Hadoop生态集群之HDFS
一、HDFS是什么
HDFS是hadoop集群中的一个分布式的我文件存储系统。他将多台集群组建成一个集群,进行海量数据的存储。为超大数据集的应用处理带来了很多便利。
和其他的分布式文件存储系统相比他有以下优点:
高容错:即在HDFS运行过程中,若其中一台机器宕机了,也无需担心数据的丢失,因为在存储的过程中进行了备份,备份数量可以选择,这个将在后面的博客说明。
成本低:即使配置条件不足的情况下,都可以搭建一个HDFS,对硬件的要求不高。
易扩展:若出现集群容量不足的情况,直接添加机器,进行配置即可,无需太麻烦的操作。
高吞吐量:HDFS能够提供比较吞吐量的数据访问,这里是访问不是修改
在满足以上有点的同时,也存在一些不足:
对于对数据的访问时间要求较高的情况时,HDFS并没有什么优势。
不利于同时有大量的用用户进行文件的修改操作。
二、HDFS的平台搭建
搭建HDFS集群的方式有很多种,目前在企业工作中应用较多的是通过cloudera manager来对整个hadoop集群进行搭建,同时提供一整套的监控平台进行监控,大大提高了维护成本。但是对于初学者来说还是进行源码的方式安装
这样有助于大家更加深入的了解HDFS的工作原理和配置参数的作用,小编在这就通过这种方式进行安装,当然如果有兴趣的读者,我会在接下来的时间通过cloudera manager的方式进行搭建。
搭建准备:注意这是在linux机器上进行搭建,如对如何配置linux环境的同学不动的话,可以在网上进行搜索,小编也会更新博文给大家提供便利。
主机名:hdp- 对应的ip地址:192.168.33.61
主机名:hdp- 对应的ip地址:192.168.33.62
主机名:hdp- 对应的ip地址:192.168.33.63
主机名:hdp- 对应的ip地址:192.168.33.64
第一步:关闭防火墙
[root@hdp1 ~]# service iptables stop # 临时关闭
[root@hdp1 ~]# chkconfig iptables off # 关闭防火墙开机自动启动
第二步:安装jdk,因为hdfs是通过java语言开发的,所以需要我们安装java的运行环境
jdk下载地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
下载对应版本:我这里下载的是 ,并解压:对应整个集群环境,为了方便管理可以将安装包上传到 /usr/local/src下面
tar -zxvf jdk-8u191-linux-x64.tar.gz
三、HDFS数据存储原理
要了解HDFS数据的存储原理,就必须知道HDFS的工作原理,通过工作原理,我们就可以得出HDFS的数据存储原理。
hdfs有着文件系统共同的特征:
- 有目录结构,顶层目录是: /
- 系统中存放的就是文件,类似于 /wallace/aaa.txt
- 系统可以提供对文件的:创建、删除、修改、查看、移动等功能
hdfs跟普通的单机文件系统有区别:
- 单机文件系统中存放的文件,是在一台机器的操作系统中
- hdfs的文件系统会横跨N多的机器
- 单机文件系统中存放的文件,是在一台机器的磁盘上
- hdfs文件系统中存放的文件,是落在n多机器的本地单机文件系统中(hdfs是一个基于linux本地文件系统之上的文件系统)
hdfs的工作机制:简单的讲,hdfs是分布式的文件存储系统,它可以将一个大的文件切块,将这些块存储在不同的服务器上。
1、客户把一个文件存入hdfs,其实hdfs会把这个文件切块后,分散存储在N台linux机器系统中(负责存储文件块的角色:datanode)<准确来说:切块的行为是由客户端决定的>,切块的大小,切块的副本数这些都可以由
客户端进行指定,若没有进行指定,则HDFS会自动加载配置文件中配置的信息,进行切块大小,副本数量信息。
2、一旦文件被切块存储,那么,hdfs中就必须有一个机制,来记录用户的每一个文件的切块信息,及每一块的具体存储机器(负责记录块信息的角色是:name node),这样可以方便客户端在访问hdfs文件系统时准确的
找到每一块文件存储在哪些节点上,将切块的数据进行归整,同时他又可以合理的控制磁盘IO问题。
3、为了保证数据的安全性,hdfs可以将每一个文件块在集群中存放多个副本,保证当其中一台机器宕机后,namenode可以通过记录的副本信息找到切块的文件。(到底存几个副本,是由当时存入该文件的客户端指定的)
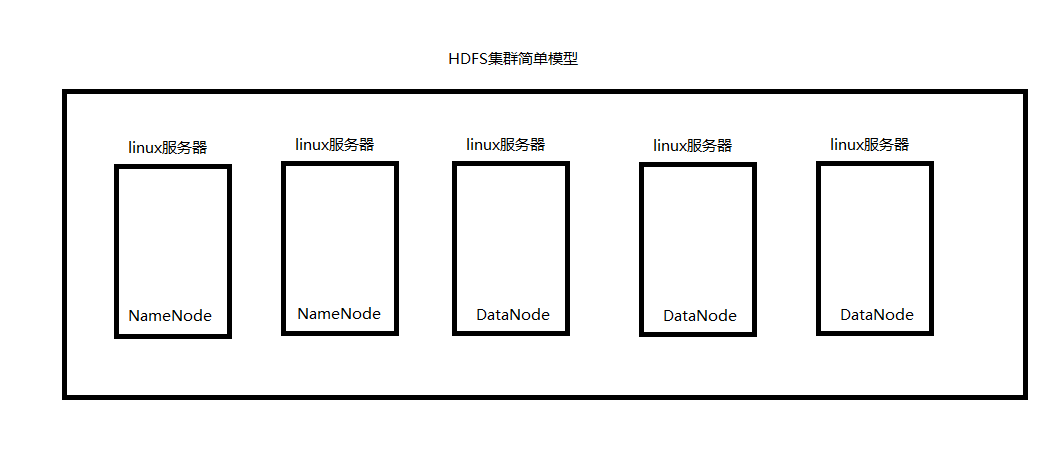
综述:一个hdfs系统,由一台运行了namenode的服务器,和N台运行了datanode的服务器组成!
