DGCNN
架构总览
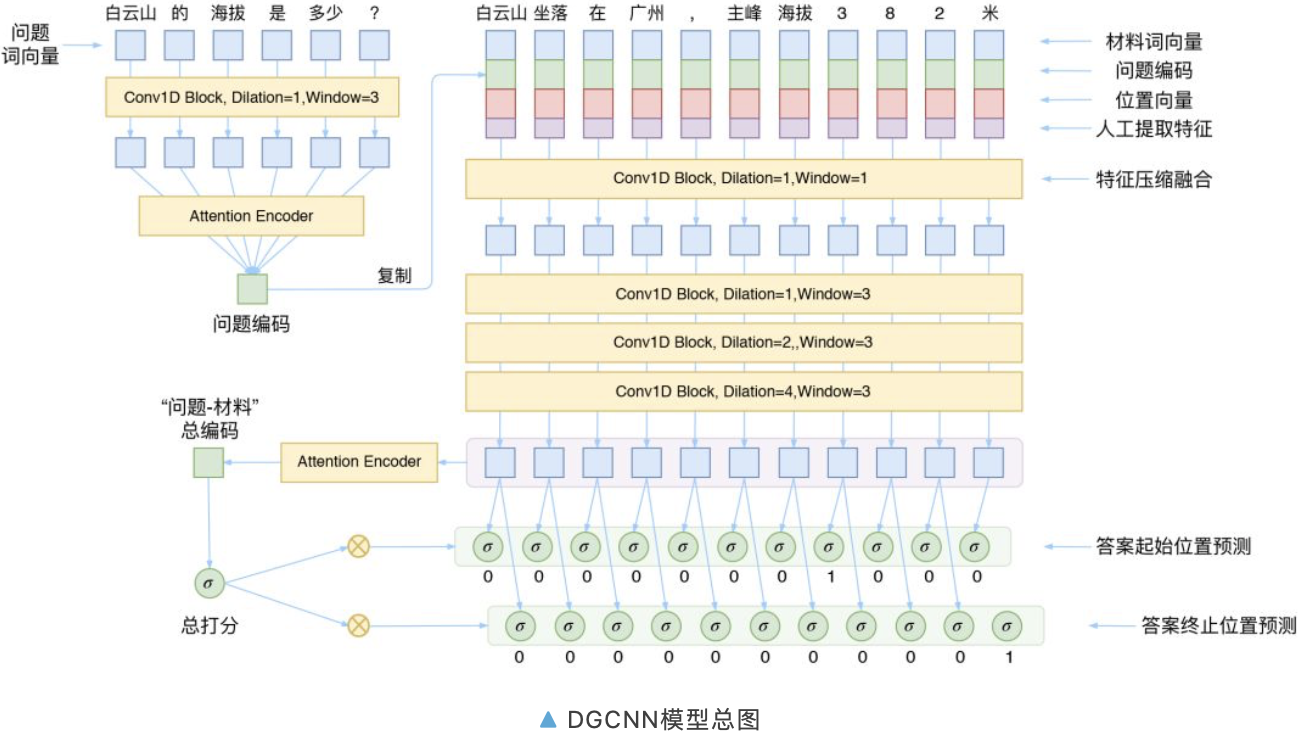
模型的整体架构源于 WebQA 的参考论文 Dataset and Neural Recurrent Sequence Labeling Model for Open-Domain Factoid Question [2]。这篇论文有几个特点:
1. 直接将问题用 LSTM 编码后得到“问题编码”,然后拼接到材料的每一个词向量中
2. 人工提取了 2 个共现特征
3. 将最后的预测转化为了一个序列标注任务,用 CRF 解决
而 DGCNN 基本上就是沿着这个思路设计的,不同点在于:
1. 把原模型中所有的 LSTM 部分都替换为 CNN
2. 提取了更丰富的共现特征(8 个)
3. 去掉 CRF,改为“0/1 标注”来分开识别答案的开始和终止位置,这可以看成一种“半指针半标注”的结构
卷积结构
这部分我们来对图中的 Conv1D Block 进行解析
门机制
模型中采用的卷积结构,来自 FaceBook 的 Convolutional Sequence to Sequence Learning [3]
假设我们要处理的向量序列是 X=[x1,x2,…,xn],那么我们可以给普通的一维卷积加个门:

注意这里的两个 Conv1D 形式一样(比如卷积核数、窗口大小都一样),但权值是不共享的,也就是说参数翻倍了,其中一个用 sigmoid 函数激活,另外一个不加激活函数,然后将它们逐位相乘。
因为 sigmoid 函数的值域是 (0,1),所以直觉上来看,就是给 Conv1D 的每个输出都加了一个“阀门”来控制流量。这就是 GCNN 的结构了,或者可以将这种结构看成一个激活函数,称为 GLU(Gated Linear Unit)。
除了有直观的意义外,用 GCNN 的一个好处是它几乎不用担心梯度消失问题,因为有一个卷积是不加任意激活函数的,所以对这部分求导是个常数(乘以门),可以说梯度消失的概率非常小。如果输入和输出的维度大小一致,那么我们就把输入也加到里边,即使用残差结构:
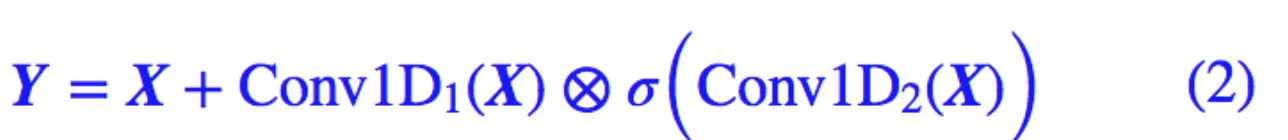

值得一提的是,我们使用残差结构,并不只是为了解决梯度消失,而是使得信息能够在多通道传输。我们可以将上式改写为更形象的等价形式,以便我们更清晰看到信息是如何流动的:

从 (3) 式中我们能更清楚看到信息的流向:以 1−σ 的概率直接通过,以 σ 的概率经过变换后才通过。这个形式非常像递归神经网络中的 GRU 模型。
补充推导:

由于 Conv1D1 并没有加激活函数,所以它只是一个线性变换,从而 Conv1D1(X)−X 可以结合在一起,等效于单一一个 Conv1D1。说白了,在训练过程中,Conv1D1(X)−X 能做到的事情,Conv1D1(X) 也能做到。从而 (2) 和 (3) 两者是等价的。
