《软件测试自动化之道》读书笔记 之 XML测试
《软件测试自动化之道》读书笔记 之 XML测试
2014-10-07
待测程序
测试程序
通过XmlTextReader解析XML
通过XmlDocument解析XML
通过XmlPathDocument解析XML
通过XmlSerializer解析XML
通过DataSet解析XML
通过XSD Schema对XML文件进行验证
通过XSLT对XML文件进行修改
通过XmlTextWrite对XML文件进行写操作
比较两个XML文件是否严格相等
不考虑编码方式,比较两个XML文件是否严格相等
比较两个XML文件的规范等价性
示例代码
待测程序
‘testCases.xml’示例代码:
<?xml version="1.0" encoding="utf-8" ?>
<suite>
<testcase id="001" bvt="yes">
<inputs>
<arg1>red</arg1>
<arg2>blue</arg2>
</inputs>
<expected>purple</expected>
</testcase> <testcase id="002" bvt="no">
<inputs>
<arg1>blue</arg1>
<arg2>yellow</arg2>
</inputs>
<expected>green</expected>
</testcase> <testcase id="003" bvt="yes">
<inputs>
<arg1>white</arg1>
<arg2>black</arg2>
</inputs>
<expected>gray</expected>
</testcase>
</suite>
测试程序
本章给出5种解析技术,都是把‘testCases.xml’解析成测试用例Suite对象,Suite的定义如下:
namespace Utility
{
public class TestCase
{
public string id;
public string bvt;
public string arg1;
public string arg2;
public string expected;
} public class Suite
{
public System.Collections.ArrayList cases = new System.Collections.ArrayList();
public void Display()
{
foreach (TestCase tc in cases)
{
Console.WriteLine(tc.id + " " + tc.bvt + " " + tc.arg1 + " " + tc.arg2 + " " + tc.expected);
}
}
}
}
通过XmlTextReader解析XML
示例代码:
private static void ParseByXMLTextReader(Utility.Suite suite, string tcPath)
{
XmlTextReader xtr = new XmlTextReader(tcPath);
xtr.WhitespaceHandling = WhitespaceHandling.None;
xtr.Read(); //read xml declaration, move to tag<suite> while (!xtr.EOF)
{
if (xtr.Name == "suite" && !xtr.IsStartElement()) break;
while (xtr.Name != "testcase" || !xtr.IsStartElement())
xtr.Read(); //move to tag<testcase> Utility.TestCase tc = new Utility.TestCase();
tc.id = xtr.GetAttribute("id");
tc.bvt = xtr.GetAttribute("bvt");
xtr.Read(); //move to tag <inputs>
xtr.Read(); //move to tag <arg1>
tc.arg1 = xtr.ReadElementString("arg1");
tc.arg2 = xtr.ReadElementString("arg2");
xtr.Read(); //move to tag <expected>
tc.expected = xtr.ReadElementString("expected");
//current tag is </testcase>
suite.cases.Add(tc); xtr.Read(); //current tag is <testcase> or </suite>
}
xtr.Close();
}
}
分析:
XmlTextReader把XML 解析成单个的数据片,如下xml:
<?xml version="1.0" encoding="utf-8" ?>
<alpha id="001">
<beta>123</beta>
</alpha>
不计空格,这里共有6个结点:XML声明、<alpha id="001">、<beta>、123、</beta>、</alpha>。
- Read()方法:每次向前读取一个结点。与其它类的Read()不同,该方法并不返回有意义的数据;
- ReadElementString()方法:才会返回单个标签和结尾之间的数据,并向前糯稻标签结束后面的下一个结点。
- EOF属性:判断是否碰到文件结尾
当被解析的XML文件结构相对比较简单并且前后一致,且需要向前进行处理的时候,使用XmlTextReader是 一种直接有效的方法。与本章其他解析技术相比,也是最快的方法。与本章其他解析技术相比,XmlTextReader所进行的操作在比较地的抽象层次上,也就以为这作为程序员,要负责正确跟踪XML文件中的位置和正确调用Read()。
通过XmlDocument解析XML
示例代码:
private static void ParseByXMLDocument(Utility.Suite suite, string tcPath)
{
XmlDocument xd = new XmlDocument();
xd.Load(tcPath); //get all <testcase> nodes
XmlNodeList nodeList = xd.SelectNodes("/suite/testcase");
foreach (XmlNode node in nodeList)
{
Utility.TestCase tc = new Utility.TestCase();
tc.id = node.Attributes.GetNamedItem("id").Value;
tc.bvt = node.Attributes.GetNamedItem("bvt").Value; XmlNode n = node.SelectSingleNode("inputs");
tc.arg1 = n.ChildNodes.Item().InnerText;
tc.arg2 = n.ChildNodes.Item().InnerText;