如下图所示,就是一个简单的HDFS分布式文件系统的模型:
存储文件的详情:请看下图
HDFS文件存储信息: 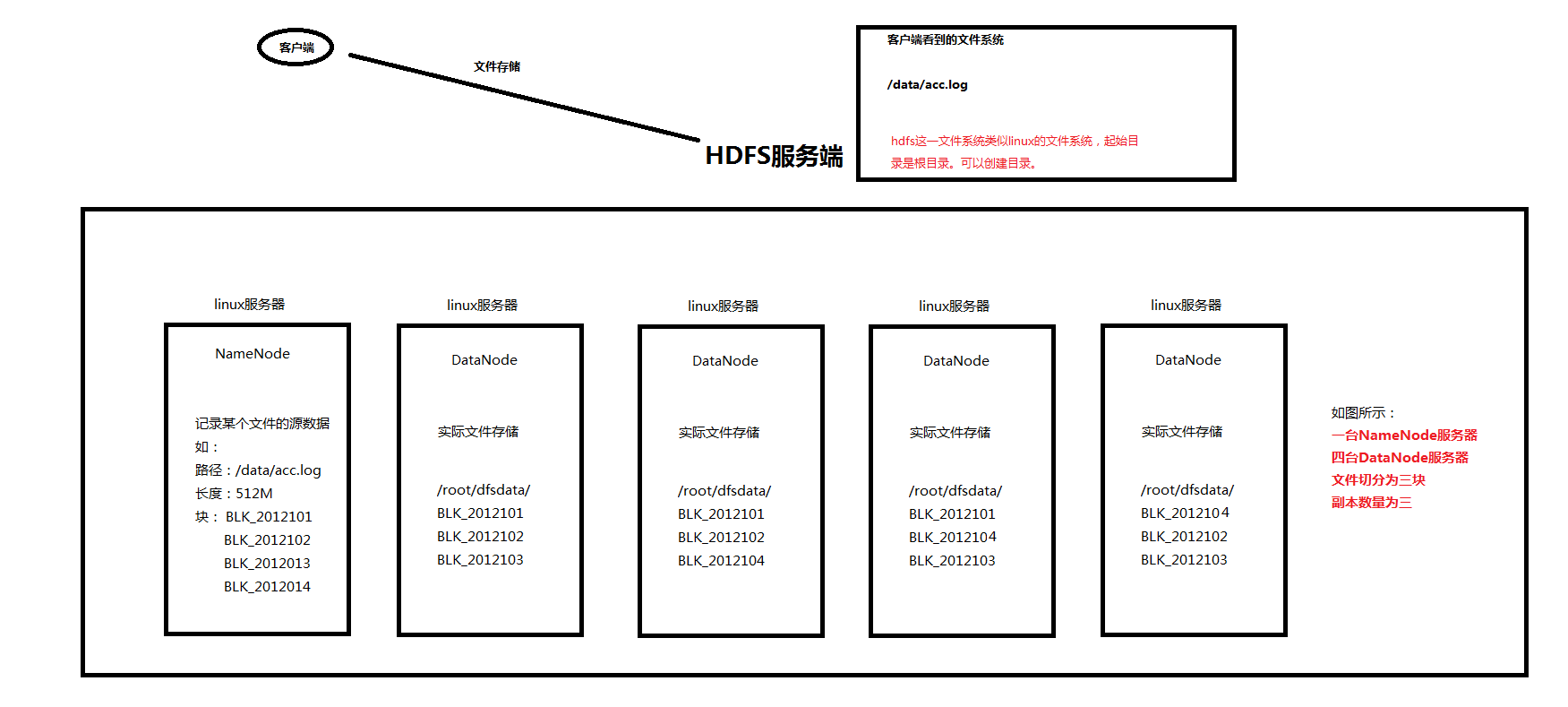
1、hdfs客户端与服务端进行交互,将文件存储在hdfs集群中。
2、hdfs服务端将客户端传来的文件,根据参数进行切块、复制,并将这些块存储在hdfs的datanode节点中。
3、hdfs的namenode节点记录某个文件的元数据(元数据包含文件大小,文件路径,文件块存储在哪个地方,副本信息等)
HDFS读取数据流程如下图:
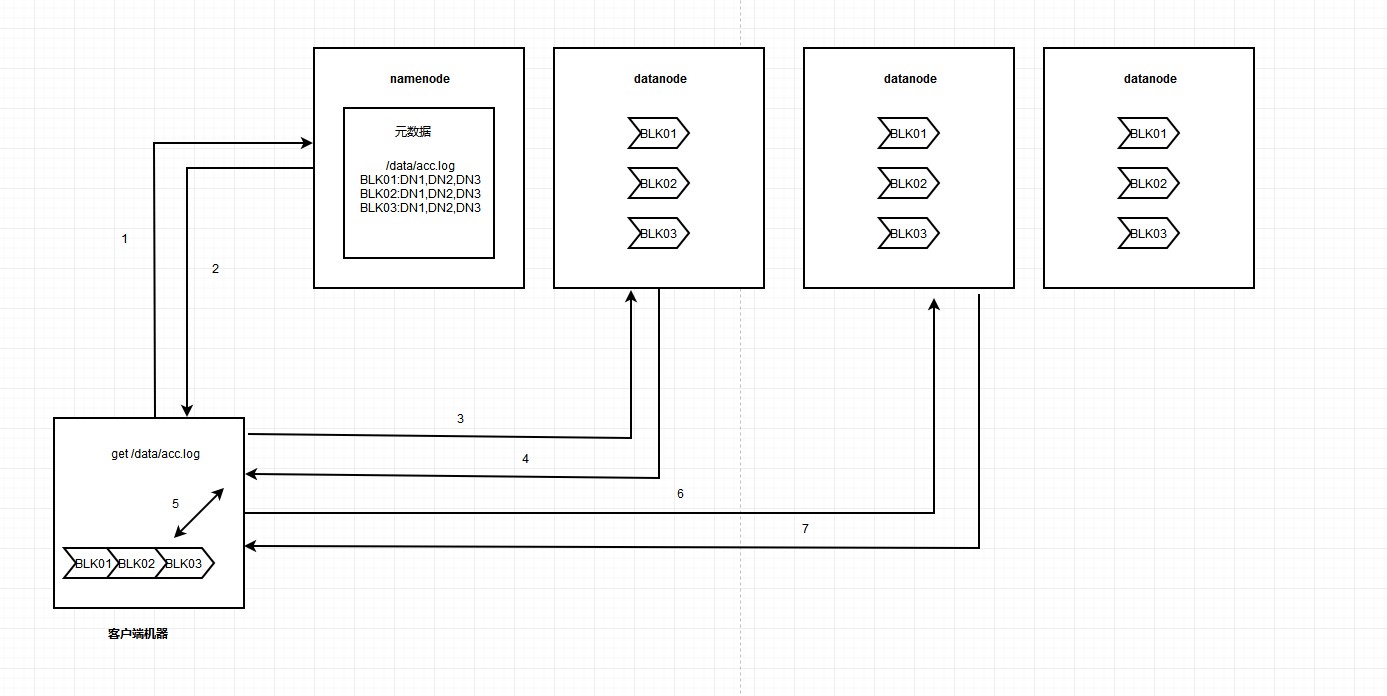
读取流程介绍:
1、hdfs客户端请求读取数据 get /data/acc.log
2、namenode收到消息,返回对应文件的元数据信息
3、根据对应的元数据信息,向datanode请求读取文件块
4、数据块先是以文本输入流的形式输入到网络,然后通过网络输出流发送到客户端机器。
5、接收到网路输入流数据,然后通过本地文本输出流写入文件块1。
6-7重复3-4-5的步骤,最终得到完整的文件。
HDFS写数据流程数据流程如下图:
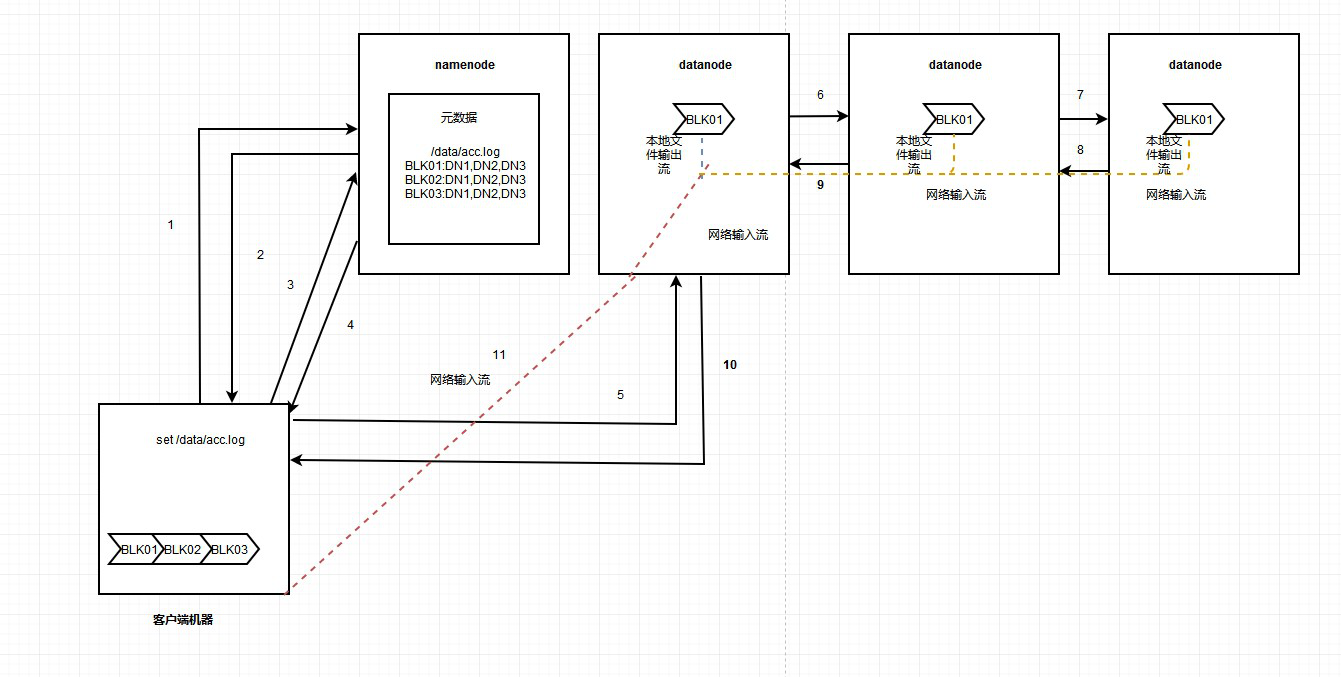
hdfs写数据流程详解:
1、hdfs客户端发送请求,要求写入文件。
2、namenode告知客户端可以进行写入。
3、client请求写入第一个block
4、namenode返回可以进行写的主机,这个主机的数量是根据定的副本数来进行判断,并且返回的datanode容量是相对平均的。
5、client挑选一个datanode,请求建立传输数据链接。
6-7,datanode之间建立传输数据链接。
8-10,响应之前的请求,即数据链接没问题,可以进行传输。
11,通过网络输入流进行客户端和datanode以及datanode和datanode之间的数据传输,到达datanode时也会以本地文件输出流的形式将文件写入。
12、重复3-11的操作,进行剩余文件块的写入。
13、数据写完后通知namenode, 它会确认并记录元数据。
HDFS的namenode和secondarynamenode
通过上面的分析,我们知道namenode是用来保存文件的元数据的,这些元数据包含文件存储路径,块信息等,但是当我们启动hdfs时还有另一个进程就是secondarynamenode,很多人以为secondary是第二
个namenode,其实不是这样的。secondarynamenode是用来同步namenode日志文件的。如下图所示:该图非原创
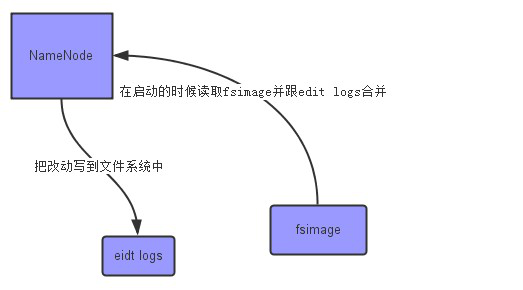
hdfs的namenode节点上有比较重要文件,就是fsimage和edit logs文件:
fsimage:镜像文件,可以理解为linux的虚拟机的快照,在启动namenode时会把改文件加载到内存。
eidt logs:hdfs文件变更记录文件,当有文件发生变更是,就会进行日志记录。
namenode的实时的完整的元数据存储在内存中;namenode还会在磁盘中(dfs.namenode.name.dir)存储内存元数据在某个时间点上的镜像文件(fsimage);
namenode会把引起元数据变化的客户端操作记录在edits日志文件中,namenode会下载edits文件导fsimage中。
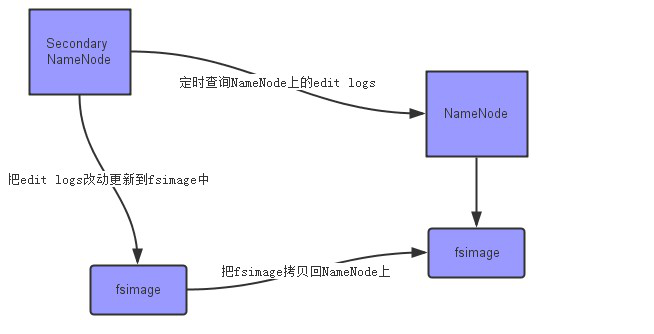
secondarynamenode会定期从namenode上下载fsimage镜像和新生成的edits日志,然后加载fsimage镜像到内存中,然后顺序解析edits文件,对内存中的元数据对象进行修改(整合)
整合完成后,将内存元数据序列化成一个新的fsimage,并将这个fsimage镜像文件上传给namenode。
