Solr专题(一)手把手教你搭建Solr服务
一、Solr是什么,能解决什么问题?
Solr是一个高性能,采用Java开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
简而言之就是在项目中可以作为搜索引擎,提供资源的高效查询。
Q:数据库不是能提供查询的接口吗?为什么要用额外的框架来做?
A:因为模糊查询不能使用数据库的索引,所以数据库提供的模糊查询效率很低。而Solr本身也可以看做是数据库(no sql)类似于MongoDB存文档数据的菲关系型数据库。许多大型网站的搜索引擎绝不是通过查询数据库来做的,而是由Solr、Elasticsearch 这样的全文检索框架来负责。
二、同类型产品比较
全文检索框架还有ElasticSearch,它们两者之间的区别如下:
- Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
- Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;
- Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch。
- Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
三、搭建服务
本例中Solr版本为7.7.2
1.下载Solr
官方下载网站: https://lucene.apache.org/solr/downloads.html
2.版本变更记录
参考博文: https://blog.csdn.net/jiangchao858/article/details/52443745
说明:Solr从5.0.0开始内嵌jetty服务器,可直接启动,之前版本需依赖外部容器(tomcat、jetty...)中启动。
3.安装与启动
免安装,下载解压即用。
常用命令:
- 启动:solr start
- 停止:solr stop -p 8983
- 重启:solr restart
启动方式:找到bin目录,在地址栏输入cmd,打开命令界面
![]()
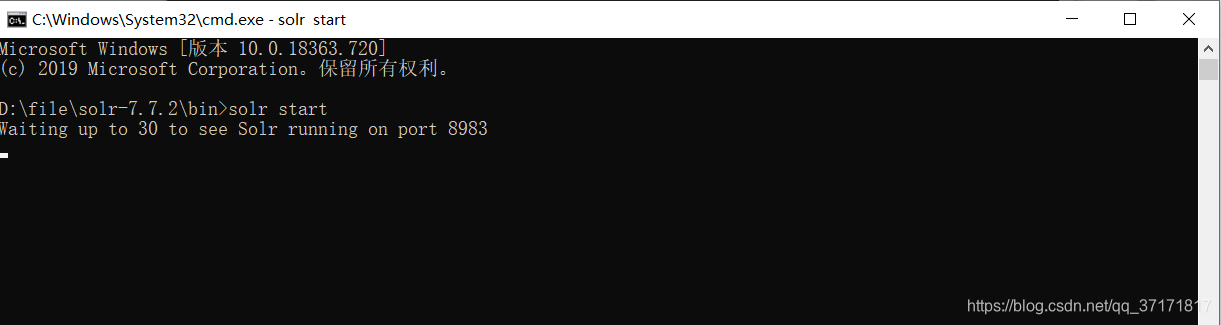
输入solr start,使用默认端口启用jetty服务。
![]()
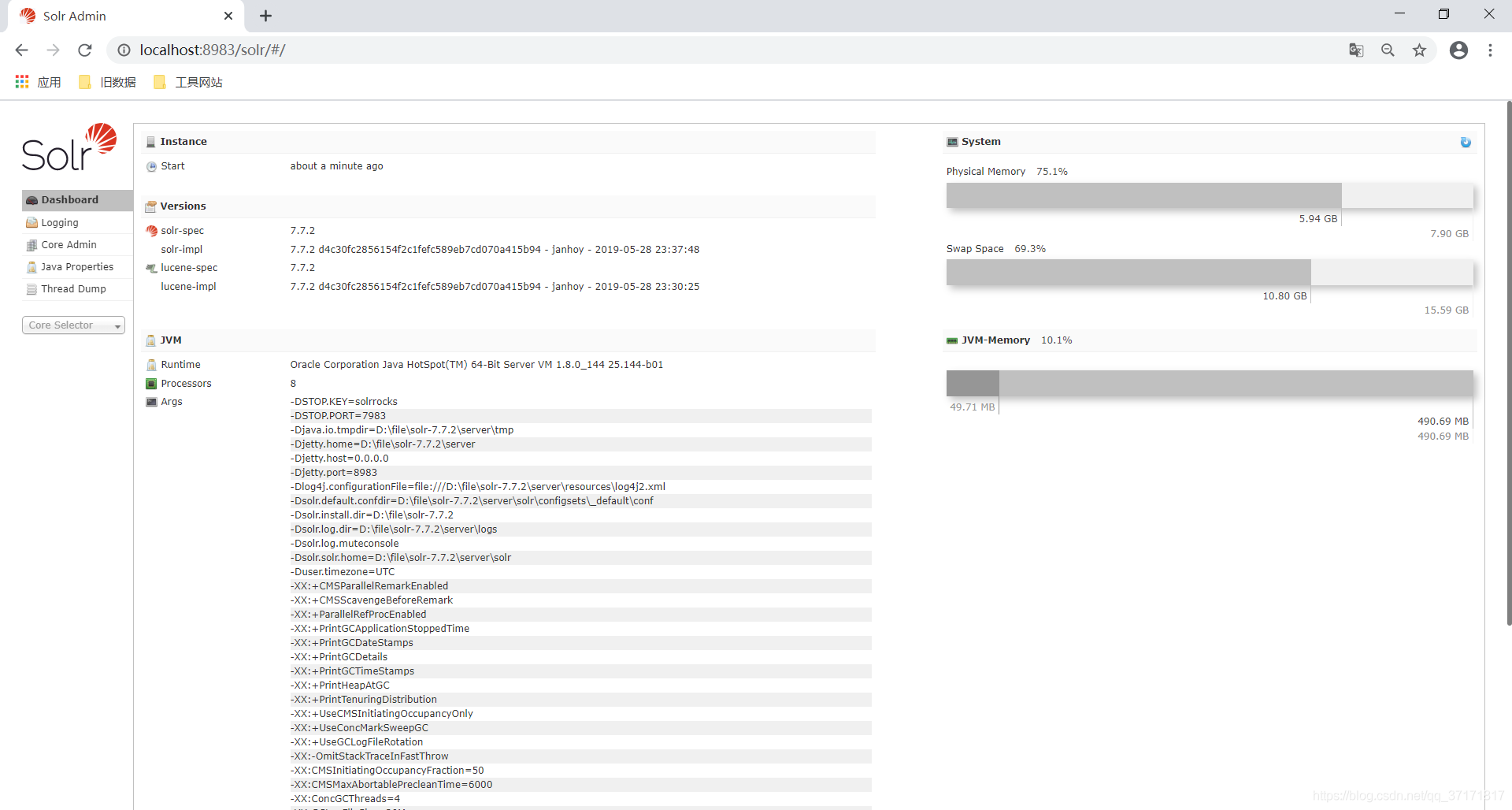
在浏览器输入localhost:8983/solr查看效果
![]()
4、建立core
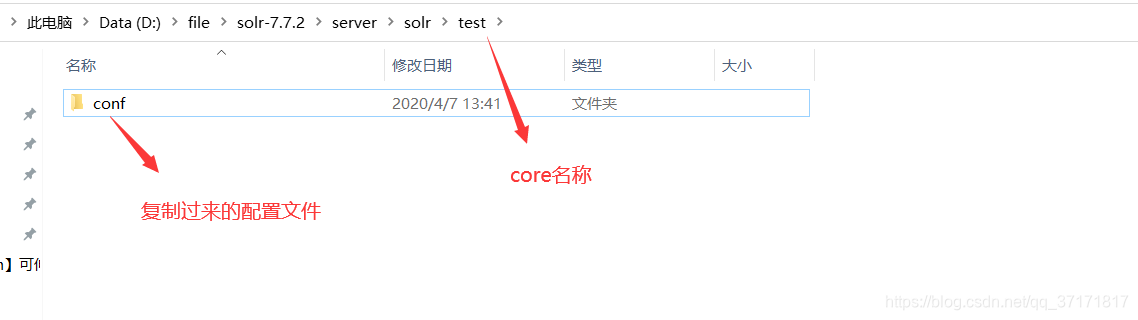
core就相当于数据库中的表,用来存放数据。
在/server/solr下新建一个文件夹,文件夹的名称就是core的名称,再将/server/solr/configsets/sample_techproducts_configs中的conf文件夹复制到新建的文件夹下。
![]()
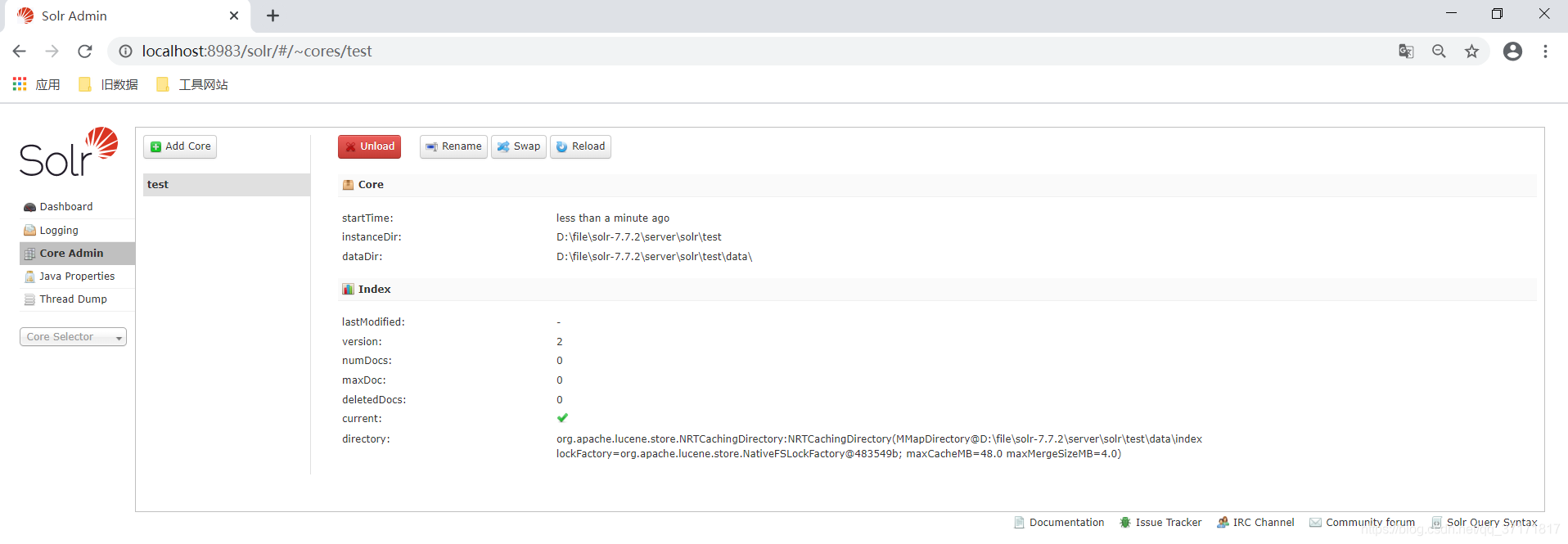
完成后重启solr服务,再进入solr的admin界面进行添加Core
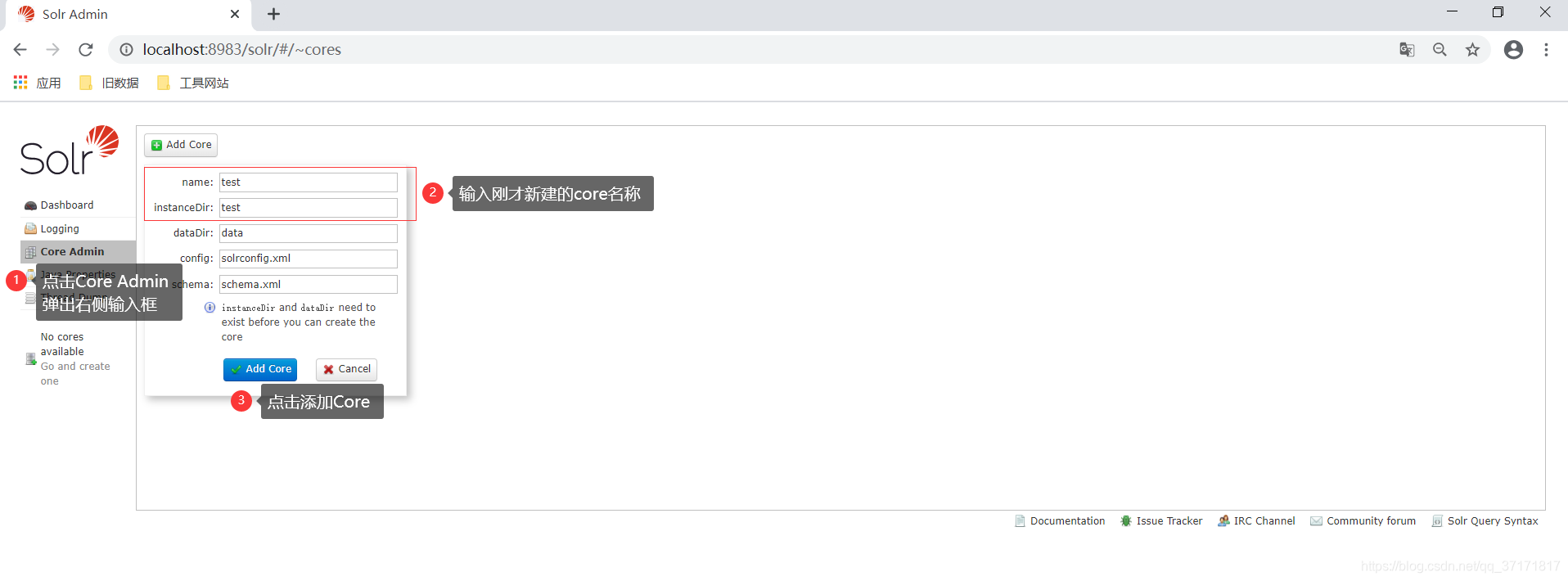
![]()
![]()
添加成功后,文件夹里会多出两个文件(data、core.properties)
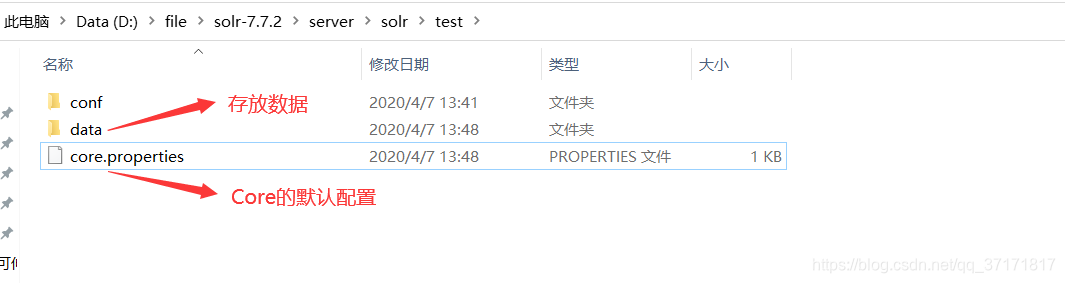
![]()
进入自己建立的core进行管理:
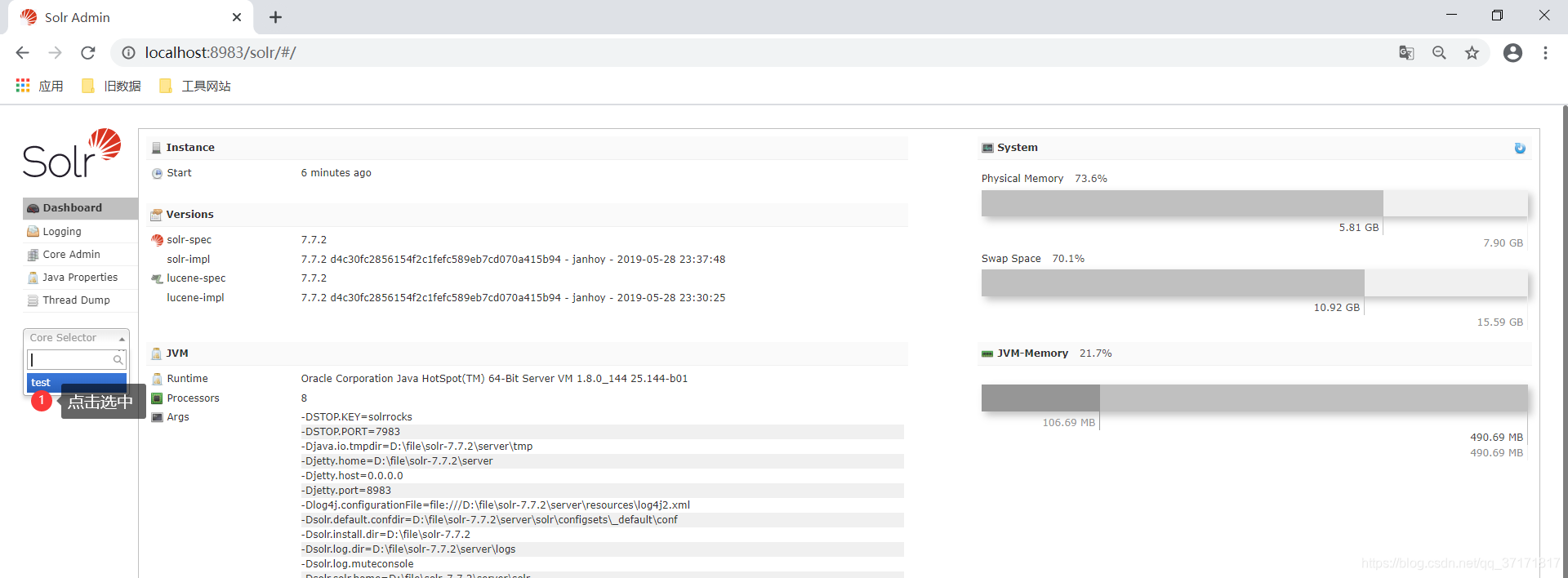
![]()
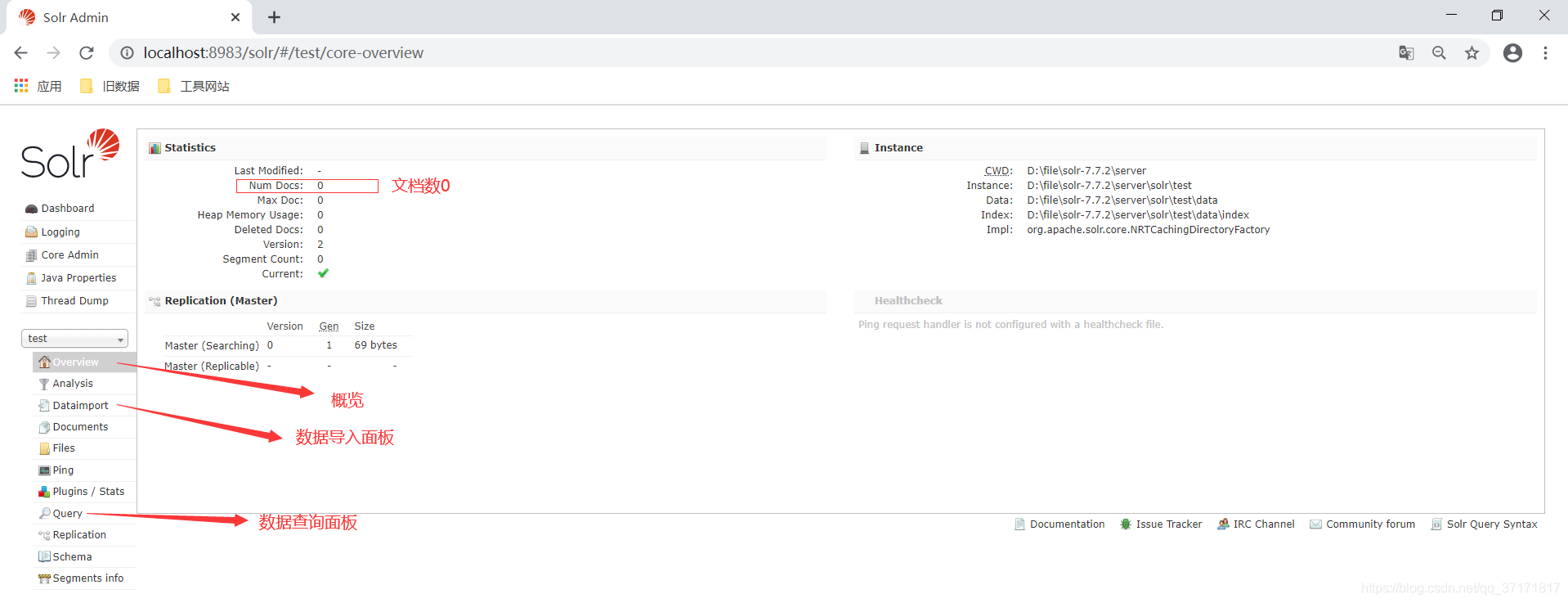
![]()
至此,Solr服务的搭建已经成功了,接下来是运用教程。
5、导入数据
是指将数据库里面的数据导入到Solr中。
首先导入需要的jar包,将dist下的两个jar包复制到/server/solr-webapp/webapp/WEB-INF/lib文件夹下
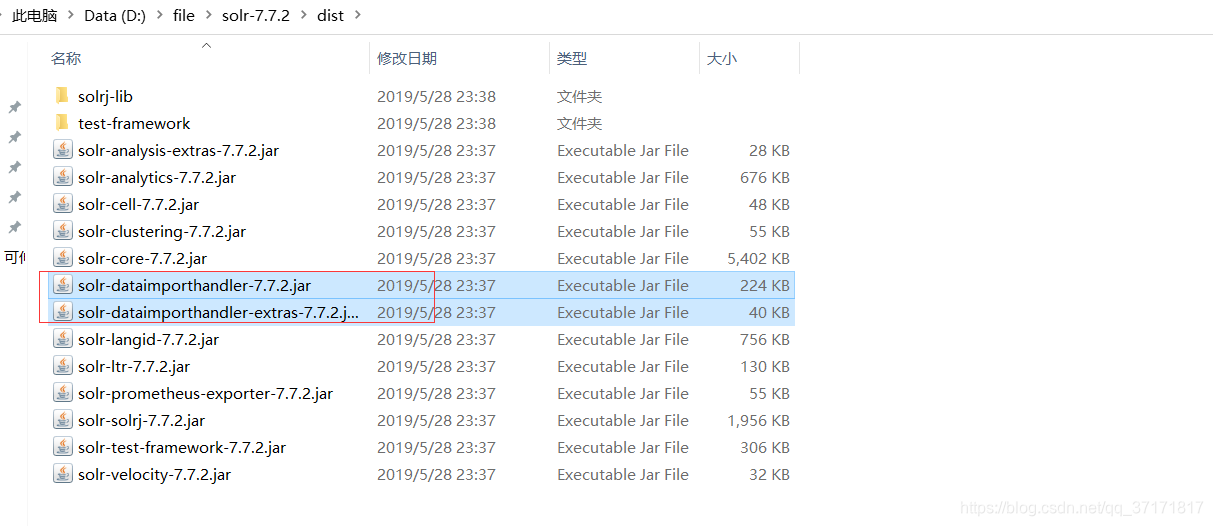
![]()
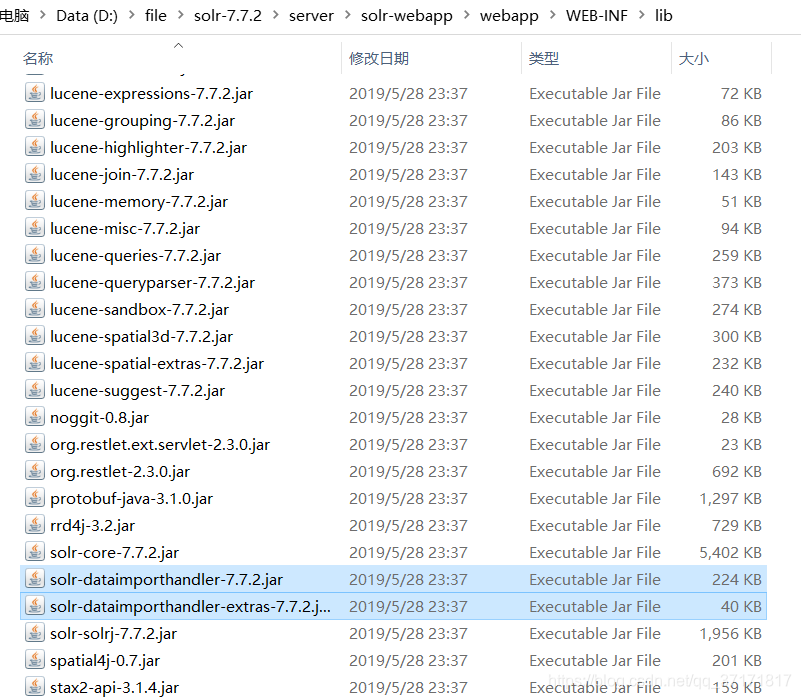
![]()
在你自己的core里的conf下新建一个data-config.xml的配置文件。
- <?xml version="1.0" encoding="UTF-8" ?>
- <dataConfig>
- <dataSource driver="com.mysql.jdbc.Driver" url="jdbc:mysql://127.0.0.1:3306/mydb?useUnicode=true&characterEncoding=utf-8" user="root" password="root"/>
- <document name="SysUser">
- <entity name="SysUser" pk="id"
- query='SELECT id,name,age FROM sys_suer'
- deltaImportQuery='SELECT id,name,age FROM sys_user WHERE id = "${dataimporter.delta.id}"'