tc.expected = node.ChildNodes.Item().InnerText; suite.cases.Add(tc);
}
}
分析:
XmlDocument.Load()方法:把整个XML文件读如内存中。XmlDocument对象基于XML结点和子结点的概念。我们不采用顺序的方式遍历XML文件,而是通过SelectNodes()方法选择一组结点,或这通过SelectSingleNode()选择单个的结点。请注意:因为XML文件的attributes和elements之间有着显著的差别,所以我们必须通过Attributes.GetNamedItem()方法得到某个元素结点的id和bvt值。
因为XmlDocument会一次把整个XML文挡读入到内存中,所以对于被解析的XML文件非常大的情况,这种方法并不合适。
通过XmlPathDocument解析XML
示例代码:
private static void ParseByXPathDocument(Utility.Suite suite, string tcPath)
{
System.Xml.XPath.XPathDocument xpd = new XPathDocument(tcPath);
XPathNavigator xpn = xpd.CreateNavigator();
XPathNodeIterator xpi = xpn.Select("/suite/testcase"); while (xpi.MoveNext())
{
Utility.TestCase tc = new Utility.TestCase();
tc.id = xpi.Current.GetAttribute("id", xpn.NamespaceURI);
tc.bvt = xpi.Current.GetAttribute("bvt", xpn.NamespaceURI); XPathNodeIterator tcChild = xpi.Current.SelectChildren(XPathNodeType.Element);
while (tcChild.MoveNext())
{ if (tcChild.Current.Name == "inputs")
{
XPathNodeIterator tcSubChild = tcChild.Current.SelectChildren(XPathNodeType.Element);
while (tcSubChild.MoveNext())
{
if (tcSubChild.Current.Name == "arg1")
tc.arg1 = tcSubChild.Current.Value;
else if (tcSubChild.Current.Name == "arg2")
tc.arg2 = tcSubChild.Current.Value;
}
}
else if (tcChild.Current.Name == "expected")
tc.expected = tcChild.Current.Value; }
suite.cases.Add(tc);
}
}
分析:
- XpathDocument()构造函数:把整个XML文件存入内存。
- XpathNavigator对象的Select()方法:选择XML文挡的一部分
- XpathNodeIterator对象的MoveNext()方法:遍历XpathDocument对象。
- GetAttribut()方法:取得attribute的值
- SelectChildren()方法和Current.Value属性:取得XML元素的值
通过XmlPathDocument对象对XML文件进行解析,给人的感觉是它一部分是过程式的、底层的(类似于XmlTextReader)处理方法,一部分是面向对象的、高层次的(类似于XMLDocument)的处理方法。
XmlPathDocument类是针对XPath数据模型特别优化过的。所以当要解析的XML文件嵌套层次很深、结构很复杂或者需要大范围的查找炒作,这种方法尤为合适。但XmlPathDocument只能对XML文件进行读取,所以如果想对文件在内存中进行直接的操作,这种方法不行。
通过XmlSerializer解析XML
示例代码:
内存结构对应类:
namespace SerializerLib
{
using System.Xml.Serialization; [XmlRootAttribute("suite")]
public class Suite
{
[XmlElementAttribute("testcase")]
public TestCase[] items;
public void Display()
{
foreach(TestCase tc in items)
{
Console.WriteLine(tc.id + " " + tc.bvt + " " + tc.inputs.arg1 + " " + tc.inputs.arg2 + " " + tc.expected);
}
} } public class TestCase
{
[XmlAttributeAttribute()]
public string id;
[XmlAttributeAttribute()]
public string bvt;
[XmlElementAttribute("inputs")]
public Inputs inputs;
public string expected; } public class Inputs
{
public string arg1;
public string arg2;
}
}
ParseByXmlSerializer()方法:
private static void ParseByXmlSerializer(string tcPath)
{
XmlSerializer xs = new XmlSerializer(typeof(SerializerLib.Suite));
StreamReader sr = new StreamReader(tcPath);
SerializerLib.Suite suite = (SerializerLib.Suite)xs.Deserialize(sr);
sr.Close();
suite.Display();
}
分析:
通过XmlSerializer类对XML文件进行解析于其他5中XML解析类有着很大的不同,因为采用这种方法必须很仔细的把存储结构预先准备好。我们注意到把XML加载到内存中的操作只通过下面一个语句就完成了:
SerializerLib.Suite suite = (SerializerLib.Suite)xs.Deserialize(sr);
存储结构可以手工编写一个目标类,也可以通过Visual Studio .NET自带的xsd.exe命令行工具:
首先,执行以下命令(假设testCase.xml位于C盘根目录):
C:\>xsd.exe testCases.xml /o:.
这个命令的意思上创建testCases.xml文件的XSD schema定义并且把结果按照默认名保存到当前目录
然后,执行以下命令:
C:\xsd.exe testCases.xsd /c /o:.
