C# 内存管理和指针 (13)
本章要点
- 运行库在栈和堆上分配空间
- 垃圾回收
- 使用析构函数 和 SYstem.IDisposable 接口来释放非托管的资源
- C#中使用指针的语法
- 使用指针实现基于栈的高性能数组
值类型数据
程序第一次开始运行时,栈指针指向为栈保留的内存块末尾。栈实际是从高内存地址向低内存地址填充的,向下填充。当数据入栈后,栈指针就会随之调整,以始终指向下一个空间存储单元。
引用数据类型
虽然栈有非常高的性能,但它没有灵活到可以用于所有的变量(引用类型)。引用类型,用 new 运算符请求分配存储空间,存放托管堆的。
- Custormer arabel = new Custormer();
arabel 仅是一个引用。占用 4个字节空间。
当一个引用变量超出作用域时,它会从栈中删除,但引用的对象数据仍保留在堆中,一直到垃圾回收器删除它 或 程序终止,它才会被删除。
垃圾回收
在垃圾回收器运行时,它会从堆中删除不在引用所有对象。在完成删除操作后,堆会立即把对象分散开来,与已经释放的内存混合一起。
托管堆,在其新对象分配内存就称为一个很难处理的过程,运行库必须搜索整个堆,才能找到足够大的内存块来存储每个新对象。
垃圾回收器释放了所有的对象,就会把其他对象移动回堆的端部,再次形成一个连续的内存块。因此,堆可以继续像栈那样确定在什么地方存储新对象。当然移动对象时,这些对象的所有引用都需要用正取的新地址来更新,但垃圾回收器也会处理更新问题。
垃圾回收器的压缩操作是托管的堆与非托管的旧堆的区别所在。使用托管的堆,只需要读取指针的值即可,而不需要遍历地址的链表,来查找一个地方来放置新数据。
调用 System.GC.Collect() 方法,强迫来及回收器在代码的某个地方运行,System.GC 类是一个表示垃圾回收器的 .NET 类,Collect() 方法 启动一个来及回收过程。GC类适用的场合很少,例如,代码中有大量的对象刚刚取消引用,就适合调用垃圾回收器。
垃圾回收器的逻辑不能保证在一次垃圾收集过程中,所有未引用的对象都从堆中删除。
创建对象时, 会把这些对象放在托管堆上。 堆的第一部分称为第0代。 创建新对象时, 会把它们移动到堆的这个部分中。 因此, 这里驻留了最新的对象。对象会继续放在这个部分, 直到垃圾回收过程第一次进行回收。 这个清理过程之后仍保留的对象会被压缩, 然后移动到堆的下一部分上或世代部分 一 第1代对应的部分。
此时, 第0代对应的部分为空, 所有的新对象都再次放在这一部分上。 在垃圾回收过程中遗留下来的旧对象放在第1代对应的部分上。 老对象的这种移动会再次发生。接着重复下一次回收过程。这意味着 第1代中在垃圾回收过程中遗留下来的对象会移动到堆的第2代, 位于第0代的对象会移动到第1代, 第0代仍用于放置新对象。
在给对象分配内存空间时,如果超出了第0代对应的部分的容量,或者调用 GC.Collect() 方法,就会进行垃圾回收。
这个过程极大地提高了应用程序的性能。一般而言,最新的对象通常是可以回收的对象,而且可能也会回收比较新的对象。如果这些对象在堆中的位置是相邻的,垃圾回收过程就会更快。另外,相关的对象相邻放置也会使程序执行得更快。
在.NET中,垃圾回收提高性能的另一个领域是架构处理堆上较大的对象的方式。在.NET下,较大对象有自己的托管堆,称为大对象堆。使用大于85000个字节的对象时,它们就会放在这个特殊的堆上,而不是主堆上。.NET 应用程序不知道两者的区别,因为这是 自动完成的。其原因是在堆上压缩大对象时比较昂贵的,因此驻留在大对象堆上的对象不执行压缩过程。
在进一步改进垃圾回收过程后,第二代和大对象堆上的回收现在放在后台线程上进行。这表示,应用程序线程仅会为第0代和第1代的回收而阻塞,减少了总暂停时间,对于大型服务器应用程序尤其如此。服务器好工作站默认打开这个功能。要关闭该功能,可以在配置文件中把<gcConcurrent>元素设置为false。
有助于提高应用程序性能的另一个优化是垃圾回收的平衡,它专用于服务器的垃圾回收,服务器一般有一个线程池,执行大致相同的工作。内存分配在所有线程上都是类似的。对于服务器,每个逻辑服务器都有一个垃圾回收堆。其中一个堆用尽了内存,触发了垃圾回收过程时,所有其他队也可能得益于垃圾的回收。如果一个线程使用的内存远远多于其他线程,导致垃圾回收,其他线程可能不需要垃圾回收,这就不是很高效。垃圾回收过程会平衡这些堆-----小对象堆和大对象堆。进行这个平衡过程,可以减少不必要的回收。
为了利用包含大量内存的硬件,垃圾回收过程添加了GCSettings.LatencyMode 属性。把这个属性设置为 GCLatencyMode枚举的一个值,可以控制垃圾回收器进行回收的方式。
GCLatencyMode的设置
| Batch | 禁用并发设置,把来及回收设置为最大吞吐量。这会重写配置设置 |
