Andrew Ng机器学习公开课笔记 -- Generalized Linear Models
网易公开课,第4课
notes,http://cs229.stanford.edu/notes/cs229-notes1.pdf
前面介绍一个线性回归问题,符合高斯分布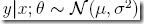
一个分类问题,logstic回归,符合伯努利分布
也发现他们有些相似的地方,其实这些方法都是一个更广泛的模型族的特例,这个模型族称为,广义线性模型(Generalized Linear Models,GLMs)
The exponential family
为了介绍GLMs,先需要介绍指数族分布(exponential family distributions)
参考,http://en.wikipedia.org/wiki/Exponential_family
The exponential families include many of the most common distributions, including the normal, exponential, gamma, chi-squared, beta, Dirichlet, Bernoulli, categorical, Poisson, Wishart, Inverse Wishart and many others.
这种分布族包含了很多常见的分布,其中包含了上面提到的高斯分布和伯努利分布
定义如下, 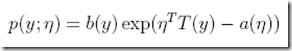
η is called the natural parameter (also called the canonical parameter) of the distribution
T(y) is the sufficient statistic (for the distributions we consider, it will often be the case that T(y) = y)
a(η) is the log partition function. The quantity 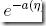 essentially plays the role of a normalization constant, that makes sure the distribution p(y; η) sums/integrates over y to 1.
essentially plays the role of a normalization constant, that makes sure the distribution p(y; η) sums/integrates over y to 1.
这个定义本身不那么好理解,不需要去理解它
当选定T,a和b这3个function时,就可以确定一种以η为参数的分布,比如以η为参数的高斯分布或伯努利分布
下面就看看从高斯分布或伯努利分布如何转换为指数族分布的形式,并且各自具体参数是什么?
伯努利分布的转换过程 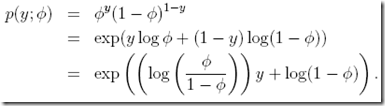
其中, 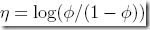 ,即
,即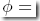
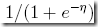
可以看到这就是logistic函数或sigmoid函数
之前只是单纯从分布图上说看上去使用logistic函数比线性更好
这里直接可以从伯努利分布推导出,需要使用logistic函数,参考后面的推导
另外的参数为, 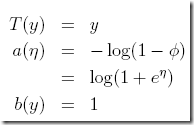
高斯分布的转换过程,
设 ,因为这个参数对回归结果没有影响,设什么都行,1更方便点
,因为这个参数对回归结果没有影响,设什么都行,1更方便点 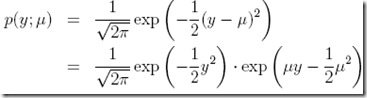
其中, 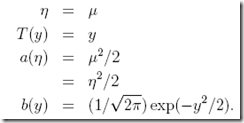
前面说了,指数族分布包含很多常用的分布,包含泊松分布。。。
这里以高斯和伯努利为例,当然其他的分布也可以完成这样的转换
Constructing GLMs
这里我们需要看看如何使用GLMs来解决分类和回归问题
如果要用GLMs来解决这个问题,需要基于下面的3个假设
To derive a GLM for this problem, we will make the following three assumptions about the conditional distribution of y given x and about our
model:
1. y | x; θ ∼ ExponentialFamily(η). I.e., given x and θ, the distribution of
y follows some exponential family distribution, with parameter η.
首先是符合ExponentialFamily分布,这是使用GLMs的前提
2. Given x, our goal is to predict the expected value of T(y) given x.
In most of our examples, we will have T(y) = y, so this means we would like the prediction h(x) output by our learned hypothesis h to satisfy h(x) = E[y|x]. (Note that this assumption is satisfied in the choices for h(x) for both logistic regression and linear regression. For instance, in logistic regression, we had h(x) = p(y = 1|x; θ) = 0 · p(y = 0|x; θ) + 1 · p(y = 1|x; θ) = E[y|x; θ].)