这个命令的意思是使用testCase.xsd定义文件,通过默认的C#语言产生一组于Deserialize()方法兼容的类,并且以默认文件名testCases.cs保存到当前目录。
现在你可以把testCases.cs的代码直接拷贝到测试套间中,稍加修改(比如:去处一些不需要的代码,加一些额外的方法,改名等)
XmlSerialzier类为XML文件的解析提供了一种非常优雅的解决方案。所进行的操作也在最高的抽象层次,也就是说算法的细节大多屏蔽掉了。但也失去了一些对XML处理过程的处理。
通过DataSet解析XML
示例代码:
private static void ParseByDataSet(Utility.Suite suite, string tcPath)
{
DataSet ds = new DataSet();
ds.ReadXml(tcPath); foreach (DataRow row in ds.Tables["testcase"].Rows)
{
Utility.TestCase tc=new Utility.TestCase();
tc.id = row["id"].ToString();
tc.bvt = row["bvt"].ToString();
tc.expected = row["expected"].ToString(); DataRow[] children = row.GetChildRows("testcase_inputs"); //relation name
tc.arg1=(children[]["arg1"]).ToString();
tc.arg2=(children[]["arg2"]).ToString(); suite.cases.Add(tc);
}
}
分析:
ReadXml()方法:把XML文件直接读如一个System.Data.DataSet对象。你可以把DataSet对象想像成一个内存中的关系型数据库。通过DataSet对象对XML进行解析,关键是要理解XML(本质上是层次型的)是如何映射到一组DataTable对象(本质上是平面型的)的。XML源文件的每个层次都会在DataSet中产生一个表。
顶层的<testcase>产生一个名为testcase的DataTable。下一层次<inputs>产生一个名为inputs的DataTable。这时候还会产生一个叫做testcase_inputs的关系对象用来连接DataTable对象。请注意:XML的根结点所在的层次和最低层(本例中即<arg>所表示的数据)并不会产生表。
下面这个‘DisplayInfo’方法的代码提供一些你需要的信息:
public static void DisplayInfo(DataSet ds)
{
foreach (DataTable dt in ds.Tables)
{
Console.WriteLine("\n==========================================");
Console.WriteLine("Table= " + dt.TableName + "\n");
foreach (DataColumn dc in dt.Columns)
Console.Write("{0,-14}", dc.ColumnName);
Console.WriteLine("\n------------------------------------------");
foreach (DataRow dr in dt.Rows)
{
foreach(object data in dr.ItemArray)
Console.Write("{0,-14}", data.ToString());
Console.WriteLine();
}
Console.WriteLine("\n==========================================");
}
foreach (DataRelation dr in ds.Relations)
{
Console.WriteLine("\n\nRelations:");
Console.WriteLine(dr.RelationName+"\n\n");
}
}
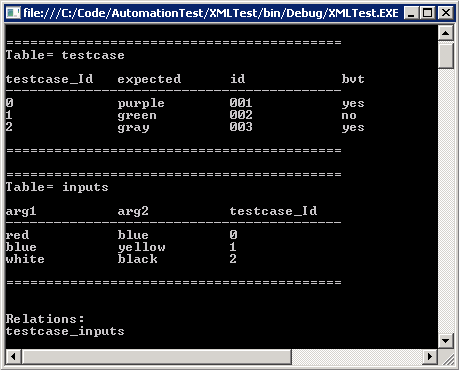
图1 DataSet信息
通过XSD Schema对XML文件进行验证
示例代码:
private static void VerifyByXsdSchema(string tcPath)
{
XmlSchemaCollection xsc = new XmlSchemaCollection();
xsc.Add(null, @"..\..\testCases.xsd");
XmlTextReader xtr = new XmlTextReader(tcPath);
XmlValidatingReader xvr = new XmlValidatingReader(xtr);
xvr.ValidationType = ValidationType.Schema;
xvr.Schemas.Add(xsc);
xvr.ValidationEventHandler += new ValidationEventHandler(ValidationCallBack);
while (xvr.Read()) ; Console.WriteLine("If no error message then XML is valid");
} private static void ValidationCallBack(object sender, ValidationEventArgs ea)
{
Console.WriteLine("Validation error: " + ea.Message);
Console.ReadLine();
}
分析:
通过XmlValidatingReader对象对想要验证的XML文件进行遍历。如果这个文件不是有效的XML文件,程序控制流程转向一个代理方法(delegate method),这个代理方法会打印出错误信息。
通过XmlSchemaCollection对象加载用于验证的schema定义,通过这种方法可以针对XML文件应用多个schema定义。
通过XSLT对XML文件进行修改
‘testCase.xml’原始形式如下:
<?xml version="1.0" encoding="utf-8" ?>
<suite>
<testcase id="001" bvt="yes">
<inputs>
<arg1>red</arg1>
<arg2>blue</arg2>
</inputs>
<expected>purple</expected>
</testcase> <suite>
修改后的版本:
<?xml version="1.0" encoding="utf-8"?>
<allOfTheTestCases>
<aCase caseID="001">
<bvt>yes</bvt>
<expRes>purple</expRes>
<inputs>
<input1>red</input1>
<input2>blue</input2>
</inputs>
</aCase> </allOfTheTestCases>
示例代码:
‘testCasesModifier.xslt’代码:
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:msxsl="urn:schemas-microsoft-com:xslt" exclude-result-prefixes="msxsl"
>
<xsl:output method="xml" indent="yes"/> <xsl:template match="/">
<allOfTheTestCases>
<xsl:for-each select ="//testcase">
<aCase>
<xsl:attribute name="caseID">
<xsl:value-of select ="@id"/>
</xsl:attribute>
<bvt>
<xsl:value-of select="@bvt"/>