| Interactive | 默认行为 |
| LowLatency | 保守的垃圾回收。只有系统存在内存压力时,才进行完整的回收。只应用于较短时间,执行特定的操作 |
| SustainedLowLatency | 只有系统存在内存压力时,才进行完整的内存块回收 |
LowLatency 设置使用的时间应为最小值,分配的内存量应尽可能小。如果不小心,就可能出现溢出内存错误。
为了使用64位机器的高内存量,添加了<gcAllorVeryLargeObjects>配置配置。它允许创建大于2GB的对象。这对32位机器没有影响,32位机器仍有2GB的限制。
释放非托管的资源
那些对象所有引用只要超出作用域,并允许垃圾回收时,它就会在需要时,释放内存。但是垃圾回收器不知道如何释放非托管的资源。在定义类时,需要实现两种机制,来实现垃圾回收。
- 声明析构函数(或终结器),作为类的一个成员
- 在类中实现 System.IDisposable 接口
析构函数
在底层的.NET体系结构中,这些函数称为终结器(finalizer)。在C#中定义析构函数时,编译器发送给程序集的实际上是Finalize()方法。它不会影响源代码,但如果需要查看程序集的内容,就应知道这个事实。
- class StaticClass
- {
- public StaticClass()
- {
- }
- // 析构函数
- ~StaticClass()
- {
- }
- }
C#编译器在编译析构函数时,它会隐式地把析构函数的代码编译为等价 Finalize() 方法的代码,从而确保执行父类的 Finalize() 方法。下面列出了等价于编译器为 MyClass析构函数生成的IL的c#代码
- class StaticClass
- {
- public StaticClass()
- {
- }
- // 析构函数
- protected override void Finalize()
- {
- return base.Finalize();
- }
- }
由于使用C#时垃圾回收器的工作方式,无法确定C#对象的析构函数何时执行,所以不能在析构函数中放置需要在某一时刻运行的代码,也不应寄望于析构函数会以特定顺序对不同类的的实例调用。如果对象占用了宝贵而重要的资源,应尽快释放这些资源,此时就不能等待垃圾回收器来释放了。
C#析构函数的实现会延迟对象最终从内存删除的时间,没有析构函数的对象会在垃圾回收器的一次处理中从内存中删除,但有析构函数的对象需要两次处理才能销毁:第一次调用析构函数时,没有删除对象,第二次调用才真正删除对象。另外,运行库使用一个线程来执行所有对象的 Finalize() 方法。如果频繁使用析构函数,而且使用它们执行长时间的清理任务,对性能影响就会非常显著。
IDisposeable接口
在C#中,推荐使用 System.IDisposeable 接口替代析构函数。IDisposeable 接口定义了一种模式(具有语言级的支持),该模式为释放非托管的资源提供了确定的机制,并避免产生析构函数固有的与垃圾回收器相关的问题。IDisposeable 接口声明了一个 Dispose() 方法,它不带参数,返回 void。
- class MyClass : IDisposable
- {
- public void Dispose()
- {
- }
- }
Dispose() 方法的实现代码显式地释放由对象直接使用的所有非托管资源,并在所有也实现 IDisposeable 接口的封装对象上调用 Dispose() 方法。这样,Dispose() 方法为和是释放非托管资源提供了精确的控制。
- MyClass myClass = new MyClass();
- myClass.Dispose();
还可以使用 using 关键字。
C#提供一种语法,确保在实现IDisposeable接口的对象的引用超出作用域时,在该对象上自动调用Dispose()方法。 该关键字在完全不同的环境下,它与名称空间没有关系。
- using ( MyClass myClass = new MyClass() )
- {
- }
它与try块生成等价的IL代码:
- MyClass theInstance = null;
- try
- {
- theInstance = new MyClass();
- }
- finally
- {
- if (theInstance != null)
- {
- theInstance.Dispose();
- }
- }
using语句的后面是一对圆括号,其中是引用变量的声明和实例化,该语句使变量的作用域限定在随后的语句块中。在变量超出作用域时,即使出现异常,也会自动调用其 Dispose() 方法。然而,如果已经使用 try 块来捕获其他异常,就会非常清晰,如果避免使用using语句,仅在已有的try块的 finally子句中调用 Dispose() 方法,还可以避免进行额外的代码缩进。
