Selenium WebDriver Api 知识梳理
之前一直没有系统的梳理WebDriver Api的相关知识,今天借此机会整理一下。
1、页面元素定位
1.1、8种常用定位方法
# id定位
driver.find_element_by_id()
# name定位
driver.find_element_by_name()
# className定位
driver.find_element_by_class_name()
# tag定位
driver.find_element_by_tag_name()
# link定位
driver.find_element_by_link_text()
# partial link定位
driver.find_element_by_partial_link_text()
# xpath定位
driver.find_element_by_xpath()
# css定位
driver.find_element_by_css_selector()
1.2、实例
以百度输入框为例如下图
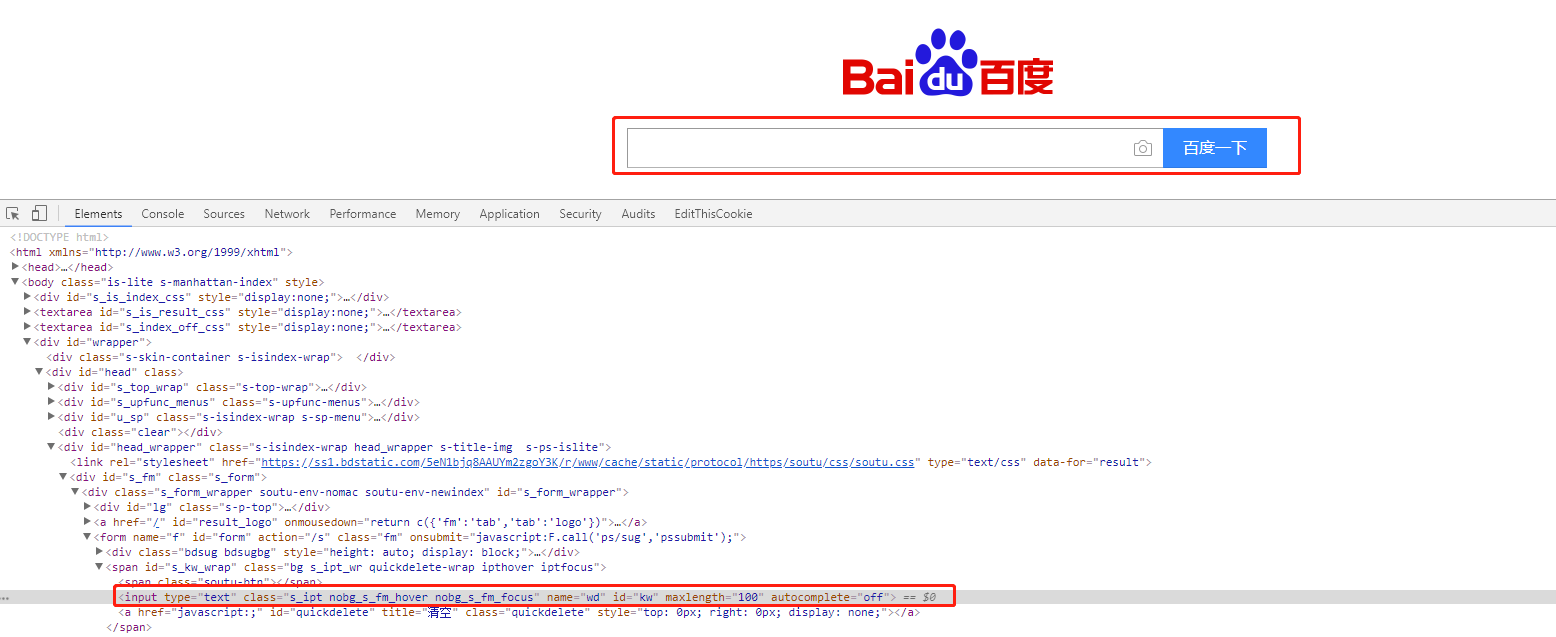
# id定位
driver.find_element_by_id('kw')
# name定位
driver.find_element_by_name('wd')
# className定位
driver.find_element_by_class_name('s_ipt')
# tag定位
driver.find_element_by_tag_name('input')
注意:由于name、class 、tag等不具有唯一性,所以不能区分不同的元素,所以很少使用。
link 定位与前面介绍的几种定位方法有所不同,它专门用来定位本链接。百度输入框上面的几个文本
链接的代码如下:
<a class="mnav" name="tj_trnews" href="http://news.baidu.com">新闻</a>
<a class="mnav" name="tj_trhao123" href="http://www.hao123.com">hao123</a>
<a class="mnav" name="tj_trmap" href="http://map.baidu.com">地图</a>
<a class="mnav" name="tj_trvideo" href="http://v.baidu.com">视频</a>
<a class="mnav" name="tj_trtieba" href="http://tieba.baidu.com">贴吧>
通过查看上面的代码,我们发现通过 name 属性定位是个不错的选择。不过我们这里为了要学习 link
定位,通过 link 定位实现如下:
find_element_by_link_text("新闻")
find_element_by_link_text("hao123")
find_element_by_link_text("地图")
find_element_by_link_text("视频")
find_element_by_link_text("贴吧")
通过 partial link 定位如下:
find_element_by_partial_link_text("一个很长的")
find_element_by_partial_link_text("文本连接")
find_element_by_link_text()方法通过元素标签对之间的部分文本信息来定位元素。
xpath 、css定位
# xpath定位
driver.find_element_by_xpath('//*[@id="kw"]')
# css定位
driver.find_element_by_css_selector('#kw')
通过 class 属性定位:
find_element_by_css_selector(".s_ipt")
find_element_by_css_selector(".bg s_btn")
find_element_by_css_selector()方法用于 CSS 语言定位元素,点号(.)表示通过 class 属性来定位元素。
通过 id 属性定位:
find_element_by_css_selector("#kw")
find_element_by_css_selector("#su")
井号(#)表示通过 id 属性来定位元素
1.3、定位一组元素
WebDriver 还
提供了与之对应的 8 种定位方法用于定位一组元素。
find_elements_by_id()
find_elements_by_name()
find_elements_by_class_name()
find_elements_by_tag_name()
find_elements_by_link_text()
find_elements_by_partial_link_text()
find_elements_by_xpath()
find_elements_by_css_selector()
定位一组对象的方法与定位单个对象的方法类似,唯一的区别是在单词 element 后面多了一个 s 表示
复数。
定位一组对象一般用于以下场景:
批量操作对象,比如将页面所有的复选框都被勾选。
先获取一组对象,再在这组对象中过滤出需要具体定位的一些对象。比如定位出页面上所有的
checkbox,然后选择最后一个。
如下图通过 css 定位出一组元素,然后获取对应文本,判断是否是自己需要的,然后获取对应下标。
fac_list = self.driver.find_elements_by_css_selector(".w220.ellipsis")
for fac in fac_list:
if fac.text == u'洛阳顺势药业有限公司':
i = fac_list.index(fac)
i = i+1
break
googs_path = ".//*[@id='search_result_list']/li[%d]/div/table/tbody/tr[1]/td[9]/p/a" % i
time.sleep(5)
以上完成了页面元素简单定位,当然这里只是最简单的举例,复杂的定位可以根据需要进行组合,当然也可以借助浏览器插件等工具,进行元素定位,如chrome 的开发者模式,firefox 的 firebug、firepath等工具
2、浏览器操作
2.1、控制浏览器大小
# 设置浏览器大小
driver.set_window_size(800,800) # 设置浏览器最大化
driver.maximize_window()
2.2、控制浏览器后退、前进、刷新
# FileName : setWindow.py
# Author : Adil
# DateTime : 2018/3/12 16:48
# SoftWare : PyCharm from selenium import webdriver import time
driver = webdriver.Chrome()
driver.implicitly_wait(1) first_url = "http://www.baidu.com/"
driver.get(first_url) time.sleep(5) # 设置浏览器大小
driver.set_window_size(800,800) # 设置浏览器最大化
driver.maximize_window() # 访问第二个页面
second_url = 'http://news.baidu.com/'
driver.get(second_url) # 返回(后退)到百度首页
print("back to %s"%first_url) # back to http://www.baidu.com/
driver.back() # 前进到新闻页
print("forward to %s"% second_url) # forward to http://news.baidu.com/
driver.forward()
time.sleep(5)
driver.refresh()
time.sleep(15)
driver.quit()
2.3、浏览器滚动
关于浏览器滚动条的滚动,之前,chrome与其他浏览器是不兼容的,
参考 http://www.cnblogs.com/Skyyj/p/7275938.html
今天尝试发现,chrome 与其他浏览器兼容了,改变了原有的写法。
上下滚动统一支持如下写法
