springcloud -- sleuth+zipkin整合rabbitMQ详解
为什么使用RabbitMQ?
我们已经知道,zipkin的原理是服务之间的调用关系会通过HTTP方式上报到zipkin-server端,然后我们再通过zipkin-ui去调用查看追踪服务之间的调用链路。但是这种方式存在一个隐患,如果微服务之间与zipkin服务端网络不通,或调用链路上的网络闪断,http通信收集方式就无法工作。而且zipkin默认是将数据存储在内存中的,如果服务端重启或宕机,就会导致数据丢失。
所以我们不仅将数据存储在zipkin-serve中,同时还能通过某个消息存储的容器将本次调用其他服务的消息数据进行持久化存储,这样不就可以解决问题吗?结合RabbitMQ证好解决了这一问题,再发一份到消息队列中去。
安装RabbitMQ
查找镜像
- 进入docker hub镜像仓库地址:https://hub.docker.com/_/rabbitmq?tab=description ,选择带有 "management" 的版本(包含管理界面)
- docker 搜素下载
docker search rabbitmq:management

拉取镜像
docker pull rabbitmq:3.7.7-management // 1
docker pull rabbitmq:management // 2
运行rabbitMQ
docker run -d -p 5672:5672 -p 15672:15672 --name rabbitmq rabbitmq:management
此方式默认用户名:guest,密码:guest,手动配置参考:
-d 后台运行容器;
--name 指定容器名;
-p 指定服务运行的端口(5672:应用访问端口;15672:控制台Web端口号);
-v 映射目录或文件;
--hostname 主机名(RabbitMQ的一个重要注意事项是它根据所谓的 “节点名称” 存储数据,默认为主机名);
-e 指定环境变量;(RABBITMQ_DEFAULT_VHOST:默认虚拟机名;RABBITMQ_DEFAULT_USER:默认的用户名;RABBITMQ_DEFAULT_PASS:默认用户名的密码)
查看正在运行的容器
docker container ps
访问rabbitMQ WEB管理界面
访问地址 http://192.168.2.28:15672/#/queues,这时候应该是啥也没有的

zipkin-server
上一篇文章用的是docker快速启动,这篇文章用jar包启动模式,因为配置方便,不用写docker-compose.yml 环境配置文件
- 下载jar包,地址 https://search.maven.org/remote_content?g=io.zipkin&a=zipkin-server&v=LATEST&c=exec
- 运行jar包
java -jar zipkin-server-2.17.0-exec.jar --zipkin.collector.rabbitmq.addresses=localhost
后面的--zipkin.collector.rabbitmq.addresses=localhost 就是RabbitMQ的配置,这是默认的
如果要自己指定的用户名和密码可以参考下面的启动命令:
java -jar zipkin-server-2.17.0-exec.jar --zipkin.collector.rabbitmq.addresses=localhost --zipkin.collector.rabbitmq.username=guest --zipkin.collector.rabbitmq.password=guest
- 可配置的环境变量参考表
| 属性 | 环境变量 | 描述 |
|---|---|---|
| zipkin.collector.rabbitmq.concurrency | RABBIT_CONCURRENCY | 并发消费者数量,默认为 1 |
| zipkin.collector.rabbitmq.connection-timeout | RABBIT_CONNECTION_TIMEOUT | 建立连接时的超时时间,默认为 60000 毫秒,即 1 分钟 |
| zipkin.collector.rabbitmq.queue | RABBIT_QUEUE | 从中获取 span 信息的队列,默认为 zipkin |
| zipkin.collector.rabbitmq.uri | RABBIT_URI | 符合 RabbitMQ URI 规范 的 URI,例如 amqp://user:pass@host:10000/vhost |
如果设置了URL,则以下属性将被忽略
| 属性 | 环境变量 | 描述 |