对于某些类,使用Close()方法要比 Dispose() 方法更富有逻辑性。如处理文件或数据库连接时,就是这样。Close()方法调用Dispose()方法。这种方法在类的使用上比较清晰,还支持C#提供的using语句。
实现IDisposeable接口 和 析构函数
一般情况下, 最好的方法是实现两种机制,获得两种机制的优点,克服其缺点。假定大多数程序员都能正确调用 Dispose() 方法,同事把实现析构函数作为一种安全机制,以防没有调用Dispose()方法。
- using System;
- public class ResourceHolder : IDisposable
- {
- // 成员变量表示对象是否已被清理,并确保不试图多次清理成员变量。
- private bool isDisposed = false;
- public void Dispose()
- {
- Dispose(true);
- // GC类表示垃圾回收器
- // SuppressFinalize方法则告诉垃圾回收器有一个类不再需要调用其析构函数了,因为Dispose()方法已经完成了所有需要的清理工作,所以析构函数不需要做任何工作。调用SuppressFinalize()方法就意味着垃圾回收器认为这个对象根本没有析构函数。
- GC.SuppressFinalize(this);
- }
- // 重载 Dispose方法
- protected virtual void Dispose(bool disposing)
- {
- if (!isDisposed)
- {
- if (disposing)
- {
- // Cleanup managed objects by calling their
- // Dispose() methods.
- }
- // Cleanup unmanaged objects
- }
- isDisposed = true;
- }
- ~ResourceHolder()
- {
- Dispose (false);
- }
- public void SomeMethod()
- {
- // 确保在执行实例方法之前,测试对象是否已清理
- // 这个方法不是线程安全的,需要调用者确保在同一时刻只有一个线程调用方法。要求使用者进行同步是一个合理的假定。
- // Ensure object not already disposed before execution of any method
- if(isDisposed)
- {
- throw new ObjectDisposedException("ResourceHolder");
- }
- // method implementation…
- }
- }
不安全的代码
有时也需要直接访问内存。例如,由于性能问题,要在外部(非.NET环境)的DLL中访问一个函数,该函数需要把一个指针当做参数来传递(许多Windows API函数就是这样)。
用指针访问内存
引用就是一个类型安全的指针。引用表示对象和数组的变量实际上存储相应数据(被引用者)的内存地址。指针只是一个以与引用相同的方式存储地址的变量。其区别是C#不允许直接访问引用变量中包含的地址。有了引用后,从语法上看,变量就可以存储引用的实际内容。
C#引用主要用于C#语言易于使用,防止用户无意中执行某些破坏内存中内容的操作。另一方面,使用指针,就可以访问实际内存地址,执行新类型的操作。例如,给地址加上4个字节,就可以查看甚至修改存储在新地址中的数据。
下面是使用指针的两个主要原因:
- 向后兼容性----------尽管.NET运行库提供了需要工具,但仍可以调用本地的 Windows API 函数。对于某些操作这可能是完成任务的唯一方式。这些API函数都是用C++或C#语言编写的,通常要求把指针作为其参数。但许多情况下,还可以使用 DllImport 声明,以避免使用指针,例如,使用System.IntPtry 类型。
- 性能 ----------在一些情况下,速度是最重要的,而指针可以提供最优性能。假定用户最多自己在做什么,就可以确保以最搞笑的方式访问或处理数据。但是,注意在代码的其他区域中,不使用指针,也可以对性能进行必要的改进。使用代码配置文件,查找代码中的瓶颈,VS中就包含一个代码配置文件。
使用指针,必须授予代码运行库的代码访问安全机制的高级别信任,否则就不能执行它。在默认的代码访问安全策略中,只有代码运行在本地计算机上,这才是可能的。如果代码必须运行在远程地点,如Internet,用户就必须给代码授予额外的许可,代码才能工作。除非用户信任你和代码,否则他们不会授予这些许可。