学习到的hypothesis h满足,h(x) = E[y|x]
可以看到前面在logistic回归中,我们选择的h(x)是满足这个假设的
3. The natural parameter η and the inputs x are related linearly: 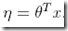
(Or, if η is vector-valued, then 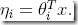 )
)
最后一个假设为,η和输入x满足线性关系
这条假设可以看成是一种”design choice”
基于上面3条假设,我们就可以GLMs学习算法来优雅的解决问题
下面看看如何基于上面假设来推导出线性回归和logistic回归的hypothesis h
前面碰到问题,都是直接先给出h,并没有说明为什么
这里可以通过GLMs,对特定问题和分布推导出h
线性回归
h(x) = E[y|x; θ] //根据假设2
= μ //对于高斯分布,分布的期望为μ
= η //在由高斯分布转换到指数族分布时,得到μ=η
= 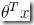 //根据假设3
//根据假设3
Logistic回归
h(x) = E[y|x; θ]
= φ
= 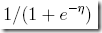
= 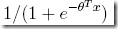
推导理由基本和上面的一样
Softmax回归
Logistic回归可以解决二元分类问题,但是对于多元分类,就需要使用Softmax回归来解决,比如对于邮件不是仅仅分为spam和not-spam,而是分为spam,personal,work
所以数据的分布也变成多项分布(multinomial distribution),是二项分布的推广
那么要解决这个问题,首先需要把多项分布转化为指数族分布
先声明一些假设,
假设有k个输出(k类),分到每类的概率为φ1, . . . , φk(对于二项分布为φ和1-φ)
φi = p(y = i; φ)
其实φk可以表示为,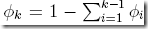
所以我们只需要定义 即可
即可
另外这里需要定义T(y),虽然一般都是等于y,但这里T(y)为向量表示为 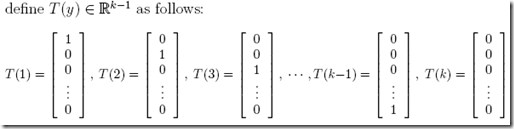

继续定义一个操作符,1{·}
(1{True} = 1, 1{False} = 0). For example, 1{2 = 3} = 0, and 1{3 =
5 − 2} = 1.
所以有,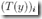 可以表示为
可以表示为  ,比较好理解,只有y=i时,才是1,其他都是0
,比较好理解,只有y=i时,才是1,其他都是0
进一步可以得到, 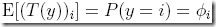 ,因为求期望时,其他项都是×0,只会留下这项
,因为求期望时,其他项都是×0,只会留下这项
下面给出多项分布的转换过程, 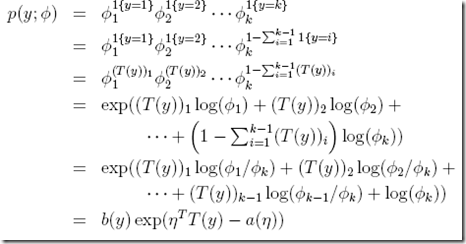
首先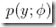 为何等于
为何等于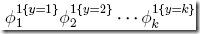
可以参考二项分布,这里只是简单的扩展,同样只会留下一项,其他项都为1
剩下的是基于前面假设的一些替换,
最终得到参数为,
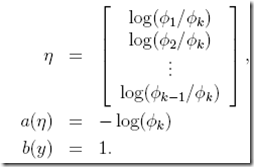
这里得到η和φ的关系,我们可以反推出,过程参考讲义 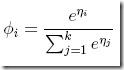 ,根据GLMs第三假设,
,根据GLMs第三假设,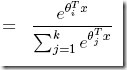
前面知道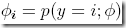 ,所以带入得到
,所以带入得到

到了这边,我们就可以用最大似然法来解决这个问题了 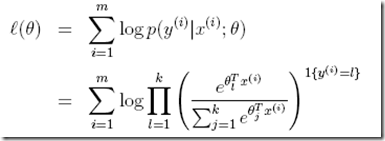
后面可以使用梯度上升或牛顿法来求解
同时根据GLMs第二假设,也可以给出hypothesis h 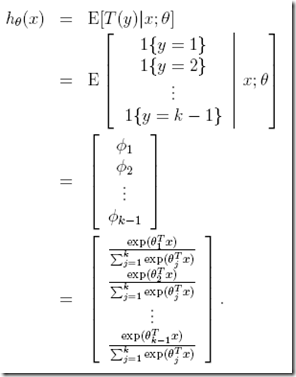
可见解决这类问题的关键就是推出p(y|x; θ)
因为有了这个,后面就可以使用最大似然法求解
对于logistic回归, 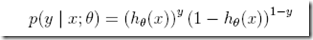
对于softmax回归,
而使用GLMs算法就可以直接的或间接的推导出p(y|x; θ)
首先通过统计分布函数可以得到P(y|φ), φ是参数,比如对于伯努利分布
可是为了拟合样本点,我们需要得到p(y|x; θ),可是如果将φ转换成x
那么在GLMs中,通过转换,可以找到η和φ的关系
并且根据假设3,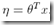 ,所以通过GLMs我们就可以推导出p(y|x; θ)
,所以通过GLMs我们就可以推导出p(y|x; θ)
我的理解,之所以成为广义线性模型
就是因为假设3,η和x是成线性关系的
虽然对于大部分的模型,都需要再进行一次指数族的转换才能得到H
特例就是线性回归,不需要做转换,H=η
Andrew Ng机器学习公开课笔记 -- Generalized Linear Models的更多相关文章
- 广义线性模型 - Andrew Ng机器学习公开课笔记1.6
在分类问题中我们如果: 他们都是广义线性模型中的一个样例,在理解广义线性模型之前须要先理解指数分布族. 指数分布族(The Exponential Family) 假设一个分布能够用例如以下公式表达, ...