膨胀卷积
接下来,为了使得 CNN 模型能够捕捉更远的的距离,并且又不至于增加模型参数,我们使用了膨胀卷积。
普通卷积跟膨胀卷积的对比,可以用一张图来演示:

同样是三层的卷积神经网络(第一层是输入层),窗口大小为 3。普通卷积在第三层时,每个节点只能捕捉到前后 3 个输入,而跟其他输入完全不沾边。
而膨胀卷积在第三层时则能够捕捉到前后 7 个输入,但参数量和速度都没有变化。这是因为在第二层卷积时,膨胀卷积跳过与中心直接相邻的输入,直接捕捉中心和次相邻的输入(膨胀率为 2),也可以看成是一个“窗口大小为 5 的、但被挖空了两个格的卷积”,所以膨胀卷积也叫空洞卷积(Atrous Convolution)。
在第三层卷积时,则连续跳过了三个输入(膨胀率为 4),也可以看成一个“窗口大小为 9、但被挖空了 6 个格的卷积”。而如果在相关的输入输出连一条线,就会发现第三层的任意一个节点,跟前后 7 个原始输入都有联系。
按照“尽量不重不漏”的原则,膨胀卷积的卷积率一般是按照 1、2、4、8、...这样的几何级数增长。当然,这里指明了是“尽量”,因为还是有些重复的。这个比例参考了 Google 的 wavenet 模型。
Block
现在就可以解释模型图中的各个 Conv1D Block 了,如果输入跟输出维度大小一致时,那么就是膨胀卷积版的 (3) 式;如果输出跟输出维度大小不一致时,就是简单的 (1) 式,窗口大小和膨胀率在图上都已经注明。
注意力
从模型示意图可以看到,本文的 DGCNN 模型中,Attention 主要用于取代简单的 Pooling 来完成对序列信息的整合,包括将问题的向量序列编码为一个总的问题向量,将材料的序列编码为一个总的材料向量。
这里使用的 Attention 稍微不同于 Attention is All You Need 中的 Attention,本文这种 Attention 可以认为是一种“加性注意力”,形式为:
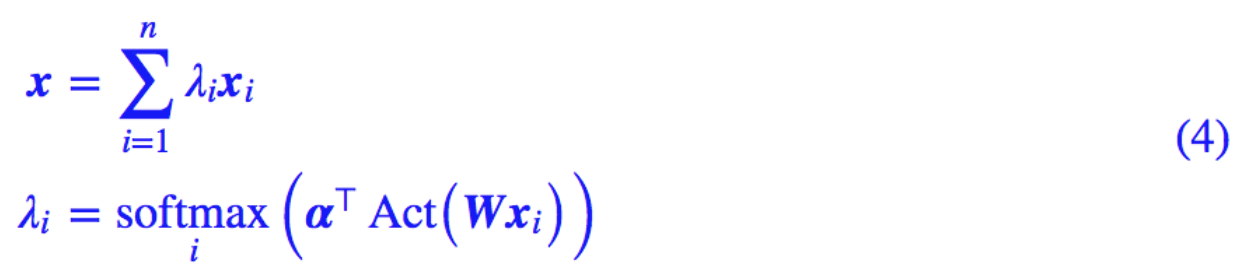
这里的 v,W 都为可训练参数。而 Act 为激活函数,一般会取 tanh,也可以考虑 swish 函数。注意用 swish 时,最好把偏置项也加上去,变为:

这种 Attention 的方案参考自 R-Net 模型(注:不一定是 R-Net 首创,只是我是从 R-Net 中学来的)。
位置向量
为了增强 CNN 的位置感,我们还补充了位置向量,拼接到材料的每个词向量中。位置向量的构造方法直接沿用 Attention is All You Need 中的方案:

输出设计
这部分是我们整个模型中颇具特色的地方。
思路分析