指针无法通过 CLR(.NET 公共语言运行库)内存类型安全检查。
用unsafe关键字编写不安全代码
因为使用指针会带来相关的风险,所以C#只允许特别标记的代码块中使用指针。标记代码所用的关键字是unsafe。
- unsafe int GetSomeNumber()
- {
- }
任何方法都可以标记为 unsafe -----无论该方法是否应用了其他修饰符(例如,静态方法、虚方法等)。unsafe 修饰符还会应用到方法的参数上,允许把指针用做参数。还可以把整个类或结构标记为 unsafe ,这表示假设所有的成员都是不安全的。
- unsafe class MyClass()
- {
- }
- class MyClass
- {
- unsafe int* pX;
- }
- // 把代码块标记为 unsafe
- void MyMethod
- {
- unsafe
- {
- }
- }
注意,它不能把局部变量标记为 unsafe 。
如果要使用不安全的局部变量,就需要在不安全的方法或语句块中声明和使用它。在使用指针前还有一步要完成。C#编译器会拒绝不安全的代码,除非告诉编译器代码包含不安全的代码块。标记所用的关键字 unsafe 。因为要编译包含不安全代码块的文件 MySource.cs ( 假定没有其他编译器选项),就要使用下述命令:
- csc /unsafe MySource.cs
- 或者
- csc -unsafe MySource.cs
如果使用 vs 可以在项目属性窗口的 Build 选项卡中 找到 编译器不安全代码的选项。
新版本的VS

指针的语法
把代码块标记为 unsafe 后,就可以使用下面的语法声明指针。
- // 在指针变量名的前面使用前缀来表示这些变量是指针。
- // 符号 * 表示声明一个指针,换言之,就是存储特定类型的变量的地址。
- // 整数型指针
- int* pWidth, pHeight;
- // double 型指针
- double* pResult;
- // 字节型的数据指针
- byte*[] pFlags;
C++开发人员要注意与C#中的语法差异。C#语句中的 "int*pX,pY;" 对应 C++ 语句中的 "int *pX, *pY;" 在c#中 * 符号与类型相关,而与变量名无关。
- unsafe
- {
- int x = ;
- int* pX, pY;
- pX = &x;
- pY = pX;
- *pY = ;
- System.Console.WriteLine(x);
- }
- & 表示 "取地址",并把一个值数据类型转换为指针,例如,int 转换为 *int 。这个运算符称为 寻址运算符。
- * 表示 "获取地址的内容", 把一个指针转换为值数据类型(例如 *float 转换为 float)。这个运算符称为 "间接寻址运算符" (有时称为 "取消引用运算符" )。
首先声明一个整数x,其值是10。接着声明两个整数指针pX和pY。然后把pX设置为指向x(换言之,把pX的内容设置为x的地址)。然后把pX的值赋值予pY,所以pY也指向x。最后,在语句 *pY = 20 中,把值 20 赋予 pY 指向的地址包含的内容。实际上把 x 的内容改为20,因为 pY 指向 x。 注意, pY 和 x 之家没有任何关系,只是此时 pY 指向 存储 x 的存储单元。
进一步理解这个过程。假定 x 存储在栈的存储单元 0x12F8C4 ~ 0x12F8C7 ,既有4个存储单元,因为一个int占用4个字节。因为栈向下分配内存,所以变量pX存储在 0x12F8C0 ~ 0x12F8C3 的位置上,pY存储在 0x12F8BC ~ 0x12F8BF 的位置上。注意,pX 和 pY 也分别占用 4 个字节。这不是因为 int 占用 4个 字节,而是因为在32位处理器上,需要用4个字节存储一个地址。利用这些地址,在执行完上述代码后,栈如以下图所示
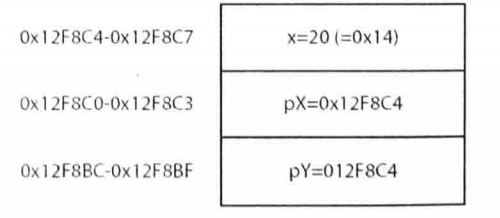
这个示例使用int来说明该过程,其中int存储在32位处理器中栈的连续空间上,但并不是所有的数据类型都回存储在连续的空间中,原因是32位处理器最擅长于在4个字节的内存块中检索数据。这中计算机上的内存会分解位4个字节块,在Windows上,每个块有事称为 DWORD,因为这是32位无符号int数在.NET出现之前的名字。这是从内存获取 DWORD 的最高效的方式-----跨越 DWORD 边界存储数据通常会降低硬件的性能。因此, .NET 运行库通常会给某些数据类型填充一些空间,使它们占用的内存是4个倍数。例如 ,short 数据占用两个字节,但如果把一个short 放在栈中,栈指针仍会向下移动4个字节,而不是两个字节,这样,下一个存储在栈中的变量就仍从 DWORD 的边界开始存储。
