sklearn preprocessing (预处理)
预处理的几种方法:标准化、数据最大最小缩放处理、正则化、特征二值化和数据缺失值处理。
知识回顾:

p-范数:先算绝对值的p次方,再求和,再开p次方。
数据标准化:尽量将数据转化为均值为0,方差为1的数据,形如标准正态分布(高斯分布)。
标准化(Standardization)
公式为:(X-X_mean)/X_std 计算时对每个属性/每列分别进行。
将数据按其属性(按列进行)减去其均值,然后除以其方差。最后得到的结果是,对每个属性/每列来说所有数据都聚集在0附近,方差值为1。
sklearn中preprocessing库里面的scale函数使用方法:
sklearn.preprocessing.scale(X, axis=0, with_mean=True, with_std=True, copy=True)
根据参数不同,可以沿任意轴标准化数据集。
参数:
- X:数组或者矩阵
- axis:int类型,初始值为0,axis用来计算均值和标准方差。如果是0,则单独的标准化每个特征(列),如果是1,则标准化每个观测样本(行)。
- with_mean:boolean类型,默认为True,表示将数据均值规范到0。
- with_std:boolean类型,默认为True,表示将数据方差规范到1。
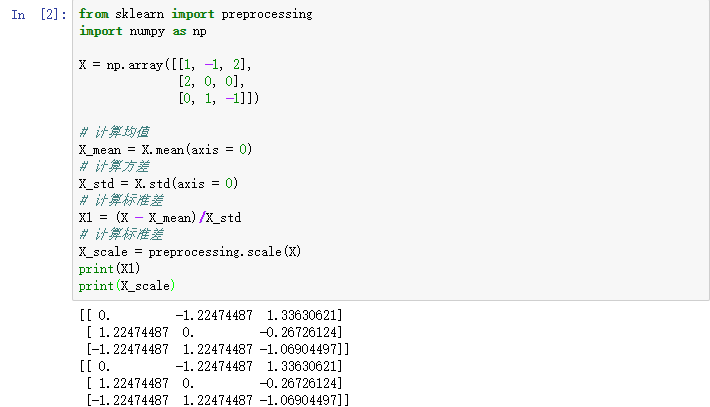
范例:假设现在构造一个数据集X,然后想要将其标准化。
方法一:使用sklearn.preprocessing.scale()函数
方法说明:
- X.mean(axis=0)用来计算数据X每个特征的均值;
- X.std(axis=0)用来计算数据X每个特征的方差;
- preprocessing.scale(X)直接标准化数据X。
方法二:sklearn.preprocessing.StandardScaler类
sklearn.preprocessing.StandardScaler(copy=True, with_mean=True, with_std=True)
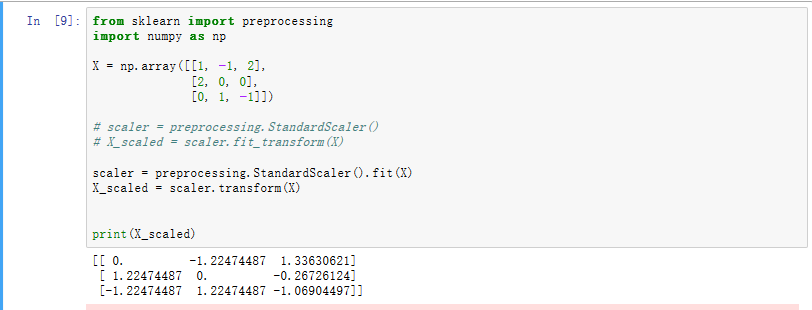
scaler = preprocessing.StandardScaler()
X_scaled = scaler.fit_transform(X)scaler = preprocessing.StandardScaler().fit(X)
X_scaled = scaler.transform(X)
上面两段代码等价。
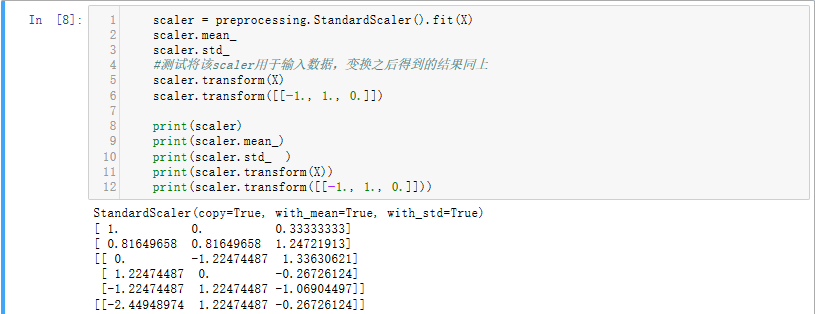
转换器(Transformer)主要有三个方法:
fit():训练算法,拟合数据
transform():标准化数据
fit_transform():先拟合数据,再标准化。
sklearn preprocessing (预处理)的更多相关文章
- 【sklearn】数据预处理 sklearn.preprocessing
数据预处理 标准化 (Standardization) 规范化(Normalization) 二值化 分类特征编码 推定缺失数据 生成多项式特征 定制转换器 1. 标准化Standardization ...
