python爬虫笔记之re.match匹配,与search、findall区别
为什么re.match匹配不到?re.match匹配规则怎样?(捕一下seo)
re.match(pattern, string[, flags])
pattern为匹配规则,即输入正则表达式。
string为,待匹配的文本或字符串。
网上的定义【 从要匹配的字符串的头部开始,当匹配到string的尾部还没有匹配结束时,返回None;
当匹配过程中出现了无法匹配的字母,返回None。】
但我觉得要强调关键一句【仅从要匹配的字符串头部开始匹配!】
看看例子,你就明白了!!!想用的话,一定要看!

出现<_src.SRE_Match object at .....>表示匹配成功。
出现None表示,匹配失败或未匹配到。
总结:re.match只从待匹配的字符串或文本的开头开始匹配,即如果匹配的字符串不在开头,而是在中间或结尾,则无法匹配!
———————————————————分割线——————————————————
顺便对比下re.match、re.search、re.findall的区别
match()函数只在string的开始位置匹配(例子如上图)。
search()会扫描整个string查找匹配,会扫描整个字符串并返回第一个成功的匹配。

re.findall()将返回一个所匹配的字符串的字符串列表。

———————————————————分割线——————————————————
《用python写网络爬虫》中1.4.4链接爬虫中,下图为有异议代码

这里的输出经测试,根本啥也没有,如下图

查了很久,应该是因为re.match一直匹配不到数据引起的,毕竟他只匹配开头。
我将re.match改为re.search,再测试,可正常下载
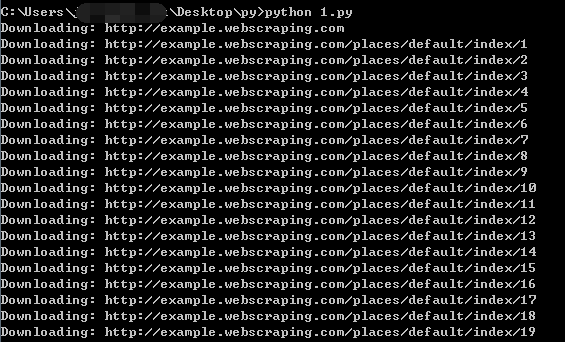
分析:可能是由于书编写时,http://example.webscraping.com/页面所带的链接都是:/index/1、/index/2……且输入匹配表达式为 【 /(index/view) 】,使用的是re.match匹配,如果匹配上述的url则没问题,而现在该网站页面所带的链接为:/places/default/index/1、/places/default/index/2……所以,上文讲到的re.match的特点,从开头开始匹配,则这时候re.match就会一直匹配不上!我将它换位re.search就可以解决这个问题了。
如有错误,麻烦及时指正,谢谢!
python爬虫笔记之re.match匹配,与search、findall区别的更多相关文章
- [Python爬虫笔记][随意找个博客入门(一)]
[Python爬虫笔记][随意找个博客入门(一)] 标签(空格分隔): Python 爬虫 2016年暑假 来源博客:挣脱不足与蒙昧 1.简单的爬取特定url的html代码 import urllib ...
- Python爬虫笔记一(来自MOOC) Requests库入门
Python爬虫笔记一(来自MOOC) 提示:本文是我在中国大学MOOC里面自学以及敲的一部分代码,纯一个记录文,如果刚好有人也是看的这个课,方便搬运在自己电脑上运行. 课程为:北京理工大学-嵩天-P ...
- Python学习笔记——基础篇【第五周】——正在表达式(re.match与re.search的区别)
目录 1.正在表达式 2.正则表达式常用5种操作 3.正则表达式实例 4.re.match与re.search的区别 5.json 和 pickle 1.正则表达式 语法: import re # ...
- python爬虫笔记Day01
python爬虫笔记第一天 Requests库的安装 先在cmd中pip install requests 再打开Python IDM写入import requests 完成requests在.py文 ...
- 正则表达式中 re.match与re.search的区别
标签: 本文和大家分享的主要是python正则表达式中re.match函数与re.search方法的相关用法及异同点,希望通过本文的分享,能对大家有所帮助. re.match函数 re.match 尝 ...
- re.match与re.search的区别
re.match与re.search的区别 re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None:而re.search匹配整个字符串,直到找到一个匹配. 实 ...
- PYTHON 爬虫笔记四:正则表达式基础用法
知识点一:正则表达式详解及其基本使用方法 什么是正则表达式 正则表达式对子符串操作的一种逻辑公式,就是事先定义好的一些特定字符.及这些特定字符的组合,组成一个‘规则字符串’,这个‘规则字符串’用来表达 ...
- Python爬虫笔记安装篇
目录 爬虫三步 请求库 Requests:阻塞式请求库 Requests是什么 Requests安装 selenium:浏览器自动化测试 selenium安装 PhantomJS:隐藏浏览器窗口 Ph ...
- Python爬虫笔记技术篇
目录 前言 requests出现中文乱码 使用代理 BeautifulSoup的使用 Selenium的使用 基础使用 Selenium获取网页动态数据赋值给BeautifulSoup Seleniu ...
随机推荐
- grep专题
grep -R --include="*.cpp" key dir[指定文件的扩展名] 上述命令的含义: 在dir目录下递归查找所有.cpp文件中的关键字key grep -r m ...
- 【必须知道】Enum_Flags
[Flags] enum AnyThings{ A=1, B=2, C=4, D=8 } 枚举赋值必须是2^n才可以,目的是实现他们的二进制表示中的 1 ,不要重叠,如 1=0001 2=0010 ...
- JS function document.onclick(){}报错Syntax error on token "function", delete this token - CSDN博客
原文:JS function document.onclick(){}报错Syntax error on token "function", delete this token - ...
- Delphi编写系统服务:完成端口演示
在开发大量Socket并发服务器,完成端口加重叠I/O是迄今为止最好的一种解决方案,下面是简单的介绍: “完成端口”模型是迄今为止最为复杂的一种I/O模型,特别适合需要同时管理为数众多的套接字,采 ...
- Silverlight消散,WinRT登台
2011年,Silverlight刚开始有蓬勃发展的起色,不利的传言就开始大量流传.不安的Silverlight开发者们要求微软澄清,但得到的只是沉默.终于随着微软在BUILD上亮相Window 8以 ...
- ASP.NET 5 (vNext) 牛刀小試:自帶 DI 容器
小引 在 ASP.NET 5(vNext)之前,亦即 MVC 4/5.Web API 2 的时代,MVC 与 Web API 框架彼此有非常相似的设计,却是以不同的代码来实现.现在,ASP.NET 5 ...
- CAP碎碎念
整个2017年都在搞大数据平台,完全远离了机器学习,甚至都不记得写过类似ETL的job. 从数据到平台,从业务处理到基础服务. Metrics的收集,报警,生成报表.Data pipeline的准确性 ...
- Ural_1169_Pairs
此题略坑... 思路:把N个点分成m若干个联通子图,然后用m-1个桥把这m个联通子图连接起来即可. 若每个联通子图内部都是完全图也符合题意,但答案却是Wrong Answer,只有把每个联通子图内部当 ...
- flask(一)
一.python现阶段三大主流框架Django Tornado Flask的对比 特点: 1.Django的特点是大而全,集成了很多组件,属于全能型框架 2.tornado的主要特点是原生异步非阻塞, ...
- Spring Boot入门篇(基于Spring Boot 2.0系列)
1:概述: Spring Boot是用来简化Spring应用的初始化开发过程. 2:特性: 创建独立的应用(jar|war形式); 需要用到spring-boot-maven-plugin插件 直接嵌 ...