2018.8.20 Python之路---常用模块
一、re模块
查找:
re.findall(‘正则表达式’,‘字符串’)
匹配所有符合正则表达式的内容,形成一个列表,每一项都是列表中的一个元素。
ret = re.findall('\d+','sjkhk172按实际花费928') # 正则表达式,带匹配的字符串,flag
ret = re.findall('\d','sjkhk172按实际花费928') # 正则表达式,带匹配的字符串,flag
print(ret)
re.search(‘正则表达式’,‘字符串’)
只匹配从左到右的第一个,得到的不是直接的结果,而是一个变量,通过这个变量的group方法来获取结果
如果没有匹配到,会返回None,使用group会报错
ret = re.search('\d+','sjkhk172按实际花费928')
print(ret) # 内存地址,这是一个正则匹配的结果
print(ret.group()) # 通过ret.group()获取真正的结果
ret = re.search('\d+','sjkhk172按实际花费928')
if ret : # 内存地址,这是一个正则匹配的结果
print(ret.group()) # 通过ret.group()获取真正的结果
re.match('正则表达式',‘字符串’)
从头开始匹配,相当于search中的正则表达式加上一个^
ret = re.match('\d+$','172sjkhk按实际花费928')
print(ret)
字符串的扩展处理:替换、切割
split:切割
s = 'alex83taibai40egon25'
ret = re.split('\d+',s)
print(ret) #['alex', 'taibai', 'egon', '']
sub:替换
ret = re.sub('\d+','H','alex83taibai40egon25')
print(ret) #alexHtaibaiHegonH
ret = re.sub('\d+','H','alex83taibai40egon25',1)
print(ret) #alexHtaibai40egon25
subn:替换。返回一个元组,第二个元素是替换的次数。
ret = re.subn('\d+','H','alex83taibai40egon25')
print(ret)
#('alexHtaibaiHegonH', 3)
re模块的进阶:时间/空间
compile:编译正则表达式,编译成字节码,节省使用正则表达式解决问题的时间。
ret = re.compile('\d+') # 已经完成编译了
print(ret)
res = ret.findall('alex83taibai40egon25')
print(res)
res = ret.search('sjkhk172按实际花费928')
print(res.group())
finditer:返回一个迭代器,所有匹配到的内容需要迭代取到,迭代取到的每一个结果都需要group取具体值,节省内存空间。
ret = re.finditer('\d+','alex83taibai40egon25')
for i in ret:
print(i.group())
分组:
1.给不止一个字符的整体做量词约束的时候 www(\.[\w]+)+ www.baidu.com
2.优先显示,当要匹配的内容和不想匹配的内容混在一起的时候,
就匹配出所有内容,但是对实际需要的内容进行分组
3.分组和re模块中的方法 :
findall : 分组优先显示 取消(?:正则)
search :
可以通过.group(index)来取分组中的内容
可以通过.group(name)来取分组中的内容
正则 (?P<name>正则)
使用这个分组 ?P=name
split : 会保留分组内的内容到切割的结果中
ret = re.split('\d+','alex83taibai40egon25')
print(ret)
#['alex', 'taibai', 'egon', '']
ret = re.split('(\d+)','alex83taibai40egon25aa')
print(ret)
#['alex', '83', 'taibai', '40', 'egon', '25', 'aa']
二、random模块
取随机小数:数学计算
print(random.random()) # 取0-1之间的小数
print(random.uniform(1,2)) # 取1-2之间的小数
取随机整数 : 彩票 抽奖
print(random.randint(1,2)) # [1,2]
print(random.randrange(1,2)) # [1,2)
print(random.randrange(1,200,2)) # [1,200) 每两个取一个
从一个列表中随机取值:抽奖
l = ['a','b',(1,2),123]
print(random.choice(l))
print(random.sample(l,2))
打乱一个列表的顺序,在原列表的基础上直接进行修改,节省空间
洗牌
l = ['a','b',(1,2),123]
random.shuffle(l)
print(l) #[(1, 2), 'a', 123, 'b']
验证码:
4位数字验证码
6位数字验证码
6位数字+字母验证码
def code(n = 6,alpha = True):
s = ''
for i in range(n):
num = str(random.randint(0,9))
if alpha:
alpha_upper = chr(random.randint(65,90))
alpha_lower = chr(random.randint(97,122))
num = random.choice([num,alpha_upper,alpha_lower])
s += num
return s
print(code(4,False))
print(code(alpha=False))
三、时间模块(import time)
time.sleep(2) 程序走到这会等待2秒
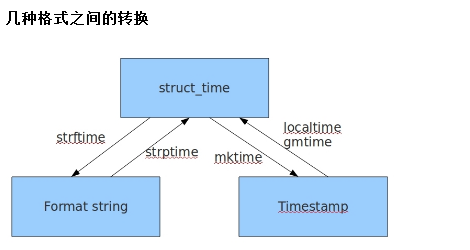
时间格式:
时间戳时间:
print(time.time()) #1534767054.6681
格式化时间:
print(time.strftime('%Y-%m-%d %H:%M:%S')) # str format time
# 2018-08-20 20:17:08
print(time.strftime('%y-%m-%d %H:%M:%S')) # str format time
# 18-08-20 20:17:08
print(time.strftime('%Y-%m-%d %X'))
# 2018-08-20 20:19:25
print(time.strftime('%c'))
# Mon Aug 20 20:18:14 2018
结构化时间:
struct_time = time.localtime() # 北京时间
print(struct_time)
#time.struct_time(tm_year=2018, tm_mon=8, tm_mday=20, tm_hour=20, tm_min=21, tm_sec=23, tm_wday=0, tm_yday=232, tm_isdst=0)
print(struct_time.tm_mon)
#
print(time.gmtime()) #伦敦时间
时间戳时间换成字符串时间
struct_time = time.localtime(1500000000)
# print(time.gmtime(1500000000))
ret = time.strftime('%y-%m-%d %H:%M:%S',struct_time)
print(ret)
字符串时间转时间戳时间
struct_time = time.strptime('2018-8-8','%Y-%m-%d')
print(struct_time)
res = time.mktime(struct_time)
print(res)
相关操作:
1.查看一下2000000000时间戳时间表示的年月日
时间戳 - 结构化 - 格式化
struct_t = time.localtime(2000000000)
print(struct_t)
print(time.strftime('%y-%m-%d',struct_t))
2.将2008-8-8转换成时间戳时间
t = time.strptime('2008-8-8','%Y-%m-%d')
print(time.mktime(t))
3.请将当前时间的当前月1号的时间戳时间取出来 - 函数
def get_time():
st = time.localtime()
st2 = time.strptime('%s-%s-1'%(st.tm_year,st.tm_mon),'%Y-%m-%d')
return time.mktime(st2)
print(get_time())
4.计算时间差 - 函数
str_time1 = '2018-8-19 22:10:8'
str_time2 = '2018-8-20 11:07:3'
struct_t1 = time.strptime(str_time1,'%Y-%m-%d %H:%M:%S')
struct_t2 = time.strptime(str_time2,'%Y-%m-%d %H:%M:%S')
timestamp1 = time.mktime(struct_t1)
timestamp2 = time.mktime(struct_t2)
sub_time = timestamp2 - timestamp1
gm_time = time.gmtime(sub_time)
# 1970-1-1 00:00:00
print('过去了%d年%d月%d天%d小时%d分钟%d秒'%(gm_time.tm_year-1970,gm_time.tm_mon-1,
gm_time.tm_mday-1,gm_time.tm_hour,
gm_time.tm_min,gm_time.tm_sec))
# 过去了0年0月0天12小时56分钟55秒
四、sys模块(import sys)
sys是和python解释器打交道的。
sys.argv 命令行参数List,第一个元素是程序本身路径
print(sys.argv) # argv的第一个参数 是python这个命令后面的值
usr = input('username')
pwd = input('password')
usr = sys.argv[1]
pwd = sys.argv[2]
if usr == 'alex' and pwd == 'alex3714':
print('登录成功')
else:
exit()
sys.exit(n) 退出程序,正常退出时exit(0),错误退出时sys.exit(1)
sys.path 返回模块的搜索路径
# 一个模块能否被顺利的导入 全看sys.path下面有没有这个模块所在的
# 自定义模块的时候 导入模块的时候 还需要再关注 sys.path
sys.modules
print(sys.modules) # 是我们导入到内存中的所有模块的名字,存在一个字典中 : 这个模块的内存地址
print(sys.modules['re'].findall('\d','abc126'))
五、os模块(import os #os是和操作系统交互的模块)
#文件和文件夹的处理
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
#执行操作系统命令
os.system("bash command") 运行shell命令,直接显示
os.popen("bash command).read() 运行shell命令,获取执行结果
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
#路径的处理
os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如果path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
六、序列化模块 (json/pickle)
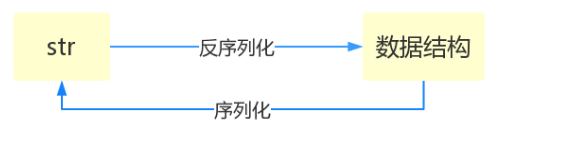
什么叫序列化——将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化。