可以把指针声明为任意一种值类型---任何预定义的类型 uint、int 和 byte ,也可以声明 一个结构。 但不能把指针声明为一个 类 或 数组,因为这么做会使垃圾回收器出现问题。为了正常工作,垃圾回收器需要做的在堆上创建了什么类的实例,它们在什么地方。但如果代码开始使用指针处理类,就很容易破坏堆中 .NET 运行库为垃圾回收器维护的与类相关的信息。在这里,垃圾回收器可以访问的任何数据类型称为托管类型,而指针只能声明为非托管类型,因为垃圾回收器不能处理它们。
指针强制转换为整数类型
指针实际上存储了一个表示地址的整数,因此任何指针中的地址都可以和任何整数类型之间相互转换。指针到整数类型的转换必须是显式指定的,隐式的转换是不允许的。
- unsafe
- {
- // 把指针 pX 中包含的地址强制转换为一个 uint ,存储在变量 y 中。接着把 y 强制转换回一个 int* ,存储在新变量 pD 中。因此 pD 也指向 x 的值。
- int x = ;
- int* pX, pY;
- pX = &x;
- pY = pX;
- *pY = ;
- uint y = (uint)pX;
- int* pD = (int*)y;
- Console.WriteLine(y + " " + (int)*pD );
- }
把指针的值强制转换为整数类型的主要目的是显式它。
可以把一个指针强制转换为任何整数类型,但是因为在32位系统上,一个地址占用4个字节,把指针强制转换为了除了 uint、long 或 ulong 之外的数据类型,肯定会导致溢出错误(int数也可能导致这个问题,因为它的取值范围是 -20亿 ~ 20亿 ,而地址的取值范围是 0 ~ 40亿)。C#用于64位处理器时,一个地址占用8个字节。因此在这样的系统上,把指针强制转换为非 ulong 类型,就可能导致溢出错误。
指针转换时,发生溢出时,即使使用 checked 关键字,也不会抛出异常。 因为 .NET运行库假定,如果使用指针,就必须知道自己要做什么,不必担心可能出现的溢出。
指针类型之间的强制转换
可以在指向不同类型的指针之间进行显示的转换。
- byte aByte = ;
- byte* pByte = &aByte;
- double* pDouble = (double*) pByte;
- Console.WriteLine((double)*pDouble);
- Console.WriteLine((double)*pByte);
如果要查找指针pDouble指向的 double 值,就会查找包含 1个 byte(aByte)的内存,和一些其他内存,并把它当做包含一个 double 值的内存区域来对待----这不会得到一个有意义的值。但是,可以在类型之间转换,实现 C union 类型的等价形式,或者把指针强制转换为其他类型,例如把指针转换为 sbyte ,检查内存的单个字节。
void 指针
如果不希望指定它指向的数据类型,可以把指针声明为 void :
- unsafe
- {
- int* pointerToInt;
- void* pointerToVoid;
- pointerToVoid = (void*) pointerToInt;
- }
void指针的主要用途是调用需要 void* 参数的API函数。在C#语言中,使用 void 指针的情况并不是很多。特殊情况下, 如果试图使用 * 运算符取消引用 void 指针,编译器就会标记一个错误。
指针算术的运算
可以给指针加减整数。例如假定有一个 int 指针,要在其值加1。编译器会假定我们要查找int后面的存储单元,因此会给该值加上4个字节,即加上一个int占用的字节数。如果这是一个double指针,加1就表示指针的值加上8个字节,即一个double占用的字节数。只有指针指向 byte 或 sbyte (都是1个字节时),才会给该指针的值加1。
可以对指针使用运算符+、-、+=、-=、++和--,这是运算符右边的变量必须是 long 或 ulong 类型。
不允许对 void 指针执行算术运算。
- unsafe
- {
- uint u = ;
- uint u2 = ;
- uint* pUint = &u;
- Console.WriteLine((uint)pUint + " " + (uint)&u + " " + (uint)*pUint);
- pUint -= ;
- Console.WriteLine("{0} {1} {2}", (uint)pUint, (uint)&u2, (uint)*pUint);
- }