到现在,模型的整体结构应该已经呈现出来了。首先我们通过卷积和注意力把问题编码为一个固定的向量,这个向量拼接到材料的每个词向量中,并且还拼接了位置向量、人工特征。
这时候我们得到了一个混合了问题、材料信息的特征序列,直接对这个序列进行处理即可,所以后面接了几层卷积进行编码处理,然后直接对序列进行标注,而不需要再对问题进行交互了。
在 SQUAD 的评测中,材料是肯定有答案的,并且答案所在的位置也做好了标注,所以 SQUAD 的模型一般是对整个序列做两次 softmax,来预测答案的开始位置和终止位置,我们一般称之为“指针网络”。
然而在 WebQA 式问答,材料中不一定有答案,所以我们不用 softmax,而是对整个序列都用 sigmoid,这样既允许了材料中没有答案,也允许答案在材料中多次出现。
双标注输出
既然用到标注,那么理论上最简单的方案是输出一个 0/1 序列:直接标注出材料中的每个词“是(1)”或“否(0)”答案。
然而,这样的效果并不好,因为一个答案可能由连续多个不同的词组成,要让模型将这些不同的词都有同样的标注结果,有可能“强模型所难”。于是我们还是用两次标注的方式,来分别标注答案的开始位置和终止位置。
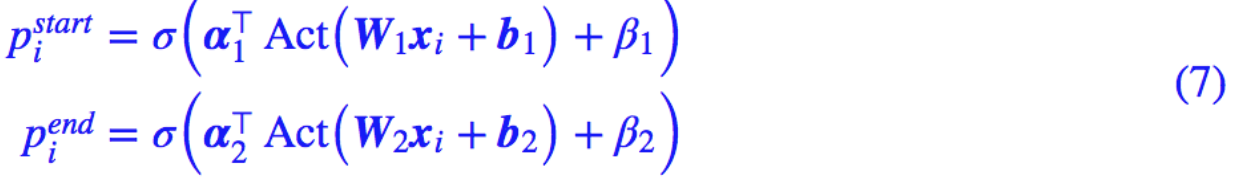
这样一来,模型的输出设计跟指针方式和纯序列标注都不一样,或者说是两者的简化及融合。
大局观
最后,为了增加模型的“大局观”,我们将材料的序列编码为一个整体的向量,然后接一个全连接层来得到一个全局的打分,并把这个打分的结果乘到前面的标注中,即变成:

这个全局打分对模型的收敛和效果具有重要的意义,它的作用是更好地判断材料中是否存在答案,一旦材料中没有答案,直接让 即可,不用“煞费苦心”让每个词的标注都为 0。
即可,不用“煞费苦心”让每个词的标注都为 0。
人工特征
文章的前面部分,我们已经多次提到过人工特征,那么这些人工特征的作用有多大呢?简单目测的话,这几个人工特征对于模型效果的提升可能超过 2%。可见设计好的特征对模型效果的特征、模型复杂度的降低,都有着重要的作用。
Q-E全匹配
也就是判断材料中的词是否在问题出现过,出现过则为 1,没出现过则为 0。这个特征的思路是直接告诉模型问题中的词在材料中什么地方出现了,那些地方附近就很有可能有答案。这跟我们人类做阅读理解的思路是吻合的。
E-E共现
这个特征是计算某个材料中的词在其他材料中的出现比例。比如有 10 段材料,第一段材料有一个词 w,在其余九段材料中,有 4 段都包含了这个词,那么第一段材料的词 w 就获得一个人工特征 4/10。 这个特征的思路是一个词出现在的材料越多,这个词越有可能是答案。
Q-E软匹配
以问题大小为窗口来对材料的每个窗口算 Jaccard 相似度、相对编辑距离。
