【AI测试】也许这有你想知道的人工智能 (AI) 测试--开篇
人工智能测试
什么是人工智能,人工智能是怎么测试的。可能是大家一开始最想了解的。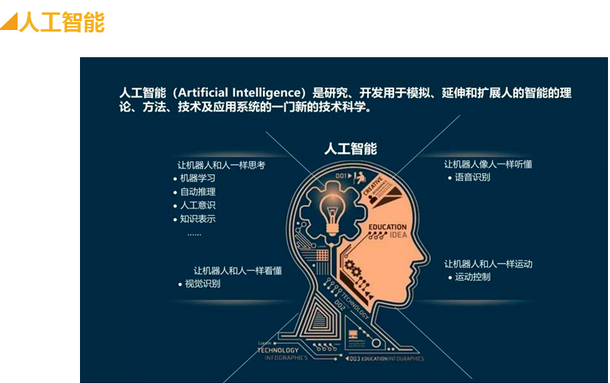
大家看图中关于人工智能的定义。通俗点来说呢,就是 让机器实现原来只有人类才能完成的任务;比如看懂照片,听懂说话,思考等等。
很多人测试的同学会问,那人工智能是怎么测试的?其实这个问题本身问的不太对。
举个例子,把 人工智能 比做 水果。如果有人问你 “水果是怎么吃的”,你可能不知道怎么回答。
在不知道是什么类型的水果,或者具体是什么水果的时候,恐怕不能很好的回答这个问题。
那正确的问法是什么,可以从具体的人工智能应用的来问:
机器学习项目怎么测试
推荐系统项目怎么测试
图像识别项目怎么测试
自然语言处理项目怎么测试。
目前应用最广泛的人工智能也是这四个类型。
刚刚把人工智能比作水果,我们知道,吃水果的方法有很多。可以把机器学习比作 一种吃水果的方法。如果用刀切这种方法。深度学习又是机器学习的一个分支。大概的关系图如图中显示。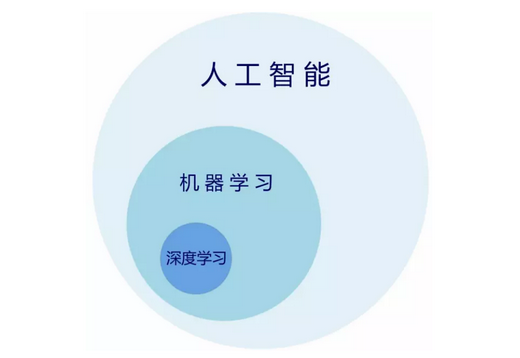
测试什么
一般这些项目都要测试什么,要进行什么类型的测试。
1. 模型评估测试
模型评估主要是测试 模型对未知新数据的预测能力,即泛化能力。
泛化能力越强,模型的预测能力表现越好。而衡量模型泛化能力的评价指标,就是性能度量(performance measure)。性能度量一般有错误率、准确率、精确率、召回率等。
2. 稳定性/鲁棒性测试
稳定性/鲁棒性主要是测试算法多次运行的稳定性;以及算法在输入值发现较小变化时的输出变化。
如果算法在输入值发生微小变化时就产生了巨大的输出变化,就可以说这个算法是不稳定的。
3. 系统测试
将整个基于算法模型的代码作为一个整体,通过与系统的需求定义作比较,发现软件与系统定义不符合或与之矛盾的地方。
系统测试主要包括以下三个方面:
1、项目的整体业务流程
2、真实用户的使用场景
3、数据的流动与正确
4. 接口测试
接口测试是测试系统组件间接口的一种测试。接口测试主要用于检测外部系统与系统之间以及内部各个子系统之间的交互点。测试的重点是要检查数据的交换,传递和控制管理过程,以及系统间的相互逻辑依赖关系等。
5. 文档测试
文档测试是检验用户文档的完整性、正确性、一致性、易理解性、易浏览性。
在项目的整个生命周期中,会得到很多文档,在各个阶段中都以文档作为前段工作成果的体现和后阶段工作的依据。为避免在测试的过程中发现的缺陷是由于对文档的理解不准确,理解差异或是文档变更等原因引起的,文档测试也需要有足够的重视。
6. 性能测试
7. 白盒测试–代码静态检查
8. 竞品对比测试
如果有涉及时,可针对做竞品对比测试,清楚优势和劣势。比如AI智能音箱产品。
9. 安全测试
发布上线后,线上模型监控
测试数据
不管是机器学习,推荐系统,图像识别还是自然语言处理,都需要有一定量的测试数据来进行运行测试。
算法测试的核心是对学习器的泛化误差进行评估。为此是使用测试集来测试学习器对新样本的差别能力。然后以测试集上的测试误差作为泛化误差的近似。测试人员使用的测试集,只能尽可能的覆盖正式环境用户产生的数据情况。正式环境复杂多样的数据情况,需要根据上线后,持续跟进外网数据。算法模型的适用性一定程度上取决于用户数据量,当用户量出现大幅增长,可能模型会随着数据的演化而性能下降,这时模型需要用新数据来做重新训练。
