python+selenium自动化框架
---恢复内容开始---
主要使用的模块:
- selenium/webdriver模块(须准备Chrome驱动),主要用于调用浏览器实现自动点击。
- unittest模块,主要用于整合测试用例。
- xlrd模块,主要用于调用Excle获取测试数据。
- HTMLTestRunnerCN模块,主要用于生成测试报告。
框架分层思路:
- 常用函数层
- 测试数据层
- 测试元素层
- 测试用例层
- 测试结果层
详细解释层级划分:
一、常用函数层:主要写常用的一些类,方便后面调用,如:selenium调用浏览器、读取URL的EXCEL、读取用户数据的EXCEL等
二、测试数据层:主要存放一些用户数据/URL/测试数据等到EXCEL中方便后续调用 我这里存放的主要有:
- 测试网站的URL。
- 项目中不同权限用户的用户名和密码
- 常用配置文件信息
三、测试元素层:主要存放一些较长的Xpath和Css定位路径,使后续脚本简洁
四、测试用例层:主要使用unittest模块 创建测试用例:
class Test(unittest.TestCase):
def setUp(self):
self.flag = 1
self.ca = function.OpenChrome()
self.br = function.OpenChrome().open()
self.xpath = element.Element()
self.eid = element.ID()
self.css = element.Css()
self.temp = function.Openurl()
self.br.maximize_window()
#以上为定义unittest类,并在setUp中添加前置条件 def test_登录用户(self):...
def test_xxx(self):...
def test_xxx(self):...
def test_xxx(self):...
def test_xxx(self):...
#以上为使用test__xx函数逐个创建测试用例 def tearDown(self):
self.assertEqual(self.flag,1,msg="用例执行失败")
self.br.close()
#以上为添加后置条件,如:断言,关闭浏览器等
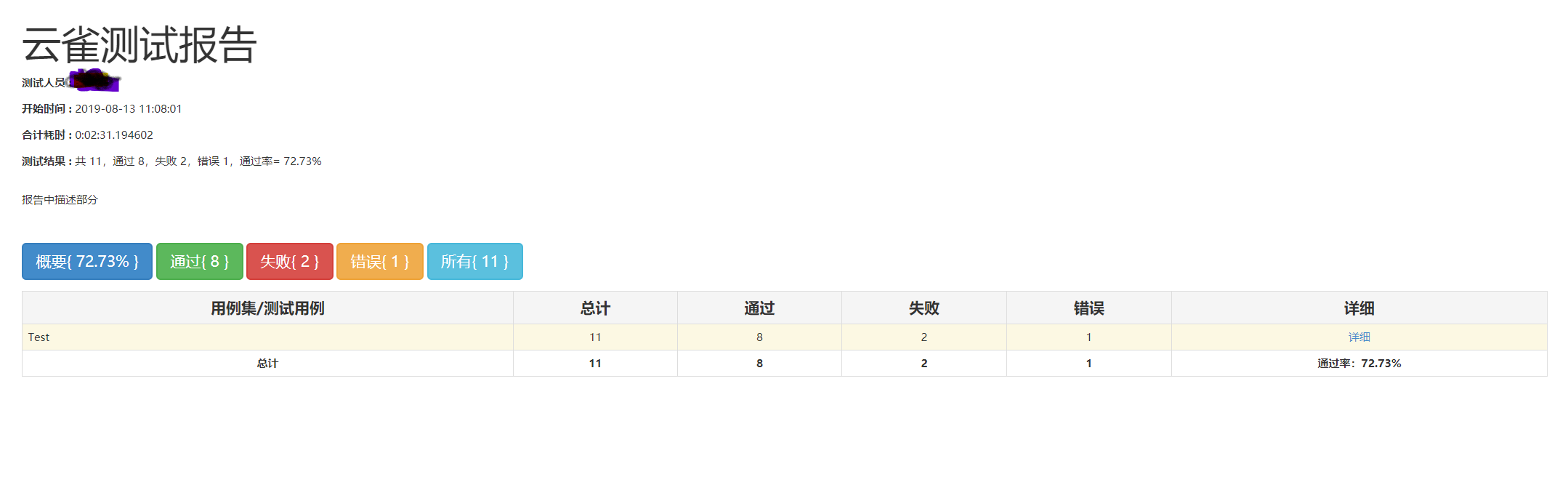
五、测试结果层:主要使用HTMLTestRunnerCN模块生成测试报告:
filepath = '../result/Yunque_result.html'
fp = open(filepath,'wb')
runner = HTMLTestRunnerCN.HTMLTestReportCN(stream=fp,title='xx测试报告',tester='测试人员',description = '报告中描述部分')
runner.run(suite)
测试结果如下图:
python+selenium自动化框架的更多相关文章
- python+selenium自动化框架搭建
环境及使用软件信息 python 3 selenium 3.13.0 xlrd 1.1.0 chromedriver HTMLTestRunner 说明: selenium/xlrd只需要再pytho ...
