Linux EXT2 文件系统
磁盘是用来储文件的,但是必须先把磁盘格式化为某种格式的文件系统,才能存储文件。文件系统的目的就是组织和管理磁盘中的文件。在 Linux 系统中,最长见的是 ext2 系列的文件系统。其早期版本为 ext2,后来又发展出 ext3 和 ext4。ext3 和 ext4 虽然对 ext2 进行了增强,但是其核心设计并没有发生变化,所以我们仍是以较老的 ext2 作为演示对象。
基本结构
Ext2 文件系统在格式化的时候一般会包含多个区块群组(blockgroup)。Ext2 格式化后有点像下面这样:
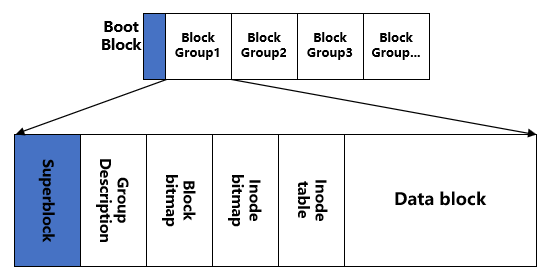
这是因为文件系统非常大时,如果将所有的 inode 和所有的 block 放在一起管理起来会比较麻烦。所以将文件系统分割为多个 Block Group,每个 Block Group 中都有独立的 inode/block/superblock 系统。
Block
Block 就是我们在《Linux 文件系统相关的基本概念》一文中介绍的逻辑块。对于 ext2 文件系统来说,硬盘分区首先被分割为一个一个的逻辑块(Block),每个 Block 就是实际用来存储数据的单元,大小相同,Block 按照0,1,2,3 的顺序进行编号,第一个 Block 的编号为 0。ext2 文件系统支持的 Block 的大小有 1024 字节、2048 字节和 4096 字节,Block 的大小在创建文件系统的时候可以通过参数指定,如果不指定,则会从 /etc/mke2fs.conf 文件中读取对应的值。原则上,Block 的大小与数量在格式化后就不能够发生改变了,每个 Block 内最多只会存放一个文件的数据(即不会出现两个文件的数据被放入同一个 Block 的情况),如果文件大小超过了一个 Block 的 size,则会占用多个 Block 来存放文件,如果文件小于一个 Block 的 size,则这个 Block 剩余的空间就浪费掉了。
可以使用 dumpe2fs 命令查看 Block 的大小:
$ sudo dumpe2fs /dev/sda1 | grep "Block size:"
在笔者的环境中,输出的结果如下:
Block size: 1024
注意,Ext2 文件系统的 block 主要有下面一些特点:
- block 的大小与数量在格式化完就不能够再改变了(除非重新格式化)
- 每个 block 内最多只能够放置一个文件的数据
- 如果文件大于 block 的大小,则一个文件会占用多个 block 数量
- 若文件小于 block,则该 block 的剩余容量就不能够再被使用了
Block Group
Block 在逻辑上被划分为多个 Block Group,每个 Block Group 包含的 Block 数量相同,具体是在 SuperBlock 中通过 s_block_per_group 属性定义的(最后一个 Block Group 除外,最后剩下的 Block 数量可能小于 s_block_per_group,这些 Block 会被划分到最后一个 Block Group 中)。dumpe2fs 命令会列出所有的 Block Group 信息,但是在统计信息中却没有说明当前的文件系统中包含有多少个 Block Group。下面是 dumpe2fs 输出的 Block Group 信息的节选:
...
Group : (Blocks -) [ITABLE_ZEROED]
Checksum 0xa22b, unused inodes
Primary superblock at , Group descriptors at -
Reserved GDT blocks at -
Block bitmap at (+), Inode bitmap at (+)
Inode table at - (+)
free blocks, free inodes, directories, unused inodes
Free blocks: -
Free inodes: -
Group : (Blocks -) [INODE_UNINIT, BLOCK_UNINIT, ITABLE_ZEROED]
Checksum 0xea71, unused inodes
Backup superblock at , Group descriptors at -
Reserved GDT blocks at -
Block bitmap at (bg # + ), Inode bitmap at (bg # + )
Inode table at - (bg # + )
free blocks, free inodes, directories, unused inodes
Free blocks: -
Free inodes: -
...