</bvt>
<expRes>
<xsl:value-of select="expected"/>
</expRes>
<inputs>
<xsl:for-each select="inputs">
<input1>
<xsl:value-of select="arg1"/>
</input1>
<input2>
<xsl:value-of select="arg2"/>
</input2>
</xsl:for-each>
</inputs>
</aCase>
</xsl:for-each>
</allOfTheTestCases>
</xsl:template>
</xsl:stylesheet>
UpdateXMLByXSLT()方法代码:
private static void UpdateXMLByXSLT(string tcPath)
{
XslTransform xst = new XslTransform();
xst.Load(@"..\..\testCasesModifier.xslt");
xst.Transform(tcPath, @"..\..\testCasesModifier.xml");
Console.WriteLine("Done. New XML file is 'testCasesModifier.xml'");
}
通过XmlTextWrite对XML文件进行写操作
示例代码:
private static void WriteXMLbyXmlTextWrite()
{
string caseID = "";
string result = "Pass";
string whenRun = "10/09/2014";
XmlTextWriter xtw = new XmlTextWriter(@"..\..\Results1.xml", System.Text.Encoding.UTF8);
xtw.Formatting = Formatting.Indented;
xtw.WriteStartDocument();
xtw.WriteStartElement("Results");
xtw.WriteStartElement("result");
xtw.WriteAttributeString("id", caseID);
xtw.WriteStartElement("passfaill");
xtw.WriteString(result);
xtw.WriteEndElement();
xtw.WriteStartElement("whenRun");
xtw.WriteString(whenRun);
xtw.WriteEndElement();
xtw.WriteEndElement();
xtw.WriteEndElement();
xtw.Close();
}
结果‘TestResult1.xml’:
<?xml version="1.0" encoding="utf-8"?>
<Results>
<result id="0001">
<passfaill>Pass</passfaill>
<whenRun>10/09/2014</whenRun>
</result>
</Results>
比较两个XML文件是否严格相等
示例代码:
private static bool XMLExactlySame(string file1,string file2)
{
FileStream fs1 = new FileStream(file1, FileMode.Open);
FileStream fs2 = new FileStream(file2, FileMode.Open); if (fs1.Length != fs2.Length)
return false;
else
{
int b1 = ;
int b2 = ; while ((b1 = fs1.ReadByte()) != -)
{
b2 = fs2.ReadByte();
if (b1 != b2)
{
fs1.Close();
fs2.Close();
return false;
}
}
fs1.Close();
fs2.Close();
return true;
}
}
分析:
通过FileStream对象遍历两个XML文件。一个字节一个字节的读入文件内容,如果某个字节不匹配,则返回false。
不考虑编码方式,比较两个XML文件是否严格相等
示例代码:
private static bool XMLExactlyExceptEncoding(string file1, string file2)
{
FileStream fs1 = new FileStream(file1, FileMode.Open);
FileStream fs2 = new FileStream(file2, FileMode.Open);
StreamReader sr1 = new StreamReader(fs1);
StreamReader sr2 = new StreamReader(fs2); string s1 = sr1.ReadToEnd();
string s2 = sr2.ReadToEnd();
sr1.Close();
sr2.Close();
fs1.Close();
fs2.Close();
return (s1==s2);
}
分析:
编写软件测试时,可能需要对实际的XML文件和期望的XML文件进行比较,而不关心它们的编码机制是否一样。换句话说,如果实际的XML文件和期望的XML文件包含相同的字符数据,只不过编码方式不同(比如:UTF-8,ANSI )。若要考虑编码,可用重载过的==运算符。
比较两个XML文件的规范等价性
第一个XML文件Books1.xml代码如下:
<?xml version="1.0" encoding="utf-8"?>
<books> <book>
<title isbn='1111' storeid="A1A1">
All About Apples
</title>
<author>
<last>Anderson</last>
<first>Adam</first>
</author>
</book>
</books>
第二个XML文件Books2.xml代码如下:
<books>
<book>
<title storeid="A1A1" isbn="1111">
All About Apples
</title>
<author>
<last>Anderson</last>
<first>Adam</first>
</author>
</book>
</books>
示例代码:
private static void XMLCanonicalEquivalence()
{
string file1 = @"..\..\Books1.xml";
string file2 = @"..\..\Books2.xml"; XmlDocument xd1 = new XmlDocument();
xd1.Load(file1); XmlDsigC14NTransform t1 = new XmlDsigC14NTransform(true); //true mean inclue comment t1.LoadInput(xd1);
Stream s1 = t1.GetOutput() as Stream;
XmlTextReader xtr1 = new XmlTextReader(s1);
MemoryStream ms1 = new MemoryStream();
XmlTextWriter xtw1 = new XmlTextWriter(ms1, System.Text.Encoding.UTF8);
xtw1.WriteNode(xtr1, false); //false mean not copy default properties xtw1.Flush();
ms1.Position = ;
StreamReader sr1 = new StreamReader(ms1);
string str1 = sr1.ReadToEnd();
