Hbase原理(转学习自用)
一、系统架构
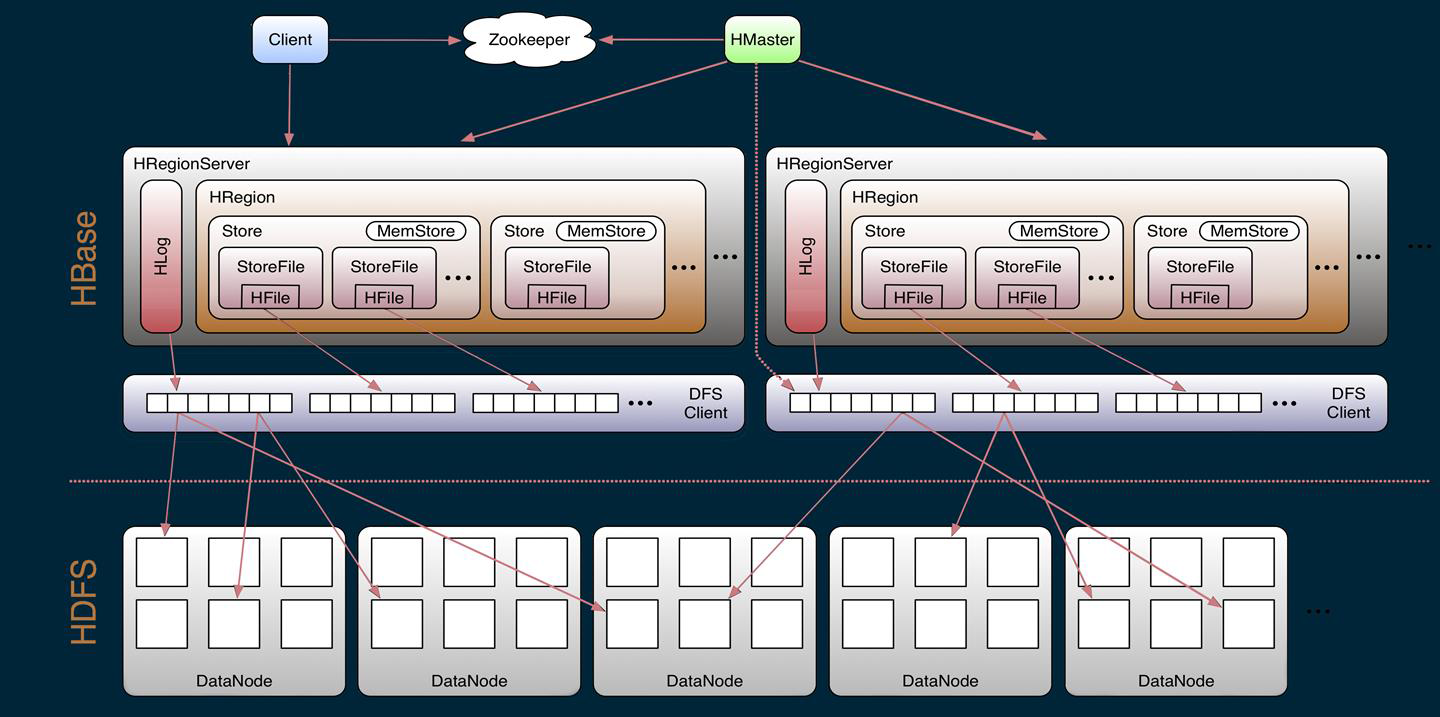
从HBase的架构图上可以看出,HBase中的组件包括Client、Zookeeper、HMaster、HRegionServer、HRegion、Store、MemStore、StoreFile、HFile、HLog等,接下来介绍他们的作用。
Client
1、Hbase有两张特殊表:
.META:记录了用户所有表拆分出来的Region映射信息,.META可以有多个Region
-ROOT-:记录了.META表的Region信息,-ROOT-只有一个Region,无论如何也不会分裂
2、Client访问永福数据前需要先访问Zookeeper,找到-ROOT-表的Region所在的位置,然后访问-ROOT-表,接着访问.META表,最后找到用户数据的位置去访问,中间需要多次网络操作,不过client端会做Cache缓存。
Zookeeper
1、zookeeper为Hbase提供Failover机制,选举Master,避免单点Master单点故障问题。
2、存储所有Region的寻址入口:-ROOT-表在哪台服务器上。-ROOT-这张表的位置信息
3、实时监控RegionServer的状态,将RegionServer的上线和下线信息实时通知给 Master。
4、存储 HBase 的 Schema,包括有哪些 Table,每个 Table 有哪些 Column Family
Master
1、为RegionServer分配Region
2、负责RegionServer的负载均衡
3、发现失效的RegionSerer并重新分配其上的Rgion
4、HDFS上的垃圾(Hbase)回收
5、处理Schema更新请求(表的创建,删除等)
注意:
从架构图可以看到,client访问Hbase上数据的过程并不需要master参与(寻址zookeeper和RegionServer数据读写访问RgionServer),Master 仅仅维护者 Table 和 Region 的元数据信息,负载很低。
.META. 存的是所有的 Region 的位置信息,那么 RegioneServer 当中 Region 在进行分裂之后 的新产生的 Region,是由 Master 来决定发到哪个 RegioneServer,这就意味着,只有 Master 知道 new Region 的位置信息,所以,由 Master 来管理.META.这个表当中的数据的 CRUD
所以结合以上两点表明,在没有 Region 分裂的情况,Master 宕机一段时间是可以忍受的。
RegionServer
1、RegionServer维护Master分配给它的Region,处理这些Region的I/O请求
2、RegionServer负责Slipt在运行过程中变得过大的Region,同时也负责Compact操作
HRegion
table在行的方向上分隔为多个Region,Region是Hbase中分布式存储和负载均衡的最小单元,即不同的Region可以分别在不同的RegionServer上,但同一个Region是不会拆分到多个Server上。
Region按大小分隔,每个表一般是只有一个Region,随着数据不断插入表,Region不断增大,当一个Region的某个列族达到一个阈值时就会分成两个新的Region.
