RF/GBDT/XGBoost/LightGBM简单总结(完结)
这四种都是非常流行的集成学习(Ensemble Learning)方式,在本文简单总结一下它们的原理和使用方法.
Random Forest(随机森林):
- 随机森林属于Bagging,也就是有放回抽样,多数表决或简单平均.Bagging之间的基学习器是并列生成的.RF就是以决策树为基学习器的Bagging,进一步在决策树的训练过程中引入了随机特征选择,这会使单棵树的偏差增加,但总体而言有利于集成.RF的每个基学习器只使用了训练集中约63.2%的样本,剩下的样本可以用作袋外估计.
- 一般使用的是sklearn.ensemble中的RandomForestClassifier和RandomForestRegressor.
- 框架参数(相比GBDT较少,因为基学习器之间没有依赖关系):
- n_estimators=100:最大的基学习器的个数
- oob_score=False:是否采用袋外样本
- bootstrap=True:是否有放回采样
- n_jobs=1:并行job个数
- 决策树参数:
- max_features=None:划分时考虑的最大特征数,可选log2,sqrt,auto或浮点数按比例选择,也可以选整数按个数选择.
- max_depth:最大深度
- min_samples_split:内部节点划分所需最小样本数,如果样本小于这个值就不会再继续划分.
- min_saples_laef:叶子节点最少的样本数,小于这个值就会被剪枝.
- min_weight_fraction_leaf:叶子节点所有样本权重和的最小值
- max_leaf_nodes=None:最大叶子节点数,可以防止过拟合
- min_impurity_split:节点增长的最小不纯度
- criterion:CART树划分时对特征的评价标准,分类树默认gini,可选entropy,回归树默认mse,可选mae.
GBDT(梯度提升树)
- GBDT属于Boosting.它和Bagging都使用同样类型的分类器,区别是不同分类器通过串行训练获得,通过关注被已有分类器错分的数据来获得新的分类器.Boosting分类器的权重并不相等,每个权重对应分类器在上一轮迭代中的成功度.GBDT的关键是利用损失函数的负梯度方向作为残差的近似值,进而拟合出新的CART回归树.
- 一般使用的是sklearn.ensemble中的GradientBoostingClassifier和GradientBoostingRegressor.
- 框架参数:
- n_estimators=100:最大基学习器个数
- learning_rate=1:每个基学习器的权重缩减系数(步长)
- subsample=1.0:子采样,是不放回抽样,推荐值0.5~0.8
- loss:损失函数,分类模型默认deviance,可选exponential.回归模型默认ls,可选lad,huber和quantile.
- 决策树参数(与RF基本相同):
- max_features=None:划分时考虑的最大特征数,可选log2,sqrt,auto或浮点数按比例选择,也可以选整数按个数选择.
- max_depth:最大深度
- min_samples_split:内部节点划分所需最小样本数,如果样本小于这个值就不会再继续划分.
- min_saples_laef:叶子节点最少的样本数,小于这个值就会被剪枝.
- min_weight_fraction_leaf:叶子节点所有样本权重和的最小值
- max_leaf_nodes=None:最大叶子节点数,可以防止过拟合
- min_impurity_split:节点增长的最小不纯度
XGBoost
- 相比传统GBDT,XGBoost能自动利用CPU的多线程,支持线性分类器,使用二阶导数进行优化,在代价函数中加入了正则项,可以自动处理缺失值,支持并行(在特征粒度上的).
- 参考XGBoost python API和xgboost调参经验.
- 在训练过程一般用xgboost.train(),参数有:
- params:一个字典,训练参数的列表,形式是 {‘booster’:’gbtree’,’eta’:0.1}
- dtrain:训练数据
- num_boost_round:提升迭代的次数
- evals:用于对训练过程中进行评估列表中的元素
- obj:自定义目的函数
- feval:自定义评估函数
- maxmize:是否对评估函数最大化
- early_stopping_rounds:早停次数
- learning_rates:每一次提升的学习率的列表
- params参数:
- booster=gbtree:使用哪种基学习器,可选gbtree,gblinear或dart
- objective:目标函数,回归一般是reglinear,reg:logistic,count:poisson,分类一般是binary:logistic,rank:pairwise
- eta:更新中减少的步长
- max_depth:最大深度
- subsample:随即采样的比例
- min_child_weight:最小叶子节点样本权重和
- colsample_bytree:随即采样的列数的占比
- gamma:分裂最小loss,只有损失函数下降超过这个值节点才会分裂
- lambda:L2正则化的权重
LightGBM
- LightGBM是基于决策树的分布式梯度提升框架.它与XGBoost的区别是:
- 切分算法,XGBoost使用pre_sorted,LightGBM采用histogram.
- 决策树生长策略:XGBoost使用带深度限制的level-wise,一次分裂同一层的叶子.LightGBM采用leaf-wise,每次从当前所有叶子找到一个分裂增益最大的叶子.
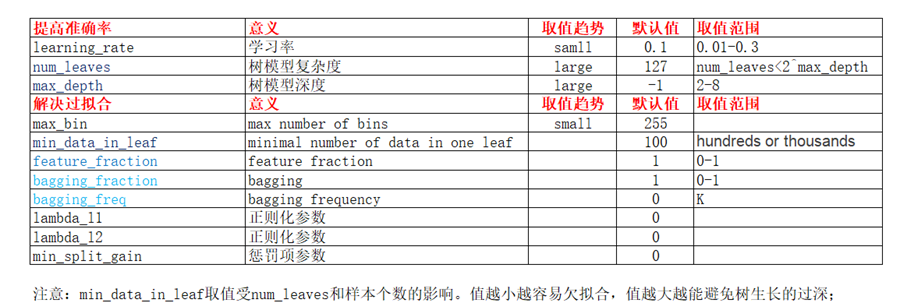
此外还有objective,metric等参数.
