目标检测算法(一):R-CNN详解
参考博文:https://blog.csdn.net/hjimce/article/details/50187029
R-CNN(Regions with CNN features)--2014年提出
算法流程
1.输入一张图片,通过selective search算法找出2000个可能包括检测目标的region proposal(候选框)
2.采用CNN提取候选框中的图片特征(AlexNet输出特征向量维度为4096)
3.使用SVM对特征向量分类
4.bounding-box regression修正候选框位置
(一)候选框搜索
通过selective search算法可以搜索出2000个大小不同的矩形框,得到对应的坐标
遍历候选框:
对候选框进行筛选,去掉重复的、太小的方框等,假设剩余1500个。截取剩余的方框对应的图片,得到了1500张图片
由于CNN对输入图片的大小有要求,需要对以上图片进行缩放处理,方法有:各向异性缩放、各向同性缩放。缩放到CNN要求的大小
根据IOU对每一张图片进行标注,如IOU>0.5标注为目标类别(正样本),否则为背景类别(负样本)
我的理解:每一张原始图片都会生成1500个训练样本
(二)CNN提取特征
可选网络结构:AlexNet,Vgg-16
预训练:有监督预训练
物体检测的一个难点在于,物体标签训练数据少,如果要直接采用随机初始化CNN参数的方法,那么目前的训练数据量是远远不够的。
这种情况下,最好的是采用某些方法,把参数初始化了,然后在进行有监督的参数微调,文献采用的是有监督的预训练。
有监督预训练,我们也可以把它称之为迁移学习。比如你已经有一大堆标注好的人脸年龄分类的图片数据,训练了一个CNN,
用于人脸的年龄识别。然后当你遇到新的项目任务是:人脸性别识别,那么这个时候你可以利用已经训练好的年龄识别CNN模型,
去掉最后一层,然后其它的网络层参数就直接复制过来,继续进行训练。这就是所谓的迁移学习,说的简单一点就是把一个任务训练好的参数,
拿到另外一个任务,作为神经网络的初始参数值,这样相比于你直接采用随机初始化的方法,精度可以有很大的提高。
图片分类标注好的训练数据非常多,但是物体检测的标注数据却很少,如何用少量的标注数据,训练高质量的模型,这就是文献最大的特点,
这篇paper采用了迁移学习的思想。文献就先用了ILSVRC2012这个训练数据库(这是一个图片分类训练数据库),先进行网络的图片分类训练。
这个数据库有大量的标注数据,共包含了1000种类别物体,因此预训练阶段cnn模型的输出是1000个神经元,
或者我们也直接可以采用Alexnet训练好的模型参数。
fine-tuning
将最后一层的输出层单元数修改为目标检测的类别数+1,多出的一类为背景。输出层参数采用随机初始化,之前的参数不变。继续对网络进行训练。
(三)训练SVM
CNN最后的softmax层可以做分类,在论文中为什么要把softmax层换成SVM进行分类?
因为SVM和CNN分类时的正负样本定义不同,导致CNN+softmax输出比SVM精度要低。由于CNN容易过拟合,需要大量的训练样本,
所以CNN的样本标注比较宽松,IOU>0.5即标记为正样本。SVM适用于小样本训练,对样本的IOU要求较高,在训练时,IOU>0.7时标记为正样本。
由于SVM是二分类器,因此对每一个类别都需要训练一个SVM
(四)Bounding Box Regression--边框回归
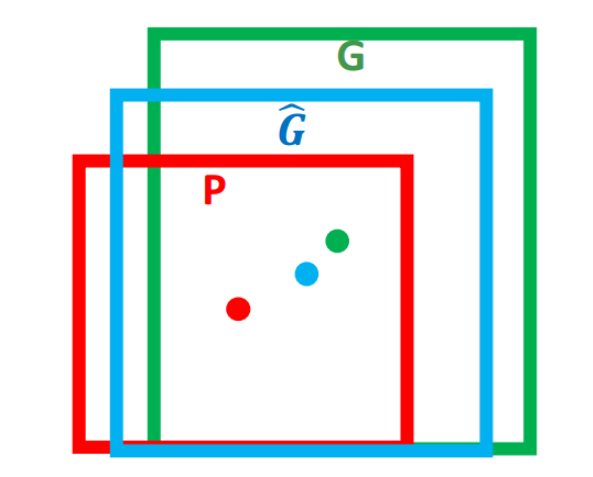
任务描述:G为目标边框(人为标注),P为网络计算得到的边框。边框回归的任务是计算从P到G^的映射f,使P经过映射以后得到与真实窗口G
更接近的G^
思路:平移+尺度缩放
输入:(训练时)CNN提取到的该边框的特征+Ground Truth即G的坐标
(预测时)CNN提取到的该边框的特征
输出:需要进行的平移量和尺度缩放量,即P到G^的映射,包括4个值:Δx,Δy,Sw,Sh
通过计算得到新的回归框
目标检测算法(一):R-CNN详解的更多相关文章
- 第二十九节,目标检测算法之R-CNN算法详解
Girshick, Ross, et al. “Rich feature hierarchies for accurate object detection and semantic segmenta ...
