python-多任务编程04-生成器(generator)
生成器是一类特殊的迭代器,创建方法比自定迭代器类更加简单
使用()创建生成器
把列表生成式的 [ ] 改成 ( )
In [15]: L = [ x*2 for x in range(5)] In [16]: L
Out[16]: [0, 2, 4, 6, 8] In [17]: G = ( x*2 for x in range(5)) In [18]: G
Out[18]: <generator object <genexpr> at 0x7f626c132db0>
对于生成器G,我们可以按照迭代器的使用方法来使用,即可以通过next()函数、for循环、list()等方法使用,当遍历完后再调用next()依然会抛出StopIteration异常
In [19]: next(G)
Out[19]: 0 In [20]: next(G)
Out[20]: 2 In [21]: next(G)
Out[21]: 4 In [22]: next(G)
Out[22]: 6 In [23]: next(G)
Out[23]: 8 In [24]: next(G)
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
<ipython-input-24-380e167d6934> in <module>()
----> 1 next(G) StopIteration:
使用yield创建生成器
当算法比较复杂,用类似列表生成式的 for 循环无法实现的时候,还可以用函数+yield来实现。简单来说:只要在def中有yield关键字的 就称为 生成器。此时按照调用函数的方式( 案例中为F = fib(5) )使用生成器就不再是执行函数体了,而是会返回一个生成器对象( 案例中为F ),然后就可以按照使用迭代器的方式来使用生成器了。如实现斐波那契生成器
def fibonacci(num):
a, b = 0, 1
current = 0
while current < num:
yield a
a, b = b, a + b
current += 1
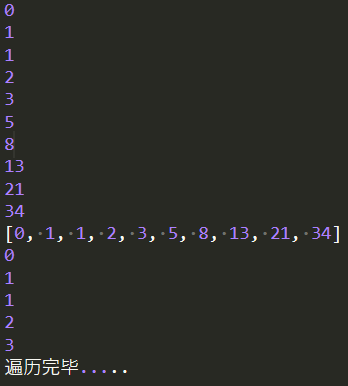
return '遍历完毕.....' def main():
f1 = fibonacci(10)
f2 = fibonacci(10)
f3 = fibonacci(5)
# for循环比遍历生成器
for i in f1:
print(i)
# list处理生成器
print(list(f2))
# while循环处理生成器
while True:
try:
print(next(f3))
except StopIteration as e:
# 异常StopIteration的value属性即为生成器return的值
print(e.value)
break if __name__ == '__main__':
main()
运行结果为:
- 使用了yield关键字的函数不再是函数,而是生成器。(使用了yield的函数就是生成器)
- yield关键字有两点作用:
- 保存当前运行状态(断点),然后暂停执行,即将生成器(函数)挂起
- 将yield关键字后面表达式的值作为返回值返回,此时可以理解为起到了return的作用
- 可以使用next()函数让生成器从断点处继续执行,即唤醒生成器(函数)
- Python3中的生成器可以使用return返回最终运行的返回值,而Python2中的生成器不允许使用return返回一个返回值(即可以使用return从生成器中退出,但return后不能有任何表达式)。
使用send唤醒
除了可以使用next()函数来唤醒生成器继续执行外,还可以使用send()函数来唤醒执行。使用send()函数的一个好处是可以在唤醒的同时向断点处传入一个附加数据。如下面例子,使用send传入一个4,使数列在传入4后从4开始计算下面的值
def fibonacci(num):
a, b = 0, 1
current = 0
while current < num:
# ret用来接收send()传入的参数,若是next()则ret为None
ret = yield a
print('ret:', ret)
# 当ret不为None时,则将b设置为传入的新的起始值,如4,这样下一次遍历时,a = b = 4,就会从4往下开始返回了
if ret:
b = ret
a, b = b, a + b
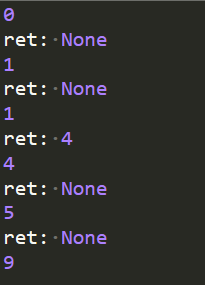
current += 1 def main():
f1 = fibonacci(10)
print(next(f1))
print(next(f1))
# 除了next可以获取生成器下一个值外,还可以使用send()方法,区别就是send()支持传入一个参数
# 这个传入的参数其中一个作用就是可以用来设置生成器下一次返回的起始值
# f1.send(None)等价于next(f1)
print(f1.send(None))
# send(4)传入参数值4,在生成器中,使用传入参数处理想要的逻辑
print(f1.send(4))
print(f1.send(None))
print(f1.send(None)) if __name__ == '__main__':
main()
运行结果为:
python-多任务编程04-生成器(generator)的更多相关文章
- Python高级编程之生成器(Generator)与coroutine(二):coroutine介绍
原创作品,转载请注明出处:点我 上一篇文章Python高级编程之生成器(Generator)与coroutine(一):Generator中,我们介绍了什么是Generator,以及写了几个使用Gen ...
- Python高级编程之生成器(Generator)与coroutine(一):Generator
转载请注明出处:点我 这是一系列的文章,会从基础开始一步步的介绍Python中的Generator以及coroutine(协程)(主要是介绍coroutine),并且详细的讲述了Python中coro ...