比如问题“白云山 的 海拔 是 多少 ?”,材料“白云山 坐落 在 广州 , 主峰 海拔 3 8 2 米”。问题有 6 个词,那么窗口大小就为 6,将材料拆分为:

其中 X 代表占位符。有了这个拆分,我就可以算每一块与问题的 Jaccard 相似度了,将相似度的结果作为当前词(也就是红色词)的一个特征,上述例子算得 [0.13, 0.11, 0.1, 0.09, 0.09, 0.09, 0.09, 0.09, 0.09, 0.1, 0]。
同样地,我们还可以算每一块与问题的编辑距离,然后除以窗口大小,就得到一个 0~1 之间的数,我称之为“相对编辑距离”,上述例子算得 [0.83, 0.83, 0.83, 0.83, 1, 1, 1, 0.83, 1, 1, 1]。
Jaccard 相似度是无序的,而编辑距离是有序的,因此这两个做法相对于从有序和无序两个角度来衡量问题和材料之间的相似度。这两个特征的思路跟第一个特征一样,都是告诉模型材料中哪部分会跟问题相似,那部分的附近就有可能有答案。
模型设置
下面是实现模型的一些基本要点。
中文分词
从前面的介绍中可以看到,本模型是基于词来实现的,并且基于前面说的人工特征简单引入了字符级别的信息。不过,为了使得模型整体上更加灵活,能够应答更多的问题,本文仅仅对输入进行了一个基本的分词,使得分词的颗粒度尽量低一些。
具体实现为:自己写了一个基于一元模型的分词模块,自行准备了一个约 50 万词的词典,而所有的英文、数字都被拆开为单个的字母和数字,比如 apple 就变成了五个“词”:a p p l e,382 就变成了三个“词”:3 8 2。
由于没有新词发现功能,这样一来,整个词表的词就不会超过 50 万。事实上,我们最后得到的模型,模型总词数只有 30 万左右。
当然,读者可以使用结巴分词,关闭结巴分词的新词发现,并且手动对数字和英文进行拆分,效果是一样的。
部分参数
1. 词向量的维度为 128 维,由比赛方提供的训练语料、WebQA 语料、50 万百度百科条目、100 万百科知道问题用 Word2Vec 预训练而成,其中 Word2Vec 的模型为 Skip Gram,窗口为 5,负采样数为 8,迭代次数为 8,训练时间约为 12 小时;
2. 词向量在 DGCNN 模型的训练过程中保持固定;
3. 所有 Conv1D 的输出维度皆为 128 维,位置向量也是 128 维;
4. Conv1D 的最大长度取为 100,如果一个 batch 中某些样本涉及到 padding,那么对 padding 部分要做好 mask;
5. 由于最后变成一个二分类的标注形式,并且考虑到正负类不均衡,使用二分类的 focal loss 作为损失函数;
6. 用 adam 优化器进行训练,先用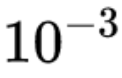 的学习率训练到最优(大概 6 个 epoch 内),然后加载最优模型,改用