Console.WriteLine(str1); Console.WriteLine("\n==============\n"); XmlDocument xd2 = new XmlDocument();
xd2.Load(file2); XmlDsigC14NTransform t2 = new XmlDsigC14NTransform(true); //true mean inclue comment t2.LoadInput(xd2);
Stream s2 = t2.GetOutput() as Stream;
XmlTextReader xtr2 = new XmlTextReader(s2);
MemoryStream ms2 = new MemoryStream();
XmlTextWriter xtw2 = new XmlTextWriter(ms2, System.Text.Encoding.UTF8);
xtw2.WriteNode(xtr2, false); //false mean not copy default properties xtw2.Flush();
ms2.Position = ;
StreamReader sr2 = new StreamReader(ms2);
string str2 = sr2.ReadToEnd();
Console.WriteLine(str2); if (str1 == str2)
Console.WriteLine("Files cannonically equivalent");
else
Console.WriteLine("Files Not canonically equivalent");
}
分析:
通过XmlDsigC14NTransform类对两个要比较的XML文件实施C14N规范花转换,然后通过两个MemoryStream对象对内存中两个转换后文件进行比较。你可以把规范等价性想像成“从大多数实际应用的角度来看都是相等的”。
上面两个XML文件‘Books1.xml’,‘Bools2.xml’具有规范等价性。两个文件中的空格不影响比较的结果;引号双引号不影响比较的结果;XML声明不影响比较的结果;attributes的顺序不影响比较的结果。
C14N规范等价性是相当复杂的。它是有W3C定义的,主要用于安全领域,XmlDsigC14NTransform类位于System.Security.dll中。为了判断一个XML文件在网络传输的过程中是否被无意中修改或被恶意修改,我们可以比较发送文件和接受文件加密哈希值。但是,由于网络可能会修改这个文件,我们需要以某种方式来判断它们的规范等价性。
示例代码
using System;
using System.Text; using System.Xml;
using System.Xml.XPath; using System.Xml.Serialization;
using System.IO;
using System.Data;
using System.Xml.Schema;
using System.Xml.Xsl; using System.Security.Cryptography.Xml; namespace XMLTest
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("Start\n");
string tcPath = @"..\..\testCases.xml";
//Utility.Suite suite = new Utility.Suite(); //ParseByXMLTextReader(suite, tcPath);
//ParseByXMLDocument(suite, tcPath);
//ParseByXPathDocument(suite, tcPath);
//ParseByXmlSerializer(suite, tcPath);
//ParseByDataSet(suite, tcPath); //suite.Display(); //VerifyByXsdSchema(tcPath);
//UpdateXMLByXSLT(tcPath);
//WriteXMLbyXmlTextWrite(); //XMLExactlySame
//XMLExactlyExceptEncoding
XMLCanonicalEquivalence(); Console.WriteLine("\nDone");
Console.Read();
} private static void XMLCanonicalEquivalence()
{
string file1 = @"..\..\Books1.xml";
string file2 = @"..\..\Books2.xml"; XmlDocument xd1 = new XmlDocument();
xd1.Load(file1); XmlDsigC14NTransform t1 = new XmlDsigC14NTransform(true); //true mean inclue comment t1.LoadInput(xd1);
Stream s1 = t1.GetOutput() as Stream;
XmlTextReader xtr1 = new XmlTextReader(s1);
MemoryStream ms1 = new MemoryStream();
XmlTextWriter xtw1 = new XmlTextWriter(ms1, System.Text.Encoding.UTF8);
xtw1.WriteNode(xtr1, false); //false mean not copy default properties xtw1.Flush();
ms1.Position = ;
StreamReader sr1 = new StreamReader(ms1);
string str1 = sr1.ReadToEnd();
Console.WriteLine(str1); Console.WriteLine("\n==============\n"); XmlDocument xd2 = new XmlDocument();
xd2.Load(file2); XmlDsigC14NTransform t2 = new XmlDsigC14NTransform(true); //true mean inclue comment t2.LoadInput(xd2);
Stream s2 = t2.GetOutput() as Stream;
XmlTextReader xtr2 = new XmlTextReader(s2);
MemoryStream ms2 = new MemoryStream();
XmlTextWriter xtw2 = new XmlTextWriter(ms2, System.Text.Encoding.UTF8);
xtw2.WriteNode(xtr2, false); //false mean not copy default properties xtw2.Flush();
ms2.Position = ;
StreamReader sr2 = new StreamReader(ms2);
string str2 = sr2.ReadToEnd();
Console.WriteLine(str2); if (str1 == str2)
Console.WriteLine("Files cannonically equivalent");
else
Console.WriteLine("Files Not canonically equivalent");
} private static bool XMLExactlyExceptEncoding(string file1, string file2)
{
FileStream fs1 = new FileStream(file1, FileMode.Open);
FileStream fs2 = new FileStream(file2, FileMode.Open);
StreamReader sr1 = new StreamReader(fs1);