|---|---|---|
| zipkin.collector.rabbitmq.addresses | RABBIT_ADDRESSES | 用逗号分隔的 RabbitMQ 地址列表,例如 localhost:5672,localhost:5673 |
| zipkin.collector.rabbitmq.password | RABBIT_PASSWORD | 连接到 RabbitMQ 时使用的密码,默认为 guest |
| zipkin.collector.rabbitmq.username | RABBIT_USER | 连接到 RabbitMQ 时使用的用户名,默认为 guest |
| zipkin.collector.rabbitmq.virtual-host | RABBIT_VIRTUAL_HOST | 使用的 RabbitMQ virtual host,默认为 / |
| zipkin.collector.rabbitmq.use-ssl | RABBIT_USE_SSL | 设置为 true 则用 SSL 的方式与 RabbitMQ 建立链接 |
启动时终端界面

此时再查看以下RabbitMQ,有一个地址已经连接上了
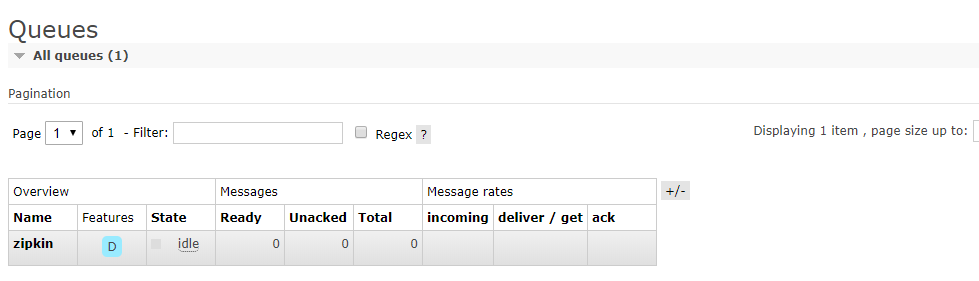
zipkin也已经启动
docker 模式启动
- 编写
docker-compose.yml文件
version: '2'
services:
zipkin:
container_name: zipkin
image: openzipkin/zipkin
environment:
- RABBIT_ADDRESSES=ivms.io:5672
- RABBIT_USER=guest
- RABBIT_PASSWORD=guest
ports:
- 9411:9411
- 在文件目录下执行
docker-compose up -d
配置微服务
- 各微服务中加入以下依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>
参考上一篇文章 springcloud --- spring cloud sleuth和zipkin日志管理(spring boot 2.18)
此时配置如下
zipkin:
#base-url: http://192.168.2.28:9411
sender:
type: rabbit
sleuth:
sampler:
probability: 0.1
rate: 2
rabbitmq:
addresses: ivms.io:5672
注:指定sender.type为rabbit后,base-url就不需要了,其他一致
其他的不用改,也有人在微服务中添加了下面的配置,但效果是一样的,可以试一下
#如果是使用rabbitmq则需要下面的配置
spring.zipkin.sender.type= rabbit
#添加rabbitmq的配置
spring.rabbitmq.host=localhost
spring.rabbitmq.port=5672
spring.rabbitmq.username=guest
spring.rabbitmq.poassword=guest
spring.rabbitmq.listener.direct.retry.enabled=true
spring.rabbitmq.listener.simple.retry.enabled=true
启动微服务测试
启动微服务,发起一个请求,观察变化如下:

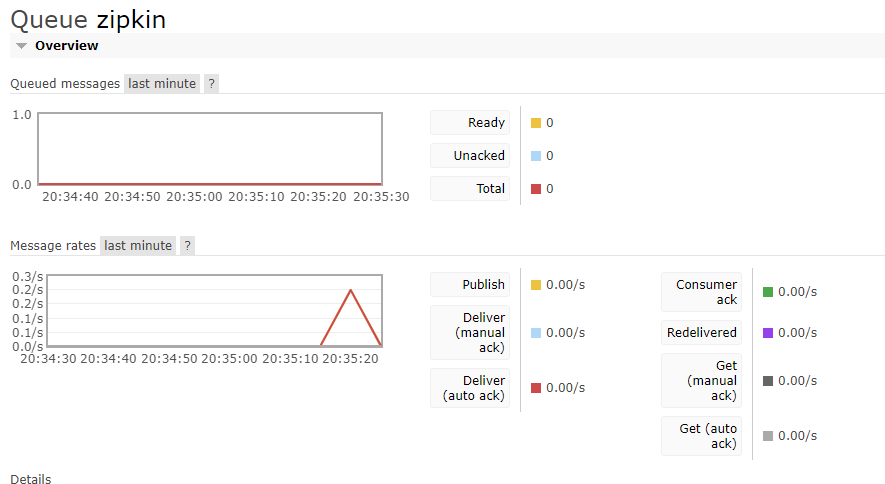
到此我们的服务已经调试成功!
如果需要加入Elasticsearch,也非常简单,安装步骤参考
然后在启动命令中加入ES配置就可以
java -jar zipkin-server-2.9.4-exec.jar --zipkin.collector.rabbitmq.addresses=localhost --STORAGE_TYPE=elasticsearch --ES_HOSTS=http://127.0.0.1:9200
参考文章:https://blog.csdn.net/zhangcongyi420/article/details/100809550
进阶中的菜鸟,欢迎留言探讨,指正不足!
springcloud -- sleuth+zipkin整合rabbitMQ详解的更多相关文章
- SpringCloud Sleuth + Zipkin 实现链路追踪
一.Sleuth介绍 为什么要使用微服务跟踪? 它解决了什么问题? 1.微服务的现状? 随着业务的发展,单体架构变为微服务架构,并且系统规模也变得越来越大,各微服务间的调用关系也变得越来越复杂 ...
