spark 源码分析之十一--Spark RPC剖析之TransportClient、TransportServer剖析
TransportClient类说明
先来看,官方文档给出的说明:
Client for fetching consecutive chunks of a pre-negotiated stream. This API is intended to allow efficient transfer of a large amount of data, broken up into chunks with size ranging from hundreds of KB to a few MB.
Note that while this client deals with the fetching of chunks from a stream (i.e., data plane), the actual setup of the streams is done outside the scope of the transport layer. The convenience method "sendRPC" is provided to enable control plane communication between the client and server to perform this setup.
For example, a typical workflow might be:
client.sendRPC(new OpenFile("/foo")) --> returns StreamId = 100
client.fetchChunk(streamId = 100, chunkIndex = 0, callback)
client.fetchChunk(streamId = 100, chunkIndex = 1, callback)
...
client.sendRPC(new CloseStream(100))
Construct an instance of TransportClient using TransportClientFactory. A single TransportClient may be used for multiple streams, but any given stream must be restricted to a single client, in order to avoid out-of-order responses.
NB: This class is used to make requests to the server, while TransportResponseHandler is responsible for handling responses from the server. Concurrency: thread safe and can be called from multiple threads.
用于获取预先协商的流的连续块的客户端。此API允许有效传输大量数据,分解为大小从几百KB到几MB的chunk。
注意,虽然该客户端处理从流(即,数据平面)获取chunk,但是流的实际设置在传输层的范围之外完成。提供便利方法“sendRPC”以使客户端和服务器之间的控制平面通信能够执行该设置。
例如,典型的工作流程可能是:
// 打开远程文件
client.sendRPC(new OpenFile(“/ foo”)) - >返回StreamId = 100
// 打开获取远程文件chunk-0
client.fetchChunk(streamId = 100,chunkIndex = 0,callback)
// 打开获取远程文件chunk-1
client.fetchChunk(streamId = 100,chunkIndex = 1,callback)
