网络流(2)——用Ford-Fullkerson算法寻找最大流
寻找最大流
在大规模战争中,后勤补给是重中之重,为了尽最大可能满足前线的物资消耗,后勤部队必然要充分利用每条运输网,这正好可以用最大流模型解决。如何寻找一个复杂网络上的最大流呢?
直觉上的方案
一种直觉上的方案是在一个流网络找到一条从源点到汇点的未充分利用的有向路径,然后增加该路径的流量,反复迭代,直到没有这样的路径为止。广度优先搜索可以在一个流网络中找到这样的路径,这种路径一旦被开充分利用,就会因为达到了最大流量而被“填满”,下次不必再打这条路径的主意。问题是,这样做就一定会得到最大流吗?考虑图下面的网络。
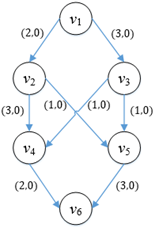
图1
两条明显的路径是v1→v2→v4→v6和v1→v3→v5→v6,依次“填满”两条路径:
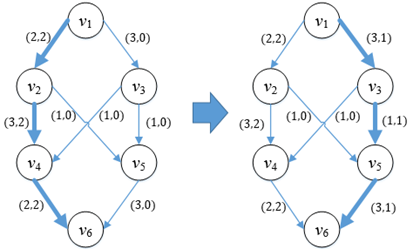
图2
此时已经无法再找到新的路径,因此判断最大流是3。然而3并不是最大流,真正的最大流是4:
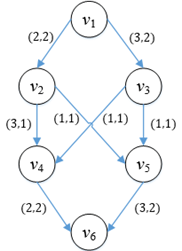
图3
看来寻找最大流并没有那么简单。为了应对这种情况,需要引入残存网的概念。
残存网
残存网也叫余留网、剩余网,它由原网络中没有被充分利用的边构成。假设有一个流网络G和它的网络流f,G的残存网用Gf表示,我们这样构造一个初始的Gf:Gf和G有同样的顶点,对于原网络中的各条边,Gf将有1条或2条边与之对应,每条边只记录了容量。对于G的一条边v→w,C(v→w)和f(v→w)代表了该边的容量和流量,如果f(v→w)的值为正,则在残存网中包含了一条容量为f(v→w)的边w→v,这条边是原网络中没有的逆向边;如果f(v→w)小于C(v→w),则在残存网中会一条容量为C(v→w)- f(v→w)的边v→w,这条边与原网络同向,它的容量是原网络中v→w的剩余容量;如果原网络中v→w是满边,则残存网中不存在v→w。图8.9展示了一个流网络对应的残存网。

图4
残存网中只记录容量,不记录流量,流量是通过逆向边的容量记录的。由于在原网络中v4→v6是满边,所以残存网中不存在v4→v6,相当于v4→v6的剩余容量用光了,即Cf(v4→v6)=0。由于残存网和原网络存在对应关系,所以增加原网络的流量相当于调整残存网。
增广路径
增广路径是残存网中一条连接源点和汇点的简单有向路径,也称为扩充路径。上图中v1→v3→v5→v6就是一条增广路径。
一条增广路径代表着原网络中一条尚未被充分利用的路径,如果想让这条路径得到充分利用,势必会把增广路径上的一条边的剩余容量用完,这样一来,残存网至少会有一条边消失,或直接调转方向:
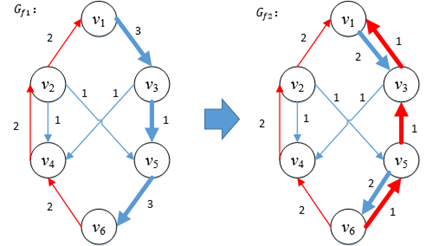
图5
Gf1上v3→v5的剩余容量被用完,所以在Gf2上删除v3→v5,并增加1条反向的边v5→v3,同时增加另外2条反向边v3→v1和v6→v5,并更新v1→v3和v5→v6的剩余容量。只要增广路径v1→v3→v5→v6得到充分利用,那么原网络上的相应路径也将得到充分利用:

图6
可以看出,原网络的v3→v5已经变成了满边,此时v1→v3→v5→v6也不存在继续扩充的余地。
增广路径在告诉我们一个结论,只要把残存网上的增广路径用完,原网络就无法继续扩充,意味着得到了最大网络流。现在,图5残存网Gf2中似乎没有一条连接源点和汇点的路径了,如果就这样结束,则仍然无法找到最大流,怎么办呢?别忘了,残存网中还有逆向边,因此还有一条增广路径,这就是v1→v3→v4→v2→v5→v6,我们填满该路径。
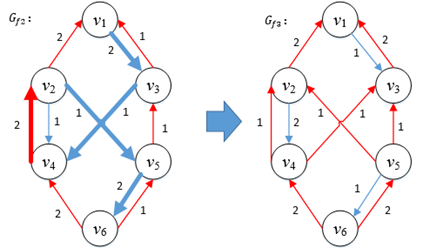
图7
在Gf2中,有1个单位的流量流过v4→v2,这相当于把原来流经v2→v4的流量退还回去,从而获得把退还的流量分配到其他路径的能力。当填满所有的增广路径时,残存网中将不存在从源点到汇点的有向路径,此时原网络中的流值也达到了最大:
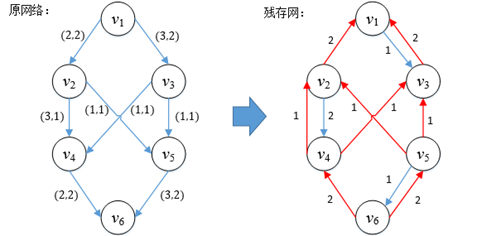
图8
增广路径是一条简单路径,路径中的每个顶点只能出现一次,并不是每条连接源点和汇点的有向路径都是增广路径,例如在8.9中,v1→v2→v5是增广路径,v1→v2→v3→v4→v2→v5虽然也连通了源点和汇点,但是v2中这条路径上出现了2次,这条路径并不“简单”,因此不是增广路径:
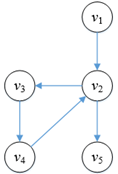
图9
为什么定义增广路径必须是简单路径呢?以图9的v1→v2→v3→v4→v2→v5为例,设这条路径为P,石油先流入中转站v2,然后绕了一圈后有回到v2,最终统一由v2流向v5。对于v1→v2和v2→v5的容量,无非是两种可能,C(v1→v2)<=C(v2→v5)或C(v1→v2)>C(v2→v5)。
