MySQL 中的自增主键
MySQL 的主键可以是自增的,那么如果在断电重启后新增的值还会延续断电前的自增值吗?自增值默认为1,那么可不可以改变呢?下面就说一下 MySQL 的自增值。
特点
保存策略
1、如果存储引擎是 MyISAM,那么这个自增值是存储在数据文件中的;
2、如果是 InnoDB 引擎,1)在 5.6 之前是存储在内存中,没有持久化,在重启后会去找最大的键值,举个例子,如果一个表当前数据行里最大 id是10,AUTO_INCREMENT=11。这时候,我们删除 id=10 的行,AUTO_INCREMENT 还是 11。但如果马上重启实例,重启后这个表的 AUTO_INCREMENT 就会变成 10;
2)在 8.0 开始,自增值就保存在 redo log 中,重启后会从 redo log 中读取之前保存的自增值。
自增值的确定
1、如果插入数据时 id 字段指定为0、null 或未指定,那么就把这个表当前的 AUTO_INCREMENT 值填到自增字段,并且会以 auto_increment_offset 作为初始值,auto_increment_increment 为步长,找出第一个大于当前自增值的值作为新的自增值。
2、如果插入的数据的 id 字段指定了具体的值,就直接使用语句里的值。
自增值的修改
假设某次要输入的值是 X,当前的自增值是 Y。那么:
1、如果 X<Y,那么这个表的自增值不变;
2、如果 X≥Y,那么就把当前自增值修改为新的自增值。
执行过程
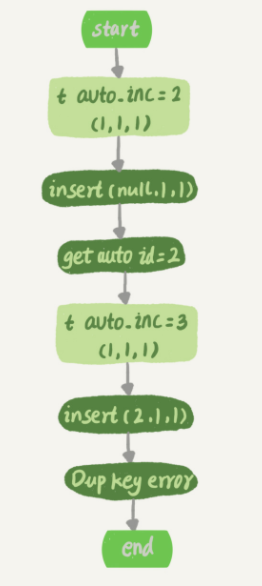
假设有表 t ,id 是自增主键,在已有 (1,1,1)的情况下,插入一条 (null,1,1),那么执行过程就如下:
1、执行器调用 InnoDB 引擎接口写入一行,传入的这一行的值是 (0,1,1);
2、InnoDB 发现用户没有指定自增 id 的值,获取表 t 当前的自增值 2;
3、将传入的行的值改成 (2,1,1);
4、将表的自增值改成 3;
5、继续执行插入数据操作,由于已经存在 c=1 的记录,所以报 Duplicate key error,语句返回。
带来的问题
由于上面说得这种特性,在一些场景中会出现主键不连续的现象。
场景1:添加数据时唯一索引重复
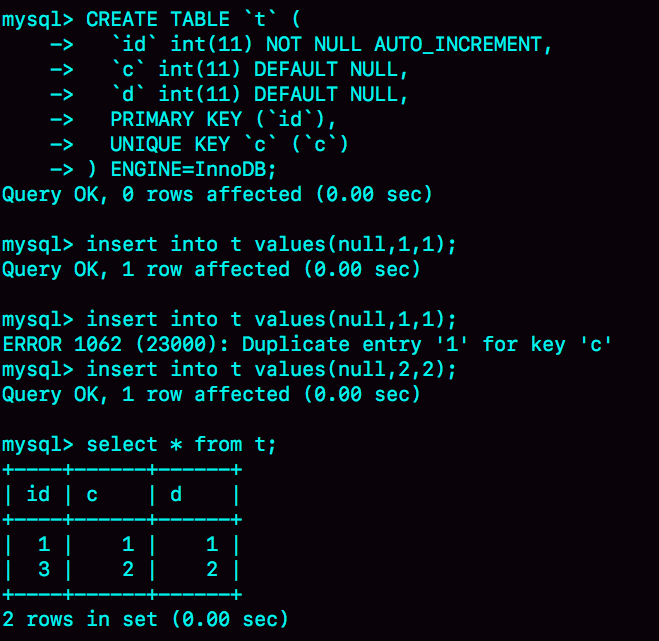
在 c 列索引重复后,原本要分配的主键值 2 就会被丢弃,而下次再次插入就从 2 开始计算,也就变成了 3。
场景2:事务回滚
insert into t values(null,1,1);
begin;
insert into t values(null,2,2);
rollback;
insert into t values(null,2,2);
//插入的行是(3,2,2)
在第二条语句回滚后分配给其的主键 2 也会被丢弃。
场景3:特殊批插入优化导致
这里说得特殊的批插入指的是 insert … select、replace … select 和 load data 语句。为什么说这些语句可能会导致?这就要说到自增锁了。首先自增锁是为了避免多线程冲突,因为在多线程下,如果同时有多个线程来获取自增值,那么就可能会导致同一个自增值被分配给多条记录,导致逐渐冲突。所以需要自增锁,而为什么前面说得这些批插入语句会导致主键不连续,在下面自增锁部分会说到。
问题:在说自增锁之前,先思考一个问题,为什么对于前两个场景,不把自增主键值设为可以回滚的?这样不就可以避免不连续了么?
