mycat分片及主从(二)
一、mycat分片规则
经过上一篇幅讲解,应该很清楚分片规则配置文件rule.xml位于$MYCAT_HOME/conf目录,它定义了所有拆分表的规则。在使用过程中可以灵活使用不同的分片算法,或者对同一个分片算法使用不同的参数,它让分片过程可配置化,只需要简单的几步就可以让运维人员及数据库管理员轻松将数据拆分到不同的物理库中。该文件包含两个重要的标签,分别是Funcation和tableRule。
总体上分为连续分片和离散分片,还有一种是连续分片和离散分片的结合,例如先范围后取模。比如范围分片(id 或者时间)就是典型的连续分片,单个分区的数量和边界是确定的。离散分片的分区总数量和边界是确定的,例如对 key 进行哈希运算,或者再取模。
1.1、连续分片
1.1.1、范围分片
关于连续分片在上一篇幅中已经讲过,那么在这一篇幅中就不演示了,在这里主要写下怎么配置及他的特点:
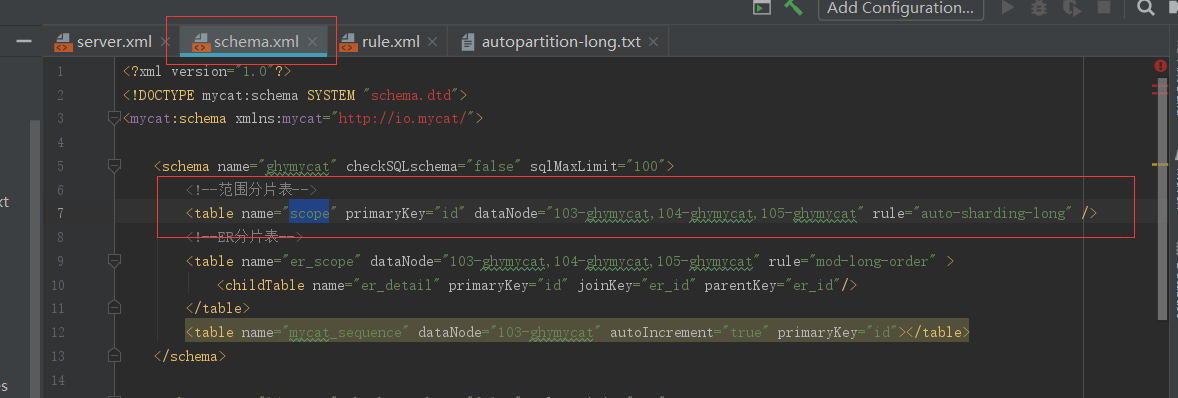
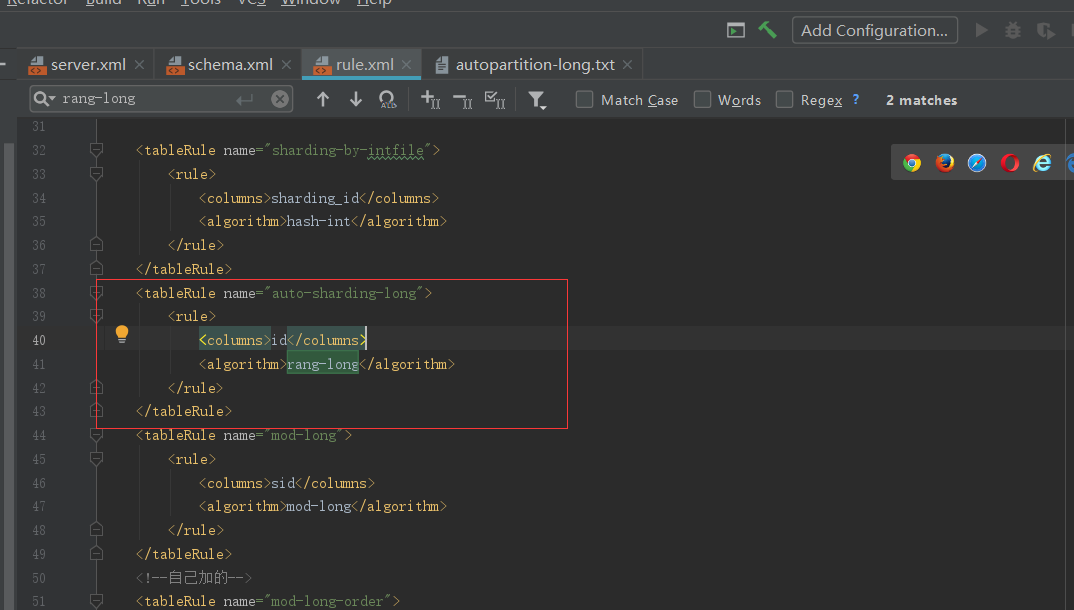
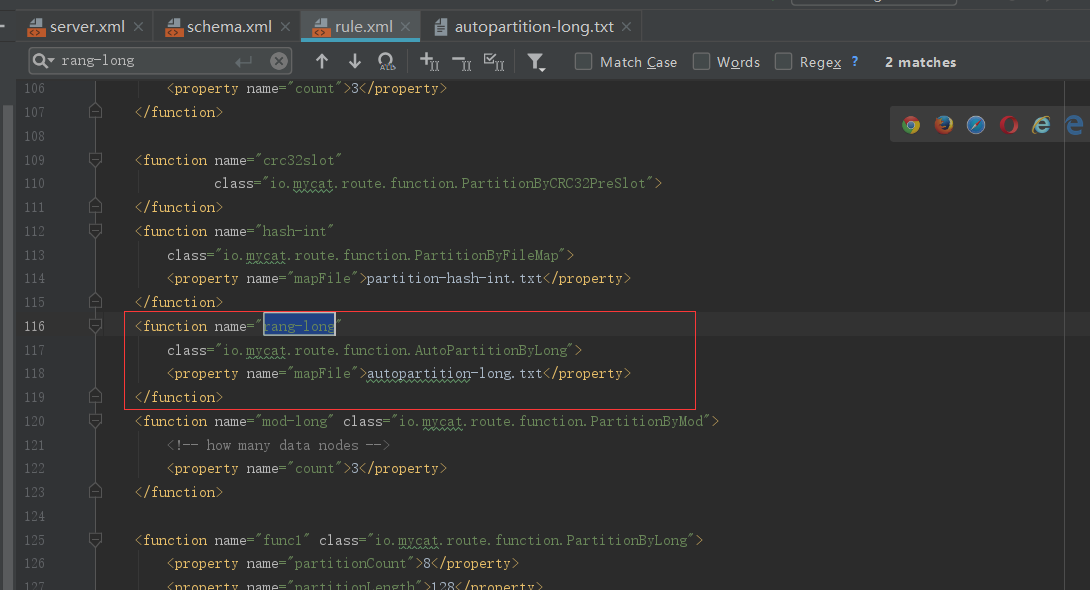
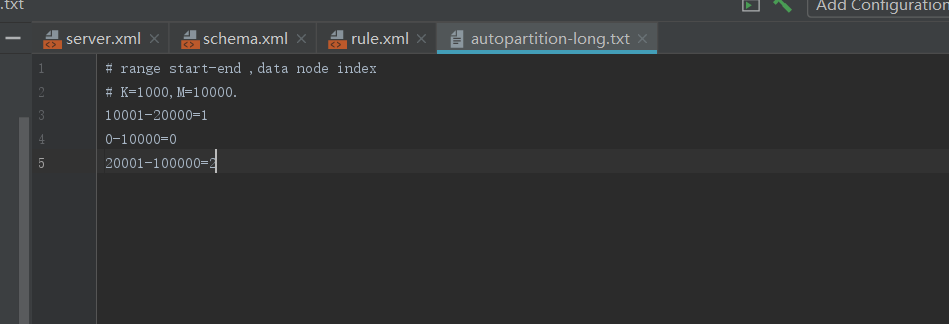
特点:容易出现冷热数据
1.1.2、按月分片
其实这里面的按月分配和上一篇幅中讲的单表中按月分片是一样的形式,唯一的区别就是一个是单库一个是多库;
在上一篇幅中的三个ghymycat库中接着创建三张表
-- 创建表
CREATE TABLE `month` (
`create_time` timestamp NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,
`name` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
在schema.xml中加入逻辑表
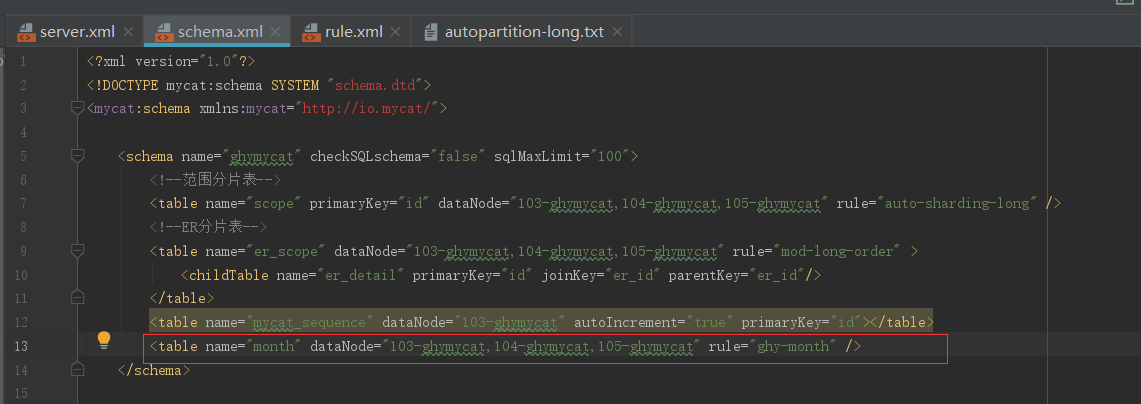
在rule.xml中加入分片规则

