Kubernetes(二)架构及资源关系简单总结
Kubernetes架构
先引用一下官方的架构图:
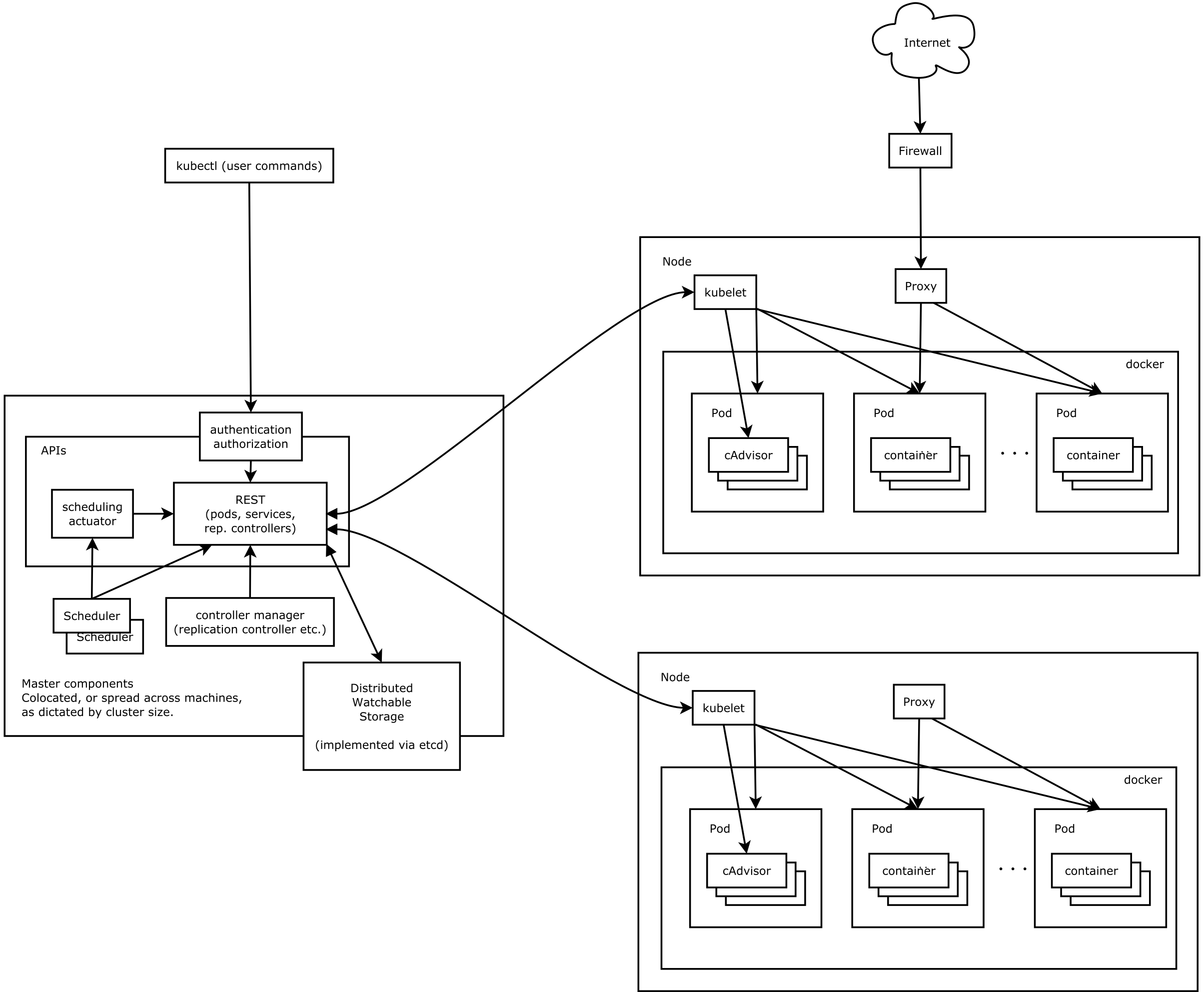
对于本文来说,我觉得这张图有点复杂了,但是我又懒得自己画了,就用这张吧。Kubernetes是一个集群,和传统的集群相似,它也是有一个主节点和若干个工作节点组成。在Kubernetes中,主节点称之为Master节点,就是上图中左边的大框;工作节点称之为Node(原来称为Minion,一个意思)。下面我们分别介绍Master节点和Node节点。
Master
Master节点上面主要由四个模块组成:APIServer、scheduler、controller manager、etcd。
APIServer。APIServer的功能如其名,负责对外提供RESTful的Kubernetes API服务,它是系统管理指令的统一入口,任何对资源进行增删改查的操作都要交给APIServer处理后再提交给etcd。如架构图中所示,kubectl(Kubernetes提供的客户端工具,该工具内部就是对Kubernetes API的调用)是直接和APIServer交互的。
schedule。scheduler的职责很明确,就是负责调度pod(Kubernetes中最小的调度单元,后面马上就会介绍)到合适的Node上。如果把scheduler看成一个黑匣子,那么它的输入是pod和由多个Node组成的列表,输出是Pod和一个Node的绑定(bind),即将这个pod部署到这个Node上。虽然scheduler的职责很简单,但我们知道调度系统的智能程度对于整个集群是非常重要的。Kubernetes目前提供了调度算法,但是同样也保留了接口,用户可以根据自己的需求定义自己的调度算法。
controller manager。如果说APIServer做的是“前台”的工作的话,那controller manager就是负责“后台”的。后面我们马上会介绍到资源,每个资源一般都对应有一个控制器,而controller manager就是负责管理这些控制器的。还是举个例子来说明吧:比如我们通过APIServer创建一个pod,当这个pod创建成功后,APIServer的任务就算完成了。而后面保证Pod的状态始终和我们预期的一样的重任就由controller manager去保证了。
etcd。etcd是一个高可用的键值存储系统,Kubernetes使用它来存储各个资源的状态,从而实现了Restful的API。
至此,Kubernetes Master就简单介绍完了。当然,每个模块内部的实现都很复杂,而且功能也比较复杂,我现在也只是比较浅的了解了一下。如果后续了解的比较清楚了,再做总结分享。
Node
真正干活的来了。每个Node节点主要由三个模块组成:kubelet、kube-proxy、runtime。先从简单的说吧。
runtime。runtime指的是容器运行环境,目前Kubernetes支持docker和rkt两种容器,一般都指的是docker,毕竟docker现在是最主流的容器。
kube-proxy。该模块实现了Kubernetes中的服务发现和反向代理功能。反向代理方面:kube-proxy支持TCP和UDP连接转发,默认基于Round Robin算法将客户端流量转发到与service对应的一组后端pod。服务发现方面,kube-proxy使用etcd的watch机制,监控集群中service和endpoint对象数据的动态变化,并且维护一个service到endpoint的映射关系,从而保证了后端pod的IP变化不会对访问者造成影响。另外kube-proxy还支持session affinity。(这里涉及到了service的概念,可以先跳过,等了解了service之后再来看。)
kubelet。Kubelet是Master在每个Node节点上面的agent,是Node节点上面最重要的模块,它负责维护和管理该Node上面的所有容器,但是如果容器不是通过Kubernetes创建的,它并不会管理。本质上,它负责使Pod得运行状态与期望的状态一致。
至此,Kubernetes的Master和Node就简单介绍完了。下面我们来看Kubernetes中的各种资源/对象。
Kubernetes资源/对象
当然上面已经介绍的Node也算Kubernetes的资源,这里就不再赘述了。
Pod
Pod是Kubernetes里面抽象出来的一个概念,它具有如下特点:
Pod是能够被创建、调度和管理的最小单元;
每个Pod都有一个独立的IP;
一个Pod由一个或多个容器构成;
一个Pod内的容器共享Pod的所有资源,这些资源主要包括:共享存储(以Volumes的形式)、共享网络、共享端口等。
集群内的Pod之间不论是否在同一个Node上都可以任意访问,这一般是通过一个二层网络来实现的。
Kubernetes虽然也是一个容器编排系统,但不同于其他系统,它的最小操作单元不是单个容器,而是Pod。这个特性给Kubernetes带来了很多优势,比如最显而易见的是同一个Pod内的容器可以非常方便的互相访问(通过localhost就可以访问)和共享数据。使用Pod时我们需要注意两点:
虽然Pod内可以有多个容器,但一般我们只将有亲密关系的容器放在一个Pod内,比如这些容器需要相互访问、共享数据等。举个最典型的例子,比如我们有一个系统,前端是tomcat作为web,后端是存储数据的数据库mysql,那么将这两个容器部署在一个Pod内就非常合理了,因为他们通过localhost就可以访问彼此。
虽然每个Pod都有独立的IP,但是不推荐前台通过IP去访问Pod,因为Pod一旦销毁重建,IP就会变化。如果我们的Pod提供了对外的Web服务,那么我们可以通过Kubernetes提供的service去访问,后面会介绍到。
下面是一个Pod的描述文件nginx-pod.yaml:
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
labels:
app: nginx
spec:
containers:
- image: registry.hnaresearch.com/library/nginx:latest
name: nginx
ports:
- containerPort:
apiVersion表示API的版本,kind表示我们要创建的资源的类型。metadata是Pod的一些元数据描述。spec描述了我们期望该Pod内运行的容器。通过kubectl create -f nginx-pod.yaml就可以创建一个Pod,这个Pod里面只有一个nginx容器。
➜ kubectl create -f nginx-pod.yaml
pod "nginx-pod" created
➜ kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-pod / Running 1h
这里我们只是为了示例,其实实际应用中我们很少会去直接创建一个Pod,因为这样创建的Pod就像个没人管的孩子,挂了的话也不会有人去重新建立一个新的来顶替它。Kubernetes提供了很多创建Pod的方式,下面我们接着介绍。
Replication Controller
Replication Controller简称RC,一般翻译为副本控制器,这里的副本指的是Pod。如它的名字所言RC的作用就是保证任意时刻集群中都有期望个数的Pod副本在正常运行。我们通过一个简单的RC描述文件(mysql-rc.yaml)来介绍它:
apiVersion: v1
kind: ReplicationController
metadata:
name: mysql
spec:
replicas:
selector:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: registry.hnaresearch.com/library/mysql:5.6
ports:
- containerPort:
env:
- name: MYSQL_ROOT_PASSWORD
value: ""
上面这个文件描述了一个RC,名字叫mysql,最上面的spec描述了我们期望有1个副本,这些副本都是按照下面的template去创建的。如果某一时刻副本数比replicas描述的少,就按照template去创建新的,如果多了,就干掉几个。而下面的spec描述了这个Pod内运行的容器。
➜ kubectl create -f mysql-rc.yaml
replicationcontroller "mysql" created
➜ kubectl get rc
NAME DESIRED CURRENT READY AGE
mysql 7s
➜ kubectl get pod
NAME READY STATUS RESTARTS AGE
mysql-1l717 / Running 27s