# 滚动到底部 js = "var q=document.documentElement.scrollTop=10000" driver.execute_script(js) time.sleep(5) # 然后滚动到上面 js = "var q=document.documentElement.scrollTop=0" driver.execute_script(js)
左右滚动
# 设置浏览器窗口大小,长500,高400
driver.set_window_size(500,400) time.sleep(5) # 设置横向滚动
js = 'window.scrollTo(500,400)'
driver.execute_script(js) time.sleep(5)
3、元素操作
3.1、元素简单操作
click() 单击、clear()清空、send_keys()文本框输入、submit()提交表单,模拟回车操作
driver.find_element_by_id("idInput").clear()
driver.find_element_by_id("idInput").send_keys("username")
driver.find_element_by_id("pwdInput").clear()
driver.find_element_by_id("pwdInput").send_keys("password")
driver.find_element_by_id("loginBtn").click()
3.2、鼠标事件
ActionChains 类提供的鼠标操作的常用方法:
perform() 执行所有 ActionChains 中存储的行为
context_click() 右击
double_click() 双击
drag_and_drop() 拖动
move_to_element() 鼠标悬停
# FileName : mouseSet.py
# Author : Adil
# DateTime : 2018/3/12 18:32
# SoftWare : PyCharm from selenium import webdriver # import ActionChains
from selenium.webdriver.common.action_chains import ActionChains import time
driver = webdriver.Chrome()
# driver.implicitly_wait(1) first_url = "http://www.baidu.com/"
driver.get(first_url) # 悬浮 move_to_element()
time.sleep(2)
driver.maximize_window()
time.sleep(2)
element1 = driver.find_element_by_xpath(".//*[@id='u1']/a[8]") ActionChains(driver).move_to_element(element1).perform() time.sleep(5)
# 右击 context_click()
ActionChains(driver).context_click(element1).perform() time.sleep(5)
# 双击 double_click()
ActionChains(driver).double_click(element1).perform() time.sleep(5)
# 拖动 drag_and_drop()
#定位元素的源位置
element = driver.find_element_by_name("xxx")
#定位元素要移动到的目标位置
target = driver.find_element_by_name("xxx")
#执行元素的拖放操作
ActionChains(driver).drag_and_drop(element,target).perform() driver.quit()
3.3、键盘事件
from selenium.webdriver.common.keys import Keys
在使用键盘按键方法前需要先导入 keys 类包。