- Andrew Ng机器学习公开课笔记 -- 支持向量机
网易公开课,第6,7,8课 notes,http://cs229.stanford.edu/notes/cs229-notes3.pdf SVM-支持向量机算法概述, 这篇讲的挺好,可以参考 先继 ...
- Andrew Ng机器学习公开课笔记–Principal Components Analysis (PCA)
网易公开课,第14, 15课 notes,10 之前谈到的factor analysis,用EM算法找到潜在的因子变量,以达到降维的目的 这里介绍的是另外一种降维的方法,Principal Compo ...
- Andrew Ng机器学习公开课笔记 -- 学习理论
网易公开课,第9,10课 notes,http://cs229.stanford.edu/notes/cs229-notes4.pdf 这章要讨论的问题是,如何去评价和选择学习算法 Bias/va ...
- Andrew Ng机器学习公开课笔记 -- Regularization and Model Selection
网易公开课,第10,11课 notes,http://cs229.stanford.edu/notes/cs229-notes5.pdf Model Selection 首先需要解决的问题是,模型 ...
- Andrew Ng机器学习公开课笔记–Reinforcement Learning and Control
网易公开课,第16课 notes,12 前面的supervised learning,对于一个指定的x可以明确告诉你,正确的y是什么 但某些sequential decision making问题,比 ...
- Andrew Ng机器学习公开课笔记 – Factor Analysis
网易公开课,第13,14课 notes,9 本质上因子分析是一种降维算法 参考,http://www.douban.com/note/225942377/,浅谈主成分分析和因子分析 把大量的原始变量, ...
- Andrew Ng机器学习公开课笔记 -- 线性回归和梯度下降
网易公开课,监督学习应用.梯度下降 notes,http://cs229.stanford.edu/notes/cs229-notes1.pdf 线性回归(Linear Regression) 先看个 ...
- Andrew Ng机器学习公开课笔记–Independent Components Analysis
网易公开课,第15课 notes,11 参考, PCA本质是旋转找到新的基(basis),即坐标轴,并且新的基的维数大大降低 ICA也是找到新的基,但是目的是完全不一样的,而且ICA是不会降维的 对于 ...
随机推荐
- apache Storm之一-入门学习
准备工作 这个教程使用storm-starter项目里面的例子.我推荐你们下载这个项目的代码并且跟着教程一起做.先读一下:配置storm开发环境和新建一个strom项目这两篇文章把你的机器设置好. 一 ...
- 重载 CreateParams 方法[1]: 从一个例子开始(取消窗口最大化、最小化按钮的三种方法)
方法1: 使用 TForm 的 BorderIcons 属性 unit Unit1; interface uses Windows, Messages, SysUtils, Variants, C ...
- ASP.NET MVC传递参数(model), 如何保持TempData的持久性
一看到此标题,相信你也会.因为路由是可以从URL地址栏传过去的. 但是Insus.NET不想在地址栏传递,还是一个条件是jQuery的Ajax进行POST的.Insus.NET不清楚别人是怎样处理的, ...
- error C2275: 'SOCKET' : illegal use of this type as an expression
在VC中编译xxx.c文件出现错误error C2275 illegal use of this type as an expression 问题在于C99之前要求所有的声明必须放在函数块的起始部分, ...
- c++ 类数据成员的定义、声明
C++为类中提供类成员的初始化列表类对象的构造顺序是这样的:1.分配内存,调用构造函数时,隐式/显示的初始化各数据成员2.进入构造函数后在构造函数中执行一般计算 1.类里面的任何成员变量在定义时是不 ...
- Python Scrapy初步使用
1.创建爬虫工程 scrapy startproject stockproject001 2.创建爬虫项目 cd stockproject001 scrapy genspider stockinfo ...
- python2.0_s12_day19_前端模版使用
Django中引用bootstrap实现在前端可以创建客户信息,可以修改客户信息我们需要设计一个前端用户交互系统.我们在设计之前,讨论一些需求:前端实现:1. 不同角色的用户,看到的东西是不一样的 销 ...
- linux 安装 nodejs
原文地址:https://nodejs.org/en/download/package-manager/#enterprise-linux-and-fedora 1)定位到nodejs的官方源(如果直 ...
- canvas一:基本认识
最近弄数据库弄得头大,想着没事整理一下画布canvas吧,毕竟canvas用途广泛,是html游戏开发必不可少的一环,也是h5新特性中的重中之重 首先canvas是一个html标签,可以给他设置一些c ...
- php第一例
参考 例子 https://www.cnblogs.com/chinajins/p/5622342.html 配置多个网站 https://blog.csdn.net/win7system/artic ...