序列化的目的
dumps loads
在内存中做数据转换 :
dumps 数据类型 转成 字符串 序列化
loads 字符串 转成 数据类型 反序列化
dump load
直接将数据类型写入文件,直接从文件中读出数据类型
dump 数据类型 写入 文件 序列化
load 文件 读出 数据类型 反序列化
json是所有语言都通用的一种序列化格式
只支持 列表 字典 字符串 数字
字典的key必须是字符串
import json
dic = {'key':'value','key2':'value2'}
ret = json.dumps(dic) #序列化
print(dic,type(dic)) #{'key': 'value', 'key2': 'value2'} <class 'dict'>
print(ret,type(ret)) #{"key": "value", "key2": "value2"} <class 'str'> res = json.loads(ret) #反序列化
print(res,type(res)) #{'key': 'value', 'key2': 'value2'} <class 'dict'> dic = {1:'value',2:'value'}
ret = json.dumps(dic) #序列化
print(dic,type(dic)) #{1: 'value', 2: 'value'} <class 'dict'>
print(ret,type(ret)) #{"1": "value", "2": "value"} <class 'str'> res = json.loads(ret) #反序列化
print(res,type(res)) #{'1': 'value', '2': 'value'} <class 'dict'> dic = {1:[1,2,3],2:(4,5,'aa')}
ret = json.dumps(dic) #序列化
print(dic,type(dic)) #{1: [1, 2, 3], 2: (4, 5, 'aa')} <class 'dict'>
print(ret,type(ret)) #{"1": [1, 2, 3], "2": [4, 5, "aa"]} <class 'str'> res = json.loads(ret) #反序列化
print(res,type(res)) #{'1': [1, 2, 3], '2': [4, 5, 'aa']} <class 'dict'> s = {1,2,'aaa'}
json.dumps(s) #不能是集合 json.dumps({(1,2,3):123}) #keys must be a string
# json 能处理的数据类型:字符串 列表 字典 数字
# 字典中的key只能是字符串 # 向文件中记录字典
dic = {'key':'value','key2':'value2'}
ret = json.dumps(dic) #序列化
with open('json_file','a') as f:
f.write(ret) #从文件中读取字典
with open('json_file','r') as f:
str_dic = f.read()
dic = json.loads(str_dic) #反序列化
print(dic.keys()) # dump load 是直接操作文件的 问题:不支持连续的存取
dic = {'key':'value','key2':'value2'}
with open('json_file','a') as f:
json.dump(dic,f)
with open('json_file','r') as f:
dic = json.load(f)
print(dic.keys()) # 一个一个存,一个一个取
dic = {'key':'value','key2':'value2'}
with open('json_file','a') as f:
str_dic = json.dumps(dic)
f.write(str_dic+'\n')
str_dic = json.dumps(dic)
f.write(str_dic+'\n')
str_dic = json.dumps(dic)
f.write(str_dic+'\n')
with open('json_file','r') as f:
for line in f:
dic = json.loads(line.strip())
print(dic.keys()) dic = {'key':'你好'}
print(json.dumps(dic,ensure_ascii=False)) #{"key": "你好"} dic = {'key':'你好'}
print(json.dumps(dic,ensure_ascii=True)) #{"key": "\u4f60\u597d"}
pickle模块
只能在python中使用,支持python几乎所有的数据类型,序列化的结果是字节,所以在和文件操作的时候用rb,wb的模式打开。
可以执行多次dump和多次load。
import pickle
# 支持python中几乎所有的数据类型, 只能在python中使用
dic = {(1,2,3):{'a','b'},1:'abc'}
ret = pickle.dumps(dic) #序列化,结果只能是字节
print(dic,type(dic)) #{(1, 2, 3): {'a', 'b'}, 1: 'abc'} <class 'dict'>
print(ret,type(ret)) #b'\x80\x03}q\x00(K\x01K\x02K\x03\x87q\x01cbuiltins\nset\nq\x02]q\x03(X\x01\x00\x00\x00aq\x04X\x01\x00\x00\x00bq\x05e\x85q\x06Rq\x07K\x01X\x03\x00\x00\x00abcq\x08u.' <class 'bytes'> res = pickle.loads(ret) #反序列化
print(res,type(res)) #{(1, 2, 3): {'a', 'b'}, 1: 'abc'} <class 'dict'> 可以多次dump 和多次 load
