kafka5 编写简单生产者
一 客户端
1.打开eclipse,新建maven项目(new-->other-->Maven Project-->Artifact Id设为mykafka)。
2.配置Build Path。
右击项目名mykafka-->Build Path-->Configure Buiid Path-->
把原来的JRE干掉(点击JRE System Library [J2SE-1.5]-->remove)-->
添加新的JRE(点击Add Library-->JRE System Library-->选择Execution environment:JavaSE-1.7(jre1.8.0_171)>)
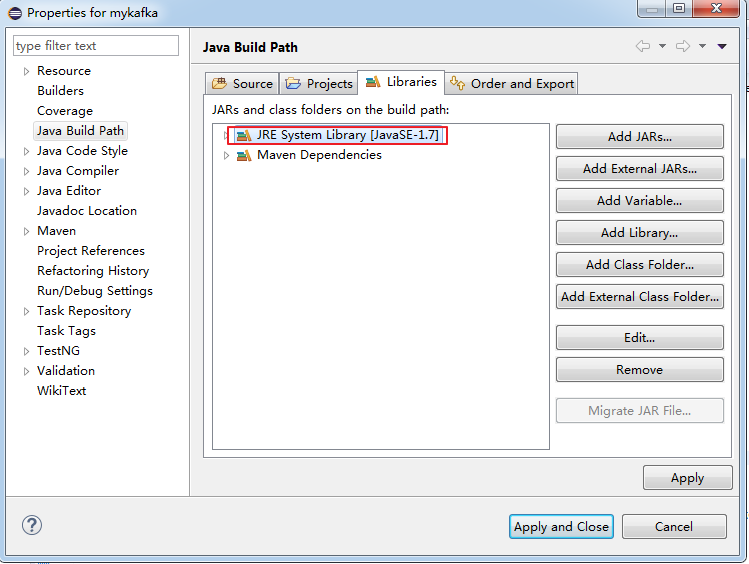
3.添加如下2个依赖。
第一个:kafka-clients

<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
也可以到maven仓库( http://mvnrepository.com/)搜索kafka-clients找到此依赖。
将依赖复制到pom.xml中,保存。此时eclipse会自动从maven仓库下载相应jar包。
第二个:slf4j-simple
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-simple -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.25</version>
</dependency>
下载完成后如下所示

4.将APP.java重命名为SimpleProducer.java。从官网拷贝示例代码,修改如下
package cn.test.mykafka; import java.util.Properties; import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord; /**
* 简单生产者
*
*/ public class SimpleProducer { public static void main(String[] args) { //创建配置信息
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.42.133:9092"); //指定broker的节点和端口
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); //创建一个生产者
Producer<String, String> producer = new KafkaProducer<>(props); //发送消息
ProducerRecord<String, String> msg = new ProducerRecord<String, String>("test-topic","hello world from win7");
producer.send(msg);
//for (int i = 0; i < 10; i++)
// producer.send(new ProducerRecord<String, String>("test-topic", Integer.toString(i), Integer.toString(i))); //topic,key(非必填),value System.out.println("over");
producer.close();
}
}
SimpleProducer.java
二 服务器端
1.搭建单节点单broker的kafka。具体步骤看这里。
2.启动服务器
启动zookeeper
[root@hadoop kafka]# zookeeper-server-start.sh config/zookeeper.properties
[root@hadoop kafka]# jps #打开另一个终端查看是否启动成功
3892 Jps
3566 QuorumPeerMain
启动kafka
[root@hadoop kafka]# kafka-server-start.sh config/server.properties
3.创建topic
#创建一个分区,一个副本的主题
#副本数无法修改,只能在创建主题时指定
[root@hadoop kafka]# kafka-topics.sh --create --zookeeper localhost: --replication-factor --partitions --topic test-topic
Created topic "test-topic". [root@hadoop kafka]# kafka-topics.sh --list --zookeeper localhost: #列出主题
test-topic
4.启动消费者
[root@hadoop kafka]# kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test-topic --from-beginning
三 测试发送消息
1.在eclipse运行代码,发送消息。
2.查看消费者是否接收到消息。

如上消费者接收到消息,说明消息发送成功。
四 遇到的问题
报错1:slf4j类加载失败。

SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
解决方法:在pom文件中添加slf4j-simple依赖,如上文所示。
由于我们虚拟机安装的是kafka_2.11-2.0.0.tgz版本,所以到maven仓库找到其依赖之后,复制粘贴到pom.xml中
报错2:java.io.IOException: Can't resolve address: hadoop:9092
原因:kafka 连接原理:首先连接 192.168.42.133:9092,再连接返回的host.name = hadoop,最后继续连接advertised.host.name=hadoop。
解决方法:添加window解析。C:\Windows\System32\drivers\etc\hosts文件添加92.168.42.133 hadoop。用cmd命令行ping hadoop试试如果可以ping通即可。
五 KafkaProducer发送消息分析
生产者是线程安全的,维护了本地的buffer pool,发送消息,消息进入pool。
send方法异步,立刻返回。
ack=all导致记录完全提交时阻塞。
p.send(rec)-->p.doSend(rec,callback)-->interceptors.onSend()-->对key+value进行串行化-->计算分区-->计算总size-->创建TopicPartition对象-->创建回调拦截器-->Sender函数
详细官网内容及翻译:
The producer consists of a pool of buffer space that holds records that haven't yet been transmitted to the server as well as a background I/O thread that is responsible for turning these records into requests and transmitting them to the cluster. Failure to close the producer after use will leak these resources.