- Apache2.2+Tomcat7.0整合配置详解
一.简单介绍 Apache.Tomcat Apache HTTP Server(简称 Apache),是 Apache 软件基金协会的一个开放源码的网页服务器,可以在 Windows.Unix.Lin ...
- spring-boot(五) RabbitMQ详解 定时任务
学习文章来自:springboot(八):RabbitMQ详解 springboot(九):定时任务 RabbitMQ 即一个消息队列,主要是用来实现应用程序的异步和解耦,同时也能起到消息缓冲,消息分 ...
- .Net使用RabbitMQ详解 转载http://www.cnblogs.com/knowledgesea/p/5296008.html
.Net使用RabbitMQ详解 序言 这里原来有一句话,触犯啦天条,被阉割!!!! 首先不去讨论我的日志组件怎么样.因为有些日志需要走网络,有的又不需要走网路,也是有性能与业务场景的多般变化在其 ...
- RabbitMQ详解(三)------RabbitMQ的五种模式
RabbitMQ详解(三)------RabbitMQ的五种模式 1.简单队列(模式) 上一篇文章末尾的实例给出的代码就是简单模式. 一个生产者对应一个消费者!!! pom.xml 必须导入Rab ...
- Spring Boot(八):RabbitMQ详解
Spring Boot(八):RabbitMQ详解 RabbitMQ 即一个消息队列,主要是用来实现应用程序的异步和解耦,同时也能起到消息缓冲,消息分发的作用. 消息中间件在互联网公司的使用中越来越多 ...
- RabbitMQ详解(一)------简介与安装(Docker)
RABBITMQ详解(一)------简介与安装(DOCKER) 刚刚进入实习,在学习过程中没有接触过MQ,RabbitMQ 这个消息中间件,正好公司最近的项目中有用到,学习了解一下. 首先什么是MQ ...
- SpringBoot与PageHelper的整合示例详解
SpringBoot与PageHelper的整合示例详解 1.PageHelper简介 PageHelper官网地址: https://pagehelper.github.io/ 摘要: com.gi ...
- VUE SpringCloud 跨域资源共享 CORS 详解
VUE SpringCloud 跨域资源共享 CORS 详解 作者: 张艳涛 日期: 2020年7月28日 本篇文章主要参考:阮一峰的网络日志 » 首页 » 档案 --跨域资源共享 CORS 详解 ...
随机推荐
- Mongodb操作2-windows系统安装数据库
1.下载mongodb 本人提供的是64位的下载地址 百度云盘连接 :链接:https://pan.baidu.com/s/1fp6aB5rvLa9dD4q4YysIXQ 提取码:ekr2 并送 ...
- [Error]Win8安装程序出现2502、2503错误解决方法
转载自:http://jingyan.baidu.com/article/a501d80cec07daec630f5e18.html 在Win8中,在安装msi安装包的时候常常会出现代码为2502.2 ...
- CodeForces 804C Ice cream coloring
Ice cream coloring 题解: 这个题目中最关键的一句话是, 把任意一种类型的冰激凌所在的所有节点拿下来之后,这些节点是一个连通图(树). 所以就不会存在多个set+起来之后是一个新的完 ...
- Marvelous Mazes UVA - 445
#include<iostream> #include<stdio.h> #include<string> #include<cstring> #def ...
- 文档打印 js print调用打印dom内容
1.首先按目前研究 print可以打印dom 2.被设置overflow:hidden 的模块,打印时会被截掉. 3.被设置成 display:none 的dom 打印不会有样式 边框等. 4.如果需 ...
- 【Offer】[9] 【用两个栈实现队列】
题目描述 思路分析 Java代码 代码链接 题目描述 用两个栈实现队列 思路分析 栈--> 先进后出 队列--> 先进先出 进队列操作,选择栈s1进栈,关键在与实现出队列操作,要考虑到队列 ...
- java课堂测试样卷-----简易学籍管理系统
程序设计思路:分别建立两个类:ScoreInformation类(用来定义学生的基本信息以及设置set和get函数)ScoreManagement类(用来定义实现学生考试成绩录入,考试成绩修改,绩点计 ...
- vue基础技术点列表(一)
一. vue编写需要注意的细节1.vue初始化实例时使用首字母大写,在添加全局配置时也要首字母大写(如添加组件Vue.component("",{template:"&q ...
- 史无前例的RNN讲解
这篇博客不是一篇讲解原理的博客,这篇博客主要讲解time_steps,如果这篇博客没有让你明白time_steps,那么算我无能. 我曾翻阅各大网站,各大博客,他们的对RNN中time_steps的讲 ...
- 最佳内存缓存框架Caffeine
Caffeine是一种高性能的缓存库,是基于Java 8的最佳(最优)缓存框架. Cache(缓存),基于Google Guava,Caffeine提供一个内存缓存,大大改善了设计Guava's ca ...