dic = {(1,2,3):{'a','b'},1:'abc'}
dic1 = {(1,2,3):{'a','b'},2:'abc'}
dic2 = {(1,2,3):{'a','b'},3:'abc'}
dic3 = {(1,2,3):{'a','b'},4:'abc'}
with open('pickle_file','wb') as f:
pickle.dump(dic, f)
pickle.dump(dic1, f)
pickle.dump(dic2, f)
pickle.dump(dic3, f) with open('pickle_file','rb') as f:
ret = pickle.load(f)
print(ret,type(ret))
ret = pickle.load(f)
print(ret,type(ret))
ret = pickle.load(f)
print(ret, type(ret))
ret = pickle.load(f)
print(ret, type(ret))
ret = pickle.load(f)
print(ret, type(ret)) # Ran out of input with open('pickle_file','rb') as f:
while True:
try:
ret = pickle.load(f)
print(ret,type(ret))
except EOFError:
break
七、hashlib 模块
Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等。
我们以常见的摘要算法MD5为例,计算出一个字符串的MD5值:
import hashlib SALT = b'2erer3asdfwerxdf34sdfsdfs90' def md5(pwd):
# 实例化对象
obj = hashlib.md5(SALT) #加盐
# 写入要加密的字节
obj.update(pwd.encode('utf-8'))
# 获取密文
return obj.hexdigest() # 21232f297a57a5a743894a0e4a801fc3
ret = md5('fc')
print(ret)
八、logging模块
函数式简单配置:
import logging
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message')
默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG),默认的日志格式为日志级别:Logger名称:用户输出消息。
灵活配置日志级别,日志格式,输出位置:
import logging logger = logging.basicConfig(filename='xxxxxxx.txt',
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
level=30) logging.debug('x1') #
logging.info('x2') #
logging.warning('x3') #
logging.error('x4') #
logging.critical('x5') #
logging.log(10,'x6')
配置参数:
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有: filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
自定义日志:
import logging
# 创建一个操作日志的对象logger(依赖FileHandler)
file_handler = logging.FileHandler('l1.log', 'a', encoding='utf-8') #创建一个handler 用于写入日志文件
file_handler.setFormatter(logging.Formatter(fmt="%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s"))
#设置handler 写入日志的格式
logger1 = logging.Logger('s1', level=logging.ERROR)
logger1.addHandler(file_handler)
logger1.error('') # 在创建一个操作日志的对象logger(依赖FileHandler)
file_handler2 = logging.FileHandler('l2.log', 'a', encoding='utf-8')
file_handler2.setFormatter(logging.Formatter(fmt="%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s")) logger2 = logging.Logger('s2', level=logging.ERROR)
logger2.addHandler(file_handler2) logger2.error('')
logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接口,Handler发送日志到适当的目的地,Filter提供了过滤日志信息的方法,Formatter指定日志显示格式。另外,可以通过:logger.setLevel(logging.Debug)设置级别,当然,也可以通过fh.setLevel(logging.Debug)单对文件流设置某个级别。
2018.8.20 Python之路---常用模块的更多相关文章
- python之路——常用模块
阅读目录 认识模块 什么是模块 模块的导入和使用 常用模块一 collections模块 时间模块 random模块 os模块 sys模块 序列化模块 re模块 常用模块二 hashlib模块 con ...
- python之路----常用模块二
collections模块 在内置数据类型(dict.list.set.tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter.deque.defaultdict. ...