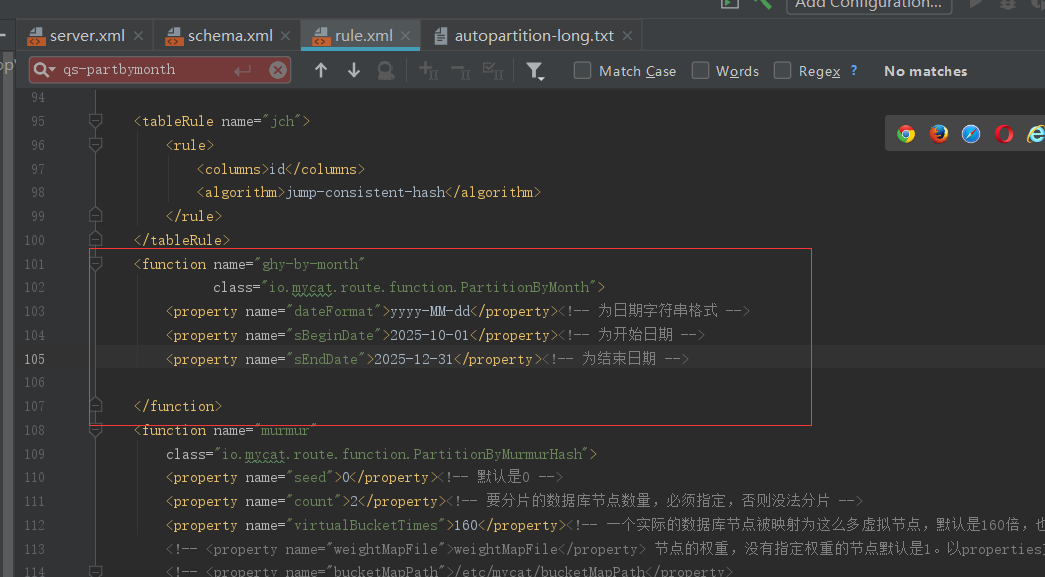
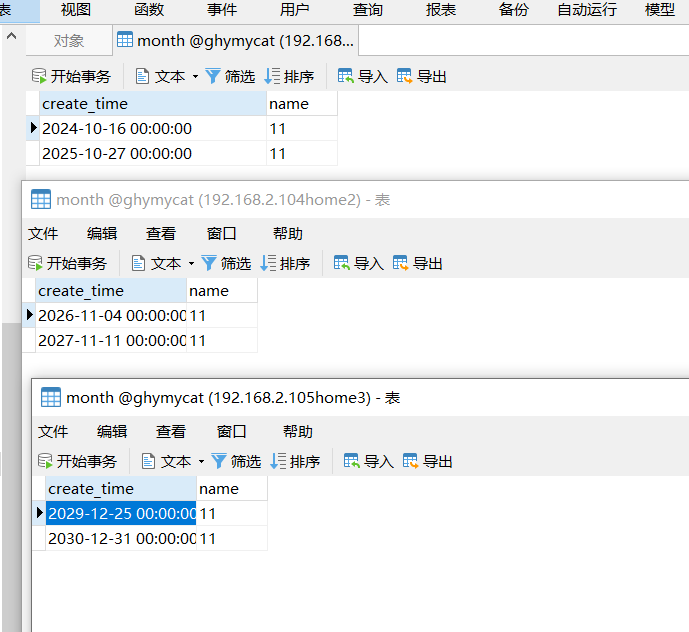
事情搞定那和上一篇幅一样,启动mycat服务然后测试
INSERT INTO month (create_time,name) VALUES ('2024-10-16', '11');
INSERT INTO month (create_time,name) VALUES ('2025-10-27', '11');
INSERT INTO month (create_time,name) VALUES ('2026-11-04', '11');
INSERT INTO month (create_time,name) VALUES ('2027-11-11', '11');
INSERT INTO month (create_time,name) VALUES ('2029-12-25', '11');
INSERT INTO month (create_time,name) VALUES ('2030-12-31', '11');
1.2、离散分片
1.2.1、十进制取模分片
根据分片键进行十进制求模运算。student表前面已经有讲过

特点:在插入数据时他会均匀的分布在所有节点上,解决了上面的冷热数据问题,但是他在数据迁移和增删节点时工作量会比较大
1.2.2、枚举分片
枚举分片适用场景,列值的个数是固定的,譬如省份,月份等。例如:全国 34 个省,要将不同的省的数据存放在不同的节点,可用枚举的方式。
和前面样,在三个ghymycat库中创建表
CREATE TABLE `t_vote` (
`age` int(11) NOT NULL,
`name` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
然后建立逻辑表

