大数据处理框架之Strom:Storm集群环境搭建
搭建环境
Red Hat Enterprise Linux Server release 7.3 (Maipo)
zookeeper-3.4.11
jdk1.7.0_80
Python 2.7.5 (https://www.cnblogs.com/kimyeee/p/7250560.html)
集群方案
机器:101 102 103
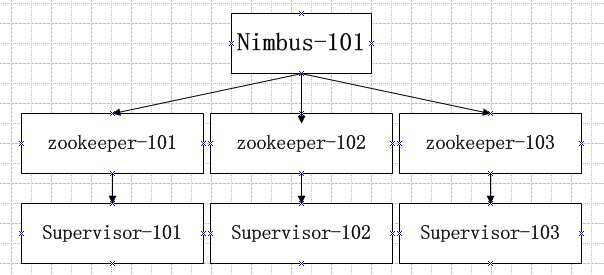
安装步骤
安装依赖jdk和python
[cluster@PCS101 ~]$ java -version
java version "1.7.0_80"
Java(TM) SE Runtime Environment (build 1.7.0_80-b15)
Java HotSpot(TM) -Bit Server VM (build 24.80-b11, mixed mode)
[cluster@PCS101 ~]$ python -V
Python 2.7.
1.解压storm
[cluster@PCS101 tars]$ tar -zxvf apache-storm-0.9.-incubating.tar.gz -C /home/cluster
#改名
[cluster@PCS101 ~]$ mv /home/cluster/apache-storm-0.9.-incubating apache-storm-0.9.
#创建任务目录
[cluster@PCS101 ~]$ mkdir /home/cluster/apache-storm-0.9./task
2.修改配置
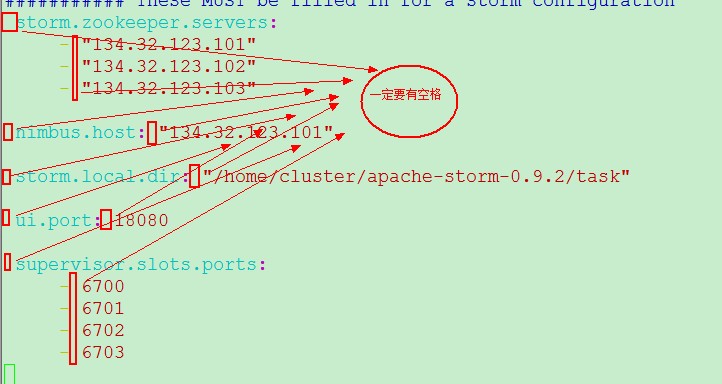
[cluster@PCS101 conf]$ vim /home/cluster/apache-storm-0.9./conf/storm.yaml
()zookeeper集群地址
storm.zookeeper.servers:
- "134.32.123.101"
- "134.32.123.102"
- "134.32.123.103" ()主节点Nimbus配置
nimbus.host: "134.32.123.101" ()设置storm运行任务执行的jar存放的目录
storm.local.dir: "/home/cluster/apache-storm-0.9.2/task" ()配置UI端口:ui.port
ui.port: ()配置worker而进程默认端口号,如果worker进程超过设置数量,则多出来的worker会随机分配端口
supervisor.slots.ports:
-
-
-
-
配置注意留有空格:
3.将101上的storm拷贝到102、103上
[cluster@PCS101 ~]$ scp -r /home/cluster/apache-storm-0.9./ cluster@134.32.123.102:/home/cluster/
[cluster@PCS101 ~]$ scp -r /home/cluster/apache-storm-0.9./ cluster@134.32.123.103:/home/cluster/
4.root用户修改系统环境变量
[root@PCS101 ~]# vim /etc/profile
export STORM_HOME=/home/cluster/apache-storm-0.9.
