Hanlp分词实例:Java实现TFIDF算法
算法介绍
最近要做领域概念的提取,TFIDF作为一个很经典的算法可以作为其中的一步处理。
关于TFIDF算法的介绍可以参考这篇博客http://www.ruanyifeng.com/blog/2013/03/tf-idf.html。
计算公式比较简单,如下:

预处理
由于需要处理的候选词大约后3w+,并且语料文档数有1w+,直接挨个文本遍历的话很耗时,每个词处理时间都要一分钟以上。
为了缩短时间,首先进行分词,一个词输出为一行方便统计,分词工具选择的是HanLp。
然后,将一个领域的文档合并到一个文件中,并用“$$$”标识符分割,方便记录文档数。

下面是选择的领域语料(PATH目录下):

代码实现
package edu.heu.lawsoutput;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* @ClassName: TfIdf
* @Description: TODO
* @author LJH
* @date 2017年11月12日 下午3:55:15
*/
public class TfIdf {
static final String PATH = "E:\\corpus"; // 语料库路径
public static void main(String[] args) throws Exception {
String test = "离退休人员"; // 要计算的候选词
computeTFIDF(PATH, test);
}
/**
* @param @param path 语料路经
* @param @param word 候选词
* @param @throws Exception
* @return void
*/
static void computeTFIDF(String path, String word) throws Exception {
File fileDir = new File(path);
File[] files = fileDir.listFiles();
// 每个领域出现候选词的文档数
Map<String, Integer> containsKeyMap = new HashMap<>();
// 每个领域的总文档数
Map<String, Integer> totalDocMap = new HashMap<>();
// TF = 候选词出现次数/总词数
Map<String, Double> tfMap = new HashMap<>();
// scan files
for (File f : files) {
// 候选词词频
double termFrequency = 0;
// 文本总词数
double totalTerm = 0;
// 包含候选词的文档数
int containsKeyDoc = 0;
// 词频文档计数
int totalCount = 0;
int fileCount = 0;
// 标记文件中是否出现候选词
boolean flag = false;
FileReader fr = new FileReader(f);
BufferedReader br = new BufferedReader(fr);
String s = "";
// 计算词频和总词数
while ((s = br.readLine()) != null) {
if (s.equals(word)) {
termFrequency++;
flag = true;
}
// 文件标识符
if (s.equals("$$$")) {
if (flag) {
containsKeyDoc++;
}
fileCount++;
flag = false;
}
totalCount++;
}
// 减去文件标识符的数量得到总词数
totalTerm += totalCount - fileCount;
br.close();
// key都为领域的名字
containsKeyMap.put(f.getName(), containsKeyDoc);
totalDocMap.put(f.getName(), fileCount);
tfMap.put(f.getName(), (double) termFrequency / totalTerm);