建立分片规则
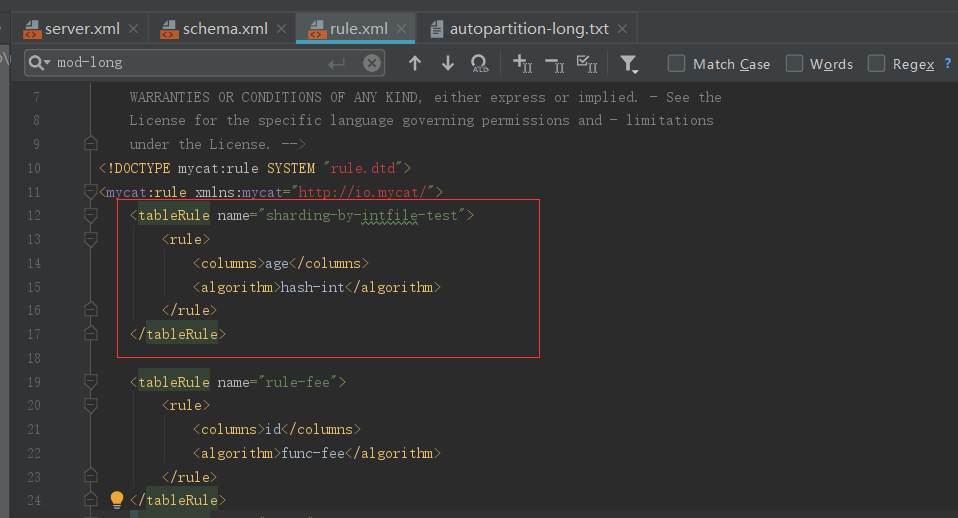
最后建立分片算法
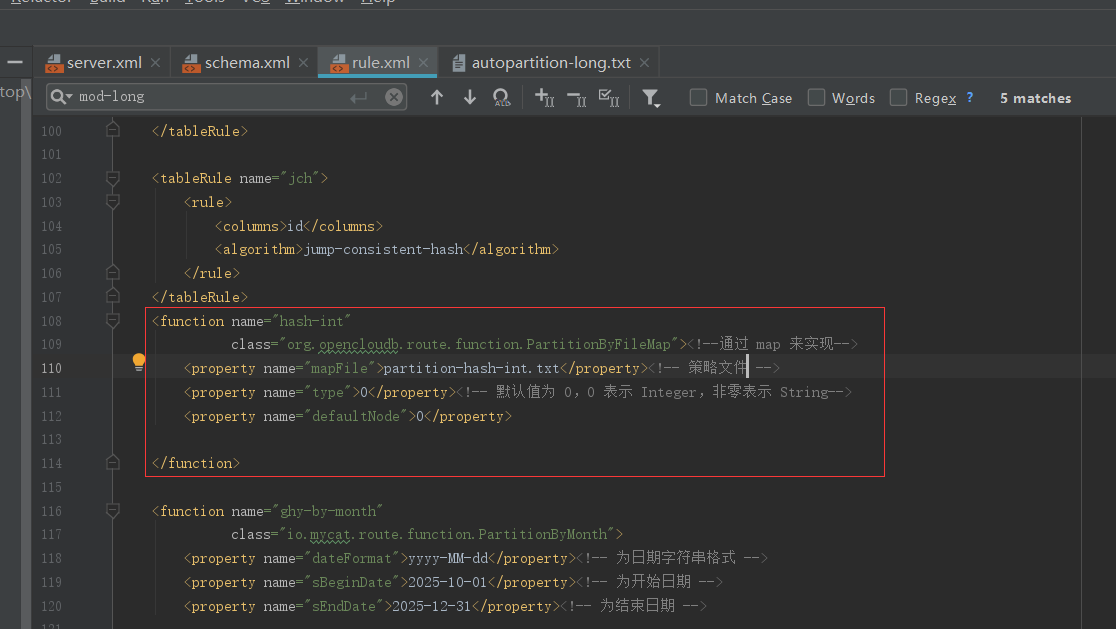
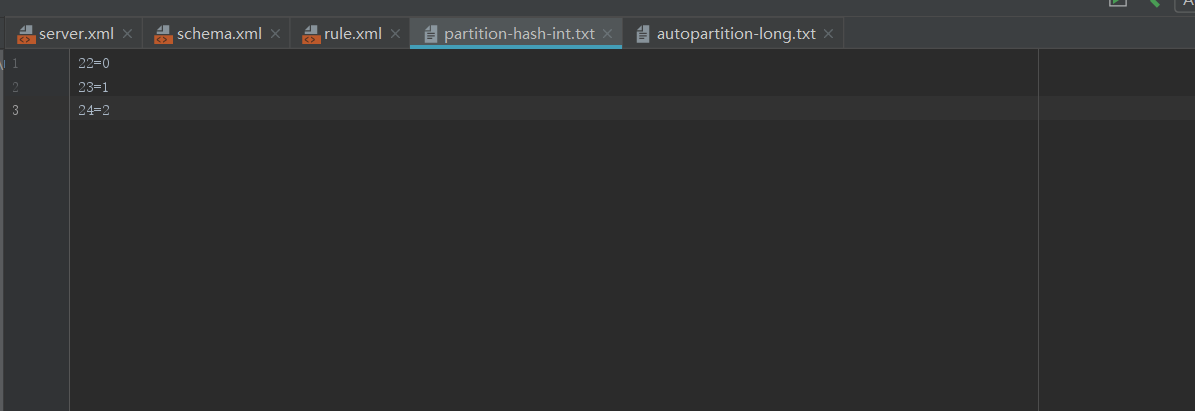
策略文件
测试数据
INSERT INTO `sharding_by_intfile` (age,name) VALUES (16, 11);
INSERT INTO `sharding_by_intfile` (age,name) VALUES (17, 11);
INSERT INTO `sharding_by_intfile` (age,name) VALUES (18, 11);
特点:如开头说的一样适用于枚举值固定的场景。
1.2.3、一致性哈希
一致性 hash 有效解决了分布式数据的扩容问题。
原理:为将数据均匀分布在各个节点中。对其进行哈希,取值在 0 ~ 232-1 闭环中定位到顺时针第一个节点,将此数据分配其中。由于节点有限,可能取哈希分布不均。设置虚拟节点比如160,先将哈希分布在160节点上,然后把对应的节点聚合到真实节点中。
在三个数据库ghymycat中建表
CREATE TABLE `consistency` (
`id` int(10) DEFAULT NULL,
`name` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
逻辑表