.. .
// 关闭远程文件
client.sendRPC(new CloseStream(100))
使用TransportClientFactory构造TransportClient的实例。
单个TransportClient可以用于多个流,但是任何给定的流必须限制在单个客户端,以避免无序响应。
注意:此类用于向服务器发出请求,而TransportResponseHandler负责处理来自服务器的响应。并发:线程安全,可以从多个线程调用。
简言之,可以认为TransportClient就是Spark Rpc 最底层的基础客户端类。主要用于向server端发送rpc 请求和从server 端获取流的chunk块。
下面看一下类的结构:
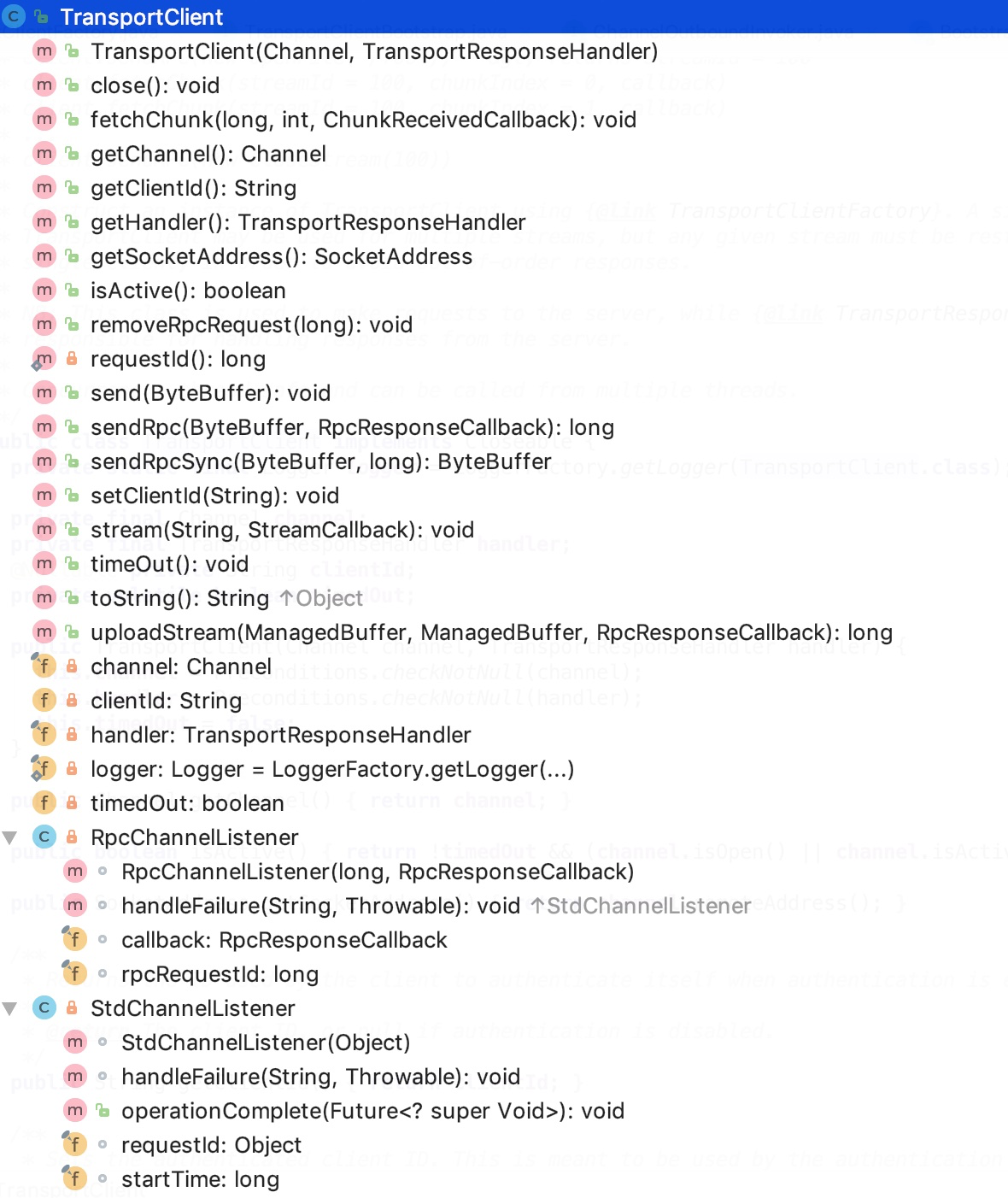
它有两个内部类:RpcChannelListener和StdChannelListener,这两个类的继承关系如下:
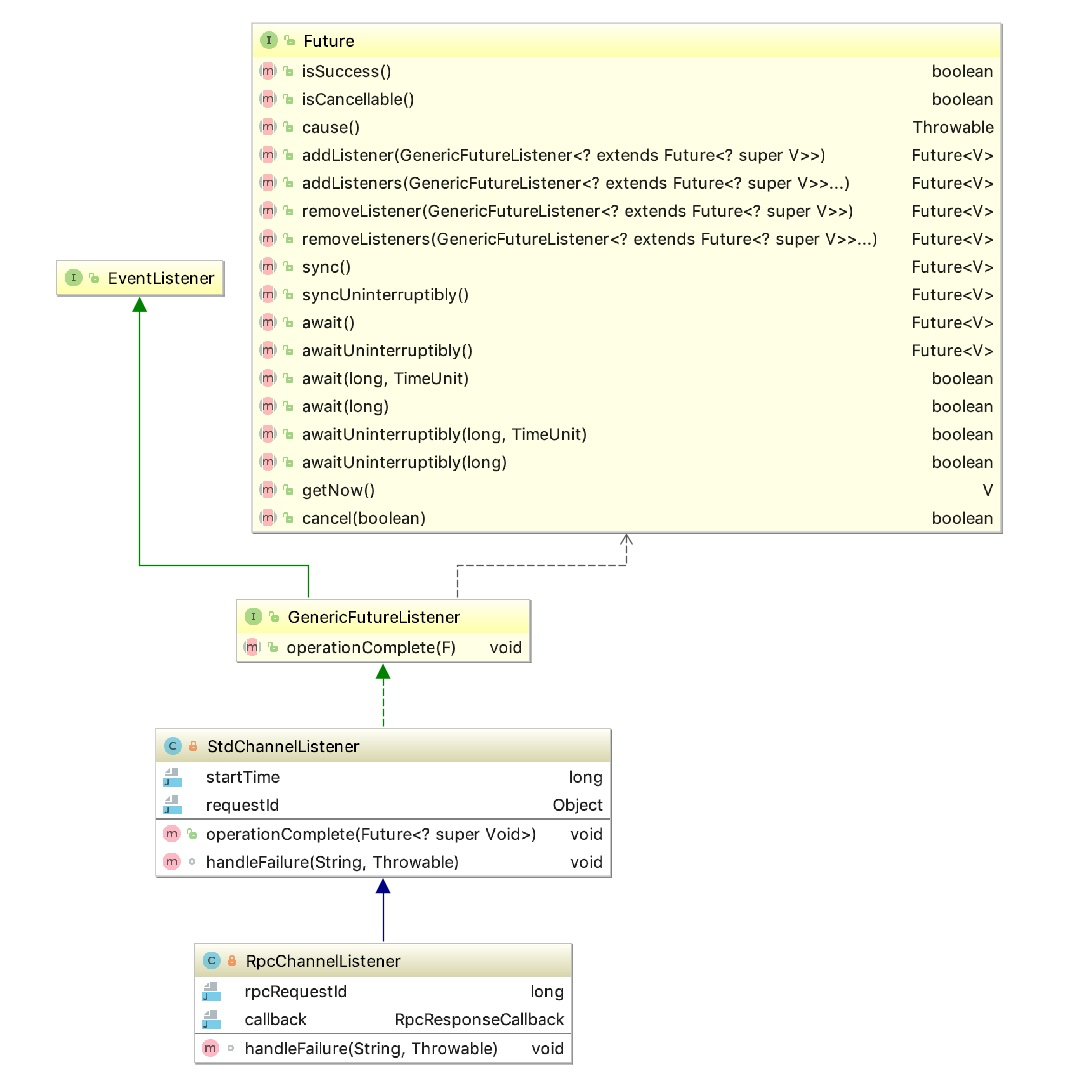
其公共父类GenericFutureListener 官方说明如下:
Listens to the result of a Future. The result of the asynchronous operation is notified once this listener is added by calling Future.addListener(GenericFutureListener).
即,监听一个Future 对象的执行结果,通过Future.addListener(GenericFutureListener)的方法,添加监听器来监听这个异步任务的最终结果。当异步任务执行成功之后,会调用监听器的 operationComplete 方法。在StdChannelListener 中,其operationComplete 方法其实就是添加了日志打印运行轨迹的作用,添加了异常的处理方法 handleFailure,它是一个空实现,如下:

其子类RpcChannelListener的handleFailure实现如下:
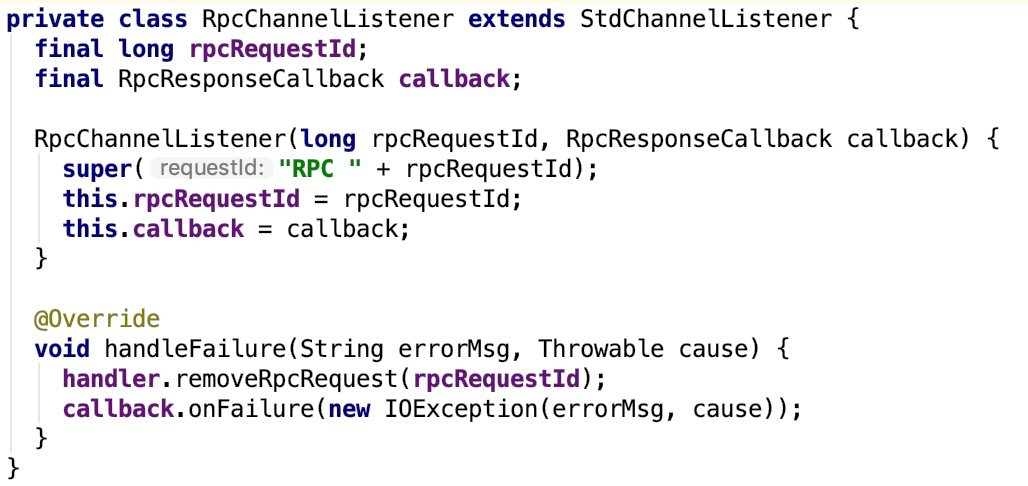
这个handleFailure 方法充当着失败处理转发的作用。其调用了 RpcResponseCallback (通过构造方法传入)的 onFailure 方法。
再来看一下TransportClient 的主要方法解释:
1. fetchChunk : Requests a single chunk from the remote side, from the pre-negotiated streamId. Chunk indices go from 0 onwards. It is valid to request the same chunk multiple times, though some streams may not support this. Multiple fetchChunk requests may be outstanding simultaneously, and the chunks are guaranteed to be returned in the same order that they were requested, assuming only a single TransportClient is used to fetch the chunks.其源码如下:
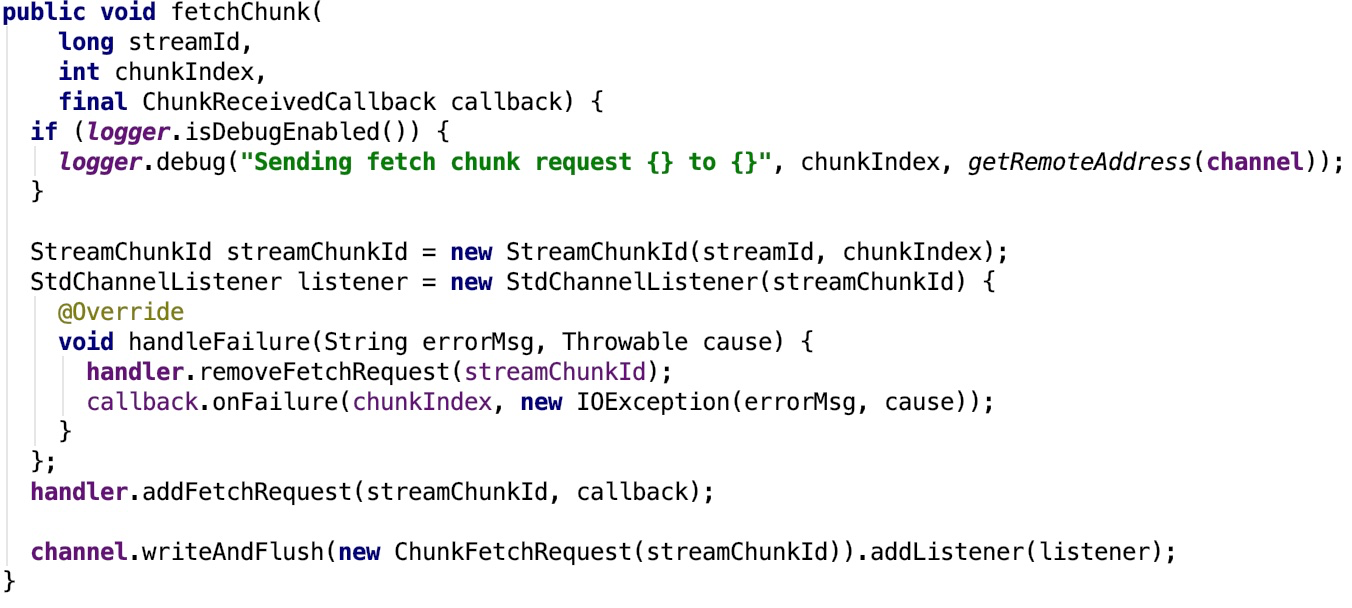
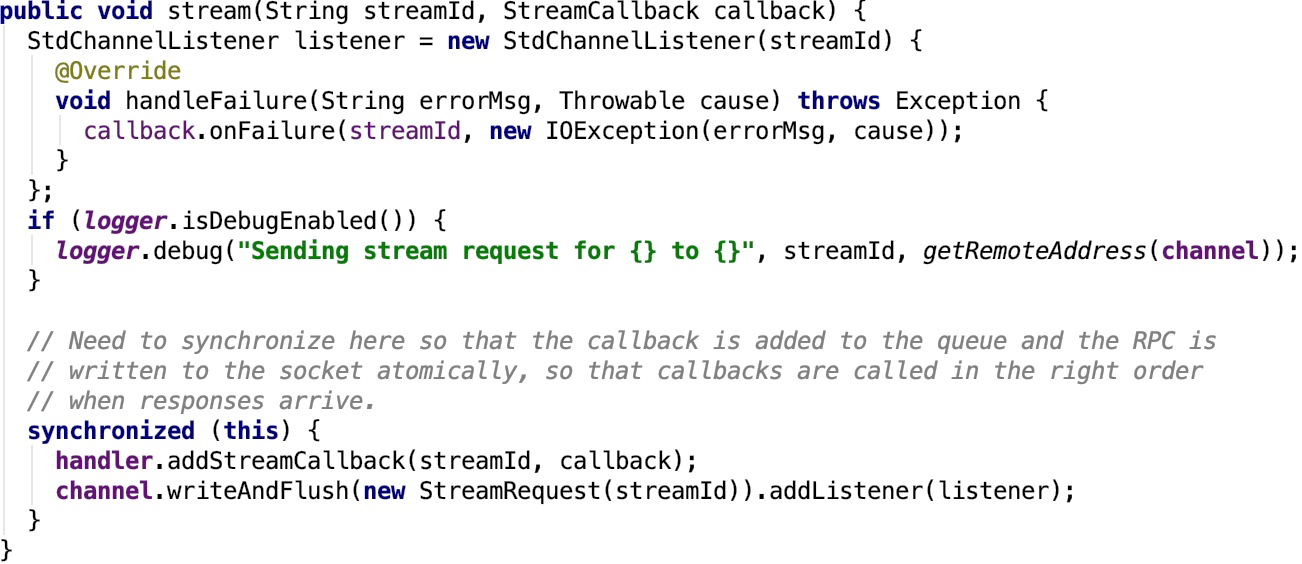
2. stream:Request to stream the data with the given stream ID from the remote end.其源码如下:
3. sendRpc:Sends an opaque message to the RpcHandler on the server-side. The callback will be invoked with the server's response or upon any failure.

4. uploadStream:Send data to the remote end as a stream. This differs from stream() in that this is a request to *send* data to the remote end, not to receive it from the remote.

5. sendRpcSync:Synchronously sends an opaque message to the RpcHandler on the server-side, waiting for up to a specified timeout for a response.

6. send:Sends an opaque message to the RpcHandler on the server-side. No reply is expected for the message, and no delivery guarantees are made.

7. removeRpcRequest:Removes any state associated with the given RPC.主要是从handler 中把监听的rpcRequest移除。
8. close:close the channel
9. timeOut: Mark this channel as having timed out.