System.out.println("----------" + f.getName() + "----------");
System.out.println("该领域文档数:" + fileCount);
System.out.println("候选词出现词数:" + termFrequency);
System.out.println("总词数:" + totalTerm);
System.out.println("出现候选词文档总数:" + containsKeyDoc);
System.out.println();
}
//计算TF*IDF
for (File f : files) {
// 其他领域包含候选词文档数
int otherContainsKeyDoc = 0;
// 其他领域文档总数
int otherTotalDoc = 0;
double idf = 0;
double tfidf = 0;
System.out.println("~~~~~" + f.getName() + "~~~~~");
Set<Map.Entry<String, Integer>> containsKeyset = containsKeyMap.entrySet();
Set<Map.Entry<String, Integer>> totalDocset = totalDocMap.entrySet();
Set<Map.Entry<String, Double>> tfSet = tfMap.entrySet();
// 计算其他领域包含候选词文档数
for (Map.Entry<String, Integer> entry : containsKeyset) {
if (!entry.getKey().equals(f.getName())) {
otherContainsKeyDoc += entry.getValue();
}
}
// 计算其他领域文档总数
for (Map.Entry<String, Integer> entry : totalDocset) {
if (!entry.getKey().equals(f.getName())) {
otherTotalDoc += entry.getValue();
}
}
// 计算idf
idf = log((float) otherTotalDoc / (otherContainsKeyDoc + 1), 2);
// 计算tf*idf并输出
for (Map.Entry<String, Double> entry : tfSet) {
if (entry.getKey().equals(f.getName())) {
tfidf = (double) entry.getValue() * idf;
System.out.println("tfidf:" + tfidf);
}
}
}
}
static float log(float value, float base) {
return (float) (Math.log(value) / Math.log(base));
}
}
运行结果
测试词为“离退休人员”,中间结果如下:
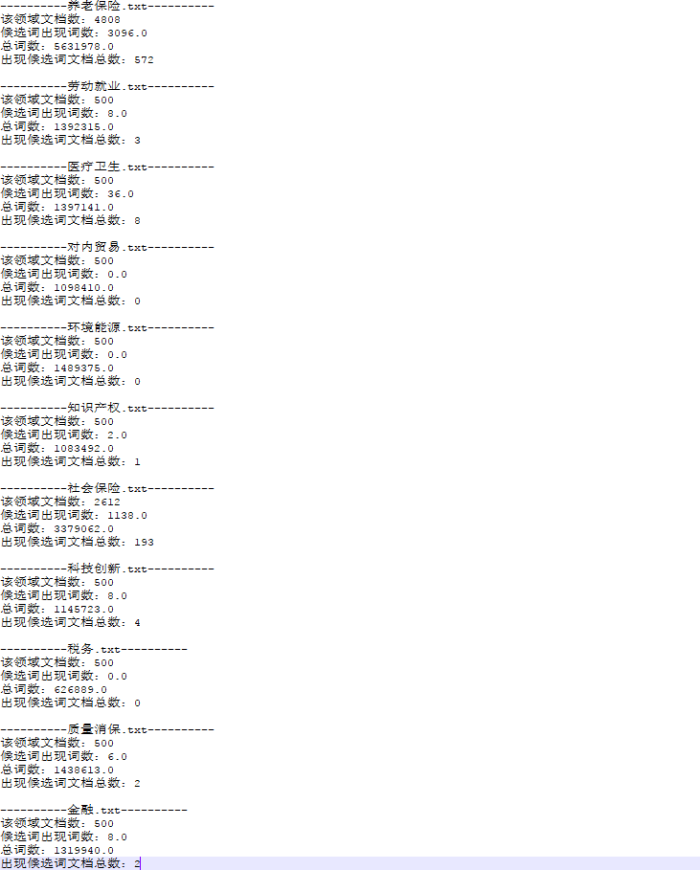
最终结果:
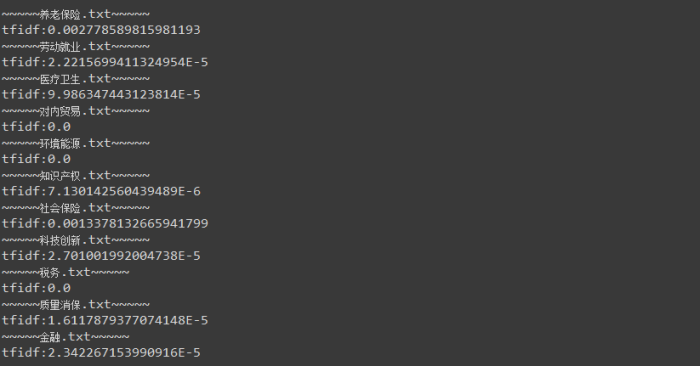
结论
可以看到“离退休人员”在养老保险和社保领域,tfidf值比较高,可以作为判断是否为领域概念的一个依据。当然TF-IDF算法虽然很经典,但还是有许多不足,不能单独依赖其结果做出判断。很多论文提出了改进方法,本文只是实现了最基本的算法。如果有其他思路和想法欢迎讨论。
文章转载自http://www.cnblogs.com/justcooooode 没课割绿地 的博客
Hanlp分词实例:Java实现TFIDF算法的更多相关文章
- Java实现TFIDF算法
算法介绍 最近要做领域概念的提取,TFIDF作为一个很经典的算法可以作为其中的一步处理. 关于TFIDF算法的介绍可以参考这篇博客http://www.ruanyifeng.com/blog/2013 ...
- NLP自然语言处理中的hanlp分词实例
本篇分享的依然是关于hanlp的分词使用,文章内容分享自 gladosAI 的博客,本篇文章中提出了一个问题,hanlp分词影响了实验判断结果.为何会如此,不妨一起学习一下 gladosAI 的这篇文 ...