分片规则
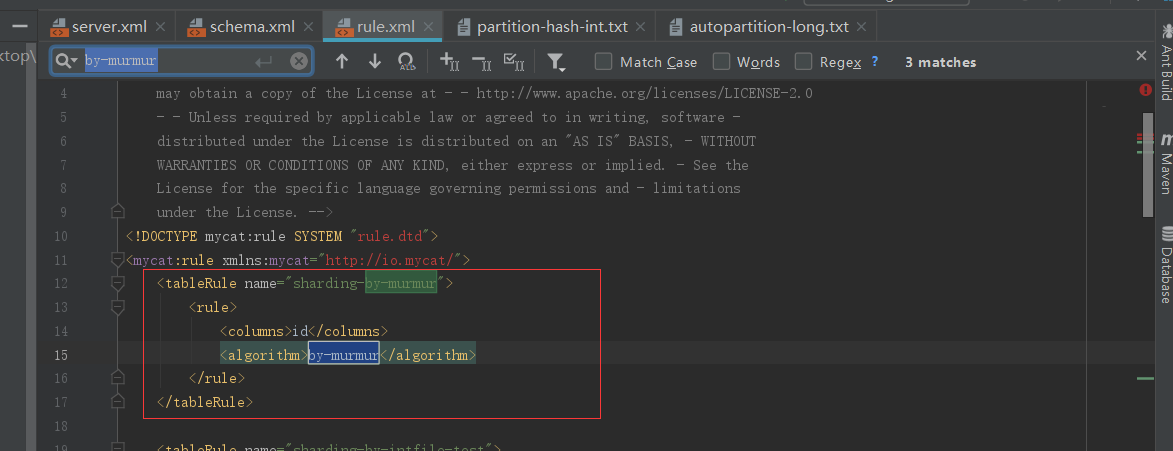
分片算法

INSERT INTO `consistency` (id,name) VALUES (1, '张三');
INSERT INTO `consistency` (id,name) VALUES (2, '张三');
INSERT INTO `consistency` (id,name) VALUES (3, '张三');
INSERT INTO `consistency` (id,name) VALUES (4, '张三');
INSERT INTO `consistency` (id,name) VALUES (5, '张三');
INSERT INTO `consistency` (id,name) VALUES (6, '张三');
INSERT INTO `consistency` (id,name) VALUES (7, '张三');
INSERT INTO `consistency` (id,name) VALUES (8, '张三');
INSERT INTO `consistency` (id,name) VALUES (9, '张三');
INSERT INTO `consistency` (id,name) VALUES (10, '张三');
INSERT INTO `consistency` (id,name) VALUES (11, '张三');
INSERT INTO `consistency` (id,name) VALUES (12, '张三');
INSERT INTO `consistency` (id,name) VALUES (13, '张三');
INSERT INTO `consistency` (id,name) VALUES (14, '张三');
INSERT INTO `consistency` (id,name) VALUES (15, '张三');
INSERT INTO `consistency` (id,name) VALUES (16, '张三');
INSERT INTO `consistency` (id,name) VALUES (17, '张三');
INSERT INTO `consistency` (id,name) VALUES (18, '张三');
INSERT INTO `consistency` (id,name) VALUES (19, '张三');
INSERT INTO `consistency` (id,name) VALUES (20, '张三');
特点:可以一定程度减少数据的迁移可以解决容灾,扩容。例如真实节点3个,比如:a,b,c;b宕机,原来要分配到b节点上的会分配到c上;加节点x到ac中间,原来分配到c节点的数据分配到x节点上。
1.2.4、固定分片哈希
这是先求模得到逻辑分片号,再根据逻辑分片号直接映射到物理分片的一种散列算法。
一样在三个ghymycat中创建表
CREATE TABLE `immobilization` (
`id` int(10) DEFAULT NULL,
`name` varchar(20) DEFAULT NULL
) ;
逻辑表

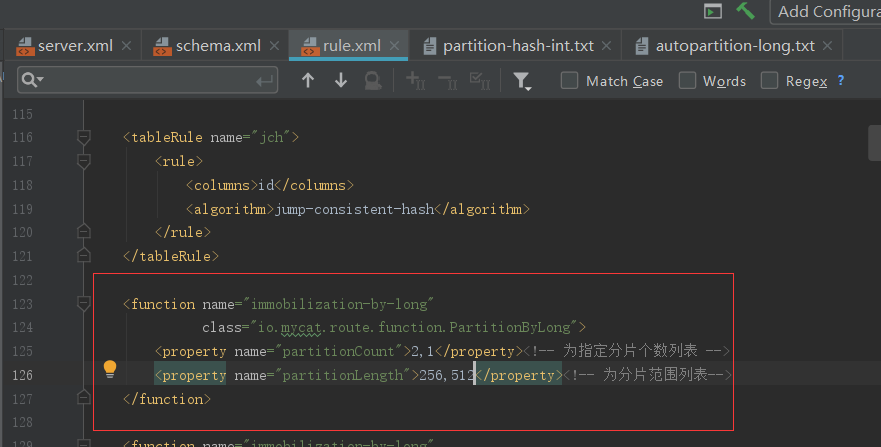
分片规则

平均分成 8 片(%1024 的余数,1024=128*8):


这是均匀分布的例子,下面再配置一个不均匀分布的例子,只用 改动分片算法(%1024 的余数,1024=2*256+1*512)

INSERT INTO `immobilization` (id,name) VALUES (222, '张三');
INSERT INTO `immobilization` (id,name) VALUES (333, '张三');
INSERT INTO `immobilization` (id,name) VALUES (666, '张三');
- 优点:这种策略比较灵活,可以均匀分配也可以非均匀分配,各节点的分配比例和容量大小由partitionCount 和 partitionLength两个参数决定
- 缺点:和取模分片类似。
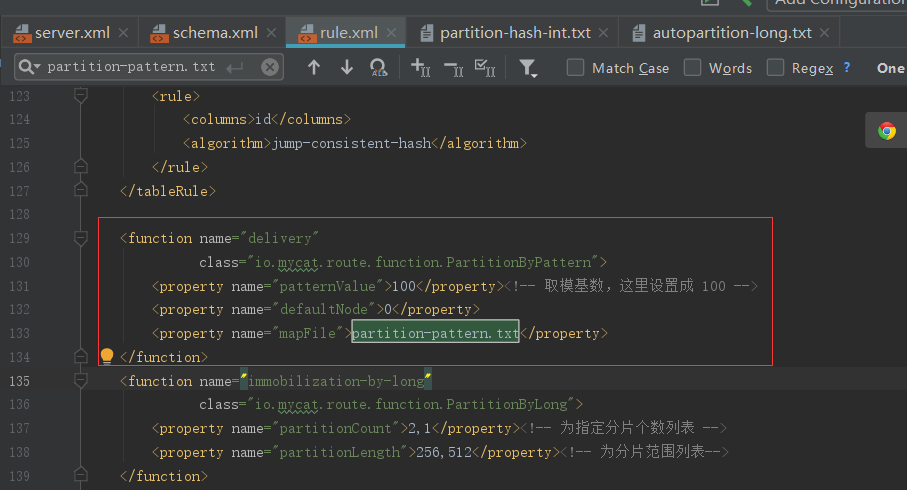
1.2.5、取模范围分片
先进行取模运算再根据求余结果范围进行分片,该种分片规则首先根据配置的分片字段,与配置的取模基数进行求余操作,根据求余的结果,然后判断在哪一个分片范围内,由此对应到具体某个数据分片上。
建表数据
CREATE TABLE `delivery` (
`id` varchar(20) DEFAULT NULL,
`name` varchar(20) DEFAULT NULL
) ;
逻辑表
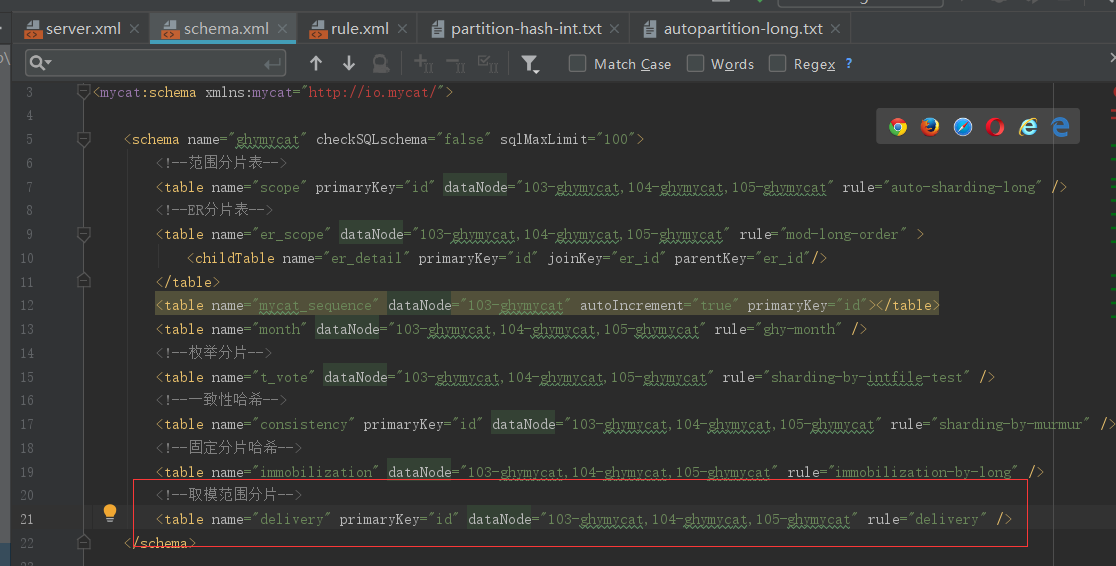
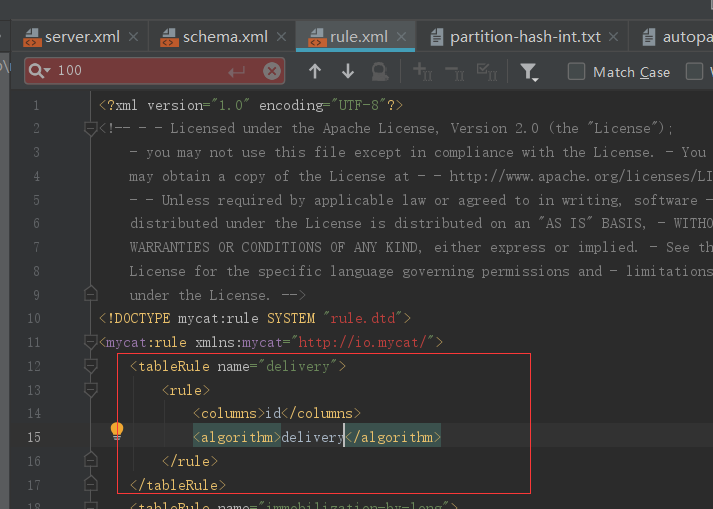
分片规则
分片算法
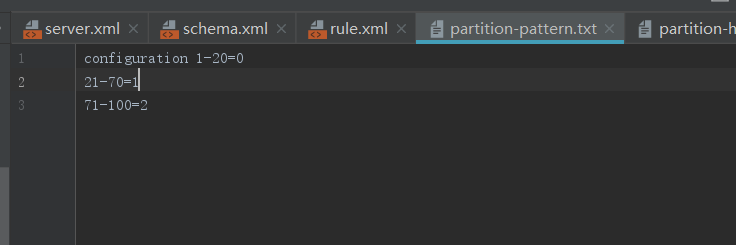
INSERT INTO `delivery` (id,name) VALUES (19, '张三');
INSERT INTO `delivery` (id,name) VALUES (222, '张三');
INSERT INTO `delivery` (id,name) VALUES (371, '张三');
- 优点:可以自由地决定取模后数据的节点分布
- 缺点:dataNode 划分节点是事先建好的,扩展比较麻烦。
1.2.6、范围取模分片
该算法先进行范围分片,计算出分片组,组内在取模
CREATE TABLE `delivery_mod` (
`id` varchar(20) DEFAULT NULL,
`name` varchar(20) DEFAULT NULL
) ;
逻辑表