一般规则是,给类型为T的指针加上数值X,其中指针的值为P,则得到的结果是 P + X *(siezeof(T))。 使用这条规则是要小心。如果给定类型的连续值存储在连续的存储单元中,指针加法就允许在存储单元之间移动指针。但如果类型是 byte 或 char,其总字节数不是4的倍数,连续值就不是默认地存储在连续的存储单元中。
如果两个指针都指向相同的数据类型,则也可以把一个指针从另一个指针中减去。此时,结果是一个long,其值是指针值的差被该数据类型所占用的字节数整除的结果。
- double d1 = ;
- double* pD1 = &d1;
- double* pD2 = pD1 - ;
- Console.WriteLine("{0} {1}", (uint)pD1, (uint)pD2);
- // 返回数据类型占用
- long mL = pD1 - pD2;
- Console.WriteLine(mL);
sizeof 运算符
size运算符,返回该类型占用的字节数。参数是数据类型的名称。
- int size = sizeof(double);
- Console.WriteLine(size);
对自己定义的结构使用 sizeof,但此时得到的结果取决于结构中的字段类型。
结构指针:指针成员运算符
结构指针的工作方式与预定义值类型的指针的工作方式完全相同。但是这有一个条件:结构不能包含任何引用类型,这是因为前面介绍的一个限制-----指针不能指向任何引用类型。为了避免这种情况,如果创建一个指针,它指向包含任何引用类型的任何结构,编译器就会标记错误。
- unsafe
- {
- MyStruct myStruct = new MyStruct();
- MyStruct* pStruct = &myStruct;
- // 通过指针访问成员值
- (*pStruct).X = ;
- (*pStruct).F = 10F;
- Console.WriteLine("{0} {1}", myStruct.X, myStruct.F);
- // C# 提供指针成员访问运算符,简化 写法
- pStruct -> X = ;
- pStruct -> F = 12F;
- Console.WriteLine("{0} {1}",myStruct.X,myStruct.F);
- }
成员运算符,C++ 和 C# 作用是一样的。
也可以
- MyStruct myStruct = new MyStruct();
- MyStruct* pStruct = &myStruct;
- long* pL = &(myStruct.X);
- float* pF = &(pStruct->F);
类成员指针
- MyClass myClass = new MyClass();
- myClass.L = ;
- myClass.F = 10f;
- long* pL = &(myClass.L);
- float* pF = &(myClass.F);
尽管 L 和 F 都是非托管类型,但它们嵌入在第一个对象中,这个对象存储在堆上。在垃圾回收的过程中,垃圾回收器会把MyObject移动到内存的一个新单元上,这样 pL 和 pF 就会指向错误的存储地址。由于存在这个问题,因此编译器不允许以这种方式把托管类型的成员的地址分配给指针。
解决办法用 fixed 关键字,它会告诉垃圾回收器,可能有引用某些对象的成员的指针,所以这些对象不能移动。
- MyClass myClass = new MyClass();
- myClass.L = ;
- myClass.F = 10f;
- fixed (long* pL = &(myClass.L))
- fixed (float* pF = &(myClass.F))
- {
- }
在关键字 fixed 后面的圆括号中,定义和初始化指针变量。这个指针变量的作用域是花括号标识的 fixed 块。这样, 垃圾回收器就知道,在执行 fixed 块中的代码时,不能移动 myClass 对象。
- MyClass myClass = new MyClass();
- fixed (long* pObject = &(myClass.L))
- {
- }
- fixed (long* pObject1 = &(myClass.L))
- fixed (float* pObject2 = &(myClass.F))
- {
- }
- fixed (long* pObject1 = &(myClass.L))
- {
- fixed (float* pObject2 = &(myClass.F))
- {
- }
- }
- fixed (long* pObject1 = &(myClass.L), pObject2 = &(myClass.L2))
- {
- }
栈的内存块始终占用的字节数总是4的倍数。
