Video Frame Synthesis using Deep Voxel Flow 论文笔记
Video Frame Synthesis using Deep Voxel Flow 论文笔记
arXiv
摘要:本文解决了模拟新的视频帧的问题,要么是现有视频帧之间的插值,要么是紧跟着他们的探索。这个问题是非常具有挑战性的,因为,视频的外观和运动是非常复杂的。传统 optical-flow-based solutions 当 flow estimation 失败的时候,就变得非常困难;而最新的基于神经网络的方法直接预测像素值,经常产生模糊的结果。
于是,在此motivation的基础上,作者提出了结合这两种方法的思路,通过训练一个神经网络,来学习去合成视频帧,通过 flowing pixel values from existing ones, 我们称之为:deep voxel flow. 所提出的方法不需要人类监督,任何video都可以用于训练,通过丢掉,并且预测现有的frames。这种方法是非常有效的,可以用于任何的分辨率。实验结果还是不错的。
引言:本文所涉及到的两个重要的部分,一个是 video interporation;一个是 video extrapolation。
传统的方法解决上述问题,就是依赖于 帧与帧之间的 optical flow,然后进行 optical flow vectors 之间的【插值】或者 【预测】。这种方法称为:“optical-flow-complete”;当光流准确的时候,这种方法是非常有效的,但是当不准确的时候,就会产生额外的错误信息。一种基于产生式 CNN 的方法,直接产生 RGB 像素值。但是这种方法经常会产生模糊的情况,并非像光流一样有效。
本文的目标是结合这两种方法的优势。作者有两个方面的观察:
1. 大部分像素块都是近邻图像的直接copy,而直接copy pixels 比模拟产生他们,要简单的多。
2. 端到端训练的神经网络是一个非常有效的工具。对于 video interpolation 和 extrapolation 来说,更是如此,因为训练可以是无限的;任何video都可以用于训练一个无监督的神经网络。
所以,我们就可以利用现有的video进行无监督的学习。我们扔掉 frames,然后利用损失函数来衡量 产生的像素值 和 gt 像素值之间的差距。但是,像 optical-flow approaches 一样,我们的网络通过从附近的 frames 插值 pixel values。这个网络包括 a voxel flow layer ------ a per-pixel, 3D optical flow vector across space and time in the input video. 所以,对于 video interpolation,最终输出的像素值,可以是前一帧和后一帧混合的像素值。
The Proposed Methods :
本文提出一种 Deep Voxel Flow (DVF) 算法 ------ an end-to-end fully differentiable network for video frame synthesis. 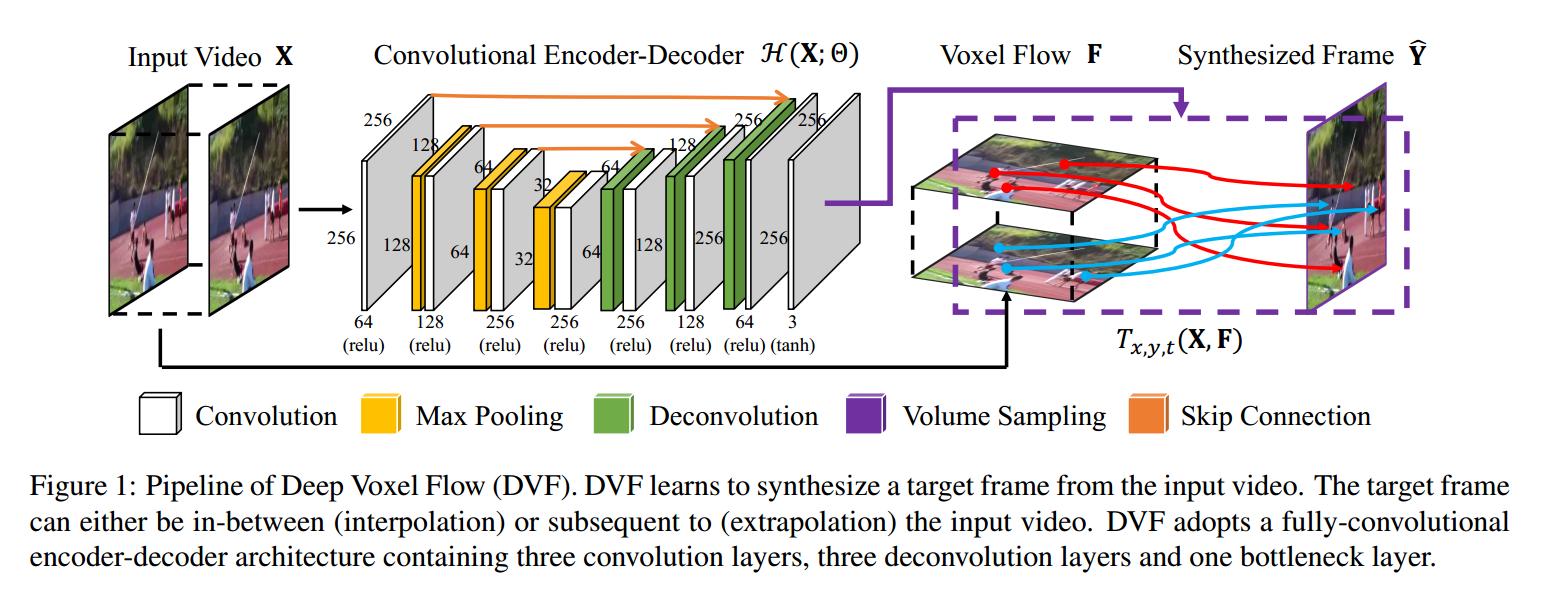