- deltaQuery="SELECT id FROM sys_user where create_date > '${dataimporter.last_index_time}'" >
- <field column="id" name="id"/>
- <field column="name" name="name"/>
- <field column="age" name="age"/>
- </entity>
- </document>
- </dataConfig>
- dataSource表示连接数据库的配置
- document表示文档信息
- entity表示实体信息
- --query表示全量导入时调用的sql语句
- --deltaImportQuery表示增量导入时调用的sql语句
- --deltaQuery表示增量导入时查出来的数据
- --field表示字段
- --column表示数据库中字段名称
- --name表示存在solr的core中的名称
- ${dataimporter.last_index_time}表示最后一次导入数据的时间
具体流程:选择全量导入(全部数据导入)时调用query查询数据并导入到Solr中。选择增量导入时,先执行deltaQuery语句获得需要导入数据的id,再根据deltaImportQuery查出数据并导入到Solr中。
编辑你Core下的conf/managed-schema文件:
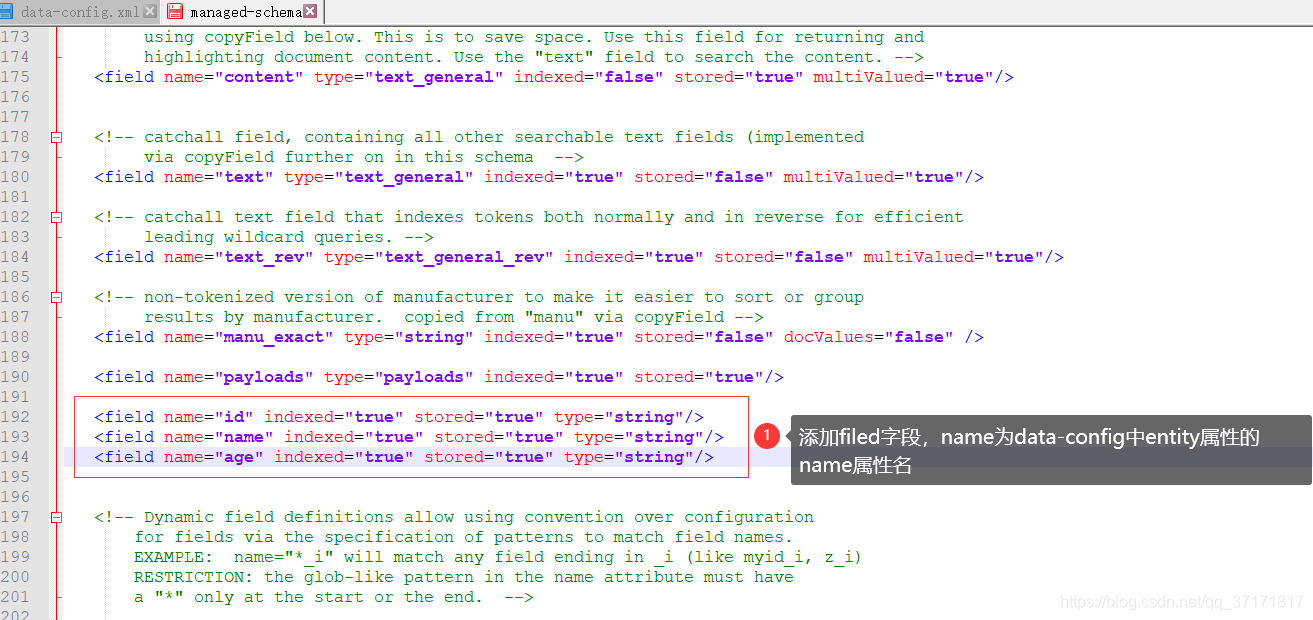
![]()
- indexed表示是否被索引,即是否被查询使用。
- stored表示是否存到Solr库。
- type表示搜索类型,当前为string类型的搜索,还可以自己配置,如IK中文分词器。