RF/GBDT/XGBoost/LightGBM简单总结(完结)的更多相关文章
- RF,GBDT,XGBoost,lightGBM的对比
转载地址:https://blog.csdn.net/u014248127/article/details/79015803 RF,GBDT,XGBoost,lightGBM都属于集成学习(Ensem ...
- 随机森林RF、XGBoost、GBDT和LightGBM的原理和区别
目录 1.基本知识点介绍 2.各个算法原理 2.1 随机森林 -- RandomForest 2.2 XGBoost算法 2.3 GBDT算法(Gradient Boosting Decision T ...
- R︱Yandex的梯度提升CatBoost 算法(官方述:超越XGBoost/lightGBM/h2o)
俄罗斯搜索巨头 Yandex 昨日宣布开源 CatBoost ,这是一种支持类别特征,基于梯度提升决策树的机器学习方法. CatBoost 是由 Yandex 的研究人员和工程师开发的,是 Matri ...
- GBDT && XGBOOST
GBDT && XGBOOST Outline Introduction GBDT Model XGBOOST Model ...
- 从信用卡欺诈模型看不平衡数据分类(1)数据层面:使用过采样是主流,过采样通常使用smote,或者少数使用数据复制。过采样后模型选择RF、xgboost、神经网络能够取得非常不错的效果。(2)模型层面:使用模型集成,样本不做处理,将各个模型进行特征选择、参数调优后进行集成,通常也能够取得不错的结果。(3)其他方法:偶尔可以使用异常检测技术,IF为主
总结:不平衡数据的分类,(1)数据层面:使用过采样是主流,过采样通常使用smote,或者少数使用数据复制.过采样后模型选择RF.xgboost.神经网络能够取得非常不错的效果.(2)模型层面:使用模型 ...
- 机器学习 GBDT+xgboost 决策树提升
目录 xgboost CART(Classify and Regression Tree) GBDT(Gradient Boosting Desicion Tree) GB思想(Gradient Bo ...
- RF, GBDT, XGB区别
GBDT与XGB区别 1. 传统GBDT以CART作为基分类器,xgboost还支持线性分类器(gblinear),这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回 ...
- xgboost&lightgbm调参指南
本文重点阐述了xgboost和lightgbm的主要参数和调参技巧,其理论部分可见集成学习,以下内容主要来自xgboost和LightGBM的官方文档. xgboost Xgboost参数主要分为三大 ...
- 机器学习之——集成算法,随机森林,Bootsing,Adaboost,Staking,GBDT,XGboost
集成学习 集成算法 随机森林(前身是bagging或者随机抽样)(并行算法) 提升算法(Boosting算法) GBDT(迭代决策树) (串行算法) Adaboost (串行算法) Stacking ...
随机推荐
- Scala的类与类型
类和类型 List<String>和List<Int>类型是不一样的,但是jvm运行时会采用泛型擦除.导致List<String>和List<Int>都 ...
- Grid Search学习
转自:https://www.cnblogs.com/ysugyl/p/8711205.html Grid Search:一种调参手段:穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性 ...
- 移动 H5(PC Web)前端性能优化指南
原文地址https://zhuanlan.zhihu.com/p/25176904?utm_source=wechat_session&utm_medium=social&utm_me ...
- 线性表:实现单链表和子类栈(Stack)及单向队列(Queue) [C++]
刚刚开始学习c++.之前c的内容掌握的也不多,基本只是一本概论课的程度,以前使用c的struct写过的链表.用python写过简单的数据结构,就试着把两者用c++写出来,也是对c++的class,以及 ...
- Linux系统——Inotify事件监控工具
每秒传输文件200个 Rsync放在定时任务中也只是一分钟执行一回,要想达到实时的效果,为防止单点nfs架构故障,再启动一台nfs服务器作为主nfs服务器的备份服务器,此时需要inotify实时同步数 ...
- Bootstrap按钮组学习
简介 通过按钮组容器把一组按钮放在同一行里.通过与按钮插件联合使用,可以设置为单选框或多选框的样式和行为. 按钮组中的工具提示和弹出框需要特别的设置 当为 .btn-group 中的元素应用工具提示或 ...
- cocos进阶教程(3)Lua加密技术
如果开发者不想让游戏中的资源或脚本文件轻易的暴露给其他人,一般会采用对文件进行加密的方式来保护文件或资源被盗用.Quick-Cocos2d-x 为开发者提供了xxtea加密算法,用来对脚本文件及资源进 ...
- 70. Climbing Stairs(动态规划 爬台阶,一次只能爬1,2两节)
You are climbing a stair case. It takes n steps to reach to the top. Each time you can either climb ...
- open-falcon设置报警邮件
下载编译好的二进制包并解压: https://files.cnblogs.com/files/dylan-wu/mail-provider.tar.gz [root@localhost work]# ...
- SQL Server2008创建数据库语法
use mastergo if exists(select * from sys.databases where name='MySchool') drop database MySchool -- ...