- python+selenium+unnittest框架
python+selenium+unnittest框架,以百度搜索为例,做了一个简单的框架,先看一下整个项目目录结构 我用的是pycharm工具,我觉得这个工具是天使,超好用也超好看! 这些要感谢原作 ...
- python selenium自动化点击页面链接测试
python selenium自动化点击页面链接测试 需求:现在有一个网站的页面,我希望用python自动化的测试点击这个页面上所有的在本窗口跳转,并且是本站内的链接,前往到链接页面之后在通过后退返回 ...
- python+selenium自动化登录dnf11周年活动界面领取奖励登录部分采坑总结[1]
背景: Dnf的周年庆活动之一,游戏在6月22日 06:00~6月23日 06:00之间登陆过游戏后可以于6月25日 16:00~7月04日 06:00领取奖励 目标:连续四天自动运行脚本,自动领取所 ...
- Python+selenium 自动化-启用带插件的chrome浏览器,调用浏览器带插件,浏览器加载配置信息。
Python+selenium 自动化-启用带插件的chrome浏览器,调用浏览器带插件,浏览器加载配置信息. 本文链接:https://blog.csdn.net/qq_38161040/art ...
- Python+Selenium自动化总结
Python+Selenium自动化总结 1.环境搭建 1.1.安装selenium模块文件 pip install selenium 1.2.安装ChromeDriver驱动 [1]下载安装Chro ...
- Python+Selenium自动化-定位一组元素,单选框、复选框的选中方法
Python+Selenium自动化-定位一组元素,单选框.复选框的选中方法 之前学习了8种定位单个元素的方法,同时webdriver还提供了8种定位一组元素的方法.唯一区别就是在单词elemen ...
- Python+Selenium自动化-模拟键盘操作
Python+Selenium自动化-模拟键盘操作 0.导入键盘类Keys() selenium中的Keys()类提供了大部分的键盘操作方法:通过send_keys()方法来模拟键盘上的按键. # ...
- Python+Selenium自动化-设置等待三种等待方法
Python+Selenium自动化-设置等待三种等待方法 如果遇到使用ajax加载的网页,页面元素可能不是同时加载出来的,这个时候,就需要我们通过设置一个等待条件,等待页面元素加载完成,避免出现 ...
随机推荐
- 【Offer】[56-2] 【数组中唯一只出现一次的数字】
题目描述 思路分析 测试用例 Java代码 代码链接 题目描述 在一个数组中除一个数字只出现一次之外,其他数字都出现了三次.请找出那个只出现一次的数字 [牛客网刷题地址]无 思路分析 如果一个数字出现 ...
- 从原理层面掌握@InitBinder的使用【享学Spring MVC】
每篇一句 大魔王张怡宁:女儿,这堆金牌你拿去玩吧,但我的银牌不能给你玩.你要想玩银牌就去找你王浩叔叔吧,他那银牌多 前言 为了讲述好Spring MVC最为复杂的数据绑定这块,我前面可谓是做足了功课, ...
- 大数据Hadoop基础入门到精通
1.hadoop前世今生: 1) 搜索引擎:网络爬虫+索引服务器(生成索引+检索) 2) Doung Cutting 3) Nutch a.分布式存储 b.分布式计算 4)GFS论文 doung c ...
- HBase数据迁移到Kafka实战
1.概述 在实际的应用场景中,数据存储在HBase集群中,但是由于一些特殊的原因,需要将数据从HBase迁移到Kafka.正常情况下,一般都是源数据到Kafka,再有消费者处理数据,将数据写入HBas ...
- 彻底解决android拍照后无法显示的问题
这是对上篇"android 图片拍照,相册选图,剪切并显示"的文章之后的 改进 上一篇文章虽然能解决图片的拍照剪切以及显示,但是发现他有一个缺点, 如果该程序单独运行,貌似没有任何 ...
- 一次误用CSRedisCore引发的redis故障排除经历
前导 上次Redis MQ分布式改造完成之后, 编排的容器稳定运行了一个多月,昨天突然收到ETL端同事通知,没有采集到解析日志了. 赶紧进服务器看了一下,用于数据接收的receiver容器挂掉了, 尝 ...
- IntelliJ IDEA远程连接tomcat,实现单步调试
web项目部署到tomcat上之后,有时需要打断点单步调试,如果用的是Intellij idea,可以通过如下方法实现: 开启debug端口,启动tomcat 以tomcat7.0.75为例,打开bi ...
- scala函数式编程(二) scala基础语法介绍
上次我们介绍了函数式编程的好处,并使用scala写了一个小小的例子帮助大家理解,从这里开始我将真正开始介绍scala编程的一些内容. 这里会先重点介绍scala的一些语法.当然,这里是假设你有一些ja ...
- Mybatis值ResultMap的使用详解
Mybatis的定义 MyBatis 是一款优秀的持久层框架,它支持定制化 SQL.存储过程以及高级映射.MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集.MyBatis ...
- 浅谈Task的用法
Task是用来实现多线程的类,在以前当版本中已经有了Thread及ThreadPool,为什么还要提出Task类呢,这是因为直接操作Thread及ThreadPool,向线程中传递参数,获取线程的返回 ...