分片规则
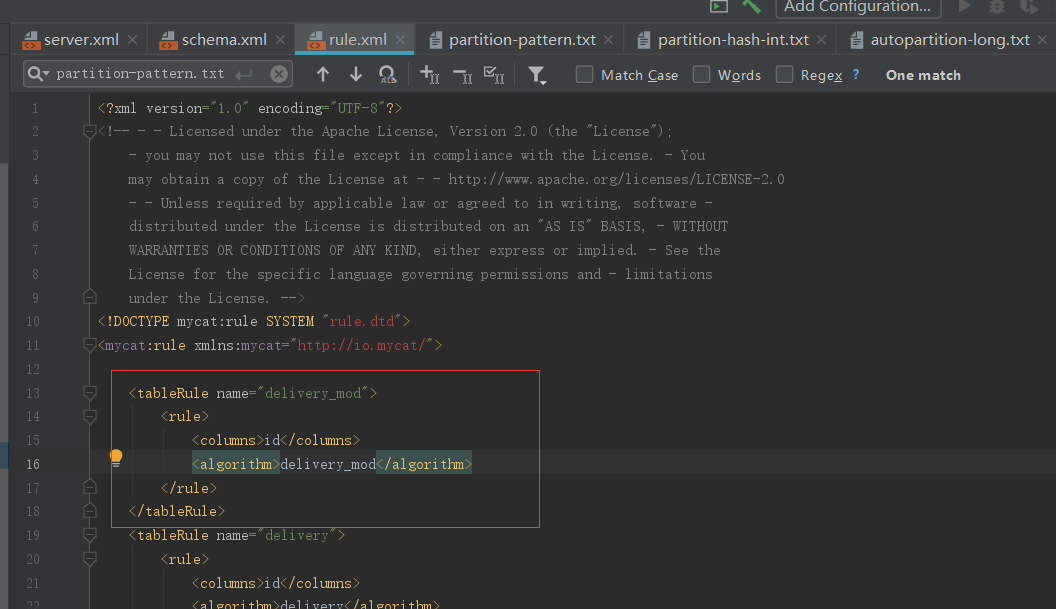
分片算法
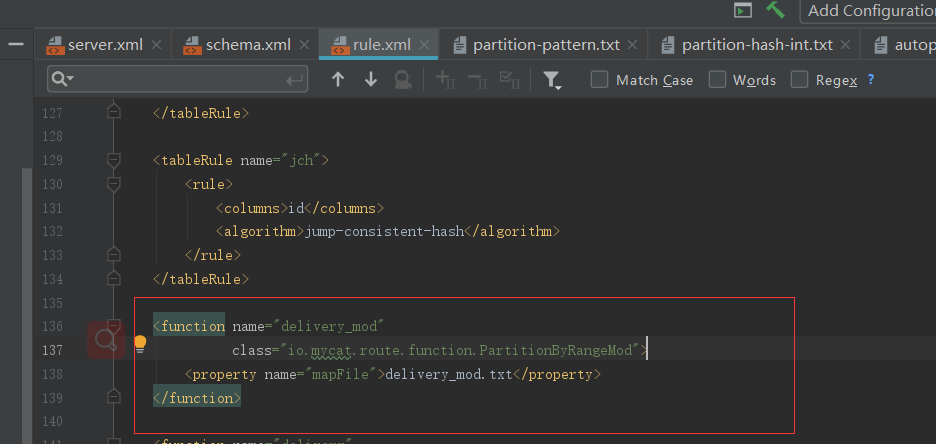
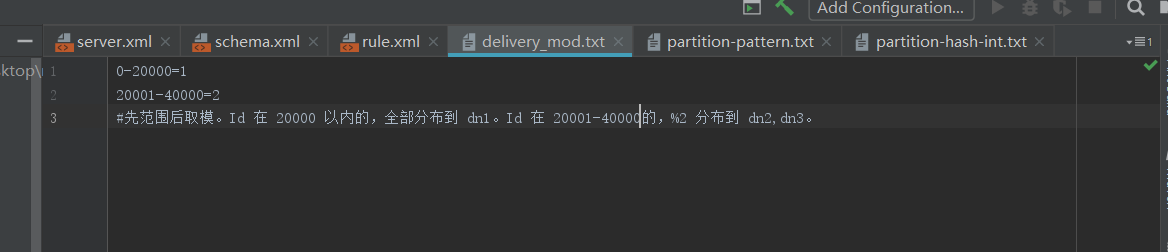
INSERT INTO `delivery_mod` (id,name) VALUES (666, '张三');
INSERT INTO `delivery_mod` (id,name) VALUES (6667, '张三');
INSERT INTO `delivery_mod` (id,name) VALUES (16666, '张三');
INSERT INTO `delivery_mod` (id,name) VALUES (21111, '张三');
INSERT INTO `delivery_mod` (id,name) VALUES (22222, '张三');
- 优点:综合了范围分片和取模分片的优点,分片组内使用取模可以保证组内的数据分布比较均匀,分片组之间采用范围分片可以兼顾范围分片的特点,事先规划好分片的数量,数据扩容时按照分片组扩容,则原有分片组的数据不需要迁移,分片组内还可以避免热点数据问题。
- 缺点:在数据范围时固定值(非递增值)时,存在不方便扩展的情况,例如将 dataNode Group size 从 2 扩展为 4 时,需要进行数据迁移才能完成
1.2.6、其他分片规则
- 应用指定分片 PartitionDirectBySubString
- 日期范围哈希 PartitionByRangeDateHash
- 冷热数据分片 PartitionByHotDate
- 也可以自定义分片规则: extends AbstractPartitionAlgorithm implements RuleAlgorithm。
1.3、连续分片和离散分片的特点
连续分片优点:
- 范围条件查询消耗资源少(不需要汇总数据)
- 扩容无需迁移数据(分片固定)
连续分片缺点:
- 存在数据热点的可能性
- 并发访问能力受限于单一或少量 DataNode(访问集中)
离散分片优点:
- 并发访问能力增强(负载到不同的节点)
- 范围条件查询性能提升(并行计算)
离散分片缺点:
- 数据扩容比较困难,涉及到数据迁移问题
- 数据库连接消耗比较多
1.4、切分规则的选择
- 找到需要切分的大表,和关联的表
- 确定分片字段(尽量使用主键),一般用最频繁使用的查询条件
- 考虑单个分片的存储容量和请求、数据增长(业务特性)、扩容和数据迁移问题。例如:按照什么递增?序号还是日期?主键是否有业务意义?一般来说,分片数要比当前规划的节点数要大。
二、 Mycat 扩缩容
一、准备工作
- mycat 所在环境安装 mysql 客户端程序
- mycat 的 lib 目录下添加 mysql 的 jdbc 驱动包(我这里下的是mysql-connector-java-5.1.27.jar)
- 对扩容缩容的表所有节点数据进行备份,以便迁移失败后的数据恢复
二、扩容缩容步骤
下面以取模分片表student为例
复制 schema.xml、rule.xml 并重命名为 newSchema.xml、newRule.xml 放于 conf 目录下
修改 newSchema.xml 和 newRule.xml 配置文件为扩容缩容后的 mycat 配置参数(表的节点数、数据源、路由规则)注意:只有节点变化的表才会进行迁移。仅分片配置变化不会迁移。
修改newSchema.xml配置
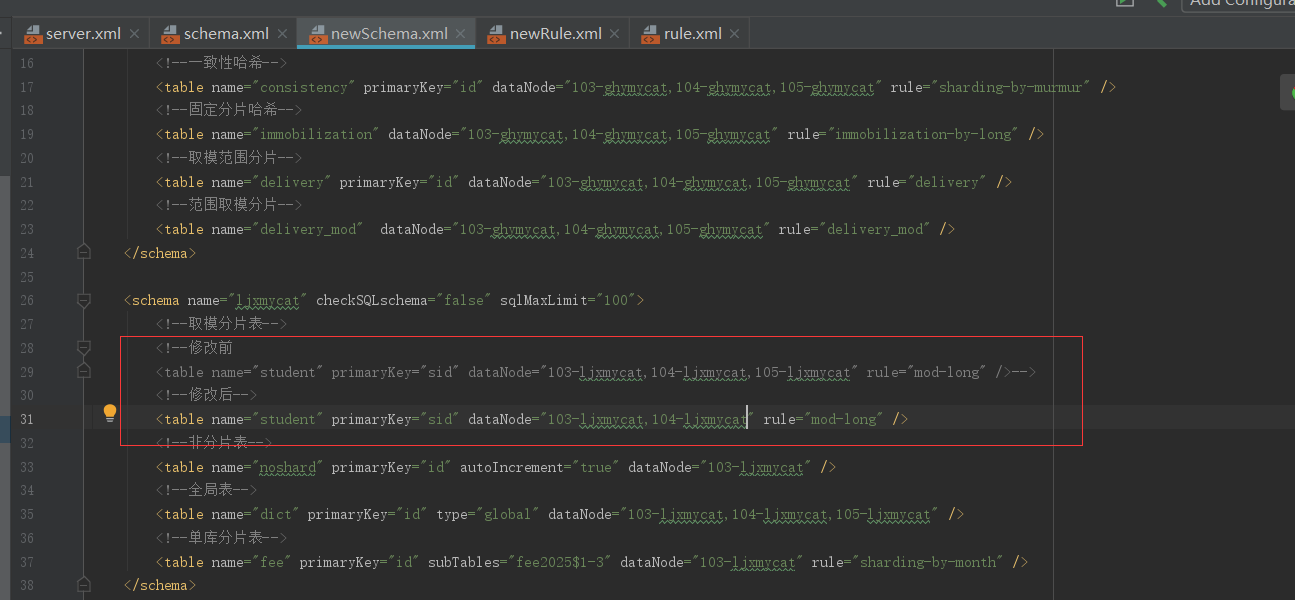
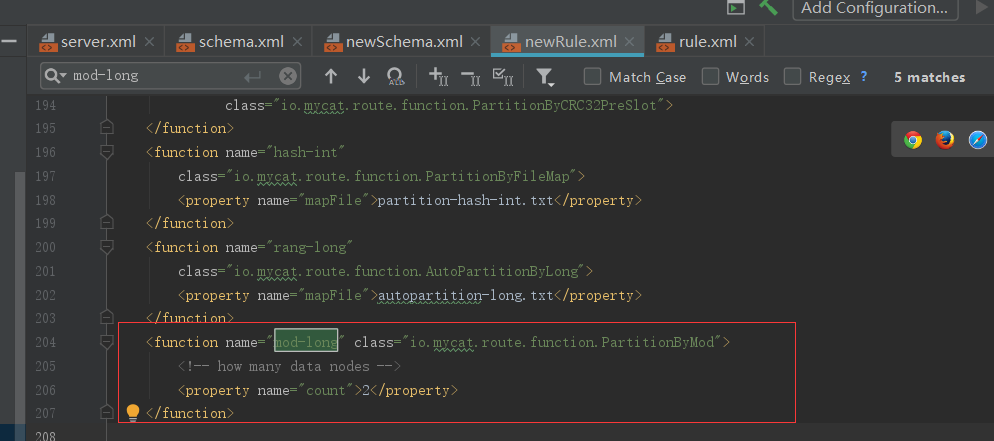
因为节点数发生了变化所以newRule.xml配置中的count节点数也需要修改成2
修改 conf 目录下的 migrateTables.properties 配置文件,告诉工具哪些表需要进行扩容或缩容,没有出现在此配置文件的 schema 表不会进行数据迁移,格式:

注意:
- 不迁移的表,不要修改 dn 个数,否则会报错。
- ER 表,因为只有主表有分片规则,子表不会迁移。
修改bin目录下的dataMigrate.sh脚本文件,参数如下:
tempFileDir 临时文件路径,目录不存在将自动创建
isAwaysUseMaster默认true:不论是否发生主备切换,都使用主数据源数据,false:使用当前数据源
mysqlBin:mysql bin路径
cmdLength mysqldump命令行长度限制 默认110k 110*1024。在LINUX操作系统有限制单条命令行的长度是128KB,也就是131072字节,这个值可能不同操作系统不同内核都不一样,如果执行迁移时报Cannot run program "sh": error=7, Argument list too long 说明这个值设置大了,需要调小此值。
charset导入导出数据所用字符集 默认utf8
deleteTempFileDir完成扩容缩容后是否删除临时文件 默认为true
threadCount并行线程数(涉及生成中间文件和导入导出数据)默认为迁移程序所在主机环境的cpu核数*2
delThreadCount每个数据库主机上清理冗余数据的并发线程数,默认为当前脚本程序所在主机cpu核数/2
queryPageSize 读取迁移节点全部数据时一次加载的数据量 默认10w条
指定临时文件路径 #临时文件路径,目录不存在将自动创建,不指定此目录则默认为mycat根下的temp目录
RUN_CMD="$RUN_CMD -tempFileDir=/root/data/program/mycat/temp"
指定为false可以查看此过程中产生的sql #完成扩容缩容后是否删除临时文件 默认为true
RUN_CMD="$RUN_CMD -deleteTempFileDir=false"
通过命令"find / -name mysqldump"查找mysqldump路径为"/usr/bin/mysqldump",指定#mysql bin路径为"/usr/bin/"

#mysql bin路径
RUN_CMD="$RUN_CMD -mysqlBin=/usr/bin/" 这个一定得配置
停止mycat服务(如果可以确保扩容缩容过程中不会有写操作,也可以不停止mycat服务)
通过crt等工具进入mycat根目录,执行bin/ dataMigrate.sh脚本,开始扩容/缩容过程:

脚本执行完成,如果最后的数据迁移验证通过,就可以将之前的 newSchema.xml和 newRule.xml 替换之前的 schema.xml 和 rule.xml 文件,并重启 mycat 即可。
注意事项:
- 保证分片表迁移数据前后路由规则一致(取模——取模)。
- 保证分片表迁移数据前后分片字段一致。
- 全局表将被忽略。
- 不要将非分片表配置到 migrateTables.properties 文件中。
- 暂时只支持分片表使用 MySQL 作为数据源的扩容缩容。migrate 限制比较多,还可以使用 mysqldump。
前面已经用 mycat 实现了 MySQL 数据的分片存储,第一个可以实现负载均衡,不同的读写发生在不同的节点上。第二可以实现横向扩展,如果数据持续增加,加机器就 可以了。当然,一个分片只有一台机器还不够。为了防止节点宕机或者节点损坏,都要用副本机制来实现。MySQL 数据库同样可以集群部署,有了多个节点之后,节点之间数据又是个大问题。所以下面说下实现节点数据同步
三、MySQL 主从复制
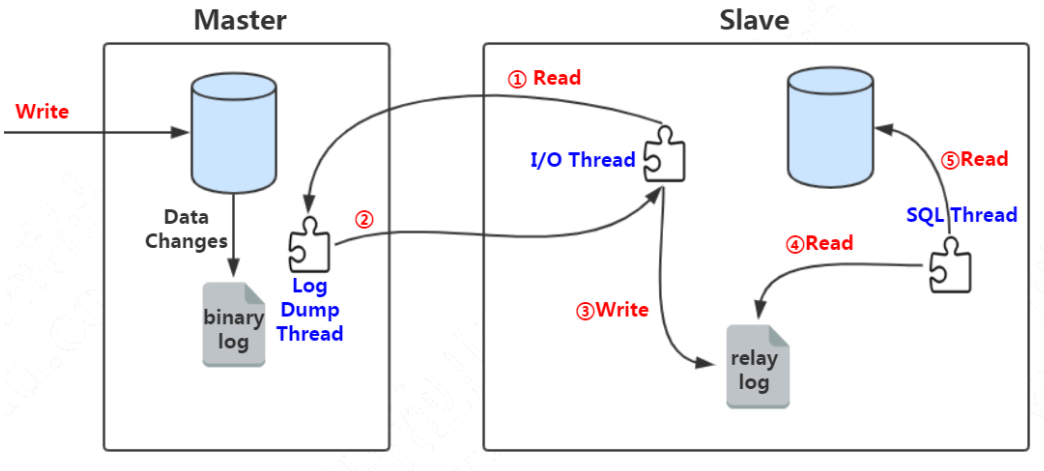
主从同步原理:
准备两台机器
master 192.168.2.103
slave 192.168.2.106
因为我是在docker中建的mysql容器,所以想要进入mysql内部要执行下面命令
docker exec -it e1066fe2db35 /bin/bash
如果没装vim的要先装下vim,运行命令:apt-get install vim
这时候需要运行命令:apt-get update

这个命令的作用是:同步 /etc/apt/sources.list 和 /etc/apt/sources.list.d 中列出的源的索引,这样才能获取到最新的软件包。
重新运行命令:apt-get install vim
安装完成。
如果用clone的方式得到两个MySQL服务,需要注意的地方:不同机器的UUID不能重复,否则IO线程不能启动:
find / -name auto.cnf
vim /var/lib/mysql/auto.cnf
把里面的UUID随便改掉一位。
重启服务命令:
service mysqld restart
103主节点配置
配置文件开启binlog
vim /etc/mysql/my.cnf文件
[mysqld]下面增加几行配置:
log-bin=mysql-bin
binlog-format=ROW
server_id=1
配置完成之后,需要重启mysql服务使配置生效。使用service mysql restart完成重启。
创建给slave使用的用户
在103主节点创建给slave 106节点访问的用户(发放通行证)
连接到MySQL:
mysql -uroot -proot;
执行SQL:
CREATE USER 'repl'@'192.168.2.106' IDENTIFIED BY 'root';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'192.168.2.106';
FLUSH PRIVILEGES;
如果有多个slave节点,使用同一个用户,也可以把IP设置成通配符的方式,例如192.168.2.*
获取binlog名字和position
接下来要获取最新的binlog文件名和position
show master status;
记住file名字和position,后面会用到。这个时候master不要发生写操作,否则position和file可能会变化。
slave节点配置
配置文件
[mysqld]下面增加几行配置:
log-bin=mysql-slave-bin
binlog-format=ROW
server_id=2
配置完成之后,需要重启mysql服务使配置生效。使用service mysql restart完成重启。
开启主从同步
连接到MySQL:
mysql -uroot -proot;
file和pos是从主节点获取的
change master to master_host='192.168.2.103', master_user='repl', master_password='root', master_log_file='mysql-bin.000028', master_log_pos=773;
查看从节点状态
show slave status;
注意,主从同步成功的标志:
IO线程和SQL线程都是成功运行的:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
现在可以在master节点上面做任意对于库表的修改操作,slave会自动同步。
不要直接操作slave。
如果IO线程not running:
stop slave;
SET GLOBAL SQL_SLAVE_SKIP_COUNTER=1;
start slave;
show slave status\G
3.1、主从复制的含义
在 MySQL 多服务器的架构中,主节点,也就是产生数据的节点叫 master 节点。其他的副本,向主节点同步数据的节点,叫做 slave(默认是异步的,客户端的数据在 master刷盘就返回)。一个集群里面至少要有一个 master。slave 可以有多个。
3.2、主从复制的用途
数据备份:把数据复制到不同的机器上,以免单台服务器发生故障时数据丢失。负载均衡:结合负载的机制,均摊所有的应用访问请求,降低单机 IO。高可用 HA:当节点故障时,自动转移到其他节点,提高可用性。主从复制的架构可以有多种
3.3、主从复制的形式
- 一主一从/一主多从
- 双主复制(互为主从)
- 级联复制
不过在,MySQL 自身并没有自动选举和故障转移的功能,需要依赖其他的中间件或者架构实现,比如 MMM,MHA,percona,mycat。下面就来说下主从的实现
3.4、binlog
客户端对 MySQL 数据库进行操作的时候,包括 DDL 和 DML 语句,服务端会在日志文件中用事件的形式记录所有的操作记录,这个文件就是 binlog 文件(属于逻辑日志,跟 Redis 的 AOF 文件类似)。Binary log,二进制日志。基于 binlog,我们可以实现主从复制和数据恢复。binlog 默认是不开启的,需要在服务端手动配置。注意有一定的性能损耗。
3.4.1、 binlog 配置
编辑 /etc/my.cnf
log-bin=mysql-bin server-id=1
重启 MySQL 服务
service mysqld stop service mysqld start ##如果出错查看日志
vi /var/log/mysqld.log
cd /var/lib/mysql
是否开启 binlog
show variables like 'log_bin%';
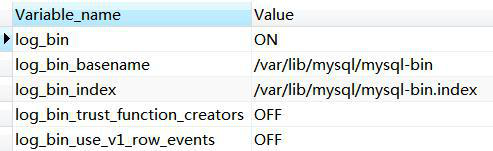
3.4.2 、binlog 格式
STATEMENT:记录每一条修改数据的 SQL 语句(减少日志量,节约 IO)。
ROW:记录哪条数据被修改了,修改成什么样子了(5.7 以后默认)。
MIXED:结合两种方式,一般的语句用 STATEMENT,函数之类的用
ROW。查看 binlog 格式:
show global variables like '%binlog_format%';
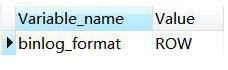
Binlog 文件超过一定大小就会产生一个新的,查看 binlog 列表:
show binary logs;