的学习率训练到最优(大概 6 个 epoch 内),然后加载最优模型,改用 学习率训练到最优(3 个 epoch 内)。
学习率训练到最优(3 个 epoch 内)。
正则项
在比赛后期,我们发现一种类似 DropPath 的正则化能轻微提升效果,不过提升幅度我也不大确定,总之当时是带来了一定的提升。
这个正则化手段建立在 (3) 式的基础上,我们的思路是在训练阶段对“门”进行扰动:
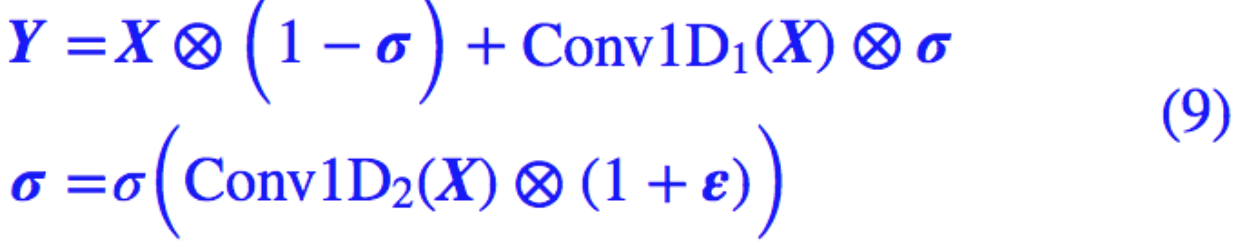

其中 ε 是 [−0.1,0.1] 内的均匀随机数张量。这样一来,我们给 GCNN 的“门”加入了“乘性噪声”来使得具有更好的鲁棒性(对抗参数的小扰动)。
这个正则化方案的提出,多多少少受到了 FractalNet: Ultra-Deep Neural Networks without Residuals [5] 和 Shake-Shake regularization [6] 里边的正则化技术启发。
解码策略
打分方式
何为答案解码?不管是用 softmax 形式的指针,还是用本文的 sigmoid 形式的“半指针-半标注”,最后模型输出的是两列浮点数,分别代表了答案起始位置和终止位置的打分。
但问题是,用什么指标确定答案区间呢?一般的做法是:确定答案的最大长度 max_words(我取了 10,但汉字算一个,字母和数字只算半个),然后遍历材料所有长度不超过 max_words 的区间,计算它们起始位置和终止位置的打分的和或积,然后取最大值。
参考:https://mp.weixin.qq.com/s/eAphGLNM2FZhIJmtsS0kpg
DGCNN的更多相关文章
- 【论文阅读】DGCNN:Dynamic Graph CNN for Learning on Point Clouds
毕设进了图网络的坑,感觉有点难,一点点慢慢学吧,本文方法是<Rethinking Table Recognition using Graph Neural Networks>中关系建模环节 ...
- 论文笔记:(TOG2019)DGCNN : Dynamic Graph CNN for Learning on Point Clouds
目录 摘要 一.引言 二.相关工作 三.我们的方法 3.1 边缘卷积Edge Convolution 3.2动态图更新 3.3 性质 3.4 与现有方法比较 四.评估 4.1 分类 4.2 模型复杂度 ...
- Mac 提交代码到Github
然后在GitHub上创建版本库(Repository),在GitHub首页上,点击“Create a New Repository”,如下所示(为了便于后面演示,创建README.md这步暂不勾选): ...