StreamReader sr2 = new StreamReader(fs2); string s1 = sr1.ReadToEnd();
string s2 = sr2.ReadToEnd();
sr1.Close();
sr2.Close();
fs1.Close();
fs2.Close();
return (s1==s2);
} private static bool XMLExactlySame(string file1,string file2)
{
FileStream fs1 = new FileStream(file1, FileMode.Open);
FileStream fs2 = new FileStream(file2, FileMode.Open); if (fs1.Length != fs2.Length)
return false;
else
{
int b1 = ;
int b2 = ; while ((b1 = fs1.ReadByte()) != -)
{
b2 = fs2.ReadByte();
if (b1 != b2)
{
fs1.Close();
fs2.Close();
return false;
}
}
fs1.Close();
fs2.Close();
return true;
}
} private static void WriteXMLbyXmlTextWrite()
{
string caseID = "";
string result = "Pass";
string whenRun = "10/09/2014";
XmlTextWriter xtw = new XmlTextWriter(@"..\..\Results1.xml", System.Text.Encoding.UTF8);
xtw.Formatting = Formatting.Indented;
xtw.WriteStartDocument();
xtw.WriteStartElement("Results");
xtw.WriteStartElement("result");
xtw.WriteAttributeString("id", caseID);
xtw.WriteStartElement("passfaill");
xtw.WriteString(result);
xtw.WriteEndElement();
xtw.WriteStartElement("whenRun");
xtw.WriteString(whenRun);
xtw.WriteEndElement();
xtw.WriteEndElement();
xtw.WriteEndElement();
xtw.Close();
} private static void UpdateXMLByXSLT(string tcPath)
{
XslTransform xst = new XslTransform();
xst.Load(@"..\..\testCasesModifier.xslt");
xst.Transform(tcPath, @"..\..\testCasesModifier.xml");
Console.WriteLine("Done. New XML file is 'testCasesModifier.xml'");
} private static void VerifyByXsdSchema(string tcPath)
{
XmlSchemaCollection xsc = new XmlSchemaCollection();
xsc.Add(null, @"..\..\testCases.xsd");
XmlTextReader xtr = new XmlTextReader(tcPath);
XmlValidatingReader xvr = new XmlValidatingReader(xtr);
xvr.ValidationType = ValidationType.Schema;
xvr.Schemas.Add(xsc);
xvr.ValidationEventHandler += new ValidationEventHandler(ValidationCallBack);
while (xvr.Read()) ; Console.WriteLine("If no error message then XML is valid");
} private static void ValidationCallBack(object sender, ValidationEventArgs ea)
{
Console.WriteLine("Validation error: " + ea.Message);
Console.ReadLine();
} public static void DisplayInfo(DataSet ds)
{
foreach (DataTable dt in ds.Tables)
{
Console.WriteLine("\n==========================================");
Console.WriteLine("Table= " + dt.TableName + "\n");
foreach (DataColumn dc in dt.Columns)
Console.Write("{0,-14}", dc.ColumnName);
Console.WriteLine("\n------------------------------------------");
foreach (DataRow dr in dt.Rows)
{
foreach(object data in dr.ItemArray)
Console.Write("{0,-14}", data.ToString());
Console.WriteLine();
}
Console.WriteLine("\n==========================================");
}
foreach (DataRelation dr in ds.Relations)
{
Console.WriteLine("\n\nRelations:");
Console.WriteLine(dr.RelationName+"\n\n");
}
} private static void ParseByDataSet(Utility.Suite suite, string tcPath)
{
DataSet ds = new DataSet();
ds.ReadXml(tcPath); foreach (DataRow row in ds.Tables["testcase"].Rows)
{
Utility.TestCase tc=new Utility.TestCase();
tc.id = row["id"].ToString();
tc.bvt = row["bvt"].ToString();
tc.expected = row["expected"].ToString(); DataRow[] children = row.GetChildRows("testcase_inputs"); //relation name
tc.arg1=(children[]["arg1"]).ToString();
tc.arg2=(children[]["arg2"]).ToString(); suite.cases.Add(tc);
}
DisplayInfo(ds);
} private static void ParseByXmlSerializer(string tcPath)
{
XmlSerializer xs = new XmlSerializer(typeof(SerializerLib.Suite));
StreamReader sr = new StreamReader(tcPath);
SerializerLib.Suite suite = (SerializerLib.Suite)xs.Deserialize(sr);
sr.Close();
suite.Display();