编辑core下conf/solrconfig.xml
新增以下内容
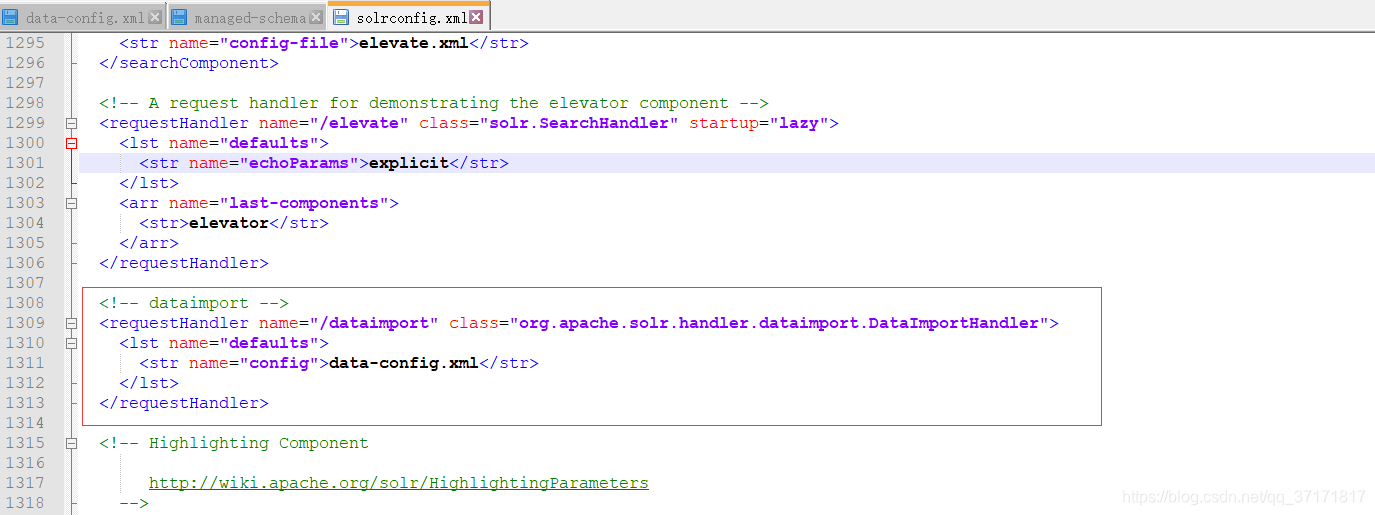
- <!-- dataimport -->
- <requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
- <lst name="defaults">
- <str name="config">data-config.xml</str>
- </lst>
- </requestHandler>
![]()
配好之后重启solr服务,并进入admin界面
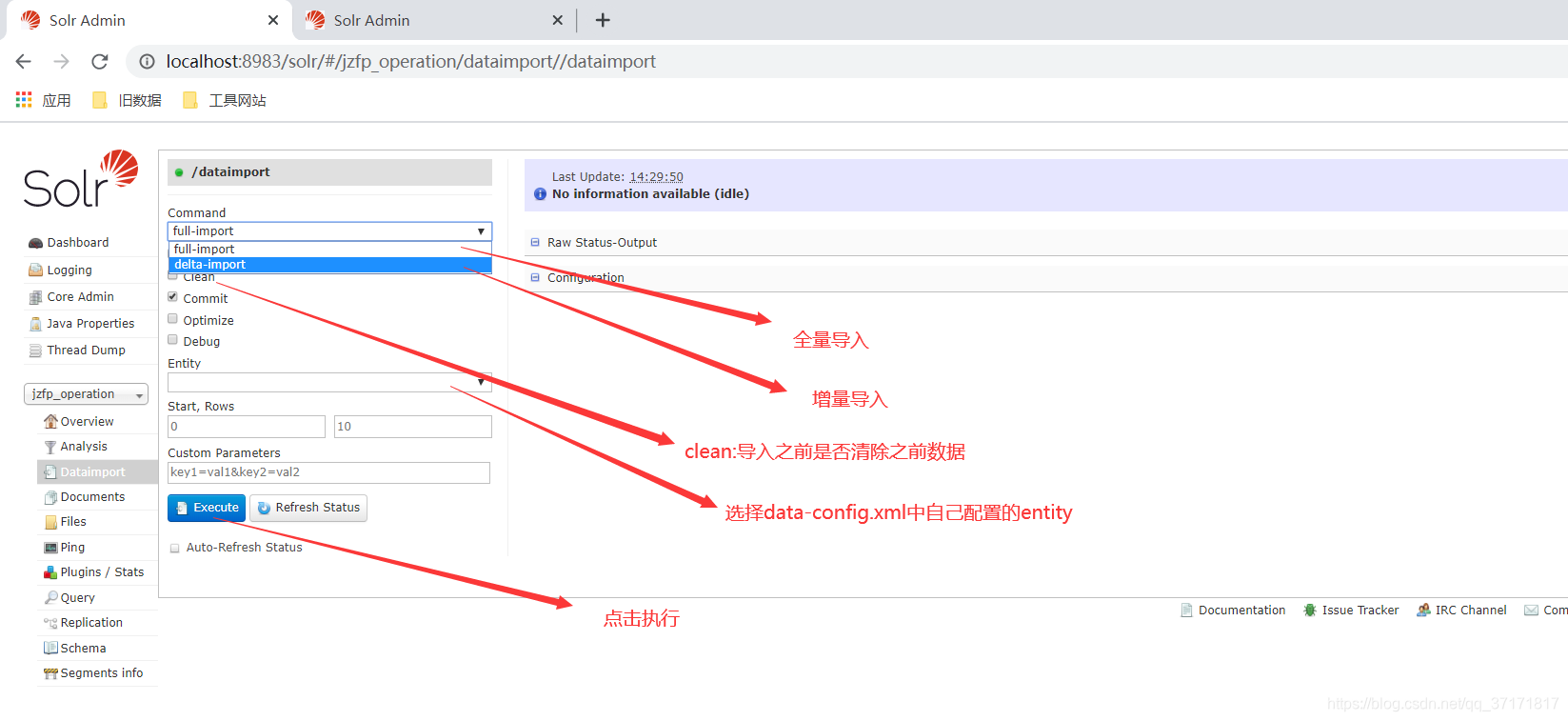
![]()
只有点击刷新状态按钮,才回刷新显示状态,出现Indexing completed则为导入完成。
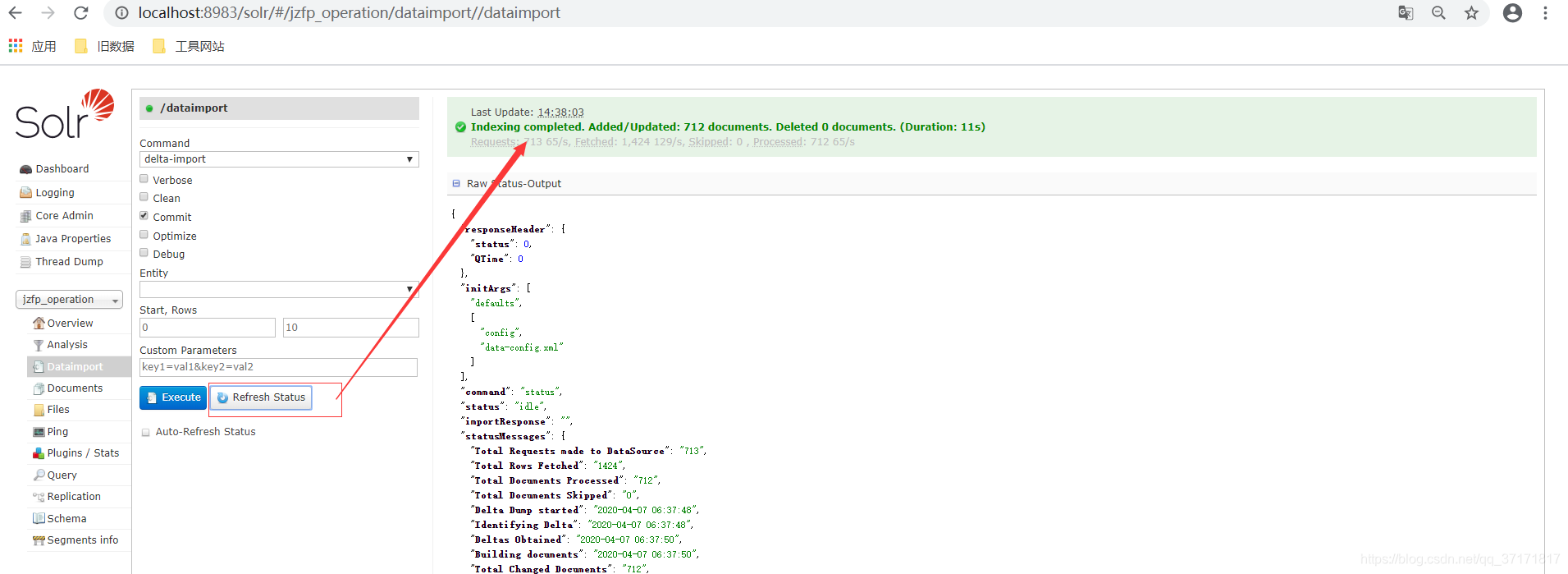
![]()
6、查询数据
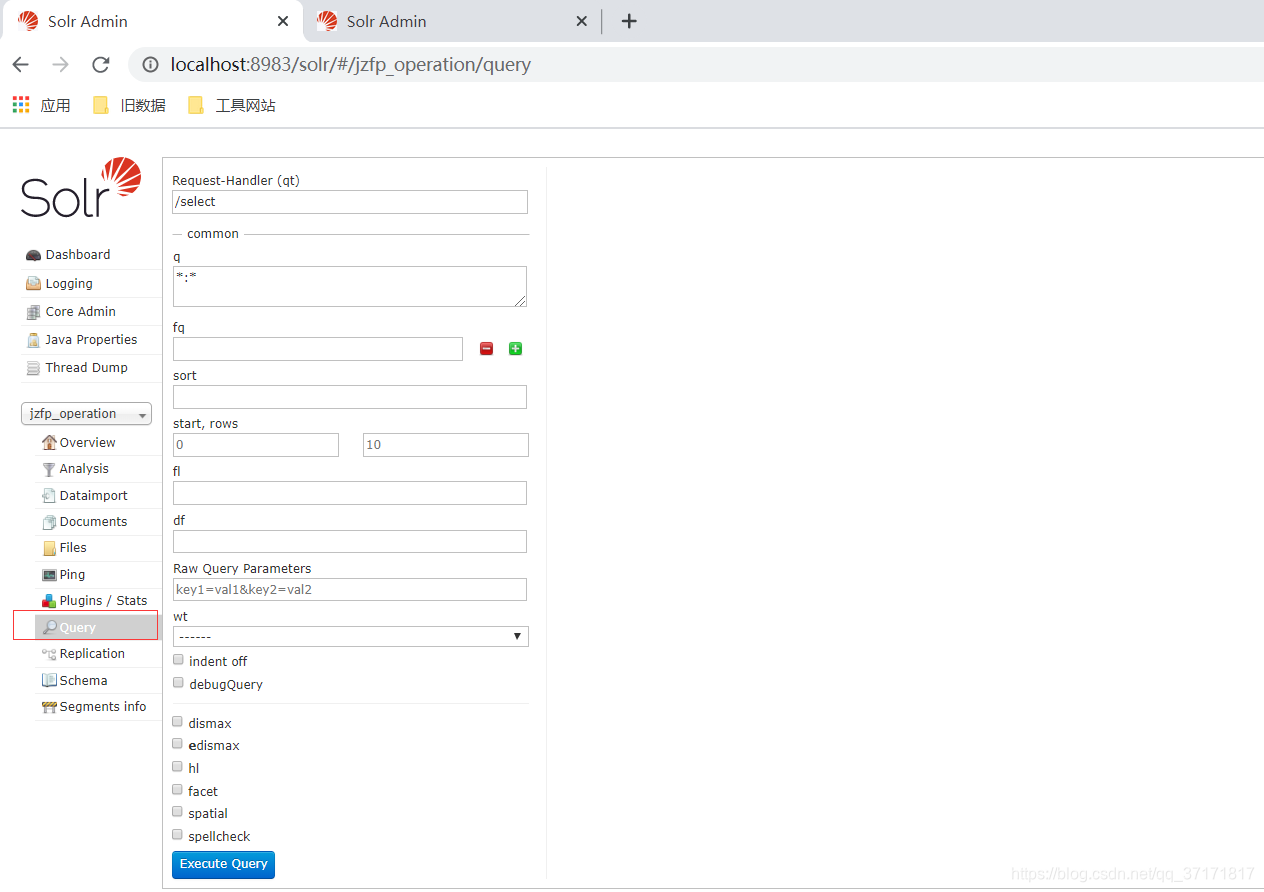
![]()
输入查询条件,点击执行查询,即可感受到全文检索的魅力。
下一节将会对Solr Query进行一个详细的讲解。
Solr专题(一)手把手教你搭建Solr服务的更多相关文章
- 手把手教你搭建SVN服务
参考一下地址 https://blog.csdn.net/marstonyjiang/article/details/52033916
- 大数据江湖之即席查询与分析(下篇)--手把手教你搭建即席查询与分析Demo
上篇小弟分享了几个“即席查询与分析”的典型案例,引起了不少共鸣,好多小伙伴迫不及待地追问我们:说好的“手把手教你搭建即席查询与分析Demo”啥时候能出?说到就得做到,差啥不能差人品,本篇只分享技术干货 ...