像上图所展示的那样,卷积 encoder-decoder 预测 the 3D voxel flow, 然后我们添加 添加一个 volume sampling layer sythesizes the desired frame, accordingly. DVF 学习去模拟target frame Y,输入的video为 X。我们将 the convolutional encoder-decoder 看做是 H(),H 的输出是 3D voxel flow field F
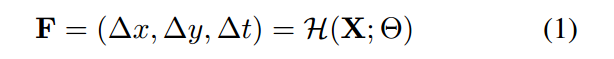
voxel flow F 的空间成分表示 从 target frame 到 the next frame 的optical flow;该光流的 negative 用来鉴别对应的前一帧的位置。即,我们假设光流是局部线性的,并且是 时间上对称的 around the in-between frame. 准确的说,我们在前一帧和后一帧,定义了对应位置的绝对位置:$L_0, L_1$。
voxel flow F 时间上的成分是 a linear blend weight between the previous and next frames to form a color in the target frame.
我们利用这个 voxel flow 来采样原始的输入video X with a volume sampling function T 来构成最终的拟合帧 Y:
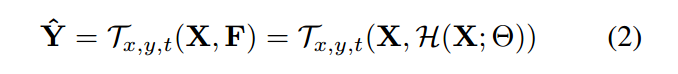
The volume sampling function 从 X 上计算出 在 optical-flow-aligned video volume 内部进行插值采样color。给定对应的位置 (L0, L1),我们利用这个 volume 构建一个 virtual voxel,然后利用 trilinear interpolation 来计算输出的 video color 。我们在输入 video X 上计算 the virtual voxel 的 8个顶点的 integer locations :
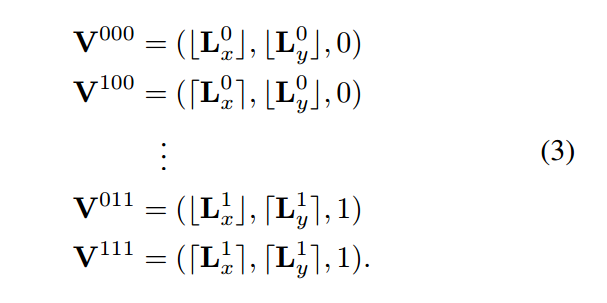
给定了这个 virtual voxel,3D voxel flow 通过 trilinear interpolation,产生每个 target voxel Y
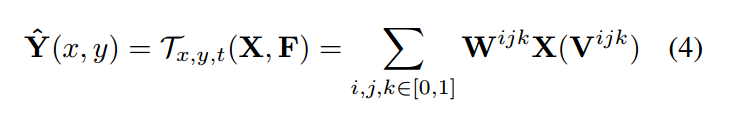
其中,$W^{ijk}$ 是 trilinear resampling weight.
这个 3D voxel flow 可以看做是 2D motion field 和 前一帧和后一帧的 mask 选择。我们可以将 F 分为 $F_{motion} and F_{mask}$。
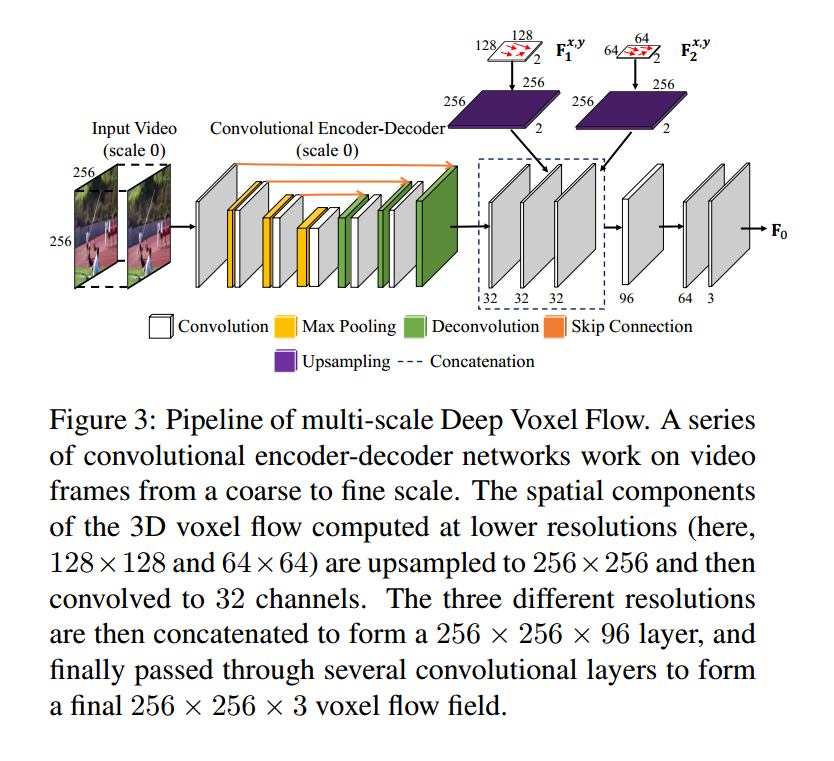
Network Architecture.