如下图所示:
四、hdfs的shell命令
查看hdfs的目录信息:
hadoop fs -ls / #这里是根目录,其他目录只需要换路径即可
上传本地文件到hdfs
hadoop fs -copyFromLocal 本地文件路径 hdfs路径 ## copyFromLocal 等价于 put
hadoop fs -put 本地文件路径 hdfs路径
hadoop fs -moveFromLocal 本地文件路径 hdfs路径 ## 这里是把本地文件移动到hdfs上
下载文件到客户端的本地磁盘
hadoop fs -get hdfs中的路径 本地路径
hadoop fs -copyToLocal hdfs路径 本地路径 ## 和get等价
hadoop fs -moveToLocal hdfs路径 本地路径 ## 移动至本地
创建hdfs文件夹
hadoop fs -mkdir -p /aaa/xxx # 这里是递归创建
移动hdfs的文件(更名)
hadoop fs -mv hdfs路径 hdfs路径
删除hdfs中的文件和文件夹
hadoop fs -rm -r /aaa
修改文件权限
hadoop fs -chown user:group /aaa
hadoop fs -chown 700 /aaa
追加内容到已存在的文件
hadoop fs -appendToFile 本地路径 hafs中的路径
显示文件文件的内容
hadoop fs -cat hdfs路径
hadoop fs -tail hdfs路径
所有其他命令:
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-x] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
三、HDFS配置参数解析
hdfs-site.xml 参数配置
– dfs.name.dir
NameNode 元数据存放位置
默认值:使用core-site.xml中的hadoop.tmp.dir/dfs/name – dfs.block.size
对于新文件切分的大小,单位byte。默认是64M,建议是128M,根据需要确定。每一个节点都要指定,包括客户端。
默认值:67108864
– dfs.data.dir
DataNode在本地磁盘存放block的位置,可以是以逗号分隔的目录列表,DataNode循环向磁盘中写入数据,每个DataNode可单独指定与其它DataNode不一样
默认值:${hadoop.tmp.dir}/dfs/data – dfs.namenode.handler.count
NameNode用来处理来自DataNode的RPC请求的线程数量
建议设置为DataNode数量的10%,一般在10~200个之间
如设置太小,DataNode在传输数据的时候日志中会报告“connecton refused"信息
在NameNode上设定
默认值: – dfs.datanode.handler.count
DataNode用来连接NameNode的RPC请求的线程数量
取决于系统的繁忙程度
设置太小会导致性能下降甚至报错
在DataNode上设定
默认值: – dfs.datanode.max.xcievers
DataNode可以同时处理的数据传输连接数
默认值:
建议值: – dfs.permissions
如果是true则检查权限,否则不检查(每一个人都可以存取文件)
于NameNode上设定
默认值:true – dfs.datanode.du.reserved
在每个卷上面HDFS不能使用的空间大小
在每个DataNode上面设定
默认值:
建议为10737418240,即10G。需要结合MapReduce场景设置。 – dfs.datanode.failed.volumes.tolerated
