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡Anaconda3.7与Anaconda3.5切换✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡
win+R输入cmd进入命令行,跳转到Anaconda的安装目录,然后执行
cd C:\ProgramData\Anaconda3
cd C:\ProgramData\Anaconda3.5
python .\Lib\_nsis.py mkmenus

然后再点击Anaconda Prompt,即切换到当前Python环境
✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡✡
基于Hadoop伪分布式集群搭建Spark的更多相关文章
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- Hadoop学习笔记(一):ubuntu虚拟机下的hadoop伪分布式集群搭建
hadoop百度百科:https://baike.baidu.com/item/Hadoop/3526507?fr=aladdin hadoop官网:http://hadoop.apache.org/ ...
- Hadoop伪分布式集群搭建
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 1.下载Hadoop压缩包 wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop- ...
- hadoop伪分布式集群的搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 linux系统环境:Centos6.5 创建普通用户 dummy 设置静态IP地址 Hadoop伪分布式集群搭建: 为普通用户添加su ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- Hadoop单机/伪分布式集群搭建(新手向)
此文已由作者朱笑笑授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 本文主要参照官网的安装步骤实现了Hadoop伪分布式集群的搭建,希望能够为初识Hadoop的小伙伴带来借鉴意 ...
- hadoop学习笔记(五)hadoop伪分布式集群的搭建
本文原创,如需转载,请注明作者和原文链接 1.集群搭建的前期准备 见 搭建分布式hadoop环境的前期准备---需要检查的几个点 2.解压tar.gz包 [root@node01 ~]# ...
- Hadoop学习---CentOS中hadoop伪分布式集群安装
注意:此次搭建是在ssh无密码配置.jdk环境已经配置好的情况下进行的 可以参考: Hadoop完全分布式安装教程 CentOS环境下搭建hadoop伪分布式集群 1.更改主机名 执行命令:vi / ...
- zookeeper伪分布式集群搭建
zookeeper集群搭建注意点: 配置数据文件myid1/2/3对应server.1/2/3 通过zkCli.sh -server [ip]:[port]检测集群是否 ...
随机推荐
- SSRF和XSS-filter_var(), preg_match() 和 parse_url()绕过学习
0x01:url标准的灵活性导致绕过filter_var与parse_url进行ssrf filter_var() (PHP 5 >= 5.2.0, PHP 7) filter_var — 使用 ...
- Misc套路记录
1.对于给定的二维码图片不能直接扫描出来的可以进行反色在进行扫描,反色可以直接选中图片然后就会进行反色.2.局域网中抓取的数据包的加密方式可能是aes加密.3.凯撒加密可能是变种的凯撒加密,可能奇数偶 ...
- 7 vi 编辑器
1.vim编辑器的工作模式 命令模式,插入模式,可视化模式,扩展命令模式. 2.命令模式 2.1.光标定位 hjkl:小键盘上下左右移动 0 $:行头.行尾 gg G:第一行.最后一行 30G:进入第 ...
- PHP压缩图片并模糊处理(抄的哟)
class image_blur{ /** * 图片高斯模糊(适用于png/jpg/gif格式) * @param $srcImg 原图片 * @param $savepath 保存路径 * @par ...
- legend3---5、lavarel爬坑杂记
legend3---5.lavarel爬坑杂记 一.总结 一句话总结: 边做边学,变学边做,可能会节约很多时间,熟悉的就跳着看,不熟悉的就慢慢看 1.如何tags表中的主键是t_id而非id,如何使用 ...
- MySQL获取距离
BEGIN ) ), ) ) ) ) ),))),); END
- koa2环境搭建
npm install -g koa-generator koa2 ssy-koa2 cd ssy-koa2 npm install
- LC 465. Optimal Account Balancing 【lock,hard】
A group of friends went on holiday and sometimes lent each other money. For example, Alice paid for ...
- GitHub-Microsoft:sql-server-samples
ylbtech-GitHub-Microsoft:sql-server-samples 1.返回顶部 2.返回顶部 3.返回顶部 4.返回顶部 5.返回顶部 1. https://gi ...
- c#阿里云短信验证码
发送验证码 private static void SendAcs(string mobile, string templateCode, dynamic json, int ourid) { if ...