使用指针优化性能
创建基于栈的数组
C#很容易支持数组的处理,但也有一个缺点,这些数组都是对象,它们是 Syste.Array 的实例。因此数组存储在堆上,这会增加系统开销。有时,我们希望创建一个使用事件比较短的高性能数组,不希望有引用对象的系统开销。而使指针就可以做到,但指针只对于一维数组比较简单。
为了创建一个高性能的数组,需要使用另一个关键字 stackalloc。stackalloc 命令指示 .NET 运行库在栈上分配一定量的内存。在调用 stackalloc 命令时,需要为它提供两条信息:
- 要存储的数据类型
- 需要存储的数据项数
- // 分配足够的内存,存储10个 decimal
- decimal* pDiDecimals = stackalloc decimal[];
- // 上面命令只分配栈内存。它不会试图把内存初始化为任何默认值,正好符合我们的目的。
- // 因为要创建一个高性能的数组,给它不必要地初始化相应值会降低性能。
stackalloc 后面紧跟要存储的数据类型名(该数据类型必须是一个值类型),之后把需要的项数放在方括号中。分配的字节数是项数乘以sizeof(数据类型)。在这里,使用方括号表示这个一个数组。如果给20个 double 数分配存储单元,就得到了一个有20个元素的double数组,最简单的数组类型是逐个存储元素的内存块。
stackalloc 总是返回分配数据类型的指针,它指向新分配内存块的顶部。要使用这个内存块,可以取消对已返回指针的引用。
- // 分配20个double内存
- double* pDoubles = stackalloc double[];
- // 设置第一个元素 3.0
- *pDoubles = 3.0;
- // 访问第二个元素,直接加 1
- *(pDoubles + ) = 4.0;
- // 那么就可以用表达式 *(pDoubles + X) 访问数组中下标为 X 的元素,一种访问数组中元素的方式。
- // C# 提供另一种语法 p[X] 它会自动被编译器解释为 *(p + X) 。
- for (int i = ; i < ; i++)
- {
- Console.WriteLine(*(pDoubles + i));
- }
- pDoubles[] = 5.0;
- pDoubles[] = 8.4;
- for (int i = ; i < ; i++)
- {
- Console.WriteLine(pDoubles[i]);
- }
数组的语法应用于指针并不是新东西,它是C 和 C++ 语言的基础部分。
高性能的数组可以用与一般C#数组相同的方式访问,但也有不同。
- double[] doublesArray = new double[];
- // 会出现索引越界错误,但如果使用 stackalloc 就不会
- doublesArray[] = 3.0;
- double* pDoubles = stackalloc double[];
- pDoubles[] = 1.0;
上面代码分配了 20个double类型数的内存,接着把sizeof(double)存储单元的位置加上50*sizeof(double)个存储单元,来保存双精度值。但这个存储单元超出刚才为double数分配的内存区域。谁也不知道这个地址存储了什么数据。最好是只使用某个当前未使用的内存,但所重写的存储单元也有可能是在栈上用于存储其他变量,或者是某个正在执行的方法的返回地址。因此,使用指针获得高性能的同时,也会出现以一些代价,需要确保自己知道在做什么,否则就会抛出非常古怪的运行错误。
QuickArray示例
- unsafe
- {
- int size = ;
- long* pArray = stackalloc long[size];
- for (int i = ; i < size; i++)
- {
- pArray[i] = i * i;
- }
- for (int i = ; i < size; i++)
- {
- Console.WriteLine("{0} {1}", i, pArray[i]);
- }
- }
C# 内存管理和指针 (13)的更多相关文章
- C#高级编程9 第14章 内存管理和指针
C#高级编程9 内存管理和指针 后台内存管理 1) 值数据类型 在处理器的虚拟内存中有一个区域,称为栈,栈存储变量的浅副本数据,通过进入变量的作用域划分区域,通过离开变量的作用域释放. 栈的指针指向栈 ...
- C语言回顾-内存管理和指针函数
1.fgets()函数 该函数是一个文件操作相关的函数 暂时使用这个函数可以从键盘上接收一个字符串,保存到数组中 char str[50]; 1)scanf("%s",str);/ ...