- 手把手教你搭建Pytest+Allure2.X环境详细教程,生成让你一见钟情的测试报告(非常详细,非常实用)
简介 宏哥之前在做接口自动化的时候,用的测试报告是HTMLTestRunner,虽说自定义模板后能满足基本诉求,但是仍显得不够档次,高端,大气,遂想用其他优秀的report框架替换之.一次偶然的机会, ...
- 手把手教你搭建FastDFS集群(下)
手把手教你搭建FastDFS集群(下) 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/u0 ...
- 手把手教你搭建FastDFS集群(中)
手把手教你搭建FastDFS集群(中) 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/u0 ...
- 手把手教你搭建FastDFS集群(上)
手把手教你搭建FastDFS集群(上) 本文链接:https://blog.csdn.net/u012453843/article/details/68957209 FastDFS是一个 ...
- 手把手教你搭建 ELK 实时日志分析平台
本篇文章主要是手把手教你搭建 ELK 实时日志分析平台,那么,ELK 到底是什么呢? ELK 是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch.Logstash 和 Kiban ...
- 手把手教你搭建SSH框架(Eclipse版)
原文来自公众号[C you again],若需下载完整源码,请在公众号后台回复"ssh". 本期文章详细讲解了SSH(Spring+SpringMVC+Hibernate)框架的搭 ...
