Gobblin采集kafka数据
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处
找时间记录一下利用Gobblin采集kafka数据的过程,话不多说,进入正题
一.Gobblin环境变量准备
需要配置好Gobblin0.7.0工作时对应的环境变量,可以去Gobblin的bin目录的gobblin-env.sh配置,比如
export GOBBLIN_JOB_CONFIG_DIR=~/gobblin/gobblin-config-dir
export GOBBLIN_WORK_DIR=~/gobblin/gobblin-work-dir
export HADOOP_BIN_DIR=/opt/cloudera/parcels/CDH-5.4.0-1.cdh5.4.0.p0.27/lib/hadoop/bin
也可以去自己当前用户bashrc下配置,当然,确保JAVA_HOME也已经配置.
这里配置的Gobblin的配置文件目录和工作目录以及执行MR需要用到的hadoop bin目录
二.Gobblin Standalone模式配置和使用
顾名思义,就是在部署Gobblin的单节点上来采集kafka数据,没有用到Hadoop MR,配置过程如下
首先去GOBBLIN_JOB_CONFIG_DIR下,新建一个gobblinStandalone.pull配置文件,配置如下
job.name=GobblinKafkaQuickStart
job.group=GobblinKafka
job.description=Gobblin quick start job for Kafka
job.lock.enabled=false
job.schedule=0 0/3 * * * ?
kafka.brokers=datanode01:9092
source.class=gobblin.source.extractor.extract.kafka.KafkaSimpleSource
extract.namespace=gobblin.extract.kafka writer.builder.class=gobblin.writer.SimpleDataWriterBuilder
writer.file.path.type=tablename
writer.destination.type=HDFS
writer.output.format=txt data.publisher.type=gobblin.publisher.BaseDataPublisher mr.job.max.mappers=1 metrics.reporting.file.enabled=true
metrics.log.dir=${env:GOBBLIN_WORK_DIR}/metrics
metrics.reporting.file.suffix=txt bootstrap.with.offset=earliest
这里需要配置好抽取数据的kafka broker以及一些gobblin的工作组件,如source,extract,writer,publisher等,不明白的可以参考Gobblin wiki,很详细.
我这里额外配置了一个job.schedule让gobblin三分钟检查一次kafka的所有topic是否有新增,然后抽取任务就会三分钟一次定时执行.这里用的Gobblin自带的Quartz定时器.
ok,配置好以后进入Gobblin根目录,启动命令如:
bin/gobblin-standalone.sh –conffile $GOBBLIN_JOB_CONFIG_DIR/gobblinStandalone.pull start
我这里GOBBLIN_JOB_CONFIG_DIR有多个pull文件,因此需要指明,如果GOBBLIN_JOB_CONFIG_DIR下只有一个配置文件,那么直接bin/gobblin-standalone.sh start即可执行
最终抽取过来的数据会输出到GOBBLIN_WORK_DIR/job-output 中去.
三.Gobblin MapReduce模式配置和使用
这次配置Gobblin会使用MapReduce来抽取kafka数据到Hdfs,新建gobblin-mr.pull文件,配置如下
job.name=GobblinKafkaToHdfs
job.group=GobblinToHdfs1
job.description=Pull data from kafka to hdfs use Gobblin
job.lock.enabled=false
kafka.brokers=datanode01:9092 source.class=gobblin.source.extractor.extract.kafka.KafkaSimpleSource
extract.namespace=gobblin.extract.kafka
topic.whitelist=jsonTest writer.builder.class=gobblin.writer.SimpleDataWriterBuilder
simple.writer.delimiter=\n
simple.writer.prepend.size=false
writer.file.path.type=tablename
writer.destination.type=HDFS
writer.output.format=txt
writer.partitioner.class=gobblin.example.simplejson.TimeBasedJsonWriterPartitioner