} private static void ParseByXPathDocument(Utility.Suite suite, string tcPath)
{
System.Xml.XPath.XPathDocument xpd = new XPathDocument(tcPath);
XPathNavigator xpn = xpd.CreateNavigator();
XPathNodeIterator xpi = xpn.Select("/suite/testcase"); while (xpi.MoveNext())
{
Utility.TestCase tc = new Utility.TestCase();
tc.id = xpi.Current.GetAttribute("id", xpn.NamespaceURI);
tc.bvt = xpi.Current.GetAttribute("bvt", xpn.NamespaceURI); XPathNodeIterator tcChild = xpi.Current.SelectChildren(XPathNodeType.Element);
while (tcChild.MoveNext())
{ if (tcChild.Current.Name == "inputs")
{
XPathNodeIterator tcSubChild = tcChild.Current.SelectChildren(XPathNodeType.Element);
while (tcSubChild.MoveNext())
{
if (tcSubChild.Current.Name == "arg1")
tc.arg1 = tcSubChild.Current.Value;
else if (tcSubChild.Current.Name == "arg2")
tc.arg2 = tcSubChild.Current.Value;
}
}
else if (tcChild.Current.Name == "expected")
tc.expected = tcChild.Current.Value; }
suite.cases.Add(tc);
}
} private static void ParseByXMLDocument(Utility.Suite suite, string tcPath)
{
XmlDocument xd = new XmlDocument();
xd.Load(tcPath); //get all <testcase> nodes
XmlNodeList nodeList = xd.SelectNodes("/suite/testcase");
foreach (XmlNode node in nodeList)
{
Utility.TestCase tc = new Utility.TestCase();
tc.id = node.Attributes.GetNamedItem("id").Value;
tc.bvt = node.Attributes.GetNamedItem("bvt").Value; XmlNode n = node.SelectSingleNode("inputs");
tc.arg1 = n.ChildNodes.Item().InnerText;
tc.arg2 = n.ChildNodes.Item().InnerText;
tc.expected = node.ChildNodes.Item().InnerText; suite.cases.Add(tc);
}
} private static void ParseByXMLTextReader(Utility.Suite suite, string tcPath)
{
XmlTextReader xtr = new XmlTextReader(tcPath);
xtr.WhitespaceHandling = WhitespaceHandling.None;
xtr.Read(); //read xml declaration, move to tag<suite> while (!xtr.EOF)
{
if (xtr.Name == "suite" && !xtr.IsStartElement()) break;
while (xtr.Name != "testcase" || !xtr.IsStartElement())
xtr.Read(); //move to tag<testcase> Utility.TestCase tc = new Utility.TestCase();
tc.id = xtr.GetAttribute("id");
tc.bvt = xtr.GetAttribute("bvt");
xtr.Read(); //move to tag <inputs>
xtr.Read(); //move to tag <arg1>
tc.arg1 = xtr.ReadElementString("arg1");
tc.arg2 = xtr.ReadElementString("arg2");
xtr.Read(); //move to tag <expected>
tc.expected = xtr.ReadElementString("expected");
//current tag is </testcase>
suite.cases.Add(tc); xtr.Read(); //current tag is <testcase> or </suite>
}
xtr.Close();
}
}
} namespace SerializerLib
{
using System.Xml.Serialization; [XmlRootAttribute("suite")]
public class Suite
{
[XmlElementAttribute("testcase")]
public TestCase[] items;
public void Display()
{
foreach(TestCase tc in items)
{
Console.WriteLine(tc.id + " " + tc.bvt + " " + tc.inputs.arg1 + " " + tc.inputs.arg2 + " " + tc.expected);
}
} } public class TestCase
{
[XmlAttributeAttribute()]
public string id;
[XmlAttributeAttribute()]
public string bvt;
[XmlElementAttribute("inputs")]
public Inputs inputs;
public string expected; } public class Inputs
{
public string arg1;
public string arg2;
}
} namespace Utility
{
public class TestCase
{
public string id;
public string bvt;
public string arg1;
public string arg2;
public string expected;
} public class Suite
{
public System.Collections.ArrayList cases = new System.Collections.ArrayList();
public void Display()
{
foreach (TestCase tc in cases)
{
Console.WriteLine(tc.id + " " + tc.bvt + " " + tc.arg1 + " " + tc.arg2 + " " + tc.expected);
}
}
}
}
《软件测试自动化之道》读书笔记 之 XML测试的更多相关文章
- 《软件测试自动化之道》读书笔记 之 基于反射的UI测试
<软件测试自动化之道>读书笔记 之 基于反射的UI测试 2014-09-24 测试自动化程序的任务待测程序测试程序 启动待测程序 设置窗体的属性 获取窗体的属性 设置控件的属性 ...