当C(v1→v2)<=C(v2→v5)时,P上能够扩充的流量取决于P上容量最小的边,因此最终扩充的流量一定小于等于C(v1→v2),如果最终扩充的流量小于C(v1→v2),那么v1→v2并没有得到充分利用,中下一次寻径中还会再次找到v1→v2→v5,这还不如一开始就通过v1→v2→v5扩充;与此类似如果最终扩充的流量等于C(v1→v2),也不如一开始就通过v1→v2→v5扩充来得方便。同理,当C(v1→v2)>C(v2→v5)时, 最快的扩充途径仍然是通过v1→v2→v5扩充。可以看出,非简单路径并不是无法得到最大流,只是这样做会增加搜索路径的次数,徒耗钱粮。
增广路径最大流算法
增广路径最大流算法也称Ford-Fullkerson算法,它通过不断寻找并填满残存网中的增广路径来扩充原网络的流值,直到残存网中不存在增广路径为止:

每填充一条增广路径,就会有这至少一条边被删除或掉转方向,在实际应用中,对于删除的边仅仅是将其容量清零,而并非真正将这条边删除。通过扩展Edge类使之能够表达残存边。
class Edge():
''' 流网络中的边 '''
def __init__(self, v, w, cap, flow=0):
'''
定义一条边 v→w
:param v: 起点
:param w: 终点
:param cap: 容量
:param flow: v→w上的流量
'''
self.v, self.w, self.cap, self.flow = v, w, cap, flow def other_node(self, p):
''' 返回边中与p相对的另一顶点 '''
return self.v if p == self.w else self.w def residual_cap_to(self, p):
'''
计算残存边的剩余容量
如果p=w,residual_cap_to(p)返回 v→w 的剩余容量
如果p=v,residual_cap_to(p)返回 w→v 的剩余容量
'''
return self.cap - self.flow if p == self.w else self.flow def moddify_flow(self, p, x):
''' 将边的流量调整x '''
if p == self.w: # 如果 p=w,将v→w的流量增加x
self.flow += x
else: # 否则将v→w的流量减少x
self.flow -= x def __str__(self):
return str(self.v) + '→' + str(self.w)
每条边有两个节点,如果一条边是v→w,根据传入的顶点不同,residual_cap_to方法既可以表示Cf(v→w)又可以表示Cf(w→v)。
由于残存网的两个顶点间可能存在两条边,因此在Network类中添加edges方法用来取得连接某一顶点的所有边,包括该顶点的流出边和流入边。
class Network():
''' 流网络 '''
def __init__(self, V:list, E:list, s:int, t:int):
'''
:param V: 顶点集
:param E: 边集
:param s: 原点
:param t: 汇点
:return:
'''
self.V, self.E, self.s, self.t = V, E, s, t def edges_from(self, v):
''' 从v顶点流出的边 '''
return [edge for edge in self.E if edge.v == v] def edges_to(self, v):
''' 流入v顶点的边 '''
return [edge for edge in self.E if edge.w == v] def edges(self, v):
''' 连接v顶点的所有边 '''
return self.edges_from(v) + self.edges_to(v) def flows_from(self, v):
'''v顶点的流出量 '''
edges = self.edges_from(v)
return sum([e.flow for e in edges]) def flows_to(self, v):
''' v顶点的流入量 '''
edges = self.edges_to(v)
return sum([e.flow for e in edges]) def check(self):
''' 源点的流出是否等于汇点的流入 '''
return self.flows_from(self.s) == self.flows_to(self.t) def display(self):
if self.check() is False:
print('该网络不符合守恒定律')
return
print('%-10s%-8s%-8s' % ('边', '容量', '流'))
for e in self.E:
print('%-10s%-10d%-8s' %
(e, e.cap,e.flow if e.flow < e.cap else str(e.flow) + '*'))