- 【读书笔记】C#高级编程 第十四章 内存管理和指针
(一)后台内存管理 1.值数据类型 Windows使用一个虚拟寻址系统,该系统把程序可用的内存地址映射到硬件内存中的实际地址,该任务由Windows在后台管理(32位每个进程可使用4GB虚拟内存,64 ...
- c++ boost库学习二:内存管理->智能指针
写过C++的人都知道申请和释放内存组合new/delete,但同时很多人也会在写程序的时候忘记释放内存导致内存泄漏.如下所示: int _tmain(int argc, _TCHAR* argv[]) ...
- 《Troubleshooting SQL Server》读书笔记-内存管理
自调整的数据库引擎(Self-tuning Database Engine) 长期以来,微软都致力于自调整(Self-Tuning)的SQL Server数据库引擎,用以降低产品的总拥有成本.从SQL ...
- 麻省理工《C内存管理和C++面向对象编程》笔记---第一讲:认识C和内存管理
最近一年都在用.net和Java,现在需要用C了.昨天看到博客园首页的麻省理工开放课程,就找来看看,正好复习一下.这门<C内存管理和C++面向对象编程>不是那种上来就变量,循环的千篇一律的 ...
- C语言讲义——内存管理
动态分配内存 动态分配内存,在堆(heap)中分配. void *malloc(unsigned int num_bytes); 头文件 stdlib.h或malloc.h 向系统申请分配size个字 ...
- 13深入理解C指针之---内存管理
该系列文章源于<深入理解C指针>的阅读与理解,由于本人的见识和知识的欠缺可能有误,还望大家批评指教. 内存管理对所有程序都很重要,主要包括显式内存管理和隐式内存管理.其中隐式内存管理主要是 ...
- c++动态内存管理与智能指针
目录 一.介绍 二.shared_ptr类 make_shared函数 shared_ptr的拷贝和引用 shared_ptr自动销毁所管理的对象- -shared_ptr还会自动释放相关联对象的内存 ...
随机推荐
- python xlrd模块
一.什么是xlrd模块? Python操作excel主要用到xlrd和xlwt这两个库,即xlrd是读excel,xlwt是写excel的库. 二.使用介绍 1.常用单元格中的数据类型 类型 含义 e ...
- Spring mybatis源码篇章-动态SQL基础语法以及原理
通过阅读源码对实现机制进行了解有利于陶冶情操,承接前文Spring mybatis源码篇章-Mybatis的XML文件加载 前话 前文通过Spring中配置mapperLocations属性来进行对m ...
- Python+request超时和重试
Python+request超时和重试 一.什么是超时? 1.连接超时 连接超时指的是没连接上,超过指定的时间内都没有连接上,这就是连接超时.(连接时间就是httpclient发送请求的地方开始到连接 ...
- DB2创建EMP和DEPT并进行基础操作
一.DB2创建EMP和DEPT测试表 --DB2创建测试表 CREATE TABLE TEST.EMP (EMPNO INTEGER NOT NULL, ENAME ), JOB ), MGR INT ...
- vue去掉链接中的#
在router.js中修改, const router = new VueRouter({ mode: 'history', routes: [...] })
- Technocup 2020 - Elimination Round 1补题
慢慢来. 题目册 题目 A B C D tag math strings greedy dp 状态 √ √ √ √ //∅,√,× 想法 A. CME res tp A 题意:有\(n\)根火柴,额外 ...
- PID程序实现
传统PID(位置式PID控制)调节: 这种算法的缺点是,由于全量输出,每次输出均与过去的状态有关,计算时要对 e(k) 进行累加,计算机运算工作量大.而且,因为计算机输出的 u(k) 对应的是执行机构 ...
- shell习题第17题:检测磁盘
[题目要求] 写一个shell脚本,检测所有磁盘分区使用率和inode使用率并记录到以当天日期命名的日志文件里,当发现某个分区容量或者inode使用量大于85%时候,发邮件提醒 [核心要点] df d ...
- vue项目build 之后,css文件加载图片或者字体文件时404的解决。
ExtractTextWebpackPlugin 提供了一个 options.publicPath 的 api,可以为css单独配置 publicPath . 对于用 vue-cli 生成的项目,di ...
- Vasya's Function CodeForces - 837E (gcd)
大意: 给定$a,b$, $1\le a,b\le 1e12$, 定义 $f(a,0)=0$ $f(a,b)=1+f(a,b-gcd(a,b))$ 求$f(a,b)$. 观察可以发现, 每次$b$一定 ...