- 庐山真面目之十一微服务架构手把手教你搭建基于Jenkins的企业级CI/CD环境
庐山真面目之十一微服务架构手把手教你搭建基于Jenkins的企业级CI/CD环境 一.介绍 说起微服务架构来,有一个环节是少不了的,那就是CI/CD持续集成的环境.当然,搭建CI/CD环境的工具很多, ...
随机推荐
- asp.netcore 3.1 program、Startup 类详解
Program类 public class Program { /// <summary> /// 应用程序入口 /// 1.asp.netcore 本质上是控制台程序 /// </ ...
- 阙乃祯:网龙在教育领域Cassandra的使用
网龙是一家游戏公司,以前是做网络在线游戏的,现在开始慢慢转型,开始从事在线教育. 在线教育已经做了5-6年时间了.为什么我们会用Cassandra呢?那我们就来介绍今天的议题. 首先介绍我们的业务背景 ...
- ESLint 使用简介
C 语言诞生之初,程序员编写的代码风格各异,在移植时会出现一些因为不严谨的代码段导致无法被编译器执行的问题.于是在 1979 年,一款叫 lint[1] 的程序被开发出来,能够通过扫描源代码检测潜在的 ...
- pytest封神之路第一步 tep介绍
『 tep is a testing tool to help you write pytest more easily. Try Easy Pytest! 』 tep前身 tep的前身是接口自动化测 ...
- Jmeter 常用函数(31)- 详解 __iterationNum