生产者包含一个缓冲区池,用于保存尚未传输到服务器的记录,以及一个后台I / O线程,负责将这些记录转换为请求并将它们传输到集群。如果在使用后没有关闭生产者,这些资源会被泄漏。
The send() method is asynchronous. When called it adds the record to a buffer of pending record sends and immediately returns. This allows the producer to batch together individual records for efficiency.
send()方法是异步的。调用时,它会将记录添加到待发送记录的缓冲区中并立即返回。这允许生产者将各个记录一起批处理以提高效率。
The acks config controls the criteria under which requests are considered complete. The "all" setting we have specified will result in blocking on the full commit of the record, the slowest but most durable setting.
acks配置用来控制请求完成的标准。我们指定的“all”设置将导致阻止完整提交记录,这是最慢但最耐用的设置。
If the request fails, the producer can automatically retry, though since we have specified retries as 0 it won't. Enabling retries also opens up the possibility of duplicates (see the documentation on message delivery semantics for details).
如果请求失败,则生产者可以自动重试,但由于我们已将retries指定为0,因此不会。启用重试也会打开重复的可能性(有关详细信息,请参阅有关消息传递语义的文档)。
The producer maintains buffers of unsent records for each partition. These buffers are of a size specified by the batch.size config. Making this larger can result in more batching, but requires more memory (since we will generally have one of these buffers for each active partition).
生产者为每个分区维护未发送记录的缓冲区。这些缓冲区的大小由batch.size指定。使这个更大可以导致更多的批处理,但需要更多的内存(因为我们通常会为每个活动分区提供这些缓冲区之一)。
By default a buffer is available to send immediately even if there is additional unused space in the buffer. However if you want to reduce the number of requests you can set linger.ms to something greater than 0. This will instruct the producer to wait up to that number of milliseconds before sending a request in hope that more records will arrive to fill up the same batch. This is analogous to Nagle's algorithm in TCP. For example, in the code snippet above, likely all 100 records would be sent in a single request since we set our linger time to 1 millisecond. However this setting would add 1 millisecond of latency to our request waiting for more records to arrive if we didn't fill up the buffer. Note that records that arrive close together in time will generally batch together even with linger.ms=0 so under heavy load batching will occur regardless of the linger configuration; however setting this to something larger than 0 can lead to fewer, more efficient requests when not under maximal load at the cost of a small amount of latency.
默认情况下,即使缓冲区中有其他未使用的空间,也可以立即发送缓冲区。但是,如果您想减少请求数量,可以将linger.ms设置为大于0的值。这将指示生产者在发送请求之前等待该毫秒数,希望更多记录到达以填满同一批次。这类似于TCP中的Nagle算法。例如,在上面的代码片段中,由于我们将逗留时间设置为1毫秒,因此可能会在单个请求中发送所有100条记录。但是,如果我们没有填满缓冲区,此设置会为我们的请求增加1毫秒的延迟,等待更多记录到达。请注意,即使在linger.ms = 0的情况下,及时到达的记录通常也会一起批处理,因此在重负载情况下,无论延迟配置如何,都会发生批处理;但是,将此值设置为大于0的值可以在不受最大负载影响的情况下以较少的延迟为代价导致更少,更有效的请求。
The buffer.memory controls the total amount of memory available to the producer for buffering. If records are sent faster than they can be transmitted to the server then this buffer space will be exhausted. When the buffer space is exhausted additional send calls will block. The threshold for time to block is determined by max.block.ms after which it throws a TimeoutException.
buffer.memory控制生产者可用于缓冲的总内存量。如果记录的发送速度快于传输到服务器的速度,则此缓冲区空间将耗尽。当缓冲区空间耗尽时,额外的发送调用将被阻止。阻塞时间的阈值由max.block.ms确定,然后抛出TimeoutException。
The key.serializer and value.serializer instruct how to turn the key and value objects the user provides with their ProducerRecord into bytes. You can use the included ByteArraySerializer or StringSerializer for simple string or byte types.
key.serializer和value.serializer指示如何将用户提供的键和值对象及其ProducerRecord转换为字节。您可以将包含的ByteArraySerializer或StringSerializer用于简单的字符串或字节类型。
kafka5 编写简单生产者的更多相关文章
- kafka8 编写简单消费者
1.eclipse运行消费者代码.代码如下 package cn.test.mykafka; import java.util.Arrays; import java.util.Properties; ...