上线只是完成了一半测试,并不像APP或者WEB网站测试一样,测试通过后,发布到正式环境,测试工作就完成了。
测试集如何选取很关键,一般遵循两个原则:
测试集独立同分布
测试数据的数量和训练数据的比例合理
测试集独立同分布
不能使用训练数据来做为测试数据,此为独立。
测试数据需要和训练数据是同一个分布下的数据,此为分布。
举个例子,训练数据中正样本和负样本的分布为7:3,测试数据的分布也需要为7:3,或者接近这个分布,比较合理
测试数据的数量和训练数据的比例合理
当数据量比较小时,可以使用 7 :3 训练数据和测试数据
(西瓜书中描述 常见的做法是将大约 2/3 ~ 4/5 的样本数据用于训练,剩余样本用于测试)
或者 6: 2 : 2 训练数据,验证数据和测试数据。
如果只有100条,1000条或者1万条数据,那么上述比例划分是非常合理的。
如果数据量是百万级别,那么验证集和测试集占数据总量的比例会趋向于变得更小。如果拥有百万数据,我们只需要1000条数据,便足以评估单个分类器,并且准确评估该分类器的性能。假设我们有100万条数据,其中1万条作为验证集,1万条作为测试集,100万里取1万,比例是1%,即:训练集占98%,验证集和测试集各占1%。对于数据量过百万的应用,训练集可以占到99.5%,验证和测试集各占0.25%,或者验证集占0.4%,测试集占0.1%。
这里写图片描述
一般算法工程师会将整个数据集,自己划分为训练集、验证集、测试集。或者训练集、验证集 等等。(这里的测试集是算法工程师的测试数据)
算法工程师提测时,写明自测时的准确率或其他指标。测试人员另外收集自己的测试集。
测试数据可以测试人员自己收集。或者公司的数据标注人员整理提供。或者爬虫。外部购买。
测试人员可以先用算法工程师的测试集进行运行测试查看结果。再通过自己的测试集测试进行指标对比。
————————————————
版权声明:本文为CSDN博主「凌晨点点」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lhh08hasee/article/details/81748680
【AI测试】也许这有你想知道的人工智能 (AI) 测试--开篇的更多相关文章
- 【AI测试】也许这有你想知道的人工智能 (AI) 测试--第二篇
概述此为人工智能 (AI) 测试第二篇 第一篇主要介绍了 人工智能测试.测试什么.测试数据等.第二篇主要介绍测试用例和测试报告.之后的文章可能具体介绍如何开展各项测试,以及具体项目举例如何测试.测试用 ...
- 人工智能--AI篇
AI背景 在当今互联网信息高速发展的大背景下,人工智能(AI)已经开始走进了千家万户,逐渐和我们的生活接轨,那具体什么是AI呢? 什么是人工智能(AI)? 人工智能:简单理解就是由人制造出来的,有一定 ...
- 【AI测试】人工智能 (AI) 测试--第二篇
测试用例 人工智能 (AI) 测试 或者说是 算法测试,主要做的有三件事. 收集测试数据 思考需要什么样的测试数据,测试数据的标注 跑测试数据 编写测试脚本批量运行 查看数据结果 统计正确和错误的个数 ...
- 解读 --- 基于微软企业商务应用平台 (Microsoft Dynamics 365) 之上的人工智能 (AI) 解决方案
9月25日微软今年一年一度的Ignite 2017在佛罗里达州奥兰多市还是如期开幕了.为啥这么说?因为9月初五级飓风厄玛(Hurricane Irma) 在佛罗里达州登陆,在当地造成了挺大的麻烦.在这 ...