下面经常使用到的键盘操作:
send_keys(Keys.BACK_SPACE) 删除键(BackSpace)
send_keys(Keys.SPACE) 空格键(Space)
send_keys(Keys.TAB) 制表键(Tab)
send_keys(Keys.ESCAPE) 回退键(Esc)
send_keys(Keys.ENTER) 回车键(Enter)
send_keys(Keys.CONTROL,'a') 全选(Ctrl+A)
send_keys(Keys.CONTROL,'c') 复制(Ctrl+C)
send_keys(Keys.CONTROL,'x') 剪切(Ctrl+X)
send_keys(Keys.CONTROL,'v') 粘贴(Ctrl+V)
send_keys(Keys.F1) 键盘 F1
……
send_keys(Keys.F12) 键盘 F12
from selenium import webdriver
#引入 Keys 模块
from selenium.webdriver.common.keys import Keys
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
#输入框输入内容
driver.find_element_by_id("kw").send_keys("seleniumm")
#删除多输入的一个 m
driver.find_element_by_id("kw").send_keys(Keys.BACK_SPACE)
#输入空格键+“教程”
driver.find_element_by_id("kw").send_keys(Keys.SPACE)
driver.find_element_by_id("kw").send_keys(u"教程")
#ctrl+a 全选输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'a')
#ctrl+x 剪切输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'x')
#ctrl+v 粘贴内容到输入框
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'v')
#通过回车键盘来代替点击操作
driver.find_element_by_id("su").send_keys(Keys.ENTER)
driver.quit()
4、多frame切换
在 web 应用中经常会遇到 frame 嵌套页面的应用,页 WebDriver 每次只能在一个页面上识别元素,对
于 frame 嵌套内的页面上的元素,直接定位是定位是定位不到的。这个时候就需要通过 switch_to_frame()
方法将当前定位的主体切换了 frame 里。
参看 hao123首页
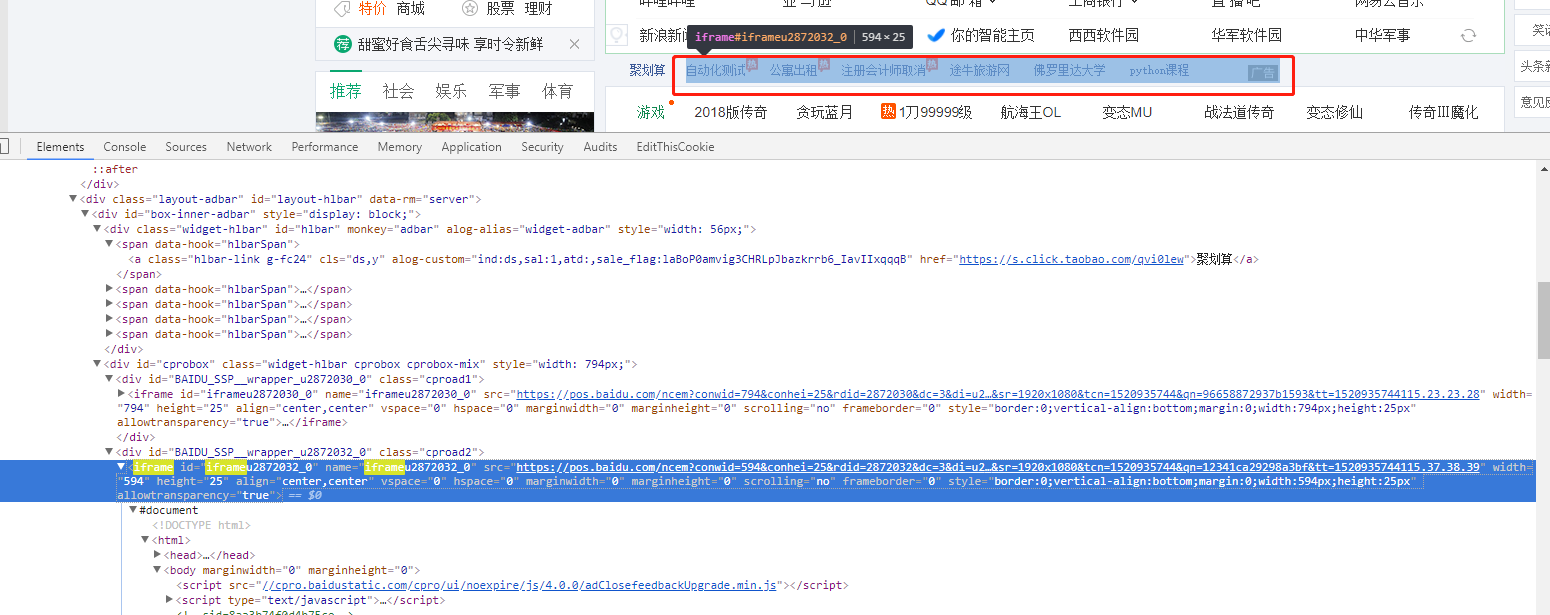
# 曾经支持的写法
# driver.switch_to_frame("iframeu2872032_0") # 最新写法
driver.switch_to.frame("iframeu2872032_0")
# 切换到该frame下,然后点击操作,到另一页面。
driver.find_element_by_xpath('//*[@id="container"]/div[3]/div/a').click()
# 切换到初始frame
driver.switch_to.default_content()
time.sleep(2)
driver.find_element_by_xpath('//*[@id="menus"]/li[2]/a').click()
对于多层frame ,可以使用frame的索引切换

driver.switch_to.frame(3)
如果 iframe没有可用的id 和name属性,还可以使用xpath
# 先通过xpath定位到iframe
xf = driver.find_element_by_xpath('XXXX')
# 再将定位对象传给switch_to.frame(xf)
driver.switch_to.frame(xf)
...