- Java-Runoob-高级教程-实例-方法:03. Java 实例 – 汉诺塔算法-un
ylbtech-Java-Runoob-高级教程-实例-方法:03. Java 实例 – 汉诺塔算法 1.返回顶部 1. Java 实例 - 汉诺塔算法 Java 实例 汉诺塔(又称河内塔)问题是源 ...
- 基于结构化平均感知机的分词器Java实现
基于结构化平均感知机的分词器Java实现 作者:hankcs 最近高产似母猪,写了个基于AP的中文分词器,在Bakeoff-05的MSR语料上F值有96.11%.最重要的是,只训练了5个迭代:包含语料 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:tf-idf算法
实验目的 通过实验了解tf-idf算法原理 通过实验了解mapreduce的更多组件 学会自定义分区,读写缓存文件 了解mapreduce程序的设计方法 实验原理 1.TF-IDF简介 TF-IDF( ...
- HanLP分词命名实体提取详解
HanLP分词命名实体提取详解 分享一篇大神的关于hanlp分词命名实体提取的经验文章,文章中分享的内容略有一段时间(使用的hanlp版本比较老),最新一版的hanlp已经出来了,也可以去看看新版 ...
- HanLP分词研究
这篇文章主要是记录HanLP标准分词算法整个实现流程. HanLP的核心词典训练自人民日报2014语料,语料不是完美的,总会存在一些错误.这些错误可能会导致分词出现奇怪的结果,这时请打开调试模式排查问 ...
- hanlp分词工具应用案例:商品图自动推荐功能的应用
本篇分享一个hanlp分词工具应用的案例,简单来说就是做一图库,让商家轻松方便的配置商品的图片,最好是可以一键完成配置的. 先看一下效果图吧: 商品单个推荐效果:匹配度高的放在最前面 这个想法很好,那 ...
- Java常用排序算法+程序员必须掌握的8大排序算法+二分法查找法
Java 常用排序算法/程序员必须掌握的 8大排序算法 本文由网络资料整理转载而来,如有问题,欢迎指正! 分类: 1)插入排序(直接插入排序.希尔排序) 2)交换排序(冒泡排序.快速排序) 3)选择排 ...
随机推荐
- 什么是wsgi,uwsgi,uWSGI
WSGI: web服务器网关接口,是一套协议.用于接收用户请求将请求进行初次封装,然后将请求交给web框架 实现wsgi协议的模块: 1,wsgiref,本质就是编写一个socket服务端,用于接收用 ...
- vuejs中v-bind绑定class时的注意事项
关于v-bind绑定class的实例 作用:可用于不同样式之间的切换 <!DOCTYPE html> <html lang="en"> <head&g ...
- svg相关
1.指定点缩放公式 translate(-centerX*(factor-1), -centerY*(factor-1)) scale(factor)
- 基于NEO的私链(Private Blockchain)
1.准备工作 1.NEO-GUI 2.NEO-CLI 3..NET Core Runtime (不能是2.x版本,官方建议是1.12,实际上我用1.14也是没有问题的) 4.四台windows操作系统 ...
- m3u8编码视频webgl、threejs渲染视频纹理demo
<!DOCTYPE html> <html> <head> <meta charset=utf-8 /> <title>fz-live< ...
- centos7 安装mysql--python模块出现EnvironmentError: mysql_config not found和error: command 'gcc' failed with exit status 1
要想使python可以操作mysql 就需要MySQL-python驱动,它是python 操作mysql必不可少的模块. 下载地址:https://pypi.python.org/pypi/MySQ ...
- tmux允许鼠标滚动
/********************************************************************** * tmux允许鼠标滚动 * 说明: * 默认tmux貌 ...
- ldd 查看程序依赖库
ldd 查看程序依赖库 https://linuxtools-rst.readthedocs.io/zh_CN/latest/tool/ldd.html
- [LeetCode&Python] Problem 427. Construct Quad Tree
We want to use quad trees to store an N x N boolean grid. Each cell in the grid can only be true or ...
- 区块链与Git版本工具的比较
区块链与Git版本工具的比较 来源:http://www.jianshu.com/p/b96b98983df6 作者: 梁波林 相同点: 1. 分布式存储方案 2. 链式数据 3. 去中心化 4. ...