- sklearn学习笔记(一)——数据预处理 sklearn.preprocessing
https://blog.csdn.net/zhangyang10d/article/details/53418227 数据预处理 sklearn.preprocessing 标准化 (Standar ...
- Python数据预处理(sklearn.preprocessing)—归一化(MinMaxScaler),标准化(StandardScaler),正则化(Normalizer, normalize)
关于数据预处理的几个概念 归一化 (Normalization): 属性缩放到一个指定的最大和最小值(通常是1-0)之间,这可以通过preprocessing.MinMaxScaler类实现. 常 ...
- sklearn preprocessing 数据预处理(OneHotEncoder)
1. one hot encoder sklearn.preprocessing.OneHotEncoder one hot encoder 不仅对 label 可以进行编码,还可对 categori ...
- sklearn数据预处理-scale
对数据按列属性进行scale处理后,每列的数据均值变成0,标准差变为1.可通过下面的例子加深理解: from sklearn import preprocessing import numpy as ...
- sklearn数据预处理
一.standardization 之所以标准化的原因是,如果数据集中的某个特征的取值不服从标准的正太分布,则性能就会变得很差 ①函数scale提供了快速和简单的方法在单个数组形式的数据集上来执行标准 ...
- Scikit-learn Preprocessing 预处理
本文主要是对照scikit-learn的preprocessing章节结合代码简单的回顾下预处理技术的几种方法,主要包括标准化.数据最大最小缩放处理.正则化.特征二值化和数据缺失值处理. 数学基础 均 ...
- 数据规范化——sklearn.preprocessing
sklearn实现---归类为5大类 sklearn.preprocessing.scale()(最常用,易受异常值影响) sklearn.preprocessing.StandardScaler() ...
- sklearn 数据预处理1: StandardScaler
作用:去均值和方差归一化.且是针对每一个特征维度来做的,而不是针对样本. [注:] 并不是所有的标准化都能给estimator带来好处. “Standardization of a dataset i ...
随机推荐
- html5的理解
1.良好的移动性,以移动设备为主 2.响应式设计,以适应自动变化的屏幕尺寸 3.支持离线缓存技术,webStorage本地缓存 4.新增canvas.video.audio等新标签元素,新增特殊内容元 ...
- VMware14安装centos7
win10专业版 虚拟机:14 Pro 1. 新建虚拟机选择典型安装 2. 稍后安装操作系统 3. 选择Linux,版本选择centso7 64位(根据系统选择) 4. 设置虚拟机名称并选择安装位置 ...
- PyCharm配置Python3开发环境
PyCharm配置Python3开发环境 PyCharm的开发环境是配置在对应的工程中: 一.创建一个Project 工具栏:New - New Project 建议指定一个专门的目录 ,用来存放py ...
- nginx按日期分割日志
#!/bin/bash # Program:chenglee # Auto cut nginx log script. LOGS_PATH="/usr/local/nginx1.13/log ...
- python简说(十一)os模块
import osres = os.listdir('/Users/nhy/Desktop') #列出某个目录下的所有文件# os.remove()# os.rename()# os.mkdir(r' ...
- 《学习OpenCV3》第14章课后习题
1.在一条含有 N 个点的封闭轮廓中,我们可以通过比较每个点与其它点的距离,找出最外层的点.(这个翻译有问题,而且这个问题是实际问题) a.这样一个算法的复杂度是多少? b.怎样用更快的速度完成这个任 ...
- 20145326蔡馨熤《网络对抗》——MSF基础应用
20145326蔡馨熤<网络对抗>——MSF基础应用 实验后回答问题 用自己的话解释什么是exploit,payload,encode. exploit:起运输的作用,将数据传输到对方主机 ...
- 基于快速排序思想partition查找第K大的数或者第K小的数。
快速排序 下面是之前实现过的快速排序的代码. function quickSort(a,left,right){ if(left==right)return; let key=partition(a, ...
- Codeforces Round 500 (Div 2) Solution
从这里开始 题目地址 瞎扯 Problem A Piles With Stones Problem B And Problem C Photo of The Sky Problem D Chemica ...
- 如何开启Intel HAXM功能
1. 启用BIOS中的Intel(R) Virtualization Technology选项 2.设置成功后,在控制台中输入sc query intelhaxm.出现下图即为成功 3. 启动andr ...