接下来通过FordFulkerson类计算网络中的最大流:
class FordFulkerson():
def __init__(self, G:Network):
self.G = G
self.max_flow = 0 # 最大流 class Node:
''' 用于记录路径的轨迹 '''
def __init__(self, w, e:Edge, parent):
'''
:param w: 顶点
:param e: 从上一顶点流入w的边
:param parent: 上一顶点
'''
self.w, self.e, self.parent = w, e, parent def get_augment_path(self):
''' 获取网络中的一条增广路径 '''
path = None
visited = set() # 被访问过的顶点
visited.add(self.G.s)
q = Queue()
q.put(self.Node(self.G.s, None, -1))
while not q.empty():
node_v = q.get()
v = node_v.w
for e in self.G.edges(v): # 遍历连接v的所有边
w = e.other_node(v) # 边的另一顶点,e的指向是v→w
# v→w有剩余容量且w没有被访问过
if e.residual_cap_to(w) > 0 and w not in visited:
visited.add(w)
node_w = self.Node(w, e, node_v)
q.put(node_w)
if w == self.G.t: # 到达了汇点
path = node_w
break
return path def start(self):
''' 增广路径最大流算法主体方法 '''
while True:
path = self.get_augment_path() # 找到一条增广路径
if path is None:
break
bottle = 10000000 # 增广路径的瓶颈
node = path
while node.parent != -1: # 计算增广路径上的最小剩余量
w, e = node.w, node.e
bottle = min(bottle, e.residual_cap_to(w))
node = node.parent
node = path
while node.parent != -1: # 修改残存网
w, e = node.w, node.e
e.moddify_flow(w, bottle)
node = node.parent
self.max_flow += bottle # 扩充最大流 def display(self):
print('最大网络流 = ', self.max_flow)
print('%-10s%-8s%-8s' % ('边', '容量', '流'))
for e in self.G.E:
print('%-10s%-10d%-8s' %
(e, e.cap, e.flow if e.flow < e.cap else str(e.flow) + '*'))
get_augment_path和《搜索的策略(3)——觐天宝匣上的拼图》 中的bfs方法类似,用先进先出队列实现广度优先搜索,找到残存网中的一条增广路径,并通过visited记录访问过的节点,以确保路径是一条最简路径,Node用于记录路径中经历的节点,start()实现了主体代码。
下面的代码用于寻找图1的最大流:
V = [1, 2, 3, 4, 5, 6]
E = [Edge(1, 2, 2), Edge(1, 3, 3), Edge(2, 4, 3), Edge(2, 5, 1),
Edge(3, 4, 1), Edge(3, 5, 1), Edge(4, 6, 2), Edge(5, 6, 3)]
s, t = 1, 6
G = Network(V, E, s, t)
ford_fullkerson = FordFulkerson(G)
ford_fullkerson.start()
ford_fullkerson.display()
运行结果:

下章内容:最小st-剪切,切断敌军的补给线
作者:我是8位的

网络流(2)——用Ford-Fullkerson算法寻找最大流的更多相关文章
- 网络流(四)dinic算法
传送门: 网络流(一)基础知识篇 网络流(二)最大流的增广路算法 网络流(三)最大流最小割定理 网络流(四)dinic算法 网络流(五)有上下限的最大流 网络流(六)最小费用最大流问题 转自:http ...
- dinic算法求最大流的学习
http://trp.jlu.edu.cn/software/net/lssx/4/4.38.htm http://www.cnblogs.com/zen_chou/archive/0001/01/0 ...