Store
每一个Region由一个或多个Store组成,至少是一个store,Hbase会把一起访问的数据放在一个store里面,即为每个ColumnFamily建一个store,如果有几个ColumnFamily,也就有几个Store。一个Store由一个memStore和0或者 多个StoreFile组成。 HBase以store的大小来判断是否需要切分region
Memstore
memstore是放在内存里的。当memestore的大小达到一个阈值时(默认128M)时,memstore会被flush到文件,即生成一个快照。目前hbase会有一个线程来负责memstore的flush操作。
StoreFIle
memstore内存中的数据写到文件后就是StoreFile,StoreFile底层是以HFile的格式保存。StoreFile 以 HFile 格式保存在 HDFS 上
HFile
hbase中keyvalue数据的存储格式,HFile是Hadoop的二进制格式文件,实际上StoreFile就是对HFile做了一个轻量级包装,即StoreFile底层就是HFile
Hlog
Hlog(WAL LOG):WAL意为write ahead log,用来做灾难恢复使用,HLog记录数据的所有变更,一旦region server 宕机,就可以从log中进行恢复。
HLog文件就是一个普通的Hadoop Sequence File, Sequence File的value是key时HLogKey对象,其中记录了写入数据的归属信息,除了table和region名字外,还同时包括sequence number和timestamp,timestamp是写入时间,sequence number的起始值为0,或者是最近一次存入文件系统中的sequence number。 Sequence File的value是HBase的KeyValue对象,即对应HFile中的KeyValue。
二、物理存储
1、整体的物理结构
1、Table中的所有行都是按照Rowkey的字典序排序
2、Table在行的方向上分隔为多个Region
3、Hregion按大小分隔的(默认10G),每个表一开始只有一个Hregion,随着数据不断插入表,HReion不断增大,当增大到一个阈值的时候,HRegion就会等分为两个新的HReion.当表中的行不断增多,就会有越来越多的HRegion。
4、HRgion是Hbase中分布式存储和负载均衡的最小单元。最小单元就表示不同的HRgion可以分布在不同的HRegionServer上。但一个HRgion是不会拆分到多个Server上的。
5、HRreion虽然是负载均衡的最小单元,但并不是物理存储的最小单元。事实上,HRegion 由一个或者多个 Store 组成,每个 Store 保存一个 Column Family。每个 Strore 又由一个 memStore 和 0 至多个 StoreFile 组成
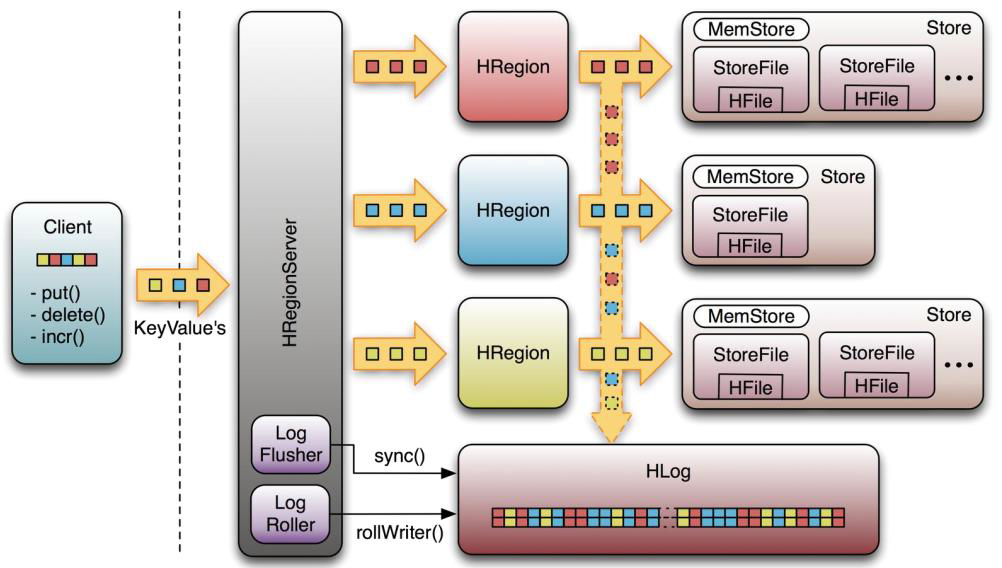
MemStore 和 StoreFile
一个HRegion由多个Store组成,每个Store包含一个列族的所有数据。
Store包括位于内存的一个memstore和位于硬盘的多个Storefile组成。
写操作先写入memstore,当memstore中的数据量达到某个阈值,HregionServer启动flushCache进程写入Storefile,每次写入形成单独一个Hfile
当总storefile大小超过一定阈值后,会把当前的region分割成两个,并由HMaster分配给相应的region服务器,实现负载均衡。
客户端检索数据时,现在memstore找,找不到再去storefile找。