答:因为设计成可回滚的会导致性能下降,看下面这个场景。
1、假设事务 A 申请到了 id=2, 事务 B 申请到 id=3,那么这时候表 t 的自增值是 4,之后继续执行。
2、事务 B 正确提交了,但事务 A 出现了唯一键冲突。
3、如果允许事务 A 把自增 id 回退,也就是把表 t 的当前自增值改回 2,那么就会出现这样的情况:表里面已经有 id=3 的行,而当前的自增 id 值是 2。
4、接下来,继续执行的其他事务就会申请到 id=2,然后再申请到 id=3。这时,就会出现插入语句报错“主键冲突”。
而为了解决上面这个问题,就需要从下面两个方法中选一个。
方法一、每次申请 id 之前,先判断表里面是否已经存在这个 id。如果存在,就跳过这个 id。但是,这个方法的成本很高。因为,本来申请 id 是一个很快的操作,现在还要再去主键索引树上判断 id 是否存在。
方法二:把自增 id 的锁范围扩大,必须等到一个事务执行完成并提交,下一个事务才能再申请自增 id。这个方法的问题,就是锁的粒度太大,系统并发能力大大下降。
所以,综合来看,比如取消自增值回滚的功能。
自增锁
自增锁是为了避免在多线程中多个线程获取到同一个主键值,导致主键冲突。
加锁策略
5.0 版本:范围是语句,只有等到语句执行完后才会释放。
5.1.22开始:引入了一个 innodb_autoinc_lock_mode 参数,根据参数值的不同执行不同的策略。默认是1。
1、参数等于0,表示采用之前的策略,即语句执行结束就会释放。
2、参数等于1,对于普通 insert 语句,自增锁在申请之后立马释放;
对于 insert...select 这样的批量插入数据的语句,会等到语句执行完才会释放。加锁范围是 select 所涉及到的范围和间隙。
3、参数等于3,所有的申请自增主键的动作都是申请后就释放锁。
问题:为什么默认情况下, insert...select 这样的批操作要使用语句级的锁?为什么参数默认不是2?
答:因为对于 insert...select 这样的批量插入数据的语句,可能会导致主从不一致的情况发生。

在 sessionB 执行完 "create table t2 like t" 后,sessionA 和 sessionB 同时操作 t2。如果没有锁,那么执行过程就可能会出现下面的情况。
session B 先插入了两个记录,(1,1,1)、(2,2,2);然后,session A 来申请自增 id 得到 id=3,插入了(3,5,5);之后,session B 继续执行,插入两条记录 (4,3,3)、 (5,4,4)。
虽然这样看起来确实没有什么问题,但是如果是在集群中,主机这样执行,提示 binlog 是 statement 格式的,那么从机执行的顺序就有可能和主机不一致,最终导致主从不一致。所以需要在批量插入时加锁。而如果设置为2,那么如果 binlog 不是 row,就会导致主从数据不一致。
所以,要想保证数据一致,也保证系统的并发性,可以有两种方案:
方案一:将 binlog 格式设为 statement,innodb_autoinc_lock_mode 设为1。
方案二:将 binlog 格式设为 row,innodb_autoinc_lock_mode 设为2。一般我们为了保证 MySQL 的高可用,都将 binlog 设为 row,所以一般选择第二种方案。
批插入的优化
在批插入时,由于不知道一次性插入的语句有多少,如果记录多达几千万甚至上亿条,那么每次插入都需要分配一次自增值,这样效率会很慢,所以 MySQL 对批操作进行了优化:
1、语句执行过程中,第一次申请自增 id,会分配 1 个;
2、1 个用完以后,这个语句第二次申请自增 id,会分配 2 个;
3、2 个用完以后,还是这个语句,第三次申请自增 id,会分配 4 个;
4、依此类推,同一个语句去申请自增 id,每次申请到的自增 id 个数都是上一次的两倍。
举个例子,执行下面的代码
insert into t values(null, 1,1);
insert into t values(null, 2,2);
insert into t values(null, 3,3);