- 目标检测算法之R-CNN算法详解
R-CNN全称为Region-CNN,它可以说是第一个成功地将深度学习应用到目标检测上的算法.后面提到的Fast R-CNN.Faster R-CNN全部都是建立在R-CNN的基础上的. 传统目标检测 ...
- 深度学习之卷积神经网络(CNN)详解与代码实现(一)
卷积神经网络(CNN)详解与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10430073.html 目 ...
- 深度剖析目标检测算法YOLOV4
深度剖析目标检测算法YOLOV4 目录 简述 yolo 的发展历程 介绍 yolov3 算法原理 介绍 yolov4 算法原理(相比于 yolov3,有哪些改进点) YOLOV4 源代码日志解读 yo ...
- 如何使用 pytorch 实现 SSD 目标检测算法
前言 SSD 的全称是 Single Shot MultiBox Detector,它和 YOLO 一样,是 One-Stage 目标检测算法中的一种.由于是单阶段的算法,不需要产生所谓的候选区域,所 ...
- 深度学习笔记之目标检测算法系列(包括RCNN、Fast RCNN、Faster RCNN和SSD)
不多说,直接上干货! 本文一系列目标检测算法:RCNN, Fast RCNN, Faster RCNN代表当下目标检测的前沿水平,在github都给出了基于Caffe的源码. • RCNN RCN ...
- FCOS : 找到诀窍了,anchor-free的one-stage目标检测算法也可以很准 | ICCV 2019
论文提出anchor-free和proposal-free的one-stage的目标检测算法FCOS,不再需要anchor相关的的超参数,在目前流行的逐像素(per-pixel)预测方法上进行目标检测 ...
- CNN详解
CNN详解 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7450413.html 前言 这篇博客主要就是卷积神经网络(CNN) ...
- 目标检测算法YOLO算法介绍
YOLO算法(You Only Look Once) 比如你输入图像是100x100,然后在图像上放一个网络,为了方便讲述,此处使用3x3网格,实际实现时会用更精细的网格(如19x19).基本思想是, ...
- FAIR开源Detectron:整合全部顶尖目标检测算法
昨天,Facebook AI 研究院(FAIR)开源了 Detectron,业内最佳水平的目标检测平台. 昨天,Facebook AI 研究院(FAIR)开源了 Detectron,业内最佳水平的目标 ...
随机推荐
- Arduboy基本操作(二)
Arduboy基本操作(二) 方向键控制物体移动 #include<Arduboy.h> Arduboy arduboy; int i,j; void setup() { arduboy. ...
- 使用C#对华为IPC摄像头二次开发(一)
开发环境: 操作系统:Win10 x64专业版2004 开发工具:VS2019 16.7.2 目标平台:x86 首先去下载IPC SDK(点击下载,需要华为授权账户.) 新建一个WPF的项目,Fram ...
- GitBook 常用插件
目录 必看说明 插件说明 page-treeview 目录 code 代码 pageview-count 阅读量计数 popup 图片点击查看 tbfed-pagefooter 页面添加页脚(简单版) ...
- HTTP系列之跨域资源共享机制(CORS)介绍
前言 本文将继续解析详解HTTP系列1中的请求/ 响应报文的首部字段,今天带来的跨域资源共享(CORS)机制,具体内容包括CORS的原理.流程.实战,希望能给大家带来收获! CORS简介 跨域资源共享 ...
- 分享一个登录页面(前端框架layui)-20200318
效果图 对该页面的总结: 1.前端框架layui layui官网:https://www.layui.com/,下载之后,简单配置就可使用 2.layui模块引用与使用的方式 <script&g ...
- SEO诊断方案以及执行方案
http://www.wocaoseo.com/thread-127-1-1.html 今天和大家一起讨论一下SEO诊断方案以及SEO执行方案要怎么写,主要从哪些方面进行呢,做SEO的朋友们一直在探讨 ...
- 如何解决 iframe 无法触发 clickOutside
注:(1)非原创,来自https://blog.csdn.net/weixin_33985679/article/details/89699215.https://zhuanlan.zhihu.com ...
- vue cli3如何引入全局less变量
最近在项目中需要写一个全局的style.less,然后在各组件中可以直接调用: 1.在assets下创建一个less文件: 2.安装style-resources-loader (npm i styl ...
- JS 替换日期的横杠为斜杠
例如1: <script type="text/javascript"> var dt = "2010-01-05"; ...
- 利用OpenCV进行H264视频编码的简易方式
在Python下,利用pip安装预编译的opencv库,并实现h264格式的视频编码. 1. 安装OpenCV $ pip install opencv-python 建议在python虚拟环境下安装 ...