export PATH=$JAVA_HOME/bin:$MYSQL_BIN:$STORM_HOME/bin:$PATH
[root@PCS101 ~]# source /etc/profile
5.启动(保证zookeeper集群已启动)
按顺序启动:
启动Nimbus
134.32.123.101: 主机器(nimbus运行) : nohup storm nimbus > /dev/null >& &
[cluster@PCS101 ~]$ jps
QuorumPeerMain
Jps
nimbus
启动supervisor
134.32.123.101: 从机器(supervisor运行): nohup storm supervisor > /dev/null >& &
134.32.123.102: 从机器(supervisor运行): nohup storm supervisor > /dev/null >& &
134.32.123.103: 从机器(supervisor运行): nohup storm supervisor > /dev/null >& &
[cluster@PCS102 conf]$ jps
supervisor
Jps
QuorumPeerMain
启动UI (默认jetty做容器)
134.32.123.101: 主机器(ui运行) : nohup storm ui > /dev/null >& & (查看ui)
[cluster@PCS101 conf]$ jps
supervisor
QuorumPeerMain
nimbus
Jps
core
启动logviewer
134.32.123.101: 主机器(logviewer运行) : nohup storm logviewer > /dev/null >& &(查看工作日志)
[cluster@PCS101 conf]$ jps
supervisor
QuorumPeerMain
Jps
nimbus
logviewer
core
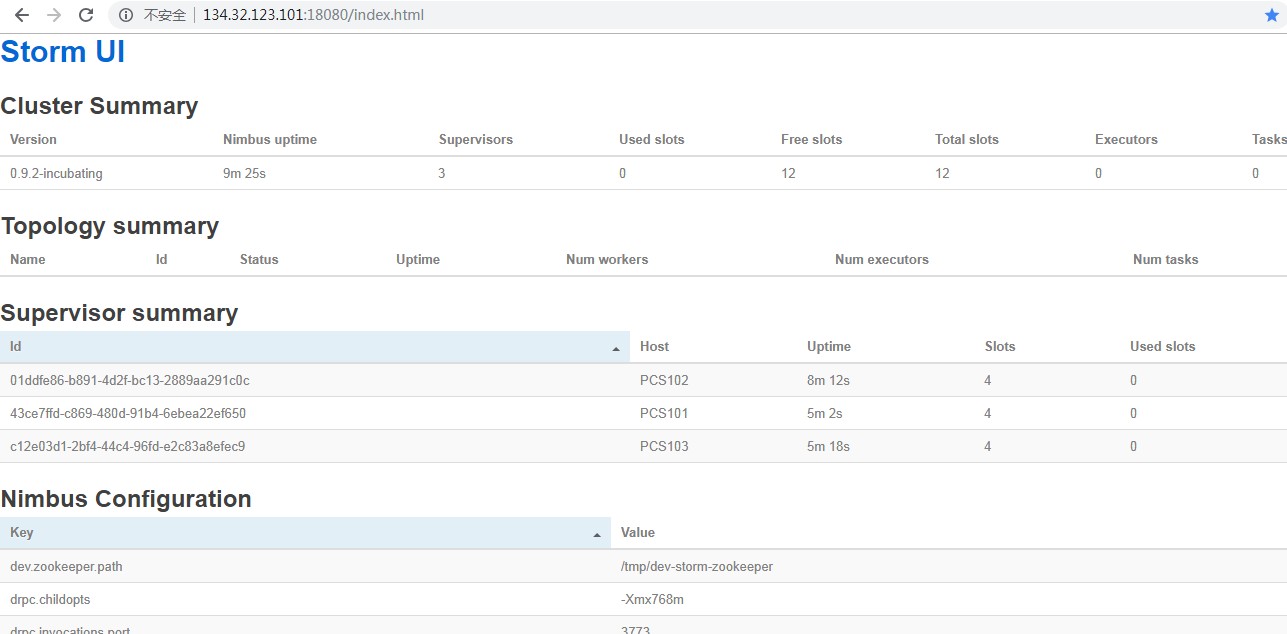
访问 StormUI
http://134.32.123.101:18080/
附一:伪分布式搭建
#storm帮助命令
[cluster@PCS101 ~]$ ./bin/storm --help #下面分别按照顺序启动ZooKeeper、Nimbus、UI、supervisor、logviewer
[cluster@PCS101 ~]$ ./bin/storm dev-zookeeper >> ./logs/zk.out 2>&1 &
[cluster@PCS101 ~]$ ./bin/storm nimbus >> ./logs/nimbus.out 2>&1 &
[cluster@PCS101 ~]$ ./bin/storm ui >> ./logs/ui.out 2>&1 &
[cluster@PCS101 ~]$ ./bin/storm supervisor >> ./logs/supervisor.out 2>&1 &
[cluster@PCS101 ~]$ ./bin/storm logviewer >> ./logs/logviewer.out 2>&1 &
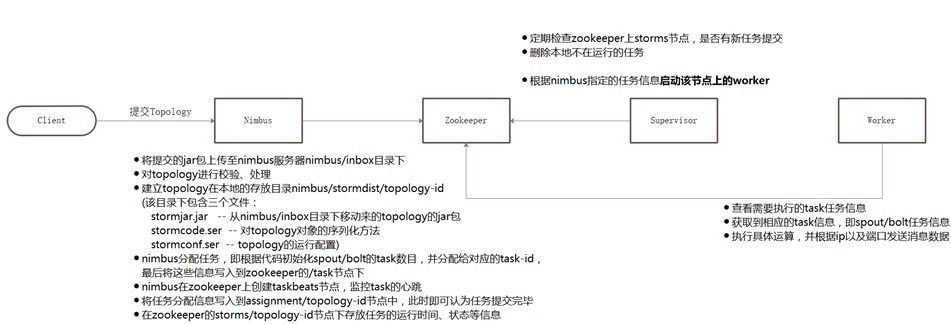
附二:storm提交任务流程
附三:storm本地目录树

附四:ZK目录树

参考:
大数据处理框架之Strom:Storm集群环境搭建的更多相关文章
- 一:Storm集群环境搭建
第一:storm集群环境准备及部署[1]硬件环境准备--->机器数量>=3--->网卡>=1--->内存:尽可能大--->硬盘:无额外需求[2]软件环境准备---& ...