- 编写简单的ramdisk(选择IO调度器)
前言 目前linux中包含anticipatory.cfq.deadline和noop这4个I/O调度器.2.6.18之前的linux默认使用anticipatory,而之后的默认使用cfq.我们在前 ...
- 编写简单的Mapreduce程序并部署在Hadoop2.2.0上运行
今天主要来说说怎么在Hadoop2.2.0分布式上面运行写好的 Mapreduce 程序. 可以在eclipse写好程序,export或用fatjar打包成jar文件. 先给出这个程序所依赖的Mave ...
- 【转】用systemJS+karma+Jasmine+babel环境去编写简单的ES6工程
原文链接:http://www.cnblogs.com/shuoer/p/7779131.html 用systemJS+karma+Jasmine+babel环境去编写简单的ES6工程 首先解释下什么 ...
- 编写简单的辅助脚本来在 Google 表格上记账
我的第二份工作入职在即,而这一次则真的是完全跑到了一个陌生的城市了.租房,购置相关用品,还尚未工作钱就花掉一堆.尽管我个人之前一直都没有过记账的习惯,但为了让自己能够搞清楚自己的钱都花在哪里了,于是还 ...
- SLAM+语音机器人DIY系列:(二)ROS入门——5.编写简单的消息发布器和订阅器
摘要 ROS机器人操作系统在机器人应用领域很流行,依托代码开源和模块间协作等特性,给机器人开发者带来了很大的方便.我们的机器人“miiboo”中的大部分程序也采用ROS进行开发,所以本文就重点对ROS ...
- SLAM+语音机器人DIY系列:(二)ROS入门——6.编写简单的service和client
摘要 ROS机器人操作系统在机器人应用领域很流行,依托代码开源和模块间协作等特性,给机器人开发者带来了很大的方便.我们的机器人“miiboo”中的大部分程序也采用ROS进行开发,所以本文就重点对ROS ...
- python模块之sys和subprocess以及编写简单的主机扫描脚本
python模块之sys和subprocess以及编写简单的主机扫描脚本 1.sys模块 sys.exit(n) 作用:执行到主程序末尾,解释器自动退出,但是如果需要中途退出程序,可以调用sys.e ...
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
随机推荐
- 【QT】QPixmap和QImage在QLabel显示一张图像
#include <QPixmap> void Dialog::on_Button1_clicked() { QPixmap img; img.load("1.bmp" ...
- linux 设置中文版man手册
作为CentOS 新手,看懂英文man固然重要,不过配置好中文man也可以让自己更快速地学习!1. 下载中文man包源码的网址:https://src.fedoraproject.org/repo/p ...
- [Stats385] Lecture 05: Avoid the curse of dimensionality
Lecturer 咖中咖 Tomaso A. Poggio Lecture slice Lecture video 三个基本问题: Approximation Theory: When and why ...
- 百度网盘上下载文件,调用api接口的请求方式和参数
REST api 功能:下载单个文件. Download接口支持HTTP协议标准range定义,通过指定range的取值可以实现断点下载功能. 例如: 如果在request消息中指定“Range: b ...
- iOS(UIWebView 和WKWebView)OC与JS交互 之二
在iOS应用的开发过程中,我们经常会使用到WebView,当我们对WebView进行操作的时候,有时会需要进行源生的操作.那么我记下来就与大家分享一下OC与JS交互. 首先先说第一种方法,并没有牵扯O ...
- 还不错的MUI技术文档
https://blog.csdn.net/xin724/article/details/81939176
- 使用Eclipse的坑
1.运行Eclipse时突然出现找不到或者无法加载主类,这个问题不解决,下面的学习就无从做起,查了网上的一些资料,无法解决,所以还是有点烦人.如果在解决问题的过程中能够学到点什么,也是很值得的,但是就 ...
- day_4_27 py
''' 2018-4-27 19:57:29 其实这些都是讲的类和对象的 self(在定义方法的时候默认的参数)就相当于java里面的this关键字, this.name=name class 类名: ...
- python 中的 print 函数与 list函数
print() 函数: 传入单个参数时默认回车换行,关键词 end 可以用来避免输出后的回车(换行), 或者以一个不同的字符串结束输出. >>> a, b = 0, 1 >& ...
- MyBatis limit分页设置
错误的写法: <select id="queryMyApplicationRecord" parameterType="MyApplicationRequest&q ...