writer.partition.level=hourly
writer.partition.pattern=yyyy/MM/dd/HH
writer.partition.columns=time
writer.partition.timezone=Asia/Shanghai
data.publisher.type=gobblin.publisher.TimePartitionedDataPublisher mr.job.max.mappers=1 metrics.reporting.file.enabled=true
metrics.log.dir=/gobblin-kafka/metrics
metrics.reporting.file.suffix=txt bootstrap.with.offset=earliest fs.uri=master:8020
writer.fs.uri=${fs.uri}
state.store.fs.uri=${fs.uri} mr.job.root.dir=/gobblin-kafka/working
state.store.dir=/gobblin-kafka/state-store
task.data.root.dir=/jobs/kafkaetl/gobblin/gobblin-kafka/task-data
data.publisher.final.dir=/gobblintest/job-output
注意标红部分的配置第一行,我这里加了topic过滤,只对topic名称为jsonTest的主题感兴趣
因为需求是需要将gobblin的topic数据按照每天每小时来进行目录分区,具体分区目录需要根据kafka record中的时间字段来
我这里record是json格式的,时间字段格式如{…"time":"2016-10-12 00:30:20"…},因此需要继承Gobblin的TimeBasedWriterPartitioner来重写子类方法按照时间字段对hdfs的目录分区
以下配置需要注意
fs.uri=master:8020
改成自己的集群的hdfs地址
writer.partition.columns=time
这里的time和json中的时间字段保持一致即可
writer.partition.level=hourly
表示hdfs分区到小时
writer.partition.pattern=yyyy/MM/dd/HH
表示最终需要在hdfs分区的目录格式(按照自己的最终分区需求自定义即可)
writer.partitioner.class=gobblin.example.simplejson.TimeBasedJsonWriterPartitioner
重写的hdfs按照json时间字段分区的子类,代码我提交到github了,参考如下链接
将扩展后的类加入Gobblin相应的模块,我这里是放入gobblin-example模块中去了,重新build,build有问题的话请参考这篇文章
上面配置文件最后的那些路径都是hdfs路径,请确保Gobblin有读写权限
随后启动命令
bin/gobblin-mapreduce.sh --conf $GOBBLIN_JOB_CONFIG_DIR/gobblin-mr.pull
运行成功后,hdfs会出现如下目录,jsonTest是按照对应topic名称生成的,如下图
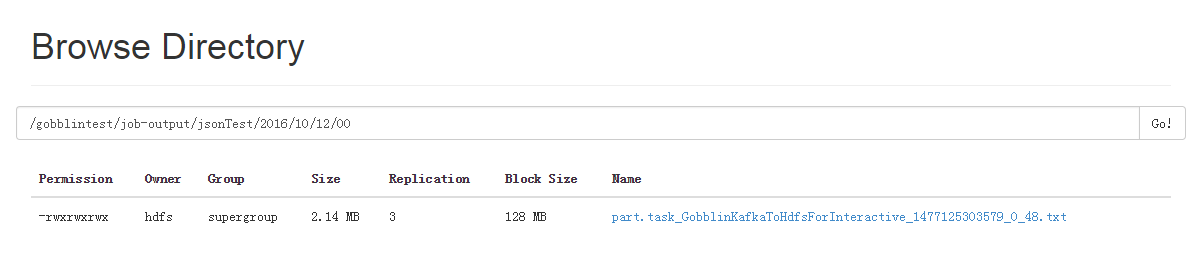
注意MR模式配置Quartz定时调度我试了好几次不起作用,因此如果需要定时执行抽取的话请利用外部的工具,比如Linux的crontab或者Oozie或者Azkaban都是可以的.
四.Gobblin使用总结
1>先熟悉Gobblin官方wiki,写的很详细
2>github上fork一个源代码仔细阅读下source,extract,partioner这块儿的代码
3>使用中遇到问题多研究Gobblin的log和Hadoop的log.
参考资料:
http://gobblin.readthedocs.io/en/latest/case-studies/Kafka-HDFS-Ingestion/
http://gobblin.readthedocs.io/en/latest/user-guide/Partitioned-Writers/
http://gobblin.readthedocs.io/en/latest/developer-guide/IDE-setup/
http://gobblin.readthedocs.io/en/latest/user-guide/FAQs/
Gobblin采集kafka数据的更多相关文章
- MongoDB -> kafka 高性能实时同步(采集)mongodb数据到kafka解决方案
写这篇博客的目的 让更多的人了解 阿里开源的MongoShake可以很好满足mongodb到kafka高性能高可用实时同步需求(项目地址:https://github.com/alibaba/Mong ...
- MongoDB -> kafka 高性能实时同步(sync 采集)mongodb数据到kafka解决方案
写这篇博客的目的 让更多的人了解 阿里开源的MongoShake可以很好满足mongodb到kafka高性能高可用实时同步需求(项目地址:https://github.com/alibaba/Mong ...
- flume采集MongoDB数据到Kafka中
环境说明 centos7(运行于vbox虚拟机) flume1.9.0(自定义了flume连接mongodb的source插件) jdk1.8 kafka(2.11) zookeeper(3.57) ...