- 数据挖掘(data mining),机器学习(machine learning),和人工智能(AI)的区别是什么? 数据科学(data science)和商业分析(business analytics)之间有什么关系?
本来我以为不需要解释这个问题的,到底数据挖掘(data mining),机器学习(machine learning),和人工智能(AI)有什么区别,但是前几天因为有个学弟问我,我想了想发现我竟然也回答 ...
- 谷歌AI涉足艺术、太空、外科手术,再强调AI七原则
谷歌AI涉足艺术.太空.外科手术,再强调AI七原则 https://mp.weixin.qq.com/s/MJG_SvKCEBKRvL3IWpL0bA 9月18日上午,Google在上海的2018世界 ...
- 人工智能AI芯片与Maker创意接轨(下)
继「人工智能AI芯片与Maker创意接轨」的(上)篇中,认识了人工智能.深度学习,以及深度学习技术的应用,以及(中)篇对市面上AI芯片的类型及解决方案现况做了完整剖析后,系列文到了最后一篇,将带领各位 ...
- 人工智能AI芯片与Maker创意接轨 (上)
近几年来人工智能(Artificial Intelligence, AI)喴的震天价响,吃也要AI,穿也要AI,连上个厕所也要来个AI智能健康分析,生活周遭食衣住行育乐几乎无处不AI,彷佛已经来到科幻 ...
- 国家制定人工智能(AI)发展战略的决策根据
在今年两会上,李彦宏的提案有何道理?提案的依据是什么?这个问题必须说清楚,对社会公众有个交代. 回想过去,早在上世纪九十年代,用"电子网络"模拟人脑的想法已经出现.这样的" ...
随机推荐
- SpringCloud学习笔记(七、SpringCloud Netflix Zuul)
目录: springcloud整合eureka.config.zuul zuul源码分析 springcloud整合eureka.config.zuul: 1.架构图 2.GitHub:https:/ ...
- 201871010111-刘佳华《面向对象程序设计(java)》第十二周学习总结
201871010111-刘佳华<面向对象程序设计(java)>第十二周学习总结 实验十 集合与GUI初步 实验时间 2019-11-14 第一部分:基础知识总结 第九章知识总结 1. ...
- markdown 编辑格式
# h1## h2### h3#### h4##### h5###### h6 *em* **strong** ***斜体加粗*** ~~待删除~~ 无序列表,用 * + - 都可以表示,[可以用四个 ...
- leetcode 贪心算法
贪心算法中,是以自顶向下的方式使用最优子结构,贪心算法会先做选择,在当时看起来是最优的选择,然后再求解一个结果的子问题. 贪心算法是使所做的选择看起来都是当前最佳的,期望通过所做的局部最优选择来产生一 ...
- ssd训练之bug:Invalid JPEG data or crop window, data size 565248
bug信息 tensorflow.python.framework.errors_impl.InvalidArgumentError: Invalid JPEG data or crop window ...
- ASP.NET开发实战——(六)ASP.NET MVC & 分层 代码篇
上一篇文章对如何规范使用ASP.NET进行了介绍,本章内容将根据上一篇得出的结论来修改博客应用的代码. 代码分层 综合考虑将博客应用代码分为以下几个层次: ○ 模型:代表应用程序中的数据模型,与数据库 ...
- POJ3662Telephone Lines(最短路+二分)
传送门 题目大意:n个点p条边,每条边有权值,让1和n点联通,可以将联通1--n的边选k条免费, 求剩下边权的最大值. 题解:二分一个答案x,大于x的边权设为1,小于等于x的边权设为0,跑最短路. 若 ...
- 快速傅立叶变换(FFT)
多项式 系数表示法 设\(f(x)\)为一个\(n-1\)次多项式,则 \(f(x)=\sum\limits_{i=0}^{n-1}a_i*x_i\) 其中\(a_i\)为\(f(x)\)的系数,用这 ...
- 为什么我会选择走 Java 这条路?
本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutorial 喜欢的话麻烦点 ...
- 动手学深度学习10- pytorch多层感知机从零实现
多层感知机 定义模型的参数 定义激活函数 定义模型 定义损失函数 训练模型 小结 多层感知机 import torch import numpy as np import sys sys.path.a ...