5、多窗口切换
有时候需要在不同的窗口切换,从而操作不同的窗口上的元素。但 WebDriver 提供了 switch_to.window()方法可以切换到任意的窗口。
看如下代码
# FileName : Switch_to_frame.py
# Author : Adil
# DateTime : 2018/3/13 17:49
# SoftWare : PyCharm from selenium import webdriver import time
driver = webdriver.Chrome()
# driver.implicitly_wait(1) first_url = "http://www.hao123.com/"
driver.get(first_url) time.sleep(1) # 曾经支持的写法
# driver.switch_to_frame("iframeu2872032_0") # 最新写法
driver.switch_to.frame("iframeu2872032_0")
# 切换到该frame下,然后点击操作,到另一页面。
driver.find_element_by_xpath('//*[@id="container"]/div[3]/div/a').click() # 获取多窗口句柄
get_handles = driver.window_handles
print(get_handles) # ['CDwindow-(79057C598F9424652D25D8405B654717)', 'CDwindow-(99F2157CBA34CE7DAE131D3039561013)'] # 获取当前窗口句柄
get_currentHandle = driver.current_window_handle # CDwindow-(79057C598F9424652D25D8405B654717)
print(get_currentHandle) for handle in get_handles:
if handle != get_currentHandle:
# 最新写法 switch_to.window
driver.switch_to.window(handle)
# 曾经支持的写法
# driver.switch_to_window(handle) print(driver.current_window_handle) # 切换到初始frame
driver.switch_to.default_content()
time.sleep(2)
driver.find_element_by_xpath('//*[@id="menus"]/li[2]/a').click() # 关闭当前句柄页
driver.close()
time.sleep(5)
# 关闭浏览器
driver.quit()
6、警告框处理
在 WebDriver 中处理 JavaScript 所生成的 alert、confirm 以及 prompt 是很简单的。具体做法是使用
switch_to_alert()方法定位到 alert/confirm/prompt。然后使用 text/accept/dismiss/send_keys 按需进行操做。
text:获取文本值
accept() :点击"确认"
dismiss() :点击"取消"或者叉掉对话框
send_keys() :输入文本值 --仅限于 prompt,在 alert 和 confirm 上没有输入
框
# 旧式写法
driver.switch_to_alert() # 切换到Alter 弹出框上
driver.switch_to.alert()
# 同意点击确认
driver.switch_to.alert().accept()
# 取消操作
driver.switch_to.alert().dismiss()
# 输入文本内容
driver.switch_to.alert().send_keys("输入信息!")
7、单选复选框操作
7.1、单选: radio
首先是定位选择框的位置
定位 id,点击图标就可以了 ,即可完成单选的选择。
7.2、复选框: checkbox
勾选单个框,比如勾选 selenium 这个,可以根据它的 id=c1 直接定位到点
击就可以了
全部勾选,可以用到定位一组元素,从上面源码可以看出,复选框的
type=checkbox,这里可以用 xpath 语法: .//*[@type='checkbox']
这里注意,敲黑板做笔记了: find_elements 是不能直接点击的,
它是复数的,所以只能先获取到所有的 checkbox 对象,然后通过 for 循环去一
个个点击操作
判断是否选中: is_selected()
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("file:///C:/Users/Gloria/Desktop/checkbox.html")
# 没点击操作前,判断选项框状态
s = driver.find_element_by_id("boy").is_selected()
print s
driver.find_element_by_id("boy").click()
# 点击后,判断元素是否为选中状态
r = driver.find_element_by_id("boy").is_selected()
print r
# 复选框单选
driver.find_element_by_id("c1").click()
# 复选框全选
checkboxs = driver.find_elements_by_xpath(".//*[@type='checkbox']")
for i in checkboxs:
i.click()
8、select下拉框操作
8.1、二次定位
1.定位 select 里的选项有多种方式,这里先介绍一种简单的方法:二次定位
2.基本思路,先定位 select 框,再定位 select 里的选项
# 分两步:先定位下拉框,再点击选项
s = driver.find_element_by_id('nr')
s.find_element_by_xpath("//option[@value='50']").click()
还有另外一种写法也是可以的,把最下面两步合并成为一步:
driver.find_element_by_id("nr").find_element_by_xpath("//option[@valu
e='']").click()
8.2、直接定位
通过xpath或是css一次性直接定位到 option 上的内容
driver.find.element_by_xpath(".//*[@id='nr']/option[2]").click()
8.3、引入Select模块
# 导入 select 模块 Select类
from selenium.webdriver.support.select import Select
select_by_index() :通过索引定位