如果你想查看更多 Jmeter 常用函数可以在这篇文章找找哦 https://www.cnblogs.com/poloyy/p/13291704.html 作用 获取当前线程的循环次数,跟线程组属性挂 ...
- 【转】Ubuntu下解决Depends: xxx(< 1.2.1) but xxx is to be installed
在ubuntu下由于更新package不成功,或者误删除了一些文件会出现Depends: xxx(< 1.2.1) but xxx is to be installed解决方法是先试着安装所缺的 ...
- SpringBoot+MyBatis整合报错Property 'sqlSessionFactory' or 'sqlSessionTemplate' are required
项目启动的时候报这个错误,这个问题我百度了一天,果然不出意外的还是没能解决,其中有一篇文章相对来说还是有点用的:https://blog.csdn.net/qq8693/article/details ...
- dcoker 小应用(二)
sudo yum install epel-release vi /etc/yum.repos.d/epel.repo use base url instead of mirror url ...
- 鼠标移上显示的下拉菜单,和鼠标移上时显示的导航,html,JavaScript代码
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Java数据结构——顺序表
一个线性表是由n(n≥0)个数据元素所构成的有限序列. 线性表逻辑地表示为:(a0,a1,…,an-1).其中,n为线性表的长度,n=0时为空表.i为ai在线性表中的位序号. 存储结构:1.顺序存储, ...