- Relation-Shape Convolutional Neural Network for Point Cloud Analysis(CVPR 2019)
代码:https://github.com/Yochengliu/Relation-Shape-CNN 文章:https://arxiv.org/abs/1904.07601 作者直播:https:/ ...
- 【GNN】图神经网络小结
图神经网络小结 图神经网络小结 图神经网络分类 GCN: 由谱方法到空域方法 GCN概述 GCN的输出机制 GCN的不同方法 基于谱方法的GCN 初始 切比雪夫K阶截断: ChebNet 一阶Cheb ...
- NLP(二十六)限定领域的三元组抽取的一次尝试
本文将会介绍笔者在2019语言与智能技术竞赛的三元组抽取比赛方面的一次尝试.由于该比赛早已结束,笔者当时也没有参加这个比赛,因此没有测评成绩,我们也只能拿到训练集和验证集.但是,这并不耽误我们在这 ...
- CVPR2020:点云分析中三维图形卷积网络中可变形核的学习
CVPR2020:点云分析中三维图形卷积网络中可变形核的学习 Convolution in the Cloud: Learning Deformable Kernels in 3D Graph Con ...
- CVPR2020:点云分类的自动放大框架PointAugment
CVPR2020:点云分类的自动放大框架PointAugment PointAugment: An Auto-Augmentation Framework for Point Cloud Classi ...
- CVPR2020:基于自适应采样的非局部神经网络鲁棒点云处理(PointASNL)
CVPR2020:基于自适应采样的非局部神经网络鲁棒点云处理(PointASNL) PointASNL: Robust Point Clouds Processing Using Nonlocal N ...
随机推荐
- Git 实用命令记录
自从上次写了一篇 Git 入门 的相关博客以来,一直自以为自己能完全的掌握 Git,其实不然,今天一小伙问我,如何删除远程上面的一个分支,呃,不会. git branch -d 分支名 只能删除本地的 ...
- 控制FlowDocumentScrollViewer滚动到最下方
原文发布于:https://www.chenxublog.com/2019/07/14/contrlo-flowdocumentscrollviewer-to-bottom.html 由于我在llco ...
- go实现整型的二进制转化
go中已经实现了int->bin的转化函数,我这里只是化过程逻辑的实现,至于原理我就假设大家都知道了 本案例只考虑 int->bin 的转化 包含了正整数,负整数,0 的转化 packa ...
- python基础(25):面向对象三大特性二(多态、封装)
1. 多态 1.1 什么是多态 多态指的是一类事物有多种形态. 动物有多种形态:人,狗,猪. import abc class Animal(metaclass=abc.ABCMeta): #同一类事 ...
- map元素area热区坐标自适应窗口大小
业务需求:点击图片热区跳转到不同的链接地址,同时要自适应窗口尺寸的变化. 问题:热区坐标点不会随着窗口调整变化 解决思路:获取初始的坐标点与图片宽高的比例,然后用比例乘以调整后的窗口宽高,就获得了新的 ...
- dependencies和devDependencies区别
vue-cli3.x项目的package.json中,有两种依赖: dependencies:项目依赖.在编码阶段和呈现页面阶段都需要的,也就是说,项目依赖即在开发环境中,又在生产环境中.如js框架v ...
- 前端开发JS——jQuery常用方法
jQuery基础(三)- 事件篇 1.jQuery鼠标事件之click与dbclick事件 click方法用于监听用户单击操作,dbclick方法用于监听用户双击操作,这两个方法用法及其类似,所以 ...
- JS基础语法---函数练习part1---5个练习
练习1:求两个数字的和:获取任意的两个数字的和 function getSum(x, y) { return x + y; } console.log(getSum(10, 20)); 练习2:求1- ...
- SQLi-LABS Page-4 (Challenges) Less-54-Less-65
Less-54 union - 1 http://10.10.202.112/sqli/Less-54?id=-1' union select 1,2,group_concat(table_name) ...
- MVC 身份证图像识别(调用dll)
源码下载 -> 提取码 QQ505645074 Index.cshtml <!DOCTYPE html> <html> <head> <meta cha ...