通过 select 选项的索引来定位选择对应选项(从 0 开始计数),如选择
第三个选项:select_by_index(2)
s = driver.find_element_by_id('nr')
Select(s).select_by_index(2)
select_by_value() :通过 value 值定位
通过选项的 value值来定位。每个选项,都有对应的 value 值
第二个选顷对应的 value 值就是"20":select_by_value("20")
s = driver.find_element_by_id('nr')
Select(s).select_by_value(20)
sl1 = Select(driver.find_element_by_id('cly_province'))
sl1.select_by_value('')
time.sleep(2)
#cly_city
sl1 = Select(driver.find_element_by_id('cly_city'))
sl1.select_by_value('')
time.sleep(2)
#cly_district
sl1 = Select(driver.find_element_by_id('cly_district'))
sl1.select_by_value('')
select_by_visible_text() :通过文本值定位
Select 模块里面还有一个更加高级的功能,可以直接通过选项的文本内容来
定位。
定位“每页显示 50 条” : select_by_visible_text("每页显示 50 条")
s = driver.find_element_by_id('nr')
Select(s).select_by_visible_text("每页显示50条")
deselect_all() :取消所有选项
deselect_by_index() :取消对应 index 选项
deselect_by_value() :取消对应 value 选项
deselect_by_visible_text() :取消对应文本选项
first_selected_option() :返回第一个选项
all_selected_options() :返回所有的选项
9、文件下载和上传
文件下载请参考 http://www.cnblogs.com/BlueSkyyj/p/7526803.html
文件上传介绍两种方法,
请参考:http://www.cnblogs.com/BlueSkyyj/p/7523821.html
http://www.cnblogs.com/BlueSkyyj/p/7523844.html
10、设置元素等待
如今大多数的 web 应用程序使用 AJAX 技术。当浏览器在加载页面时,页面内的元素可能并不是同时
被 加 载 完 成 的 , 这 给 元 素 的 定 位 添 加 的 困 难 。 如 果 因 为 在 加 载 某 个 元 素 时 延 迟 而 造 成
ElementNotVisibleException 的情况出现,那么就会降低的自动化脚本的稳定性。
WebDriver 提供了两种类型的等待:显式等待和隐式等待。
10.1、显示等待
显式等待使 WebdDriver 等待某个条件成立时继续执行,否则在达到最大时长时抛弃超时异常
(TimeoutException)。
#coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
element = WebDriverWait(driver,5,0.5).until(
EC.presence_of_element_located((By.ID,"kw"))
)
element.send_keys('selenium')
driver.quit()
WebDriverWait()
它是由 webdirver 提供的等待方法。在设置时间内,默认每隔一段时间检测一次当前页面元素是否存
在,如果超过设置时间检测不到则抛出异常。具体格式如下:
WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)
driver - WebDriver 的驱动程序(Ie, Firefox,Chrome 等)
timeout - 最长超时时间,默认以秒为单位
poll_frequency - 休眠时间的间隔(步长)时间,默认为 0.5 秒
ignored_exceptions - 超时后的异常信息,默认情况下抛 NoSuchElementException 异常。
until()
WebDriverWait()一般由 until()(或 until_not())方法配合使用,下面是 until()和 until_not()方法的说明。
until(method, message=’ ’)
调用该方法提供的驱动程序作为一个参数,直到返回值为 Ture。
until_not(method, message=’ ’)
调用该方法提供的驱动程序作为一个参数,直到返回值为 False。
Expected Conditions
在本例中,我们在使用 expected_conditions 类时对其时行了重命名,通过 as 关键字对其重命名为 EC,
并调用 presence_of_element_located()判断元素是否存在。
expected_conditions 类提供一些预期条件的实现。
title_is 用于判断标题是否 xx。
title_contains 用于判断标题是否包含 xx 信息。
presence_of_element_located 元素是否存在。
visibility_of_element_located 元素是否可见。
visibility_of 是否可见
presence_of_all_elements_located 判断一组元素的是否存在
text_to_be_present_in_element 判断元素是否有 xx 文本信息
text_to_be_present_in_element_value 判断元素值是否有 xx 文本信息
frame_to_be_available_and_switch_to_it 表单是否可用,并切换到该表单。
invisibility_of_element_located 判断元素是否隐藏
element_to_be_clickable 判断元素是否点击,它处于可见和启动状态
staleness_of 等到一个元素不再是依附于 DOM。
element_to_be_selected 被选中的元素。
element_located_to_be_selected 一个期望的元素位于被选中。
element_selection_state_to_be 一个期望检查如果给定的元素被选中。
element_located_selection_state_to_be 期望找到一个元素并检查是否选择状态
alert_is_present 预期一个警告信息