DataNode可以容忍损块的磁盘数量,超过这个数量DataNode将会离线,所有在这个节点上面的block将会被重新复制
默认是0,但是在有多块磁盘的时候一般会增大这个值
– dfs.replication
在文件被写入的时候,每一块将要被复制多少份
默认是3份。建议3份
在客户端上设定
通常也需要在DataNode上设定 、HDFS core-site.xml 参数配置 – fs.default.name
文件系统的名字。通常是NameNode的hostname与port
需要在每一个需要访问集群的机器上指定,包括集群中的节点
例如:hdfs://<your_namenode>:9000/ – fs.checkpoint.dir
以逗号分隔的文件夹列表,SecondNameNode用来存储checkpoint image文件
如果多于一个文件夹,那么都会被写入数据
需要在SecondNameNode上设定
默认值:${hadoop.tmp.dir}/dfs/namesecondary – hadoop.tmp.dir
HDFS与本地磁盘的临时文件
默认是/tmp/hadoop-${user.name}.需要在所有的节点中设定
– fs.trash.interval
当一个文件被删掉后,它会被放到用户目录的.Trash目录下,而不是立即删掉
经过此参数设置的分钟数之后,再删掉数据
默认是0,禁用此功能,建议1440(一天) – io.file.buffer.size
设定在读写数据时的缓存大小,应该为硬件分页大小的2倍
默认是4096,建议为65536 ( 64K) 、设置log文件的大小和数量
修改core-site.xml中的参数
hadoop.logfile.size
hadoop.logfile.count 、设置组件的日志级别
• 查看不同组件的日志级别
– hadoop daemonlog -getlevel host:port packageName
• 设置组件的日志级别
hadoop daemonlog –setlevle host:port packageName level
hadoop daemonlog -setlevel db74: org.apache.hadoop ERROR
• DEBUG, INFO, ERROR, FATAL
– 端口为前台页面的端口,缺省为50070
• 组件名称(packageName)
org.apache.hadoop.hdfs.server.namenode.NameNode
org.apache.hadoop.hdfs.server.datanode.DataNode
org.apache.hadoop.hdfs
org.apache.hadoop
org.apache.hadoop.mapred.JobTracker
重要程度由低到高依次为DEBUG < INFO < WARN < ERROR < FATAL。日志输出规则为:只输出级别不低于设定级别的日志信息。比如,级别设定为INFO,则INFO、WARN、ERROR和FATAL 级别的日志信息都会被输出,
但级别比INFO 低的DEBUG 则不会被输出。DEBUG为测试,INFO为默认,一般生产用,ERROR错误, 、hdfs的进程节点
.namenode
记录源数据的命名空间
数据分配到那些datanode保存
协调客户端对文件访问
.datanode
负责所在物理节点的储存管理
一次写入,多次读取(不能修改)
文件由数据块组成,典型的块大小是64M
数据块尽量散步到各个节点 .secondarynamenode (辅助)
当NameNode重启的时候,会合并硬盘上的fsimage文件和edits文件,得到完整的Metadata信息。这个fsimage文件可以看做是一个过时的Metadata信息文件(最新的Metadata修改信息在edits文件中)。