- 图论算法-网络最大流【EK;Dinic】
图论算法-网络最大流模板[EK;Dinic] EK模板 每次找出增广后残量网络中的最小残量增加流量 const int inf=1e9; int n,m,s,t; struct node{int v, ...
- 二分图带权匹配 KM算法与费用流模型建立
[二分图带权匹配与最佳匹配] 什么是二分图的带权匹配?二分图的带权匹配就是求出一个匹配集合,使得集合中边的权值之和最大或最小.而二分图的最佳匹配则一定为完备匹配,在此基础上,才要求匹配的边权值之和最大 ...
- 图论4——探索网络流的足迹:Dinic算法
1. 网络流:定义与简析 1.1 网络流是什么? 网络流是一种"类比水流的解决问题方法,与线性规划密切相关"(语出百度百科). 其实,在信息学竞赛中,简单的网络流并不需要太高深的数 ...
- 算法笔记--最大流和最小割 && 最小费用最大流 && 上下界网络流
最大流: 给定指定的一个有向图,其中有两个特殊的点源S(Sources)和汇T(Sinks),每条边有指定的容量(Capacity),求满足条件的从S到T的最大流(MaxFlow). 最小割: 割是网 ...
- 利用Manacher算法寻找字符串中的最长回文序列(palindrome)
寻找字符串中的最长回文序列和所有回文序列(正向和反向一样的序列,如aba,abba等)算是挺早以前提出的算法问题了,最近再刷Leetcode算法题的时候遇到了一个(题目),所以就顺便写下. 如果用正反 ...
- 分治算法--寻找第k大数
问题描述:给定线性序集中n个元素和一个整数k,1≤k≤n,要求找出这n个元素中第k大的元素,(这里给定的线性集是无序的). 其实这个问题很简单,直接对线性序列集qsort,再找出第k个即可.但是这样的 ...
- 21.boost Ford最短路径算法(效率低)
到某个节点最近距离 最短路径当前节点的父节点 完整代码 #include <iostream> #include <string> #incl ...
随机推荐
- HTML5播放视频,并使用ffmpeg对视频转编码
网页加入视频可以用h5自带的video标签,这里用一个jQuery封装优化好的video视频组件videojs. videojs官方网站:https://docs.videojs.com/index. ...
- UITableView HeaderView,FooterView 使用SnapKit布局导致约束异常
今天做一个APP里面设置页面(个人中心) 就是一个列表菜单 顶部是一个头像和账户标题, 底部为一个退出登录按钮 当然我第一时间就想到了UITableView, HeaderView, FooterVi ...
- Swift零基础教程2019最新版(一)搭建开发环境
Swift简单介绍 Swift是苹果强力推荐的新型开发语言,能开发苹果下属所有软件平台(iOS,iPadOS,macOS,watchOS,tvOS)初学者如果想进入苹果的开发体系,从Swift开始学习 ...
- mysql数据库相关流程图/原理图
mysql数据库相关流程图/原理图 1.mysql主从复制原理图 mysql主从复制原理是大厂后端的高频面试题,了解mysql主从复制原理非常有必要. 主从复制原理,简言之,就三步曲,如下: 主数据库 ...
- 解决Mac下java多版本共存问题
一.系统环境 macOS High Sierra(版本:10.13.6) MacBook Air (13-inch, Early 2015) 二.解决步骤 1. 新建.bash_profile文件 $ ...
- 如何在在手机上安装linux(ubuntu )关键词:Termux
目录 Termux软件 @(如何在在手机上安装ubuntu 关键词:Termux) Termux软件 Termux是一款开源且不需要root,运行在Android终端上极其强大的linux模拟器. 首 ...
- Druid-代码段-3-1
所属文章:池化技术(一)Druid是如何管理数据库连接的? 本代码段对应主流程3,新增连接的守护线程: //DruidDataSource的内部类,对应主流程3,用来补充连接 public class ...
- python使用beautifulsoup4爬取酷狗音乐
声明:本文仅为技术交流,请勿用于它处. 小编经常在网上听一些音乐但是有一些网站好多音乐都是付费下载的正好我会点爬虫技术,空闲时间写了一份,截止4月底没有问题的,会下载到当前目录,只要按照bs4库就好, ...
- 0. gitlab 一些常用知识
Monitor 但是有反映 提交慢的情况时候. 可以查看一下队列 使用root账号 gitlab最多可以同时25个队列. 多了需要排队. 可以查看一下原因.
- 第四章 返回结果的HTTP状态码
第四章 返回结果的HTTP状态码 HTTP状态码负责表示客户端HTTP请求的返回结果.标记服务端的处理是否正常.通知出现的错误等. 1.状态码的类别 2. 2XX成功 200 OK 表示服务端已正常 ...