除了 expected_conditions 所提供的预期方法,我们也可以使用前面学过的 is_displayed()方法来判断元
素是否可 见
#coding=utf-8
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
input_ = driver.find_element_by_id("kw")
element = WebDriverWait(driver,5,0.5).until(
lambda driver : input_.is_displayed()
)
input_.send_keys('selenium')
driver.quit()
lambad 为 Python 创建匿名函数的关键字。关于 Python 匿名函数的使用这里不再进行讲解,请参考
Python 相关教程。
定义 input_为百度输入框,通过 is_displayed()判断其是否可见。
10.2、隐式等待
隐式等待是通过一定的时长等待页面所元素加载完成。哪果超出了设置的时长元素还没有被加载测抛
NoSuchElementException 异常。WebDriver 提供了 implicitly_wait()方法来实现隐式等待,默认设置为 0。它
的用法相对来说要简单的多。
#coding=utf-8
from selenium import webdriver
driver = webdriver.Firefox()
driver.implicitly_wait(10)
driver.get("http://www.baidu.com")
input_ = driver.find_element_by_id("kw22")
input_.send_keys('selenium')
driver.quit()
implicitly_wait()默认参数的单位为秒,本例中设置等待时长为 10 秒,首先这 10 秒并非一个固定的等
待时间,它并不影响脚本的执行速度。其次,它并不真对页面上的某一元素进行等待,当脚本执行到某个
元素定位时,如果元素可定位那么继续执行,如果元素定位不到,那么它将以轮询的方式不断的判断元素
是否被定位到,假设在第 6 秒钟定位到元素则继续执行。直接超出设置时长(10 秒)还没定位到元素则抛
出异常。
10.3、设置sleep休眠
用 sleep()方法,需要说明的是 sleep()由 Python 的 time 模块提供。
当执行到 sleep()方法时会固定的休眠所设置的时长,然后再继续执行。sleep()方法默认参数以秒为单
位,如果设置时长小于 1 秒,可以用小数点表示,如:sleep(0.5)
from selenium import webdriver import time
driver = webdriver.Chrome()
# driver.implicitly_wait(1) first_url = "http://www.hao123.com/"
driver.get(first_url) time.sleep(1)
11、操作Cookie
有时候我们需要验证浏览器中是否存在某个 cookie,因为基于真实的 cookie 的测试是无法通过白盒和
集成测试完成的。WebDriver 提供了操作 Cookie 的相关方法可以读取、添加和删除 cookie 信息。
webdriver 操作 cookie 的方法有:
get_cookies() 获得所有 cookie 信息
get_cookie(name) 返回有特定 name 值有 cookie 信息
add_cookie(cookie_dict) 添加 cookie,必须有 name 和 value 值
delete_cookie(name) 删除特定(部分)的 cookie 信息
delete_all_cookies() 删除所有 cookie 信息
下面通过 get_cookies()来获取当前浏览器的 cookie 信息
下面贴上代码
# FileName : handleCookie.py
# Author : Adil
# DateTime : 2018/3/17 19:38
# SoftWare : PyCharm from selenium import webdriver import time url = 'https://www.yiyao.cc/' driver = webdriver.Chrome() driver.get(url) driver.maximize_window() # 获取指定cookie的值
# cookie = driver.get_cookie() cookies = driver.get_cookies() print("登录前!")
print("cookies:") print(cookies) driver.find_element_by_id("new-username").clear() driver.find_element_by_id("new-username").send_keys("username") driver.implicitly_wait(5)
driver.find_element_by_id("new-password").clear() driver.find_element_by_id("new-password").send_keys("password") driver.find_element_by_id('home-right-login').click() driver.implicitly_wait(5)
# 加一个休眠,这样得到的cookie 才是登录后的cookie,否则可能打印的还是登录前的cookie
time.sleep(5) print("登录后!") cookiesAfter = driver.get_cookies() print("cookiesAfter:") print(cookiesAfter) print("cookie") print(driver.get_cookie("domain")) driver.add_cookie({'name':'yangyaojun','value':"yangpass"}) # 再次查看 cookies,打印出的信息是包含上面添加的内容的
print(driver.get_cookies()) driver.quit()
delete_cookie() 和 delete_all_cookies()的使用也很简单,前者通过那么删除一个特定的cookie信息,后者直接删除浏览器中所有的cookies()信息。
未完待续......
Selenium WebDriver Api 知识梳理的更多相关文章
- Python + Selenium WebDriver Api 知识回顾
一直再用 Selenium WebDriver 但是用的都比较零散,也没有做过总结,今天借此机会,整理一下,方便大家使用时查阅 webDriver 的属性 ['CONTEXT_CHROME', 'C ...