insert into t values(null, 4,4);
create table t2 like t;
insert into t2(c,d) select c,d from t;
insert into t2 values(null, 5,5);
insert…select,实际上往表 t2 中插入了 4 行数据。但是,这四行数据是分三次申请的自增 id,第一次申请到了 id=1,第二次被分配了 id=2 和 id=3, 第三次被分配到 id=4 到 id=7。由于这条语句实际只用上了 4 个 id,所以 id=5 到 id=7 就被浪费掉了。之后,再执行 insert into t2 values(null, 5,5),实际上插入的数据就是(8,5,5)。这就是前面说到主键不连续的第三种情况。
insert...select 前后操作同一个表会用到临时表
假设有表结构
CREATE TABLE `t` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `c` (`c`)
) ENGINE=InnoDB; insert into t values(null, 1,1);
insert into t values(null, 2,2);
insert into t values(null, 3,3);
insert into t values(null, 4,4); create table t2 like t
如果执行的语句是:
insert into t2(c,d) (select c+1, d from t force index(c) order by c desc limit 1);
如果我们查询慢日志,会发现

扫描行数是1,也就是直接在 t 上通过索引找到那一条记录,然后插入 t2 表。
如果将这条语句改成
insert into t(c,d) (select c+1, d from t force index(c) order by c desc limit 1);
那么此时查看慢日志就会发现变成了 5,这是为什么?就算全查出来也只会是4条,这时我们查看扫描行数的变化
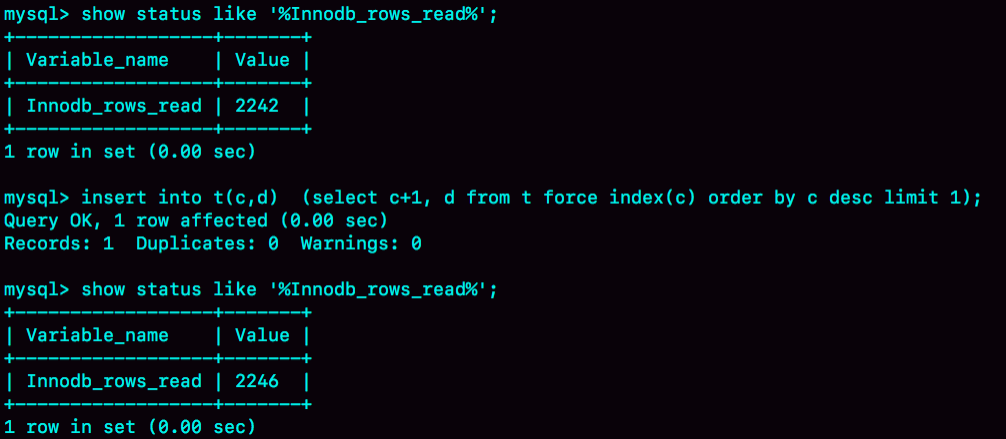
发现前后变化是4行,所以确定了是使用了临时表,那么就可以确定过程是:
1、创建临时表,表里有两个字段 c 和 d。
2、按照索引 c 扫描表 t,依次取 c=4、3、2、1,然后回表,读到 c 和 d 的值写入临时表。这时,Rows_examined=4。
3、由于语义里面有 limit 1,所以只取了临时表的第一行,再插入到表 t 中。这时,Rows_examined 的值加 1,变成了 5。
至于为什么需要临时表,这是为了防止在读取时,读到了刚刚插入的值。
优化
因为select 返回的记录数较少,所以可以使用内存临时表来优化,
create temporary table temp_t(c int,d int) engine=memory;
insert into temp_t (select c+1, d from t force index(c) order by c desc limit 1);
insert into t select * from temp_t;
drop table temp_t;
这样扫描的总行数只有 select 的 1 加上临时表上的 1。
最后
对于唯一索引的冲突,可以使用 insert into … on duplicate key update 来进行冲突后的更新处理,假设表 t 中有(1,1,1)、(2,2,2) 两条记录,那么执行:
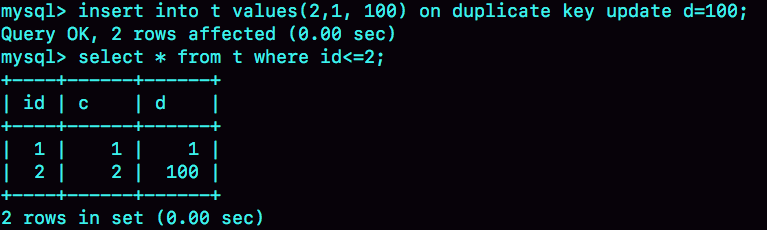
在插入时发现冲突就对冲突的记录进行修改操作。
MySQL 中的自增主键的更多相关文章
- java面试一日一题:mysql中的自增主键
问题:请讲下mysql中的自增主键 分析:该问题主要考察对mysql中自增主键的掌握,使用场景及如何设置 回答要点: 主要从以下几点去考虑 1.什么自增主键 2.使用场景是什么: 3.innodb_a ...