如果edits文件非常大,那么这个合并过程就非常慢,导致HDFS长时间无法启动,如果定时将edits文件合并到fsimage,那么重启NameNode就可以非常快。SecondaryNameNode就做这个合并的工作。 、hdfs的回收站功能
删除文件时,其实是放入回收站/trash ,回收站里的文件可以快速恢复
可以设置一个时间阈值,当回收站里文件的存放时间超过这个阈值,就被彻底删除, 并且释放占用的数据块 (开启回收站功能)
[hadoop@h1 ~]$ cd /usr/local/hadoop-1.2./conf
[hadoop@h1 conf]$ vi core-site.xml (添加下面一段,10080为保留时间,单位分钟)
<property>
<name>fs.trash.interval</name>
<value></value>
<description>
Number of minutes between trashcheckpoints.
If zero, the trash feature is disabted
</description>
</property>
[hadoop@h1 hadoop-1.2.]$ bin/start-all.sh (重启 回收站功能生效)
常见hdfs端口信息:
| 参数 | 描述 | 默认 | 配置文件 | 例子值 |
| fs.default.name namenode | namenode RPC交互端口 | 8020 | core-site.xml | hdfs://master:8020/ |
| dfs.http.address | NameNode web管理端口 | 50070 | hdfs- site.xml | 0.0.0.0:50070 |
| dfs.datanode.address | datanode 控制端口 | 50010 | hdfs -site.xml | 0.0.0.0:50010 |
| dfs.datanode.ipc.address | datanode的RPC服务器地址和端口 | 50020 | hdfs-site.xml | 0.0.0.0:50020 |
| dfs.datanode.http.address | datanode的HTTP服务器和端口 | 50075 | hdfs-site.xml | 0.0.0.0:50075 |
MR端口信息:
| 参数 | 描述 | 默认 | 配置文件 | 例子值 |
| mapred.job.tracker | job-tracker交互端口 | 8021 | mapred-site.xml | hdfs://master:8021/ |
| job | tracker的web管理端口 | 50030 | mapred-site.xml | 0.0.0.0:50030 |
| mapred.task.tracker.http.address | task-tracker的HTTP端口 | 50060 | mapred-site.xml | 0.0.0.0:50060 |
其它端口
| 参数 | 描述 | 默认 | 配置文件 | 例子值 |
| dfs.secondary.http.address | secondary NameNode web管理端口 | 50090 | hdfs-site.xml | 0.0.0.0:50090 |
hdfs-default.html的默认配置信息
| 序号 | 参数名 | 参数值 | 参数说明 |
| 1 | dfs.namenode.logging.level | info | 输出日志类型 |
| 2 | dfs.secondary.http.address | 0.0.0.0:50090 | 备份名称节点的http协议访问地址与端口 |