可以看出,其主要是一个比较底层的客户端,主要用于发送底层数据的request,主要是数据层面的流中的chunk请求或者是控制层面的rpc请求,发送数据请求的方法中都有一个回调方法,回调方法是用于处理请求返回的结果。
TransportClient初始化
它是由TransportClientFactory 创建的。看TransportClientFactory 的核心方法: createClient(java.net.InetSocketAddress)的关键代码如下:
1 // 1. 添加一个 ChannelInitializer 的 handler
2 bootstrap.handler(new ChannelInitializer<SocketChannel>() {
3 @Override
4 public void initChannel(SocketChannel ch) {
5 TransportChannelHandler clientHandler = context.initializePipeline(ch);
6 clientRef.set(clientHandler.getClient());
7 channelRef.set(ch);
8 }
9 });
10
11 // Connect to the remote server
12 long preConnect = System.nanoTime();
13 // 2. 连接到远程的服务端,返回一个ChannelFuture 对象,调用其 await 方法等待其结果返回。
14 ChannelFuture cf = bootstrap.connect(address);
15 // 3. 等待channelFuture 对象其结果返回。
16 if (!cf.await(conf.connectionTimeoutMs())) {
17 throw new IOException(
18 String.format("Connecting to %s timed out (%s ms)", address, conf.connectionTimeoutMs()));
19 } else if (cf.cause() != null) {
20 throw new IOException(String.format("Failed to connect to %s", address), cf.cause());
21 }
在connect 方法中,初始化了handler。handler 被添加到ChannelPipiline之后,使用线程池来处理初始化操作,其调用了 DefaultChannelPipeline的callHandlerAdded0 方法,callHandlerAdded0调用了handler 的 handlerAdded 方法,handlerAdded内部调用了 initChannel 私有方法,initChannel又调用了保护抽象方法 initChannel,其会调用 ChannelInitializer自定义匿名子类的initChannel 方法。在这个 initChannel 方法中调用了TransportContext 的initializePipeline方法,在这个方法中实例化了 TransportClient对象。
我们再来看一下TransportContext 的initializePipeline方法的核心方法createChannelHandler:

再来看 NettyRpcEnv 是如何初始化transportContext 的:

从上面可以看到 rpcHandler 是NettyRpcHandler, 其依赖三个对象,Dispatcher 对象,nettyEnv 对象以及StreamManager 对象。
Dispatcher 对象已经有做说明,可以看我的博客spark 源码分析之六 -- Spark内置RPC机制剖析之二Dispatcher和Inbox剖析做进一步了解。
NettyEnv 对象就是NettyRpcEnv 对象。
NettyRpcHandler已经有做说明,可以看我的博客spark 源码分析之九 -- Spark内置RPC机制剖析之五StreamManager和NettyRpcHandler做进一步了解。
即channelRpcHandler 就是NettyRpcHandler实例。
关于TransportResponseHandler、TransportRequestHandler和TransportChannelHandler三个类的说明,可以参照博客spark 源码分析之十 -- Spark内置RPC机制剖析之六TransportResponseHandler、TransportRequestHandler和TransportChannelHandler剖析 做进一步了解。
TransportServer
官方说明:
Server for the efficient, low-level streaming service.
即:用于高效,低级别流媒体服务的服务器。
使用TransportContext createServer方法创建:

其构造方法源码如下:

重点看其init方法:

ServerBootstrap是用于初始化Server的。跟TransportClientFactory创建TransportClient类似,也有ChannelInitializer的回调,跟Bootstrap类似。参照上面的剖析。
至此,TransClient和TransServer的剖析完毕。
spark 源码分析之十一--Spark RPC剖析之TransportClient、TransportServer剖析的更多相关文章
- spark 源码分析之十--Spark RPC剖析之TransportResponseHandler、TransportRequestHandler和TransportChannelHandler剖析
spark 源码分析之十--Spark RPC剖析之TransportResponseHandler.TransportRequestHandler和TransportChannelHandler剖析 ...
- spark 源码分析之十七 -- Spark磁盘存储剖析
上篇文章 spark 源码分析之十六 -- Spark内存存储剖析 主要剖析了Spark 的内存存储.本篇文章主要剖析磁盘存储. 总述 磁盘存储相对比较简单,相关的类关系图如下: 我们先从依赖类 Di ...
- spark 源码分析之九--Spark RPC剖析之StreamManager和RpcHandler
StreamManager StreamManager类说明 StreamManager 官方说明如下: The StreamManager is used to fetch individual c ...