- Python高级编程之生成器(Generator)与coroutine(四):一个简单的多任务系统
啊,终于要把这一个系列写完整了,好高兴啊 在前面的三篇文章中介绍了Python的Python的Generator和coroutine(协程)相关的编程技术,接下来这篇文章会用Python的corout ...
- Python高级编程之生成器(Generator)与coroutine(三):coroutine与pipeline(管道)和Dataflow(数据流_
原创作品,转载请注明出处:点我 在前两篇文章中,我们介绍了什么是Generator和coroutine,在这一篇文章中,我们会介绍coroutine在模拟pipeline(管道 )和控制Dataflo ...
- Python并发编程04 /多线程、生产消费者模型、线程进程对比、线程的方法、线程join、守护线程、线程互斥锁
Python并发编程04 /多线程.生产消费者模型.线程进程对比.线程的方法.线程join.守护线程.线程互斥锁 目录 Python并发编程04 /多线程.生产消费者模型.线程进程对比.线程的方法.线 ...
- Python网络编程04 /recv工作原理、展示收发问题、粘包现象
Python网络编程04 /recv工作原理.展示收发问题.粘包现象 目录 Python网络编程04 /recv工作原理.展示收发问题.粘包现象 1. recv工作原理 2. 展示收发问题示例 发多次 ...
- Python学习笔记014——生成器Generator
1 生成器定义 在Python中,一边循环一边计算的机制,称之为生成器(generator). 生成器是一个迭代器. 含有yield语句的函数是生成器函数,该函数被调用时返回一个生成器对象(yield ...
- Python核心编程之生成器
生成器 1. 什么是生成器 大家知道通过列表生成式(不知道的可自行百度一下),我们可以直接创建一个列表,但是,受内存限制,列表内容肯定是有限的.比如我们要创建一个包含100万个元素的列表,这100万个 ...
- python关于type()与生成器generator的用法
如果按这种形式写 type(a)(b) 那此处的b是个可迭代对象,这个对象迭代完成后,再放到type里 from pymysql._compat import range_type, text ...
- python函数式编程之生成器
在前面的学习过程中,我们知道,迭代器有两个好处: 一是不依赖索引的统一的迭代方法 二是惰性计算,节省内存 但是迭代器也有自己的显著的缺点,那就是 不如按照索引取值方便 一次性,只能向后取值,不能向前取 ...
随机推荐
- 黎活明8天快速掌握android视频教程--18_在SQLite中使用事务
1 所谓的事业就是一系列的操作 比如:执行转账操作:将personid=1的账户转账10元到personid=2的账号中 所以的一系列操作就是:personid=1的账户钱要减少10元 personi ...
- ECSHOP 2.5.1 二次开发文档【文件结构说明和数据库表分析】
ecshop文件架构说明 /* ECShop 2.5.1 的结构图及各文件相应功能介绍 ECShop2.5.1_Beta upload 的目录 ┣ activity.php 活动列表 ┣ affich ...
- SDL软件安全读书笔记(一)
# 如何应对当前的全球网络安全威胁? 开发安全漏洞尽可能少的软件,应该着眼于源头安全. 边界安全盒深度防御是重要的安全手段,但软件自身的安全是安全防护的第一关. 即使软件源头存在较少的漏洞,这些漏洞也 ...
- MAC安装VMware fusion
1.下载VMware fusion 11 https://www.vmware.com/cn/products/fusion/fusion-evaluation.html 2.安装后启用输入注册码 V ...
- yum本地源创建
1 安装yum-utils包,yum-utils可以将需要的包下载在本地,安装后可以使用yumdownloader yum -y install yum-utils* 2 建立目录/yum/yum ...
- Redis高级特性介绍以及实例分析
Redis基础类型回顾 转自:http://www.jianshu.com/p/af7043e6c8f9 String Redis中最基本,也是最简单的数据类型.注意,VALUE既可以是简单的Stri ...
- git和github入门指南(1)
1.git和github简介 1.1.git是什么?github是什么?git和github的关系? Git是一个开源的分布式版本控制系统,可以有效.高速地处理从很小到非常大的项目版本管理. Git ...
- 01 . Shell详细入门介绍及简单应用
Shell简介 Shell 是一个 C 语言编写的脚本语言,它是用户与 Linux 的桥梁,用户输入命令交给 Shell 解释处理Shell 将相应的操作传递给内核(Kernel),内核把处理的结果输 ...
- 全国计算机等级考试二级笔试样卷Java语言程序设计
一.选择题((1)-(35)每小题2分,共70分) 下列各题A).B).C).D)四个选项中,只有一个选项是正确的,请将正确选项涂写在答题卡相应位置上,答在试卷上不得分. (1)下列选项中不符合良好程 ...
- 用JQuery解析获取JSON数据
JSON 是一种比较方便的数据形式,下面使用$.getJSON方法,实现获得JSON数据和解析,都挺方便简单的.从http://api.flickr.com/services/feeds/photos ...