| 3 | dfs.datanode.address | 0.0.0.0:50010 | 数据节点的TCP管理服务地址和端口 |
| 4 | dfs.datanode.http.address | 0.0.0.0:50075 | 数据节点的HTTP协议访问地址和端口 |
| 5 | dfs.datanode.ipc.address | 0.0.0.0:50020 | 数据节点的IPC服务访问地址和端口 |
| 6 | dfs.datanode.handler.count | 3 | 数据节点的服务连接处理线程数 |
| 7 | dfs.http.address | 0.0.0.0:50070 | 名称节点的http协议访问地址与端口 |
| 8 | dfs.https.enable | false | 支持https访问方式标识 |
| 9 | dfs.https.need.client.auth | false | 客户端指定https访问标识 |
| 10 | dfs.https.server.keystore.resource | ssl-server.xml | Ssl密钥服务端的配置文件 |
| 11 | dfs.https.client.keystore.resource | ssl-client.xml | Ssl密钥客户端的配置文件 |
| 12 | dfs.datanode.https.address | 0.0.0.0:50475 | 数据节点的HTTPS协议访问地址和端口 |
| 13 | dfs.https.address | 0.0.0.0:50470 | 名称节点的HTTPS协议访问地址和端口 |
| 14 | dfs.datanode.dns.interface | default | 数据节点采用IP地址标识 |
| 15 | dfs.datanode.dns.nameserver | default | 指定DNS的IP地址 |
| 16 | dfs.replication.considerLoad | true | 加载目标或不加载的标识 |
| 17 | dfs.default.chunk.view.size | 32768 | 浏览时的文件块大小设置为32K |
| 18 | dfs.datanode.du.reserved | 0 | 每个卷预留的空闲空间数量 |
| 19 | dfs.name.dir | ${hadoop.tmp.dir}/dfs/name | 存贮在本地的名字节点数据镜象的目录,作为名字节点的冗余备份 |
| 20 | dfs.name.edits.dir | ${dfs.name.dir} | 存贮文件操作过程信息的存贮目录 |
| 21 | dfs.web.ugi | webuser,webgroup | Web接口访问的用户名和组的帐户设定 |
| 22 | dfs.permissions | true | 文件操作时的权限检查标识。 |
| 23 | dfs.permissions.supergroup | supergroup | 超级用户的组名定义 |
| 24 | dfs.block.access.token.enable | false | 数据节点访问令牌标识 |
| 25 | dfs.block.access.key.update.interval | 600 | 升级访问钥时的间隔时间 |
| 26 | dfs.block.access.token.lifetime | 600 | 访问令牌的有效时间 |
| 27 | dfs.data.dir | ${hadoop.tmp.dir}/dfs/data | 数据节点的块本地存放目录 |
| 28 | dfs.datanode.data.dir.perm | 755 | 数据节点的存贮块的目录访问权限设置 |
| 29 | dfs.replication | 3 | 缺省的块复制数量 |