- MySQL 插入与自增主键值相等的字段 与 高并发下保证数据准确的实验
场景描述: 表t2 中 有 自增主键 id 和 字段v 当插入记录的时候 要求 v与id 的值相等(按理来说这样的字段是需要拆表的,但是业务场景是 只有某些行相等 ) 在网上搜的一种办法是 先获取 ...
- mybatis+sqlserver中返回非自增主键
首先把实体类贴出来(这里只贴出属性,其它的就是getter和setter方法): public class Around { private String xccd; //对应主键 ...
- mycat分布式mysql中间件(自增主键)
一.全局序列号 全局序列号是MyCAT提供的一个新功能,为了实现分库分表情况下,表的主键是全局唯一,而默认的MySQL的自增长主键无法满足这个要求.全局序列号的语法符合标准SQL规范,其格式为:nex ...
- mysql的innodb自增主键为什么不是连续的
图1 图1中是表t原有的数据,这个时候我们执行show create table t会看到如下输出,如图二所示现在的自增值是2,也就是下一个不指定主键值的插入的数据的主键就是2 图2 Innodb引擎 ...
- 面试|简单描述MySQL中,索引,主键,唯一索引,联合索引 的区别,对数据库的性能有什么影响(从读写两方面)
索引是一种特殊的文件(InnoDB 数据表上的索引是表空间的一个组成部分),它们 包含着对数据表里所有记录的引用指针. 普通索引(由关键字 KEY 或 INDEX 定义的索引)的唯一任务是加快对数据的 ...
- 简单描述 MySQL 中,索引,主键,唯一索引,联合索引 的区别,对数据库的性能有什么影响(从读写两方面) ?
索引是一种特殊的文件(InnoDB 数据表上的索引是表空间的一个组成部分),它们 包含着对数据表里所有记录的引用指针. 普通索引(由关键字 KEY 或 INDEX 定义的索引)的唯一任务是加快对数据的 ...
- MySQL中的完整性约束条件(主键、外键、唯一、非空)
数据库的完整性约束用来防止对数据的意外破坏,来保证数据的安全性和一致性. 主键 1.创建表时候指定主键 创建表user(id, username, age),并且id字段非空自增. CREATE TA ...
- sqlite中的自增主键
http://stackoverflow.com/questions/8519936/sqlite-autoincrement-primary-key-questions I'm not sure w ...
随机推荐
- PHPExcel-Helper快速构建Excel
项目介绍 PHPExcel-Helper是什么? PHPExcel辅助开发类,帮助开发者快速创建各类excel. github PHPExcel-Helper存在的意义? 官方phpexcel库功能全 ...
- 【Spring】Spring IOC
Spring IOC IOC 的常用注解 小节源码 之前的 XML 配置: <bean id="accountService" class="cn.parzulpa ...
- readhat6.5下安装weblogic10.3.6
转载自:http://www.mianhuage.com/752.html 1.安装前准备 1.1.准备安装包generic.jar1.2.创建weblogic用户及用户组创建组命令:groupadd ...
- kubernets之Deployment资源
一 声明式的升级应用 1.1 回顾一下kubernets集群里面部署一个应用的形态应该是什么样子的,通过一副简单的图来描述一下 通过RC或者RS里面的模板创建了三个pod,之后通过一个servci ...
- SDUST数据结构 - chap6 树与二叉树
判断题: 选择题: 函数题: 6-1 求二叉树高度: 裁判测试程序样例: #include <stdio.h> #include <stdlib.h> typedef char ...
- UNDO表空间切换步骤
1.新建UNDO表空间 create undo tablespace UNDOTBS2 datafile '/data01/testdb/undotbs01.dbf' size 1G; alter d ...
- php 换行符
PHP 中换行可以用 PHP_EOL 来替代,以提高代码的源代码级可移植性: unix系列用 \n windows系列用 \r\n mac用 \r 总结:在一些大文本域中换行的文本可以用这个来进行切割 ...
- 1V转5V芯片,三个元件即可组成完整的稳压方案
1V低电压要转成5V的电压,需要1V转5V的芯片,由于1V输入,所以不需要指望能输出多大的电流,压差和1V的供电电压意味着供电电流也是无法做大的了.一般1V转5V的输出电流在0MA-100mA,一般6 ...
- Hive常用性能优化方法实践全面总结
Apache Hive作为处理大数据量的大数据领域数据建设核心工具,数据量往往不是影响Hive执行效率的核心因素,数据倾斜.job数分配的不合理.磁盘或网络I/O过高.MapReduce配置的不合理等 ...
- uni-app开发经验分享十九: uni-app对接微信小程序直播
uni-app对接微信小程序直播 1.登录微信小程序后台-点击>设置->第三方设置->添加直播插件 2.添加直播组件后->点击<详情> 记录这两个参数直播 ...