Java使用极小的内存完成对超大数据的去重计数,用于实时计算中统计UV
Java使用极小的内存完成对超大数据的去重计数,用于实时计算中统计UV – lxw的大数据田地 http://lxw1234.com/archives/2015/09/516.htm
Java使用极小的内存完成对超大数据的去重计数,用于实时计算中统计UV
关键字:streamlib、基数估计、实时计算uv、大数据、去重计数
一直在想如何在实时计算中完成对海量数据去重计数的功能,即SELECT COUNT(DISTINCT) 的功能。比如:从每天零点开始,实时计算全站累计用户数(UV),以及某些组合维度上的用户数,这里的用户假设以Cookieid来计。
想想一般的解决办法,在内存中使用HaspMap、HashSet?或者是在Redis中以Cookieid为key?感觉都不合适,在数以亿计用户的业务场景下,内存显然也成了瓶颈。
如果说,实时计算的业务场景中,对UV的计算精度并不要求100%(比如:实时的监测某一网站的PV和UV),那么可以考虑采用基数估计算法来统计。这里有一个Java的实现版本 stream-lib:https://github.com/addthis/stream-lib
采用基数估计算法目的就是为了使用很小的内存,即可完成超大数据的去重计数。号称是只使用几KB的内存,就可以完成对数以条数据的去重计数。但基数估计算法都不是100%精确的,误差在0~2%之间,一般是1%左右。
本文使用stream-lib来尝试对两个数据集进行去重计数。相关的文档和下载见文章最后。
测试数据集1:
- 文件名:small_cookies.txt
- 文件内容:每个cookieid一行
- 文件总记录数:14892708
- 去重记录数:3896911
- 文件总大小:350153062(约334M)
- [liuxiaowen@dev site_raw_log]$ head -5 small_cookies.txt
- 7EDCF13A03D387548FB2B8
- da5f0196-56036078075b9f-14892137
- 1D0A83B604ADD4558970EE
- 3DF76E7100025F553B1980
- 72C756700C3CAA56035EE0
- [liuxiaowen@dev site_raw_log]$ wc -l small_cookies.txt
- 14892708 small_cookies.txt
- [liuxiaowen@dev site_raw_log]$ awk '!a[$0]++{print $0}' small_cookies.txt | wc -l
- 3896911
- [liuxiaowen@dev site_raw_log]$ ll small_cookies.txt
- -rw-rw-r--. 1 liuxiaowen liuxiaowen 350153062 Sep 25 10:50 small_cookies.txt
测试数据集2:
- 文件名:big_cookies.txt
- 文件内容:每个cookieid一行
- 文件总记录数:547631464
- 去重记录数:190264959
- 文件总大小:12610638153(约11.8GB)
- --总记录数
- spark-sql> select count(1) from big_cookies;
- 547631464
- Time taken: 7.311 seconds, Fetched 1 row(s)
- --去重记录数
- spark-sql> select count(1) from (select cookieid from big_cookies group by cookieid) x;