Group0 占用从 1 到 8192 号的 block。其中的 Superblock 则在 1 号 block 内。
文件系统描述说明(Group descriptors)占用从 2 到 81 号 block。
Block bitmap 和 Inode bitmap 分别在 338 和 354 号 block 上。
Inode table 占用 370-497 号 block。
Group0 当前可用的 block 号为:2432-8192,可用的 inode 号码为:12-512。
Group 内 inode 数的计算方式:
一个 inode 占用 256 Bytes
Inode 占用的 block 数:497 - 370 + 1 = 128
每个 block 的大小为 1024 Bytes
Inode 数为:128 * 1024 / 256 = 512
Boot Block
每个磁盘分区的开头 1024 字节大小都预留为分区的启动扇区,存放引导程序和数据,所以又叫引导块。引导块在第一个 Block,即 Block 0 中存放,但是未必占满这个 Block,原因是 Block 的大小可能大于 1024 字节。
这里是存放开机管理程序的地方,这是个非常重要的设计。因为这样使得我们能够把不同的开机管理程序安装到每个文件系统的最前端,而不用覆盖整颗磁盘唯一的 MBR,这样就能支持多系统启动了。
Block Group 的组成部分
如上图所示,每个 Block Group 都由下面几个组成部分:
- Superblock(超级块)
- Group Description(组描述)
- Block bitmap(块位图)
- Inode bitmap(inode 位图)
- Inode table(inode 表)
- Data Blocks(数据块)
Superblock(超级区块)
Superblock 是记录整个 filesystem 相关信息的地方,其实上除了第一个 block group 内会含有 superblock 之外,后续的 block group 不一定都包含 superblock,如果包含,也是做为第一个 block group 内 superblock 的备份。superblock 记录的主要信息有:
- block 与 inode 的总量
- 未使用与已使用的 inode/block 数量
- block 与 inode 的大小(block 为 1,2,4K,inode 为 128 Bytes 或 256 Bytes)
- filesystem 的挂载时间、最近一次写入数据的时间、最近一次检验磁盘(fsck)的时间等文件系统的相关信息
- 一个 valid bit 数值,若此文件系统已被挂载,则 valid bit 为 0,若未被挂载,则 valid bit 为 1
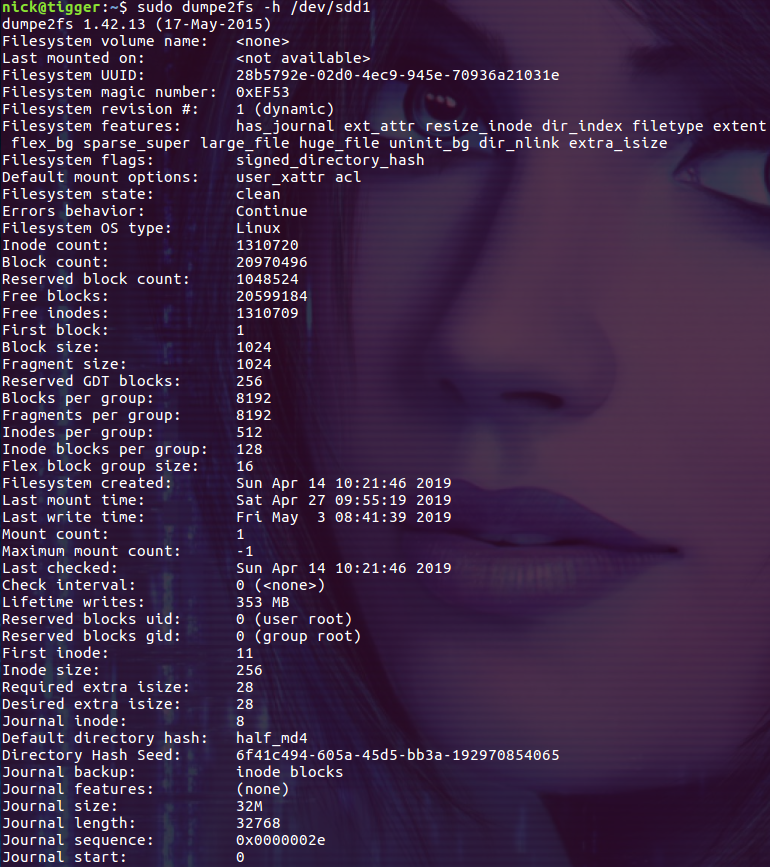
Superblock 的大小为 1024 Bytes,它非常重要,因为分区上重要的信息都在上面。如果 Superblock 挂掉了,分区上的数据就很难恢复了。可以使用 dumpe2fs 命令查看 分区的 Superblock 信息,如果添加选项 -h,dumpe2fs 命令则只输出 Superblock 中的信息:
$ sudo dumpe2fs -h /dev/sdd1
Group Description(组描述)
Group Description 用来描述每个 group 的开始与结束位置的 block 号码,以及说明每个块(superblock、bitmap、inodemap、datablock) 分别介于哪一个 block 号码之间。
Block bitmap(区块对照表)