- python之路----常用模块一
re模块 https://reg.jd.com/reg/person?ReturnUrl=https%3A//www.jd.com/ 这是京东的注册页面,打开页面我们就看到这些要求输入个人信息的提示. ...
- python笔记之常用模块用法分析
python笔记之常用模块用法分析 内置模块(不用import就可以直接使用) 常用内置函数 help(obj) 在线帮助, obj可是任何类型 callable(obj) 查看一个obj是不是可以像 ...
- 十八. Python基础(18)常用模块
十八. Python基础(18)常用模块 1 ● 常用模块及其用途 collections模块: 一些扩展的数据类型→Counter, deque, defaultdict, namedtuple, ...
- python基础31[常用模块介绍]
python基础31[常用模块介绍] python除了关键字(keywords)和内置的类型和函数(builtins),更多的功能是通过libraries(即modules)来提供的. 常用的li ...
- Python全栈开发之路 【第六篇】:Python基础之常用模块
本节内容 模块分类: 好处: 标准库: help("modules") 查看所有python自带模块列表 第三方开源模块: 自定义模块: 模块调用: import module f ...
- Python全栈之路----常用模块----re 模块
正则表达式就是字符串的匹配规则,在多数编程语言里都有相应的支持,python里对应的模块是 re. re的匹配语法有以下几种 re.match 从头开始匹配 re.search 匹配包含 re.fin ...
- Python全栈之路----常用模块----shutil模块
高级的 文件.文件包.压缩包 处理模块 参考Python之路[第四篇]:模块 #src是原文件名,fdst是新文件名 shutil.copyfileobj(fsrc, fdst[, len ...
随机推荐
- 完整的Android MVP开发之旅
开发背景 最近是在做一个与健身相关的APP,里面有训练器模块基本功能是按照特点动作的演示和描述来引导用户完成训练.在第一个版本时由于没接触过些类项目与功能花了几周的时间大概1500行代码才完成这个功能 ...
- CSS 换行
默认情况下,元素的属性是 white-space:normal:自动换行:(不把单词截断,会把单词看作一个整体) -----但是但是但是但是..当元素中的内容是一对没有空格的字符/数字时,超过容器宽度 ...
- webpack原理
webpack早就已经在前端领域大放异彩,会使用和优化webpack也已经是中.高级工程师必备技能,在此基础之上再对webpack的原理进行理解和掌握,必定会在未来的开发中事半功倍.若是对于webpa ...
- Android中内存泄露与如何有效避免OOM总结
一.关于OOM与内存泄露的概念 我们在Android开发过程中经常会遇到OOM的错误,这是因为我们在APP中没有考虑dalvik虚拟机内存消耗的问题. 1.什么是OOM OOM:即OutOfMemoe ...
- Spring Boot 2.x 基础案例:整合Dubbo 2.7.3+Nacos1.1.3(配置中心)
本文原创首发于公众号:Java技术干货 1.概述 本文将Nacos作为配置中心,实现配置外部化,动态更新.这样做的优点:不需要重启应用,便可以动态更新应用里的配置信息.在如今流行的微服务应用下,将应用 ...
- 安装高可用Hadoop生态 (三) 安装Hadoop
3. 安装Hadoop 3.1. 解压程序 ※ 3台服务器分别执行 .tar.gz -C/opt/cloud/packages /opt/cloud/bin/hadoop /etc/hadoop ...
- Redis开发与运维:数据迁移(下)
上一篇,有朋友留言redis-port,借此机会我尝试使用一下redis-port这个同步工具 redis-port 已编译版 https://github.com/CodisLabs/redis-p ...
- java中的静态
static静态 public static void main 类只是用来存储和被调用的,而对象是需要执行的,执行时就必定需要知道程序的入口,这个入口就是由main所在的位置. Java的类中没有m ...
- 使用java语言实现一个动态数组(详解)(数据结构)
废话不多说,上代码 1.从类名开始(我真是太贴心了) public class Array<E> 首先数组类需要带有泛型,这个不多说.需要注意的是在java中,数组只能存放同一个类型的. ...
- 帝国CMS 6.5功能解密:网站安全防火墙使用说明
有关帝国CMS新版防火墙介绍可以查看:http://bbs.phome.net/showthread-13-136169-0.html 本文为大家讲解如何使用网站防火墙:一.配置“网站防火墙”有下面两 ...