- 190264959
- Time taken: 80.516 seconds, Fetched 1 row(s)
- hadoop fs -getmerge /hivedata/warehouse/liuxiaowen.db/big_cookies/* big_cookies.txt
- [liuxiaowen@dev site_raw_log]$ wc -l big_cookies.txt
- 547631464 cookies.txt
- //总大小
- [liuxiaowen@dev site_raw_log]$ ll big_cookies.txt
- -rw-r--r--. 1 liuxiaowen liuxiaowen 12610638153 Sep 25 13:25 big_cookies.txt
普通方法测试
所谓普通方法,就是遍历文件,将所有cookieid放到内存的HashSet中,而HashSet的size就是去重记录数。
代码如下:
- package com.lxw1234.streamlib;
- import java.io.BufferedReader;
- import java.io.File;
- import java.io.FileReader;
- import java.io.IOException;
- import java.util.HashSet;
- import java.util.Set;
- public class Test {
- public static void main(String[] args) {
- Runtime rt = Runtime.getRuntime();
- Set set = new HashSet();
- File file = new File(args[0]);
- BufferedReader reader = null;
- long count = 0l;
- try {
- reader = new BufferedReader(new FileReader(file));
- String tempString = null;
- while ((tempString = reader.readLine()) != null) {
- count++;
- set.add(tempString);
- if(set.size() % 5000 == 0) {
- System.out.println("Total count:[" + count + "] Unique count:[" + set.size() + "] FreeMemory:[" + rt.freeMemory() + "] ..");
- }
- }
- reader.close();
- } catch (Exception e) {
- e.printStackTrace();
- } finally {
- if (reader != null) {
- try {
- reader.close();
- } catch (IOException e1) {}
- }
- }
- System.out.println("Total count:[" + count + "] Unique count:[" + set.size() + "] FreeMemory:[" + rt.freeMemory() + "] ..");
- }
- }
指定使用10M的内存运行,命令为:
- java -cp /tmp/teststreamlib.jar -Xms10M -Xmx10M -XX:PermSize=10M -XX:MaxPermSize=10M \
- com.lxw1234.streamlib.Test /home/liuxiaowen/site_raw_log/small_cookies.txt
运行结果如下:
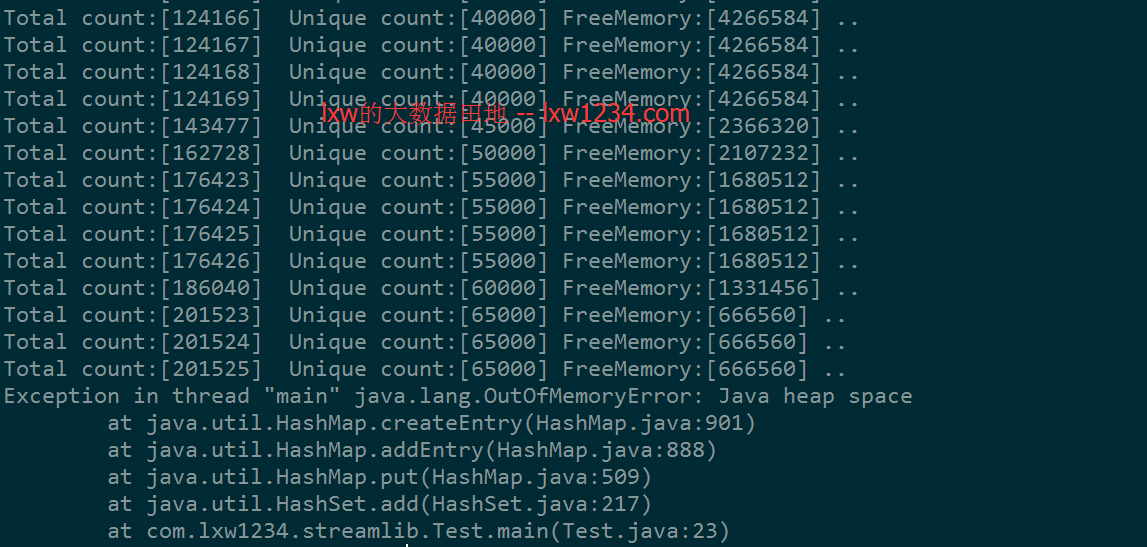
10M的内存,仅仅够存65000左右的cookieid,之后就报错,内存不够了。大数据集更不用说。
基数估计方法测试
采用streamlib中的基数估计算法实现ICardinality,对两个结果集的总记录数和去重记录数进行统计,代码如下:
- package com.lxw1234.streamlib;
- import java.io.BufferedReader;
- import java.io.File;
- import java.io.FileReader;
- import java.io.IOException;
- import com.clearspring.analytics.stream.cardinality.AdaptiveCounting;
- import com.clearspring.analytics.stream.cardinality.ICardinality;
- public class TestCardinality {
- public static void main(String[] args) {
- Runtime rt = Runtime.getRuntime();
- long start = System.currentTimeMillis();
- long updateRate = 1000000l;
- long count = 0l;
- ICardinality card = AdaptiveCounting.Builder.obyCount(Integer.MAX_VALUE).build();
- File file = new File(args[0]);
- BufferedReader reader = null;
- try {
- reader = new BufferedReader(new FileReader(file));
- String tempString = null;
- while ((tempString = reader.readLine()) != null) {
- card.offer(tempString);
- count++;
- if (updateRate > 0 && count % updateRate == 0) {
- System.out.println("Total count:[" + count + "] Unique count:[" + card.cardinality() + "] FreeMemory:[" + rt.freeMemory() + "] ..");
- }
- }
- reader.close();
- } catch (Exception e) {
- e.printStackTrace();
- } finally {
- if (reader != null) {
- try {
- reader.close();
- } catch (IOException e1) {}
- }
- }
- long end = System.currentTimeMillis();