大小:
show variables like 'max_binlog_size';
查看 binlog 内容
show binlog events in 'mysql-bin.000001';
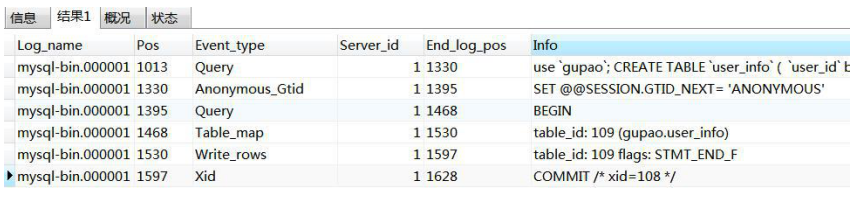
用 mysqlbinlog 工具,基于时间查看 binlog
/usr/bin/mysqlbinlog --start-datetime='2025-08-22 13:30:00' --stop-datetime='2025-08-22 14:01:01' -d ljxmycat /var/lib/mysql/mysql-bin.000001
3.5主从复制原理
3.5.1 主从复制配置
1、主库开启 binlog,设置 server-id
2、在主库创建具有复制权限的用户,允许从库连接
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'repl'@'192.168.2.106' IDENTIFIED BY 'root'; FLUSH PRIVILEGES;
3、从库/etc/my.cnf 配置,重启数据库
server-id=2 log-bin=mysql-bin relay-log=mysql-relay-bin read-only=1 log-slave-updates=1
开启 log-slave-updates 参数后,从库从主库复制的数据会写入 log-bin 日志文件里,这样可以实现互为主备或者级联复制(它自己也可以作为一个 master 节点)。
4、在从库执行
stop slave; change master to master_host='192.168.2.103',master_user='repl',master_password='root',master_log_file='mysql-bin.00000 1', master_log_pos=4; start slave;
5、查看同步状态
SHOW SLAVE STATUS
Slave_IO_Running 和 Slave SQL Running 都为 yes 为正常。
3.5.2 主从复制原理

1、slave 服务器执行 start slave,开启主从复制开关, slave 服务器的 IO 线程请求从 master 服务器读取 binlog(如果该线程追赶上了主库,会进入睡眠状态)。
2、master 服务器创建 Log Dump 线程,把 binlog 发送给 slave 服务器。slave 服务器把读取到的 binlog 日志内容写入中继日志 relay log(会记录位置信息,以便下次继续读取)。
3、slave 服务器的 SQL 线程会实时检测 relay log 中新增的日志内容,把 relay log 解析成 SQL 语句,并执行。
为什么需要 relay log?为什么不把接收到的 binlog 数据直接写入从库? Relay log 相当于一个中转站,也记录了 master 和 slave 的同步信息。
3.5.3 mycat 读写分离的实现
<dataHost name="host122" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1" url="192.168.2.103:3306" user="root" password="root"> <readHost host="hostS1" url="192.168.2.104:3306" user="root" password="root" /> </writeHost> </dataHost>
balance:负载的配置,决定 select 语句的负载

writeType:读写分离的配置,决定 update、delete、insert 语句的负载

switchType:主从切换配置

mycat分片及主从(二)的更多相关文章
- Mysql系列八:Mycat和Sharding-jdbc的区别、Mycat分片join、Mycat分页中的坑、Mycat注解、Catlet使用
一.Mycat和Sharding-jdbc的区别 1)mycat是一个中间件的第三方应用,sharding-jdbc是一个jar包 2)使用mycat时不需要改代码,而使用sharding-jdbc时 ...
- Mysql系列六:(Mycat分片路由原理、Mycat常用分片规则及对应源码介绍)
一.Mycat分片路由原理 我们先来看下面的一个SQL在Mycat里面是如何执行的: , ); 有3个分片dn1,dn2,dn3, id=5000001这条数据在dn2上,id=10000001这条数 ...
- mycat分片操作
mycat位于应用与数据库的中间层,可以灵活解耦应用与数据库,后端数据库可以位于不同的主机上.在mycat中将表分为两大类:对于数据量小且不需要做数据切片的表,称之为分片表:对于数据量大到单库性能,容 ...
- Mycat高可用解决方案二(主从复制)
Mycat高可用解决方案二(主从复制) 系统部署规划 名称 IP 主机名称 用户名/密码 配置 mysql主节点 192.168.199.110 mysql-01 root/hadoop 2核/2G ...
- mycat分片规则之分片枚举(sharding-by-intinfile)
mycat分片规则之分片枚举(sharding-by-intinfile) http://blog.51cto.com/goome/2058959 mycat安装及分片初体验 https://blog ...
- MyCat分片规则--笔记(二)
概述 myCat实现分库分表的策略,对数据量的处理带来很大的便利,这里主要整理下MyCat的使用以及常用路由算法,针对MyCat里面的事务.集群后续再做整理:另外内容整理,不免会参考技术大牛的博客,内 ...
- Mycat实现Mysql主从读写分离
一.概述 关于Mycat的原理网上有很多,这里不再详述,对于我来说Mycat的功能主要有如下几种: 1.Mysql主从的读写分离 2.Mysql大表分片 3.其他数据库例如Oracle,MSSQL,D ...
- Mycat在MySQL主从模式(1主1从)下读写分离和及自动切换模式的验证
实验环境 两台Centos7 MySQL5.7.12 IP地址为:192.168.10.36 192.168.10.37 一台Centos7 Mycat IP地址为:192.168.10.31 一 ...
- mycat系列-Mycat 分片规则
分片规则概述 在数据切分处理中,特别是水平切分中,中间件最终要的两个处理过程就是数据的切分.数据的聚合.选择合适的切分规则,至关重要,因为它决定了后续数据聚合的难易程度,甚至可以避免跨库的数据聚合处理 ...
随机推荐
- 最新主流 Markdown 编辑器推荐
Markdown ,2004年由 John Gruberis 设计和开发,是一种可以使用普通文本编辑器编写的标记语言,通过简单的标记语法,它可以使普通文本内容具有一定的格式,以下将介绍目前比较流行的一 ...
- C# 实现十六进制Unicode编码字符串转换为汉字
网上找了几个方法,但是运行之后会报错,提示要解析的字符串格式不正确.然后我猜想可能是传入的字符串 \u60a8\u4eca\u65e5\u5df2\u7b7e\u5230 中带"\" ...
- django配置跨域并开发测试接口
1.创建一个测试项目 1.1 创建项目和APP django-admin startproject BookManage # 创建项目 python manage.py startapp books ...
- 用GitHub Pages搭建博客(七)
本篇介绍百度统计.百度搜索 一般来讲,部署了一个网站后,我们需要知道网站的浏览量,以便知道网站是否有人访问. 在Jekyll的模板中,由于国外开发者更多,一般的主题默认都开发了谷歌统计(Google ...
- SQL Server 存储过程解析XML传参 参考方案
1.定义存储过程 -- =============================================--定义存储过程-- ================================ ...
- 5 MVVM
1.概述 MVVM各个部分功能如下: Model:定义业务逻辑 View:定义面向用户接口,UI逻辑,处理用户交互请求 ViewModel:负责界面导航逻辑和应用状态管理,呈现逻辑. 1.1. 各司其 ...
- JavaScript中.、[]与setAttribute()在设置属性上的区别
.和[] javaScript.和[]既可以对所有js对象设置属性,但是对于DOM对象它设置的属性有些特殊.对于元素DOM标准属性,实现属性值的设置/更改;对于元素DOM非标准属性,仅在js中有效,在 ...
- 记录一次读取hdfs文件时出现的问题java.net.ConnectException: Connection refused
公司的hadoop集群是之前的同事搭建的,我(小白一个)在spark shell中读取hdfs上的文件时,执行以下指令 >>> word=sc.textFile("hdfs ...
- switch,case语句易误区
switch case 语句语法格式如下: switch(expression){ case value : //语句 break; //可选 case value : //语句 break; //可 ...
- ceph的rbd备份软件ceph-backup
teralytics是一家国外的大数据公司,这个是他们开源的ceph的备份的工具,在twitter上搜索相关信息的时候看到,觉得不错就拿来试用一番 这是个什么软件 一个用来备份 ceph 的 rbd ...