- 《软件测试自动化之道》读书笔记 之 基于Windows的UI测试
<软件测试自动化之道>读书笔记 之 基于Windows的UI测试 2014-09-25 测试自动化程序的任务待测程序测试程序 启动待测程序 获得待测程序主窗体的句柄 获得有名字控件的 ...
- 《软件测试自动化之道》读书笔记 之 底层的Web UI 测试
<软件测试自动化之道>读书笔记 之 底层的Web UI 测试 2014-09-28 测试自动化程序的任务待测程序测试程序 启动IE并连接到这个实例 如何判断待测web程序完全加载到浏览 ...
- 《软件测试自动化之道》读书笔记 之 SQL 存储过程测试
<软件测试自动化之道>读书笔记 之 SQL 存储过程测试 2014-09-28 待测程序测试程序 创建测试用例以及测试结果存储 执行T-SQL脚本 使用BCP工具导入测试用例数据 ...
- <<google软件测试之道>>读书笔记
以前一直从开发的角度来看待测试,看完这本书以后感觉错了,难怪之前公司的测试一直搭建不起来 1.开发人员,开发测试人员,测试人员 * 开发人员负责开发 * 开发测试人员近距离接触代码,负责编写测试用例, ...
- <微软的软件测试之道>读书笔记3
一.自动化的标准步骤: 1.环境初始化,并检查环境是否处于正确的状态,能否开始测试 2.执行步骤 3.判断结果,并将结果保存到其它地方以供检查分析 4.环境清理,清理本用例产生的垃圾(临时文件.环境变 ...
- 我读<代码整洁之道>--读书笔记整理
第一章 整洁代码 "我可以列出我留意到的整洁代码的所有特点,但其中有一条是根本性的,整洁的代码总是看起来像是某位特别在意他的人写的.几乎没有改进的余地,代码作者设么都想到了,如果你企图改进它 ...
- C语言编程之道--读书笔记
C语言语法 const int nListNum =sizeof(aPrimeList)/sizeof(unsigned);//计算素数表里元素的个数 1:#define INM_MAX 32767 ...
- git命令(版本控制之道读书笔记)
1.在Windows中安装完git后,需要进行一下配置:$ git config --global user.name "zhangliang"$ git config --glo ...
随机推荐
- macos下mongoDB 3.4.5 添加用户、设置权限
macos下mongoDB 3.4.5 添加用户.设置权限 在项目中需要根据项目运行环境访问,以不同的身份访问各自的db,所以研究了一下MongoDB的 需求: 给MongoDB添加两个用户分别用 ...
- POJ 2752 (kmp求所有公共前后缀长度)
<题目链接> <转载于> 题目大意: 给出一个字符串str,求出str中存在多少子串,使得这些子串既是str的前缀,又是str的后缀.从小到大依次输出这些子串的长度.即输出该 ...
- Flutter常用组件(Widget)解析-ListView
一个可滚动的列表组件 不管在哪,列表组件都尤为重要和常用. 首先来看个例子: import 'package:flutter/material.dart'; void main () => ru ...
- Python3 Srcapy 爬虫
最近一直在理论学习,没有时间写博客.今天来一波Python爬虫,为机器学习做数据准备. 爬虫配置环境 Anaconda3 + Spyder + Scrapy Anaconda 安装就不绍了,网上很多. ...
- java如何寻找main函数对应的类
参考springboot Class<?> deduceMainApplicationClass() { try { StackTraceElement[] stackTrace = ne ...
- 利用python计算多边形面积
最近业务上有一个需求,给出多边形面积. Google了一下,发现国内论坛给的算法都是你抄我我抄你,也不验证一下是否正确, 从 博客园到csdncsdn 然后传播到国内各个角落...真是无力吐槽了. 直 ...
- PHP函数 ------ ctype_alnum
//判断是否是字母和数字或字母数字的组合 if(!ctype_alnum($str)){ echo '只能是字母或数字的组合';exit; }整理下ctype functions: 1.ctype_a ...
- nodejs区分开发环境和生产环境
参考: https://www.cnblogs.com/suoking/p/5509060.html linux&mac 设置dev,producntion export NODE_ENV=p ...
- 二分图带权匹配 KM算法与费用流模型建立
[二分图带权匹配与最佳匹配] 什么是二分图的带权匹配?二分图的带权匹配就是求出一个匹配集合,使得集合中边的权值之和最大或最小.而二分图的最佳匹配则一定为完备匹配,在此基础上,才要求匹配的边权值之和最大 ...
- PAT-A1135. Is It A Red-Black Tree (30)
已知先序序列,判断对应的二叉排序树是否为红黑树.序列中负数表示红色结点,正数表示黑色结点.该序列负数取绝对值后再排序得到的是中序序列.根据红黑树的性质判断它是否符合红黑树的要求.考察了根据先序序列和中 ...