在创建文件时需要为文件分配 block,届时就会选择分配空闲的 block 给文件使用。如何查看 block 是否已经被使用了呢?此时就需要借助于 block bitmap 了。通过 block bitmap 可以知道哪些 block 是空的,因此系统就能够很快地找到空闲空间来分配给文件。同样的,在删除某些文件时,文件原本占用的 block 号码就要释放出来,此时在 block bitmap 当中相对应到该 block 号码的标志就需要修改成"空闲"。这就是 block bitmap 的作用。
Inode bitmap(inode 对照表)
inode bitmap 与 block bitmap 的功能类似,只是 block bitmap 记录的是使用与未使用的 block 号,而 inode bitmap 则记录的是使用与未使用的 inode 号。
Inode table
Inode table 中存放着一个个 inode,inode 的内容记录文件的属性以及该文件实际数据是放置在哪些 block 内,inode 记录的主要的文件属性如下:
- 该文件的读写权限(rwx)
- 该文件的拥有者和所属组(owner/group)
- 该文件的容量
- 该文件的 ctime(创建时间)
- 该文件的 atime(最近一次的读取时间)
- 该文件的 mtime(最近修改的时间)
- 该文件的特殊标识,比如 SetUID 等
- 该文件真正内容的指向(pointer)
inode 的数量与大小也是在格式化时就已经固定了的,另外 inode 还有如下特点:
- 每个 inode 大小均固定为 128 Bytes(新的 ext4 为 256 Bytes)
- 每个文件都仅会占用一个 inode
- 文件系统能够创建的文件数量与 inode 的数量相关
- 系统读取文件时需要先找到 inode,并分析 inode 所记录的权限与使用者是否符合,若符合才能够开始读取 block 的内容
Data block
Data block 是用来存放文件内容的地方,Ext2 文件系统 1K、2K 和 4K 大小的 block。在格式化文件系统时 block 的大小就确定了,并且每个 block 都有编号。需要注意的是,由于 block 大小的差异,会导致文件系统能够支持的最大磁盘容量和最大单个文件的大小并不相同。下表描述了 block 大小与文件系统以及单个文件大小的关系:
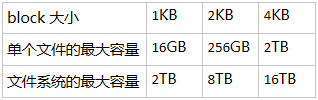
此外 Ext2 文件系统的 block 还有下面一些限制:
- block 的大小与数量在格式化后就不能再改变了(除非重新格式化)
- 每个 block 内最多只能够放置一个文件的数据
- 如果文件大于 block 的大小,那么一个文件会占用多个 block
- 若文件小于 block,则该 block 的剩余容量也不能再被使用了(磁盘空间被浪费)
参考:
鸟哥的私房菜
dumpe2fs man page
Linux ext2, ext3, ext4 文件系统解读[1]
Ext2文件系统简单剖析(一)
Linux EXT2 文件系统的更多相关文章
- linux ext2 文件系统学习
Linux ext2文件系统理解 硬盘组成: 硬盘由多个圆形硬盘片组成.按照硬盘片能够容纳的数据量分为单盘和多盘.硬盘的数据读取主要靠机械手臂上的磁头,在机械手臂上有多个磁头.机械手臂不动硬盘旋转一 ...
- Linux ext2文件系统
Linux最传统的磁盘文件系统(filesystem)使用的是ext2 1.ext2文件系统结构ext2文件系统划分为多个块组,每个块组拥有独立的inode/block,一个文件系统只有一个Super ...
- Linux ext2文件系统之初步思考
数据存放在磁盘中,磁盘最小存取单位sector(512Byte);文件系统中存储的最小单位是 块(Block),大小通常(1KB,2KB,4KB...), 一个block对应多个sector,因而可用 ...