- spark 源码分析之十二 -- Spark内置RPC机制剖析之八Spark RPC总结
在spark 源码分析之五 -- Spark内置RPC机制剖析之一创建NettyRpcEnv中,剖析了NettyRpcEnv的创建过程. Dispatcher.NettyStreamManager.T ...
- Spark 源码分析系列
如下,是 spark 源码分析系列的一些文章汇总,持续更新中...... Spark RPC spark 源码分析之五--Spark RPC剖析之创建NettyRpcEnv spark 源码分析之六- ...
- spark 源码分析之十八 -- Spark存储体系剖析
本篇文章主要剖析BlockManager相关的类以及总结Spark底层存储体系. 总述 先看 BlockManager相关类之间的关系如下: 我们从NettyRpcEnv 开始,做一下简单说明. Ne ...
- Spark源码分析 – 汇总索引
http://jerryshao.me/categories.html#architecture-ref http://blog.csdn.net/pelick/article/details/172 ...
- Spark源码分析 – BlockManager
参考, Spark源码分析之-Storage模块 对于storage, 为何Spark需要storage模块?为了cache RDD Spark的特点就是可以将RDD cache在memory或dis ...
- spark 源码分析之五 -- Spark内置RPC机制剖析之一创建NettyRpcEnv
在前面源码剖析介绍中,spark 源码分析之二 -- SparkContext 的初始化过程 中的SparkEnv和 spark 源码分析之四 -- TaskScheduler的创建和启动过程 中的C ...
随机推荐
- python中的基本数据类型之列表,元组
一.列表 1.什么是列表. 列表是python的基本数据类型之一,用[]来表示,可以存放各种数据类型(什么都能装,能装对象的对象) 列表相比于字符串,不仅可以存放不同类型的数据,而且可以存放大量的数据 ...
- 【JRebel 作者出品--译文】Java class 热更新:关于对象,类,类加载器
一篇大神的译文,勉强(嗯..相当勉强)地放在类加载器系列吧,第8弹: 实战分析Tomcat的类加载器结构(使用Eclipse MAT验证) 还是Tomcat,关于类加载器的趣味实验 了不得,我可能发现 ...
- 跟我学SpringCloud | 第二篇:注册中心Eureka
Eureka是Netflix开源的一款提供服务注册和发现的产品,它提供了完整的Service Registry和Service Discovery实现.也是springcloud体系中最重要最核心的组 ...
- 给 Windows 的终端配置代理
初衷 由于项目开发使用go,所以经常要用到go get,但是吧,terminal下根本没办法下载啊,经常下载三个小时包,写代码一个小时 迫于无奈,只好找个方式可以在terminal下使用ss cmd下 ...
- 【dateFormatSymbols】JAVA特殊日期格式转换
记录:特殊日期格式转换,如将yyyyMMdd转为01MAY2019 public static final String DATE_VIP_FORMAT = "yyyyMMdd"; ...
- linux配置多个tomcat
1.修改tomcat目录下面conf/server.xml,修改shutdown的port和http port 2.修改bin/catalina.sh 在最前面加上 export CATALINA_B ...
- 长春理工大学第十四届程序设计竞赛(重现赛)J
J.Printout 题目:链接:https://ac.nowcoder.com/acm/contest/912/J 题目: 小r为了打校赛,他打算去打字社打印一份包含世界上所有算法的模板. 到了打字 ...
- Codeforces 755A:PolandBall and Hypothesis(暴力)
http://codeforces.com/problemset/problem/755/A 题意:给出一个n,让你找一个m使得n*m+1不是素数. 思路:暴力枚举m判断即可. #include &l ...
- 有意思的 CDN
Clean Clean false 7.8 磅 0 2 false false false EN-US ZH-CN AR-SA /* Style Definitions */ table.MsoNor ...
- Anemic Model
In object-oriented programming, and especially in Domain-Driven Design, objects are said to be anemi ...