| 30 | dfs.replication.max | 512 | 块复制的最大数量 |
| 31 | dfs.replication.min | 1 | 块复制的最小数量 |
| 32 | dfs.block.size | 67108864 | 缺省的文件块大小为64M |
| 33 | dfs.df.interval | 60000 | 磁盘空间统计间隔为6秒 |
| 34 | dfs.client.block.write.retries | 3 | 块写入出错时的重试次数 |
| 35 | dfs.blockreport.intervalMsec | 3600000 | 块的报告间隔时为1小时 |
| 36 | dfs.blockreport.initialDelay | 0 | 块顺序报告的间隔时间 |
| 37 | dfs.heartbeat.interval | 3 | 数据节点的心跳检测间隔时间 |
| 38 | dfs.namenode.handler.count | 10 | 名称节点的连接处理的线程数量 |
| 39 | dfs.safemode.threshold.pct | 0.999f | 启动安全模式的阀值设定 |
| 40 | dfs.safemode.extension | 30000 | 当阀值达到量值后扩展的时限 |
| 41 | dfs.balance.bandwidthPerSec | 1048576 | 启动负载均衡的数据节点可利用带宽最大值为1M |
| 42 | dfs.hosts | 可与名称节点连接的主机地址文件指定。 | |
| 43 | dfs.hosts.exclude | 不充计与名称节点连接的主机地址文件设定 | |
| 44 | dfs.max.objects | 0 | 文件数、目录数、块数的最大数量 |
| 45 | dfs.namenode.decommission.interval | 30 | 名称节点解除命令执行时的监测时间周期 |
| 46 | dfs.namenode.decommission.nodes.per.interval | 5 | 名称节点解除命令执行是否完检测次数 |
| 47 | dfs.replication.interval | 3 | 名称节点计算数据节点的复制工作的周期数. |
| 48 | dfs.access.time.precision | 3600000 | 充许访问文件的时间精确到1小时 |
| 49 | dfs.support.append | false | 是否充许链接文件指定 |
| 50 | dfs.namenode.delegation.key.update-interval | 86400000 | 名称节点上的代理令牌的主key的更新间隔时间为24小时 |
| 51 | dfs.namenode.delegation.token.max-lifetime | 604800000 | 代理令牌的有效时间最大值为7天 |
| 52 | dfs.namenode.delegation.token.renew-interval | 86400000 | 代理令牌的更新时间为24小时 |
| 53 | dfs.datanode.failed.volumes.tolerated | 0 | 决定停止数据节点提供服务充许卷的出错次数。0次则任何卷出错都要停止数据节点 |
好了,以上就是对hdfs的一个总结,希望大家多多指正,共同进步。最后赠送大家一碗鸡汤:越努力的人运气越好。
Hadoop生态集群之HDFS的更多相关文章
- Hadoop生态集群hdfs原理(转)
初步掌握HDFS的架构及原理 原文地址:https://www.cnblogs.com/codeOfLife/p/5375120.html 目录 HDFS 是做什么的 HDFS 从何而来 为什么选 ...