- flume实时采集mysql数据到kafka中并输出
环境说明 centos7(运行于vbox虚拟机) flume1.9.0(flume-ng-sql-source插件版本1.5.3) jdk1.8 kafka(版本忘了后续更新) zookeeper(版 ...
- C#+HtmlAgilityPack+XPath带你采集数据(以采集天气数据为例子)
第一次接触HtmlAgilityPack是在5年前,一些意外,让我从技术部门临时调到销售部门,负责建立一些流程和寻找潜在客户,最后在阿里巴巴找到了很多客户信息,非常全面,刚开始是手动复制到Excel, ...
- API例子:用Python驱动Firefox采集网页数据
1,引言 本文讲解怎样用Python驱动Firefox浏览器写一个简易的网页数据采集器.开源Python即时网络爬虫项目将与Scrapy(基于twisted的异步网络框架)集成,所以本例将使用Scra ...
- Performance Monitor采集性能数据
Performance Monitor采集性能数据 Windows本身为我们提供了很多好用的性能分析工具,大家日常都使用过资源管理器,在里面能即时直观的看到CPU占用率.物理内存使用量等信息.此外新系 ...
- java spark-streaming接收TCP/Kafka数据
本文将展示 1.如何使用spark-streaming接入TCP数据并进行过滤: 2.如何使用spark-streaming接入TCP数据并进行wordcount: 内容如下: 1.使用maven,先 ...
- 【Android 应用开发】分析各种Android设备屏幕分辨率与适配 - 使用大量真实安卓设备采集真实数据统计
.主要是为了总结一下 对这些概念有个直观的认识; . 作者 : 万境绝尘 转载请注明出处 : http://blog.csdn.net/shulianghan/article/details/198 ...
随机推荐
- 一篇关于匿名函数(function(){})()不错的文章
代码如下: (function(){ //这里忽略jQuery所有实现 })(); (function(){ //这里忽略jQuery所有实现 })(); 半年前初次接触jQuery的时候,我也像其他 ...
- jQuery中设置form表单中action值与js有什么不同。。。。
jQuery中设置form表单中action值与js有什么不同.... HTML代码如下: <form action="" method="post" i ...
- Second Day: 关于Button监听事件的三种方法(匿名类、外部类、继承接口)
第一种:通过匿名类实现对Button事件的监听 首先在XML文件中拖入一个Button按钮,并设好ID,其次在主文件.java中进行控件初始化(Private声明),随后通过SetOnClickLis ...
- [译] 给PHP开发者的PHP源码-第一部分-源码结构
文章来自:http://www.hoohack.me/2016/02/04/phps-source-code-for-php-developers-ch 原文:http://blog.ircmaxel ...
- 借助 Lucene.Net 构建站内搜索引擎(下)
前言:上一篇我们学习了Lucene.Net的基本概念.分词以及实现了一个最简单的搜索引擎,这一篇我们开始开发一个初具规模的站内搜索项目,通过开发站内搜索模块,我们可以方便地在项目中集成站内搜索功能.本 ...
- ASP.NET MVC 路由(三)
ASP.NET MVC路由(三) 前言 通过前两篇的学习会对路由系统会有一个初步的了解,并且对路由系统中的Url规则有个简单的了解,在大家的脑海中也有个印象了,那么路由系统在ASP.NETMVC中所处 ...
- Functional Programming without Lambda - Part 1 Functional Composition
Functions in Java Prior to the introduction of Lambda Expressions feature in version 8, Java had lon ...
- [视频],花一分钟来看看Worktile是如何为团队协作而生的
团队协作,我们想的更深.更远.更多,花一分钟来看看我们特别奉献的故事,然后去注册一个账号,邀请小伙伴一起来工作,你会体会Worktile才是真正懂你的协作方式. 我们想做的百年公司还有很多的路,这一站 ...
- Echarts3 关系图-力导向布局图
因为项目需要,要求实现类似力导图效果的图,我就瞄上了echarts. 注意事项1:由于我的项目要部署到内网,所以js文件要在本地,网上大多力导图都是echarts2的,而其又依赖zrender基础库, ...
- KnockoutJS 3.X API 第六章 组件(2) 组件注册
要使Knockout能够加载和实例化组件,必须使用ko.components.register注册它们,从而提供如此处所述的配置. 注意:作为替代,可以实现一个自定义组件加载器(自定义加载器下一节介绍 ...