DVF 由 一个完整的 全卷积 encoder-decoder architecture, 包括三个卷积层,三个反卷积层 和 一个 bottleneck layer。
1. Learning
网络训练的目标函数为:
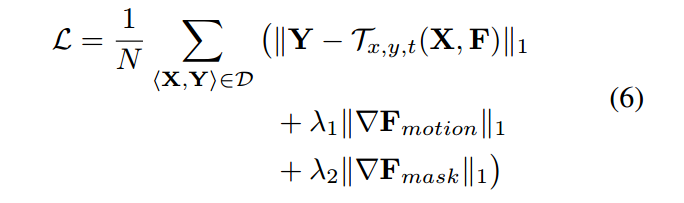
其中,D 是所有视频三元组的 训练集合,N 是对应的基数,Y 是需要重构的 target frame。
$||F_{motion}||_1$ 是 在 (x, y)上的 total variation term ;
$||F_{mask}||_1$ 是 the regularizer on the temporal component of voxel flow。
2. Multi-scale Flow Fusion.
3. Multi-step Prediction.
Video Frame Synthesis using Deep Voxel Flow 论文笔记的更多相关文章
- Research Guide for Video Frame Interpolation with Deep Learning
Research Guide for Video Frame Interpolation with Deep Learning This blog is from: https://heartbeat ...
- 《StackGAN: Text to Photo-realistic Image Synthesis with Stacked GAN》论文笔记
出处:arxiv 2016 尚未出版 Motivation 根据文字描述来合成相片级真实感的图片是一项极具挑战性的任务.现有的生成手段,往往只能合成大体的目标,而丢失了生动的细节信息.StackGAN ...
- [CVPR 2016] Weakly Supervised Deep Detection Networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 } p. ...
- 【医学影像】《Identifying Medical Diagnoses and Treatable Diseases by Image-Based Deep Learning》论文笔记
这篇论文的作者是张康教授为首的团队,联合国内外众多医院及科研机构,合力完成,最后发表在cell上,实至名归. 从方法的角度上来说,与上一篇博客中的论文很相似,采用的都是InceptionV3模型,同时 ...
- Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记
Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记 arXiv 摘要:本文提出了一种 DRL 算法进行单目标跟踪 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
- 论文笔记(1):Deep Learning.
论文笔记1:Deep Learning 2015年,深度学习三位大牛(Yann LeCun,Yoshua Bengio & Geoffrey Hinton),合作在Nature ...
随机推荐
- css解决无论页面长短footer永远置底
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- map 的用法
#include<iostream> #include<map> #include<string> #define s second #define f first ...
- Java多线程-----原子变量和CAS算法
原子变量 原子变量保证了该变量的所有操作都是原子的,不会因为多线程的同时访问而导致脏数据的读取问题 Java给我们提供了以下几种原子类型: AtomicInteger和Ato ...
- plsql连接远程oracle数据库
1.在oracle安装目录D:\app\Eric\product\11.2.0\dbhome_1\NETWORK\ADMIN找到tnsnames.ora:2.ORCL =(DESCRIPTION = ...
- Spring tokenizeToStringArray
tokenizeToStringArray: StringUtils.tokenizeToStringArray(pattern, this.pathSeparator, this.trimToken ...
- ssh 免登录
1. 生成 ssh 公钥和私钥 xiluhua@vm-xiluhua ~ $ ssh-keygen Generating public/private rsa key pair. Enter file ...
- HttpServletRequestWrapper
1). why 需要改变从 Servlet 容器 (可能是任何的 Servlet 容器)中传入的 HttpServletRequest 对象的某个行为,该怎么办? 一. 继承 HttpServletR ...
- localstorage跨域解决方案
localstorage也存在 跨域的问题, [解决思路如下] 在A域和B域下引入C域,所有的读写都由C域来完成,本地数据存在C域下; 因此 A哉和B域的页面必定要引入C域的页面; 当然C域最好是主域 ...
- 阿里云部署Java web项目
林炳文Evankaka原创作品.转载请注明出处http://blog.csdn.net/evankaka 摘要:本文主要讲了如何在阿里云上安装JDK.Tomcat以及其配置过程.最后以一个实例来演示在 ...
- java基础之包装类型
包装类型引入该类型的原因: 因为基本数据类型不具备对象的特性,不能调用方法,所以有时需要将其转换为包装类. 包装类型有两大类方法: 1.将本类型和其它基本类型进行转换方法. ...