三、RegionServer工作机制
1、Region分配
任何时刻,一个Region只能分配给一个 RegionServer。master记录了当前有哪些可用的RegionServer。以及当前哪些 Region 分配给了哪些 RegionServer,哪些 Region 还没有分配。 当需要分配的新的 Region,并且有一个 RegionServer 上有可用空间时,Master 就给这个 RegionServer 发送一个装载请求,把 Region 分配给这个 RegionServer。RegionServer 得到请 求后,就开始对此 Region 提供服务。
2、RegionServer上线
Master使用zookeeper来跟踪RegionServer状态。当某个RegionServer启动时,会首先在Zookeeper上的server目录下建立代表自己的znode,由于Master订阅了server目录上的变更消息,当server目录下的文件出现新增或删除操作时,Master可以得到来自Zookeeper的实时通知。因此一旦RegionServer上线,Master能马上得到消息。
3、RegionServer 下线
当 RegionServer 下线时,它和 zookeeper 的会话断开,ZooKeeper 而自动释放代表这台 server 的文件上的独占锁。Master 就可以确定:
1、RegionServer 和 ZooKeeper 之间的网络断开了。
2、RegionServer 挂了。
无论哪种情况,RegionServer都无法继续为它的Region提供服务了,此时Master会删除server 目录下代表这台 RegionServer 的 znode 数据,并将这台 RegionServer 的 Region 分配给其它还 活着的同志。
四、Matser工作机制
1、Master上线
Master上线启动步骤:
1、从Zookeeper上获取一个代表Active Master的锁,用来阻止其他的Matser成为Active Master。
2、扫描Zookeeper上的server父节点,获得当前可用的RegionServer列表。
3、和每个RegionServer通信,获得当前已分配的 Region 和 RegionServer 的对应关系
4、扫描.META. Region 的集合,计算得到当前还未分配的 Region,将他们放入待分配 Region 列表
2、Master下线
由于Master只维护表和Region的元数据,而不参与表数据I/O的过程,Master下线仅导致元数据的修改被冻结(无法删除表,无法修改表的schema,无法进行Region的负载均衡,无法处理Region上下线,无法进行Region合并,唯一例外的是Region的split可以正常进行,因为只有RegionServer参与),表的数据读写还可以正常进行,因此Master下线短时间内对整个 hbase 集群没有影响
Hbase原理(转学习自用)的更多相关文章
- 大数据技术之_11_HBase学习_01_HBase 简介+HBase 安装+HBase Shell 操作+HBase 数据结构+HBase 原理
第1章 HBase 简介1.1 什么是 HBase1.2 HBase 特点1.3 HBase 架构1.3 HBase 中的角色1.3.1 HMaster1.3.2 RegionServer1.3.3 ...
- HBase笔记:对HBase原理的简单理解
早些时候学习hadoop的技术,我一直对里面两项技术倍感困惑,一个是zookeeper,一个就是Hbase了.现在有机会专职做大数据相关的项目,终于看到了HBase实战的项目,也因此有机会搞懂Hbas ...
