Scrapy爬虫框架与常用命令
07.08自我总结
一.Scrapy爬虫框架
大体框架
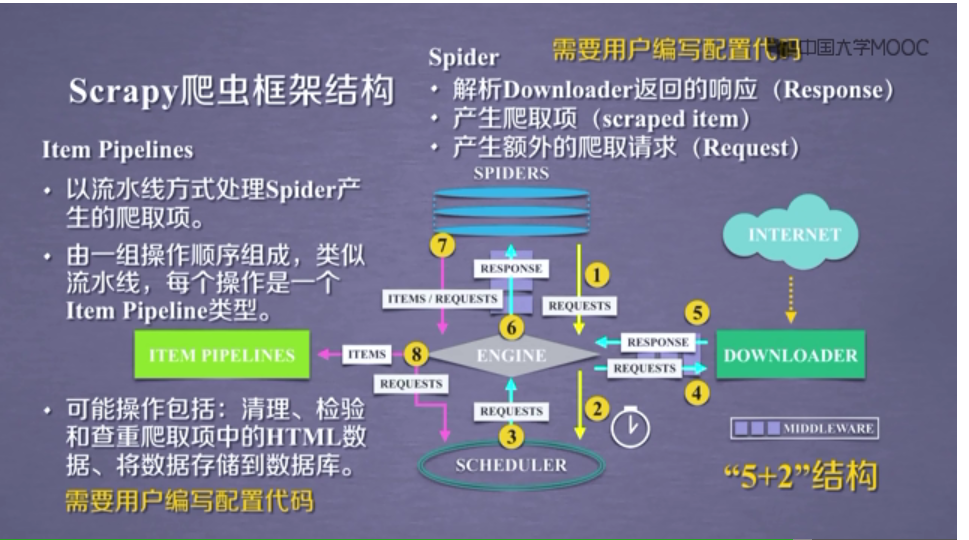
2个桥梁


二.常用命令
全局命令
startproject
语法:
scrapy startproject <project_name>这个命令是scrapy最为常用的命令之一,它将会在当前目录下创建一个名为
<project_name>的项目。settings
语法:
scrapy settings [options]该命令将会输出Scrapy默认设定,当然如果你在项目中运行这个命令将会输出项目的设定值。
runspider
语法:
scrapy runspider <spider_file.py>在未创建项目的情况下,运行一个编写在Python文件中的spider。
shell
语法:
scrapy shell [url]以给定的URL(如果给出)或者空(没有给出URL)启动Scrapy shell。
例如,
scrapy shell http://www.baidu.com
将会打开百度URL,
并且启动交互式命令行,可以用来做一些测试。
fetch
语法:
scrapy fetch <url>使用Scrapy下载器(downloader)下载给定的URL,并将获取到的内容送到标准输出。简单的来说,就是打印url的html代码。
view
语法:
scrapy view <url>在你的默认浏览器中打开给定的URL,并以Scrapy spider获取到的形式展现。 有些时候spider获取到的页面和普通用户看到的并不相同,一些动态加载的内容是看不到的, 因此该命令可以用来检查spider所获取到的页面。
version
语法:
scrapy version [-v]输出Scrapy版本。配合 -v 运行时,该命令同时输出Python, Twisted以及平台的信息。
项目命令
crawl
语法:
scrapy crawl <spider_name>使用你项目中的spider进行爬取,即启动你的项目。这个命令将会经常用到,我们会在后面的内容中经常使用。
check
语法:
crapy check [-l] <spider>运行contract检查,检查你项目中的错误之处。
list
语法:
scrapy list列出当前项目中所有可用的spider。每行输出一个spider。
genspider
语法:
scrapy genspider [-t template] <name> <domain>在当前项目中创建spider。该方法可以使用提前定义好的模板来生成spider。您也可以自己创建spider的源码文件。
Scrapy爬虫框架与常用命令的更多相关文章
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影
前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程. 工具和环境 语言:python 2 ...
- Scrapy 爬虫框架学习笔记(未完,持续更新)
Scrapy 爬虫框架 Scrapy 是一个用 Python 写的 Crawler Framework .它使用 Twisted 这个异步网络库来处理网络通信. Scrapy 框架的主要架构 根据它官 ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- scrapy爬虫框架学习笔记(一)
scrapy爬虫框架学习笔记(一) 1.安装scrapy pip install scrapy 2.新建工程: (1)打开命令行模式 (2)进入要新建工程的目录 (3)运行命令: scrapy sta ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- 安装scrapy 爬虫框架
安装scrapy 爬虫框架 个人根据学习需要,在Windows搭建scrapy爬虫框架,搭建过程种遇到个别问题,共享出来作为记录. 1.安装python 2.7 1.1下载 下载地址 1.2配置环境变 ...
随机推荐
- 写一个可拖动的 TShape(简单有效:依靠VCL体系,TShape自己就能被探测到被点击了,然后只要改变Left坐标就行了)
问题来源: http://www.cnblogs.com/del/archive/2009/03/09/1234066.html#1471535 本例效果图: 自定义类(TMyShape)单元 : u ...
- list 多行表头 表头合并
http://blog.csdn.net/safedebug/article/details/52971685
- 转载几篇文章URL
读了百伯在线Jobbole的几篇文章,转给需要的朋友.如下: 产品小设计大体验:http://blog.jobbole.com/39593/ 苹果是一家有工程师的设计公司:Google是一家有设计师的 ...
- vue-cli脚手架 ,过滤器,生命周期钩子函数
一.安装vue-cli脚手架 1.淘宝镜像下载 用淘宝的国内服务器来向国外的服务器请求,我们向淘宝请求,而不是由我们直接向国外的服务器请求,会大大提升请求速度,使用时,将所有的npm命令换成cnpm即 ...
- 一步步教你怎么用python写贪吃蛇游戏
目录 0 引言 1 环境 2 需求分析 3 代码实现 4 后记 0 引言 前几天,星球有人提到贪吃蛇,一下子就勾起了我的兴趣,毕竟在那个Nokia称霸的年代,这款游戏可是经典中的经典啊!而用Pytho ...
- 如何有效预防XSS?这几招管用!!!
原文链接 预防XSS,这几招管用 最近重温了一下「黑客帝国」系列电影,一攻一防实属精彩,生活中我们可能很少有机会触及那么深入的网络安全问题,但工作中请别忽略你身边的精彩 大家应该都听过 XSS (Cr ...
- 移动端使用rem.js,解决rem.js 行内元素占位问题
父级元素: letter-spacing: -0.5em;font-size: 0; 子级元素: letter-spacing: normal; display: inline-block; vert ...
- C# 设计模式,工厂方法
C#工厂方法 using System; using System.Collections.Generic; using System.Linq; using System.Text; using S ...
- Python自学day-11
一.RabbitMQ概述 RabbitMQ是一种消息队列,是一个公共的消息中间件,用于不同进程之间的通讯. 除了RabbitMQ以外,还有ZeroMQ.ActiveMQ等等. 前面学习了两种队列: 线 ...
- 给 Windows 的终端配置代理
初衷 由于项目开发使用go,所以经常要用到go get,但是吧,terminal下根本没办法下载啊,经常下载三个小时包,写代码一个小时 迫于无奈,只好找个方式可以在terminal下使用ss cmd下 ...