- Linux 下EXT2文件系统 —— 如何将蚂蚁和大象优雅的装进冰箱里
这一阵子真是偷懒,无时无刻不和自己身体中的懒癌做斗争.最终我还是被打败了,星期天两天几乎都是荒废过去的,在空闲的时候实际上我内心也是有点焦虑的,不知道去怎么度过这时间.学习吧又不想学习,看电视娱乐吧也 ...
- Linux ext2/ext3文件系统详解
转载: Linux ext2/ext3文件系统使用索引节点来记录文件信息,作用像windows的文件分配表.索引节点是一个结构,它包含了一个文件的长度.创建及修改时间.权限.所属关系.磁盘中的位置等信 ...
- 文件系统的特性,linux的EXT2文件系统【转】
本文转载自:https://blog.csdn.net/tongyijia/article/details/52809281 先来提出三个概念: - superblock - inode - bloc ...
- Linux中ext2文件系统的结构
1.ext2产生的历史 最早的Linux内核是从MINIX系统过渡发展而来的.Linux最早的文件系统就是MINIX文件系统.MINIX文件系统几乎到处都是bug,采用的是16bit偏移量,最大容量为 ...
- Linux磁盘管理——Ext2文件系统
前言 通常而言,对于一块新磁盘我们不是直接使用,而是先分区,分区完毕后格式化,格式化后OS才能使用这个文件系统.分区可能会涉及到MBR和GPT问题.至于格式化和文件系统又有什么关系? 这里的格式化指的 ...
- Linux 文件系统及 ext2 文件系统
linux 支持的文件系统类型 Ext2: 有点像 UNIX 文件系统.有 blocks,inodes,directories 的概念. Ext3: Ext2 的加强版,添加了日志 ...
随机推荐
- mysql数据库之表关系
外键 前戏之一对多关系 # 定义一张部门员工表id name gender dep_name dep_desc1 jason male 教学部 教书育人2 egon male 外交部 漂泊游荡3 ta ...
- spring源码深度解析— IOC 之 默认标签解析(上)
概述 接前两篇文章 spring源码深度解析—Spring的整体架构和环境搭建 和 spring源码深度解析— IOC 之 容器的基本实现 本文主要研究Spring标签的解析,Spring的标签 ...
- string类总结第一部分函数介绍
在前面几章,看了整个String类的源码,给每个方法都行写了注释,但是太过凌乱,今天我就把String类的方法整理归纳,然后再讲一下String类比较难以理解的部分 特此声明:本文篇幅较大,涵盖知识点 ...
- 第一个SpringBoot
Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程.该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置.用我 ...
- HDU 5723:Abandoned country(最小生成树+算期望)
http://acm.hdu.edu.cn/showproblem.php?pid=5723 Abandoned country Problem Description An abandoned ...
- [转]iis部署php项目
阅读目录 1.启动iis服务器 2.打开iis 3.创建网站 4.php设置 ①添加默认文档 ②处理程序映射 1.安装urlrewrite 2.使用URL重写 今天跟着学习了如何在IIS下部署php项 ...
- 利用consul在spring boot中实现最简单的分布式锁
因为在项目实际过程中所采用的是微服务架构,考虑到承载量基本每个相同业务的服务都是多节点部署,所以针对某些资源的访问就不得不用到用到分布式锁了. 这里列举一个最简单的场景,假如有一个智能售货机,由于机器 ...
- Jmeter实时监控+SpringBoot接口性能实战
性能测试 Jmeter实时监控+SpringBoot接口性能实战 自动化 SpringBoot Java Jmeter实时监控+SpringBoot接口性能实战 一.实验目的及实验环境 1.1.实验目 ...
- 微信小程序 键盘显示短信验证码
1.场景描述: IOS系统 一些APP或者微信小程序在收到短信验证码的时候会在键盘上自动保存验证码信息,当用户点击的时候,会自动赋值到当前所点击的输入框中 2.案例: 2.实现: TIPS:这个功能是 ...
- 我的it博客开张啦
今天怀着激动地心情,在这里写下第一篇开博.之前也在新浪.网易等申请过博客,并且将新浪博客作为我的个人技术博客,当有一天看到cnblog时,觉得这里的博客以一本精美的书的批复呈现时,顿觉得很有...咋说 ...