- python2.7运行selenium webdriver api报错Unable to find a matching set of capabilities
在火狐浏览器33版本,python2.7运行selenium webdriver api报错:SessionNotCreatedException: Message: Unable to find a ...
- Vue.js 2.x API 知识梳理(一) 全局配置
Vue.js 2.x API 知识梳理(一) 全局配置 Vue.config是一个对象,包含Vue的全局配置.可以在启动应用之前修改指定属性. 这里不是指的@vue/cli的vue.config.js ...
- selenium webdriver API
元素定位 #coding=utf-8 from selenium import webdriver from selenium.webdriver.firefox.firefox_binary imp ...
- Selenium - Webdriver API /ActionChains API
一.控制浏览器 1.1 控制浏览器窗口大小 # 获取当前浏览器的大小 driver.get_window_size() # 通过像素设置浏览器的大小 driver.set_window_size( ...
- selenium webdriver API详解(三)
本系列主要讲解webdriver常用的API使用方法(注意:使用前请确认环境是否安装成功,浏览器驱动是否与谷歌浏览器版本对应) 一:获取页面元素的文本内容:text 例:获取我的博客名字文本内容 代码 ...
- selenium webdriver API详解(二)
本系列主要讲解webdriver常用的API使用方法(注意:使用前请确认环境是否安装成功,浏览器驱动是否与谷歌浏览器版本对应) 一:获取当前页面的title(一般获取title用于断言) from s ...
- selenium webdriver API详解(一)
本系列主要讲解webdriver常用的API使用方法(注意:使用前请确认环境是否安装成功,浏览器驱动是否与谷歌浏览器版本对应) 一:打开某个网址:get() from selenium import ...
- Python+Selenium WebDriver API:浏览器及元素的常用函数及变量整理总结
由于网页自动化要操作浏览器以及浏览器页面元素,这里笔者就将浏览器及页面元素常用的函数及变量整理总结一下,以供读者在编写网页自动化测试时查阅. from selenium import webdrive ...
随机推荐
- P3302 [SDOI2013]森林(主席树+启发式合并)
P3302 [SDOI2013]森林 主席树+启发式合并 (我以前的主席树板子是错的.......坑了我老久TAT) 第k小问题显然是主席树. 我们对每个点维护一棵包含其子树所有节点的主席树 询问(x ...
- MySql数据库表操作(二)
一.增加表记录: insert [into] tab_name (field1,field2....) values (values1,values2....) , (values1,values2. ...
- 20145308 《网络对抗》Web安全基础实践 学习总结
20145308 <网络对抗> Web安全基础实践 学习总结 实验内容 本实践的目标理解常用网络攻击技术的基本原理.Webgoat实践下相关实验. 基础问题回答 (1)SQL注入攻击原理, ...
- 2018年11月22日 字典 E18灯翼平整度 D&G is SB
如果创建的东西需要增加修改的,则用list 如果不能修改就用元祖,如果需要修改这需要转成list 字典 字典的value是任意值 info= {"k1":'v1',"k2 ...
- topcoder srm 320 div1
problem1 link 两个数字后面都有阶乘符号,可以抵消. import java.util.*; import java.math.*; import static java.lang.Mat ...
- 又是DataSnap的问题
最近在调试DataSnap的程序,突然发现TClientDataSet打不开了,报错为dsnap200.bpl的非法地址访问,如下图: 很是怪异,干脆新建工程,只有TSQLConnection.TSQ ...
- Python3 tkinter基础 Listbox Scrollbar 创建垂直滚动条
Python : 3.7.0 OS : Ubuntu 18.04.1 LTS IDE : PyCharm 2018.2.4 Conda ...
- HIHOcoder 1457 后缀自动机四·重复旋律7
思路 后缀自动机题目,题目本质上是要求求出所有不同的子串的和,SAM每个节点中存放的子串互不相同,所以对于每个节点的sum,可以发现是可以递推的,每个点对子节点贡献是sum[x]*10+c*sz[x] ...
- 文档对象模型DOM
文档对象模型 DOM 1 DOM概述 1.1 什么是DOM 文档对象模型 Document Object Model 提供给用户操作document obj 的标准接口 文档对象模型 是表示和操作 H ...
- centos7 修改密码
Centos7破解密码的方法 Centos7忘记密码 在工作或者自己练习的时候我们难免会大意忘掉自己的root密码,有些同学忘掉密码竟然第一选择是重装系统,工作中可万万使不得! 本篇博客将讲解 ...