- System.out.println("Total count:[" + count + "] Unique count:[" + card.cardinality() + "] FreeMemory:[" + rt.freeMemory() + "] ..");
- System.out.println("Total cost:[" + (end - start) + "] ms ..");
- }
- }
- 测试数据集1
指定使用10M的内存运行,测试数据集1命令为:
- java -cp /tmp/stream-2.9.1-SNAPSHOT.jar:/tmp/teststreamlib.jar -Xms10M -Xmx10M -XX:PermSize=10M -XX:MaxPermSize=10M \
- com.lxw1234.streamlib.TestCardinality /home/liuxiaowen/site_raw_log/small_cookies.txt
运行结果如下:
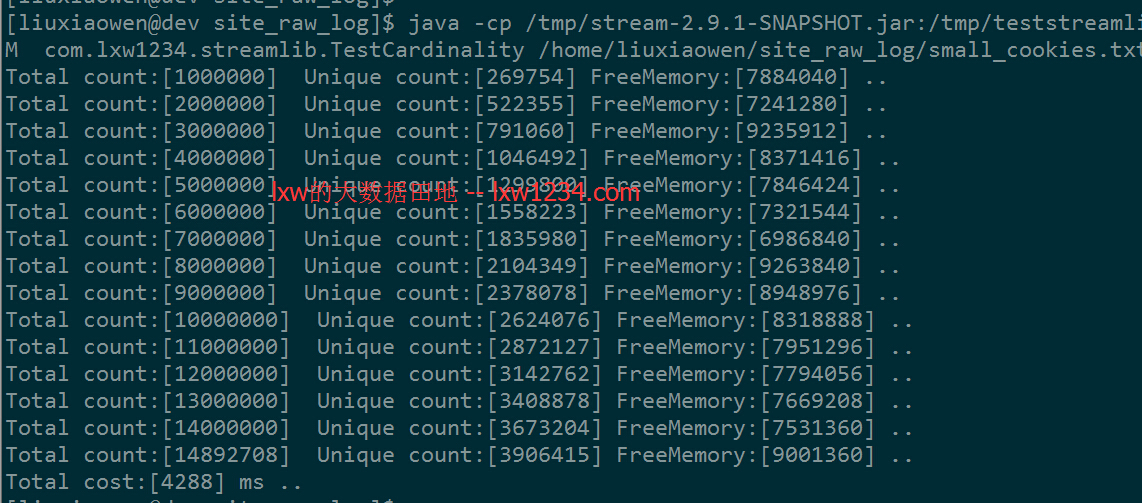
- 测试数据集2
同样指定使用10M的内存运行,测试数据集2命令为:
- java -cp /tmp/stream-2.9.1-SNAPSHOT.jar:/tmp/teststreamlib.jar -Xms10M -Xmx10M -XX:PermSize=10M -XX:MaxPermSize=10M \
- com.lxw1234.streamlib.TestCardinality /home/liuxiaowen/site_raw_log/big_cookies.txt
运行结果为:
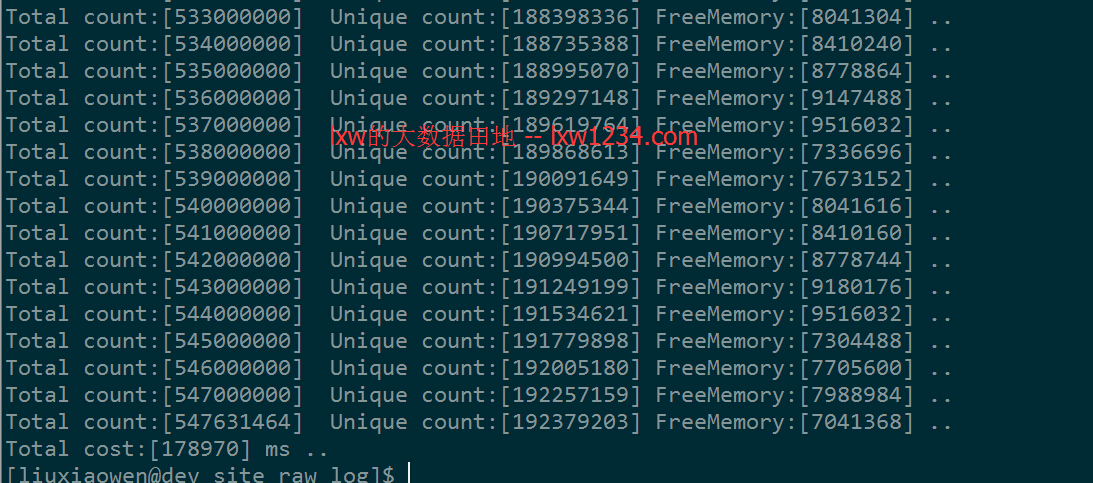
测试结果

测试结果来看,基数估计算法统计的结果中误差的确是0~2%,如果可以接受这个误差,那么这个方案完全可以用于实时计算中的不同维度UV统计中。
从运行结果图上可以看到,虽然指定了10M内存,但空闲内存(FreeMemory)一直在差不多7M以上,也就是说,5.4亿的数据去重计数,也仅仅使用了3M左右的内存。
相关下载
以上程序需要依赖stream-2.9.1-SNAPSHOT.jar,我编译好了一份,
你也可以从官网中下载源码,编译。
相关文章:
http://blog.csdn.net/hguisu/article/details/8433731
http://m.oschina.net/blog/315457
您可以关注 lxw的大数据田地 ,或者 加入邮件列表 ,随时接收博客更新的通知邮件。
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » Java使用极小的内存完成对超大数据的去重计数,用于实时计算中统计UV
Java使用极小的内存完成对超大数据的去重计数,用于实时计算中统计UV的更多相关文章
- JAVA虚拟机运行时内存划分--运行时数据区域
Java虚拟机在执行java程序时会把内存划分为以下几个不同的数据区域: java虚拟机内存划分(运行时)1.线程私有的: 程序计数器(Program Counter Register):可以看作当前 ...
- java接口对接——别人调用我们接口获取数据
java接口对接——别人调用我们接口获取数据,我们需要在我们系统中开发几个接口,给对方接口规范文档,包括访问我们的接口地址,以及入参名称和格式,还有我们的返回的状态的情况, 接口代码: package ...
- 如何计算Java对象所占内存的大小
[ 简单总结: 随便一个java项目,引入jar包: lucene-core-4.0.0.jar 如果是 maven项目,直接用如下依赖: <dependency> <groupId ...