- Hadoop生态集群YARN详解
一,前言 Hadoop 2.0由三个子系统组成,分别是HDFS.YARN和MapReduce,其中,YARN是一个崭新的资源管理系统,而MapReduce则只是运行在YARN上的一个应用,如果把YAR ...
- Hadoop生态集群MapReduce详解
一.概述 MapReduce是一种编程模型,这点很重要,仅仅是一种编程的模型,而不是具体的软件.在hadoop中,HDFS是分布式的文件存储系统,而MapReduce是一个分布式的计算框架.用于大规模 ...
- Hadoop集群(二) HDFS搭建
HDFS只是Hadoop最基本的一个服务,很多其他服务,都是基于HDFS展开的.所以部署一个HDFS集群,是很核心的一个动作,也是大数据平台的开始. 安装Hadoop集群,首先需要有Zookeeper ...
- 格式化hdfs后,hadoop集群启动hdfs,namenode启动成功,datanode未启动
集群格式化hdfs后,在主节点运行启动hdfs后,发现namenode启动了,而datanode没有启动,在其他节点上jps后没有datanode进程!原因: 当我们使用hdfs namenode - ...
- Hadoop HA集群 与 开发环境部署
每一次 Hadoop 生态的更新都是如此令人激动 像是 hadoop3x 精简了内核,spark3 在调用 R 语言的 UDF 方面,速度提升了 40 倍 所以该文章肯定得配备上最新的生态 hadoo ...
- hadoop的集群安装
hadoop的集群安装 1.安装JDK,解压jar,配置环境变量 1.1.解压jar tar -zxvf jdk-7u79-linux-x64.tar.gz -C /opt/install //将jd ...
- 大数据系列之Hadoop分布式集群部署
本节目的:搭建Hadoop分布式集群环境 环境准备 LZ用OS X系统 ,安装两台Linux虚拟机,Linux系统用的是CentOS6.5:Master Ip:10.211.55.3 ,Slave ...
- 基于Hadoop分布式集群YARN模式下的TensorFlowOnSpark平台搭建
1. 介绍 在过去几年中,神经网络已经有了很壮观的进展,现在他们几乎已经是图像识别和自动翻译领域中最强者[1].为了从海量数据中获得洞察力,需要部署分布式深度学习.现有的DL框架通常需要为深度学习设置 ...
随机推荐
- C# HTTPServer和OrleansClient结合
using System; using System.Collections.Generic; using System.IO; using System.IO.Compression; using ...
- rxjs 常用的管道操作符
操作符文档 api 列表 do -> tap catch -> catchError switch -> switchAll finally -> finalize map s ...
- jenkins管理
1.1 重启,重载,关闭 http://10.0.0.51:8080/jenkins/restart 重启 http://10.0.0.51:8080/jenkins/reload ...
- http://linux-mtd.infradead.org/doc/nand.html nand
http://linux-mtd.infradead.org/doc/nand.html
- iOS10原生的语音转文字功能
#import <Foundation/Foundation.h> #import <Speech/Speech.h> @interface SpeechListener : ...
- UTF8 、unicode 和 Ascii2
1.http://blog.renren.com/share/68464/3096404244
- dp的斜率优化
对于刷题量我觉得肯定是刷的越多越好(当然这是对时间有很多的人来说. 但是在我看来我的确适合刷题较多的那一类人,应为我对知识的应用能力并不强.这两天学习的内容是dp的斜率优化.当然我是不太会的. 这个博 ...
- LeetCode 812 Largest Triangle Area 解题报告
题目要求 You have a list of points in the plane. Return the area of the largest triangle that can be for ...
- 20165225《Java程序设计》第六周学习总结
20165225<Java程序设计>第六周学习总结 1.视频与课本中的学习: - 第八章学习总结 String类 String对象(常量,对象) 字符串并置(结果仍是常量) 常用方法 le ...
- 【Python爬虫】正则表达式与re模块
正则表达式与re模块 阅读目录 在线正则表达式测试 常见匹配模式 re.match re.search re.findall re.compile 实战练习 在线正则表达式测试 http://tool ...