- Storm —— 集群环境搭建
一.集群规划 这里搭建一个3节点的Storm集群:三台主机上均部署Supervisor和LogViewer服务.同时为了保证高可用,除了在hadoop001上部署主Nimbus服务外,还在hadoop ...
- Storm 学习之路(四)—— Storm集群环境搭建
一.集群规划 这里搭建一个3节点的Storm集群:三台主机上均部署Supervisor和LogViewer服务.同时为了保证高可用,除了在hadoop001上部署主Nimbus服务外,还在hadoop ...
- Storm 系列(四)—— Storm 集群环境搭建
一.集群规划 这里搭建一个 3 节点的 Storm 集群:三台主机上均部署 Supervisor 和 LogViewer 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Nimbus ...
- storm集群环境搭建
1.环境 Java环境 卸载虚机环境中自带的openJdk,安装sun的jdk,配置环境变量 2.安装storm 下载storm安装包 解压到安装目录,配置环境变量 vi /etc/profile # ...
- 大数据处理框架之Strom: Storm拓扑的并行机制和通信机制
一.并行机制 Storm的并行度 ,通过提高并行度可以提高storm程序的计算能力. 1.组件关系:Supervisor node物理节点,可以运行1到多个worker,不能超过supervisor. ...
- centos7:storm集群环境搭建
1.安装storm 下载storm安装包 在线下载 wget http://apache.fayea.com/storm/apache-storm-1.1.1/apache-storm-1.1.1.t ...
- 大数据hadoop入门学习之集群环境搭建集合
目录: 1.基本工作准备 1.虚拟机准备 2.java 虚拟机-jdk环境配置 3.ssh无密码登录 2.hadoop的安装与配置 3.hbase安装与配置(集成安装zookeeper) 4.zook ...
- 大数据处理框架之Strom: Storm----helloword
大数据处理框架之Strom: Storm----helloword Storm按照设计好的拓扑流程运转,所以写代码之前要先设计好拓扑图.这里写一个简单的拓扑: 第一步:创建一个拓扑类含有main方法的 ...
随机推荐
- JavaScript学习笔记--语言工具的了解
基础学习,快速入门资料:网站 https://www.liaoxuefeng.com ,http://www.runoob.com/js/js-tutorial.html 笔记: 编程工具:SubLi ...
- css自动换行如何设置?url太长会撑开页面
我们更新文章时如果有引用其他文章一般会带一个原文url,但这个链接如果太长的话会把内容的版块撑开,整个排版乱了.那我们能不能设置css自动换行呢?如下图所示,其实只要两个样式就能搞定 word-wra ...
- Navigator is deprecated and has been removed from this package
报错:'Navigator is deprecated and has been removed from this package. It can now be installed ' + ...
- 20170921 DEV功能页面
环境:vs2013 DEV第三方控件 后端使用Linq to sql , lambda 表达式 页面格式
- sap 程序之间的相互调用
1:首先进入到local object 目录下. 右键>create >function group,创建一个函数组. 右键创建类其它的东西 2:在创建的function group(fu ...
- [django]阅读笔记
https://dwz.cn/FUcnVGi8 新建目录 django-admin.exe startproject myblog django-admin.exe startproject mybl ...
- syslog-ng应用详解
syslog-ng应用详解 科技小能手 2017-11-07 02:43:00 浏览136 评论0 日志 LOG 配置 主机 syslog source file varchar 摘要: 最近做一 ...
- Linux下Nginx安装
前提: 1.需要gcc环境:yum install gcc-c++ 2.需要第三方开发包: PCRE.zlib.openssl yum install -y pcre pcre-devel yum i ...
- SQL简单操作
删除表数据,保留表结构: delete from employee 将删除所有的记录 delete from employee where lastname = 'May' 这条语句是从emplyee ...
- mac上命令行解压rar
时间进入到2018年12月,mac上好用的rar解压工具要收费了.被逼的没办法,用命令行吧,谁让咱擅长呢? 1,使用Homebrew安装unrar,没有自己装去 brew install unrar ...