- 你想要的 HBase 原理都在这了
目录 一. 集群架构 集群角色 工作机制 二.存储机制 A. 存储模型 B. LSM 与 Compaction C. Region 分裂 D. 自动均衡 三.访问机制 四. 鉴权 五. 高可靠 1.集 ...
- Hbase原理
Hbase原理 概述 HBase是一个构建在HDFS上的分布式列存储系统:HBase是基于Google BigTable模型开发的,典型的key/value系统:HBase是Apache Hadoop ...
- HBase原理、设计与优化实践
转自:http://www.open-open.com/lib/view/open1449891885004.html 1.HBase 简介 HBase —— Hadoop Database的简称,G ...
- HBase全网最佳学习资料汇总
HBase全网最佳学习资料汇总 摘要: HBase这几年在国内使用的越来越广泛,在一定规模的企业中几乎是必备存储引擎,互联网企业阿里巴巴.百度.腾讯.京东.小米都有数千台的HBase集群,中国电信的话 ...
- Hbase技术详细学习笔记
注:转自 Hbase技术详细学习笔记 最近在逐步跟进Hbase的相关工作,由于之前对Hbase并不怎么了解,因此系统地学习了下Hbase,为了加深对Hbase的理解,对相关知识点做了笔记,并在组内进行 ...
- Jquery 实现原理深入学习(3)
前言 1.总体结构 √ 2.构建函数 √ 3.each功能函数实现 √ 4.map功能函数实现 √ 5.sizzle初步学习 6.attr功能函数实现 7.toggleClass功能函数实现(好伤) ...
- 1、Hbase原理分析
一.Hbase介绍 1.1.对Hbase的认识 HBase作为面向列的数据库运行在HDFS之上,HDFS缺乏随机读写操作,HBase正是为此而出现. HBase参考 Google 的 Bigtable ...
- HBase原理 – 分布式系统中snapshot是怎么玩的?(转载)
snapshot(快照)基础原理 snapshot是很多存储系统和数据库系统都支持的功能.一个snapshot是一个全部文件系统.或者某个目录在某一时刻的镜像.实现数据文件镜像最简单粗暴的方式是加锁拷 ...
随机推荐
- PHP代码审计分段讲解(1)
PHP源码来自:https://github.com/bowu678/php_bugs 快乐的暑期学习生活+1 01 extract变量覆盖 <?php $flag='xxx'; extract ...
- 从零开始的sql注入学习(挖坑不填)
首先,本人是小白,这篇文章也只是总结了一下大佬们的sql注入方法,要是有错,请各位大佬指出,以便学习. 虽然我是菜鸡,但是太过基础的sql注入问题也就不再重复的解释了.直接从常用的说起. 实战中常用的 ...
- html5shiv.js和respond.min.js作用说明(IE9及以下兼容)
一.在web端页面开发过程中基本都会需要解决的问题(IE兼容): 1.解决ie9以下浏览器对html5新增标签的不识别,并导致CSS不起作用的问题. 2.让不支持css3 Media Query的浏览 ...
- Nginx的安装及相关配置
Nginx的安装及相关配置 Nginx 是 C语言 开发,建议在 Linux 上运行,当然,也可以安装 Windows 版本,本篇则使用 CentOS 7 作为安装环境. 一. gcc 安装 安装 n ...
- JavaSE07-字符串常用API
1.String 1.1 String类概述 String 类代表字符串,Java 程序中的所有字符串文字(例如"abc")都被实现为此类的实例.也就是说,Java 程序 中所有的 ...
- kafka监控之topic的lag情况监控
需求描述:lag(滞后)是kafka消费队列性能监控的重要指标,lag的值越大,表示kafka的堆积越严重.本篇文章将使用python脚本+influxdb+grafana的方式对kafka的offs ...
- css 03-CSS样式表和选择器
03-CSS样式表和选择器 #本文主要内容 CSS概述 CSS和HTML结合的三种方式:行内样式表.内嵌样式表.外部样式表 CSS四种基本选择器:标签选择器.类选择器.ID选择器.通用选择器 CSS几 ...
- [BUUOJ]刮开有奖reverse
刮开有奖 这是一个赌博程序,快去赚钱吧!!!!!!!!!!!!!!!!!!!!!!!!!!!(在编辑框中的输入值,即为flag,提交即可) 注意:得到的 flag 请包上 flag{} 提交 1.查壳 ...
- mysqldump 导出命令
在命令行下mysql的数据导出有个很好用命令mysqldump,它的参数有一大把,可以这样查看: mysqldump 最常用的: mysqldump -uroot -pmysql databasefo ...
- 图数据库 Nebula Graph 在 Boss 直聘的应用
本文首发于 Nebula Graph 官方博客:https://nebula-graph.com.cn/posts/nebula-graph-risk-control-boss-zhipin/ 摘要: ...