- 深入理解Java虚拟机之JVM内存布局篇
内存布局**** JVM内存布局规定了Java在运行过程中内存申请.分配.管理的策略,保证了JVM的稳定高效运行.不同的JVM对于内存的划分方式和管理机制存在部分差异.结合JVM虚拟机规范,一起来 ...
- 死磕内存篇 --- JAVA进程和linux内存间的大小关系
运行个JAVA 用sleep去hold住 package org.hjb.test; public class TestOnly { public static void main(String[] ...
- Java内存区域-- 运行时数据区域
jvm在执行Java程序时,会把它所管理的内存划分为若干个不同的数据区.这些区域都有各自的用途,以及创建和销毁的时间. 有的区域随着虚拟机进程的启动而存在,有些区域则依赖用户线程的启动和结束而建立和销 ...
- JAVA基础知识点:内存、比较和Final
1.java是如何管理内存的 java的内存管理就是对象的分配和释放问题.(其中包括两部分) 分配:内存的分配是由程序完成的,程序员需要通过关键字new为每个对象申请内存空间(基本类型除外),所有的对 ...
- java\c程序的内存分配
JAVA 文件编译执行与虚拟机(JVM)介绍 Java 虚拟机(JVM)是可运行Java代码的假想计算机.只要根据JVM规格描述将解释器移植到特定的计算机上,就能保证经过编译的任何Java代码能够在该 ...
- [转]使用Java Mission Control进行内存分配分析
jdk7u40自带了一个非常好用的工具,就是Java Mission Control.JRockit Misson Control用户应该会对mission control的很多功能十分熟悉,JRoc ...
随机推荐
- windowmasker 标记基因组中的重复序列和低复杂度序列
下载地址:ftp://ftp.ncbi.nlm.nih.gov/pub/agarwala/windowmasker/ 在这个目录下 其中windowmasker 为linux 平台的可执行文件 win ...
- 在Terminal中的光标的使用技巧
如何简单操作? 在 Terminal(终端) 中,有许多操作技巧,这里就介绍几个简单的. 光标 up(方向键上) 可以调出输入历史执行记录,快速执行命令 down(方向键下) 配合 up 选择历史执行 ...
- [转]五分钟看懂UML类图与类的关系详解
在画类图的时候,理清类和类之间的关系是重点.类的关系有泛化(Generalization).实现(Realization).依赖(Dependency)和关联(Association).其中关联又分为 ...
- OpenCV学习:OpenCV文件一览
了解一些OpenCV代码整体的模块结构后,再重点学习自己感兴趣的部分,会有一种一览众山小的感觉~ Come on! C:\OpenCV\opencv\build\include文件夹下包含两个文件夹: ...
- 换个思路理解Javascript中的this
https://segmentfault.com/a/1190000010328752
- mybatise 动态sql
1. <if><choose> 动态sql 相当 <if> Java if 满足多个条件 <choose> <when> java ...
- [extjs] ExtJS 4.2 开发环境搭建
到官网下载Extjs ,现在最新版的是Ext5.1. 这里用ext4.2演示开发.http://extjs.org.cn/. EXT4.1 在线API 项目结构中ext4.2导入的资源文件: 第一个页 ...
- Java精选笔记_JDBC
JDBC 概述 什么是JDBC JDBC全称是Java数据库连接(Java Database Connectivity),应用程序可通过这套API连接到关系数据库,并使用SQL语句来完成对数据库中数据 ...
- shell基础(七)-条件语句
条件语句在编写脚本经常遇到:用于处理逻辑问题. 一 IF 语句 if 语句通过关系运算符判断表达式的真假来决定执行哪个分支.Shell 有三种 if ... else 语句: if ... fi 语句 ...
- Linux 下配置网卡的别名即网卡子IP的配置
what 什么是ip别名?用windows的话说,就是为一个网卡配置多个ip.when 什么场合增加ip别名能派上用场?布网需要.多ip访问测试.特定软件对多ip的需要...and so on. ho ...