nginx-pod / Running 1h
然后我们进行一些删除操作:
➜ kubectl delete pod nginx-pod
pod "nginx-pod" deleted
➜ kubectl get pod
NAME READY STATUS RESTARTS AGE
mysql-1l717 / Running 5m
➜ kubectl delete pod mysql-1l717
pod "mysql-1l717" deleted
➜ kubectl get pod
NAME READY STATUS RESTARTS AGE
mysql-2vl9k / Running 4s
我们先删掉之前通过Pod描述文件创建的nginx-pod,按照预期它被删除了,并没有重建。然后我们删掉mysql-1l717,发现又出来一个新的mysql-2vl9k。这是因为mysql这个是通过RC创建的,除非删除它的RC,否则任意时刻该RC都会保证有预期个Pod副本在运行。
那么,RC是怎么和Pod产生关联的呢?上面的selector是什么含义?OK,我们来介绍下一个对象。
Labels和Selector
Label是附属在Kubernetes对象上的键值对,它可以在创建的时候指定,也可以随时增删改。一个对象上面可以有任意多个Labels。它往往对于用户是有意义的,对系统是没有特殊含义的。我个人理解你可以简单把他当做Git上面的tag。这里我们只介绍一下它和Selector配合使用时的场景。我们从上面Pod和RC的描述文件中可以看到,每个Pod都有一个Labels,而RC的Selector部分也有一个定义了一个labels。RC会认为凡是和它Selector部分定义的labels相同的Pod都是它预期的副本。比如凡是labels为app=mysql的Pod都是刚才定义的RC的副本。
所以就有一个注意点,我们不要单独去创建Pod,更不要单独去创建符合某个RC的Selector的Pod,那样RC会认为是它自己创建的这个Pod而导致与预期Pod数不一致而干掉某些Pod。当然Labels还有很多用途,Selector除了等值外也有一些其他判读规则,这里不细述。
Service
终于轮到Service出场了,之前我们已经多次提到它了。Service是Kubernetes里面抽象出来的一层,它定义了由多个Pods组成的逻辑组(logical set),可以对组内的Pod做一些事情:
对外暴露流量
做负载均衡(load balancing)
服务发现(service-discovery)。
前面我们说了如果我们想将Pod内容器提供的服务暴露出去,就要使用Service。因为Service除了上面的特性外,还有一个集群内唯一的私有IP和对外的端口,用于接收流量。如果我们想将一个Service暴露到集群外,即集群外也可以访问的话,有两种方法:
LoadBalancer - 提供一个公网的IP
NodePort - 使用NAT将Service的端口暴露出去。
为什么不能通过Pod的IP,而要通过Service呢?因为在Kubernetes中,Pod是可能随时死掉被重建的,所以说其IP是不可靠的。但是Service一旦创建,其IP就会一直固定直到这个Service消亡。其实我们能够看到,Kubernetes中一个Service就相当于一个微服务。这里我们就不细述Service的创建方法以及如何使用LB以及NodePort了。
Replica Sets和Deployment
Replica Sets被称为下一代的Replication Controller,它被设计出来的目的是替代RC并提供更多的功能。就目前看,ReplicaSet和RC的唯一区别是对于Labels和Selector的支持。RC只支持等值的方式,而ReplicaSet还支持集合的选择方式(In,Not In)。另外,ReplicaSet很少像RC一样单独使用(当然,它可以单独使用),一般都是配合Deployment一起使用。
Deployment也是Kubernetes新增加的一种资源,从它的名字就可以看出它主要是为部署而设计的,之前的文章中已经有具体的例子了。想像一下我们利用RC创建了一些Pod,但现在我们想要更新Pod内容器使用的镜像或者想更改副本的个数等。这些我们无法通过修改已有的RC去做,只能删除旧的,创建新的。但这样Pod内的容器就会停止,也即业务就会中断,这在生产环境中往往是不可接受的。但有了Deployment以后,这些问题就都可以解决了。通过Deployment我们可以动态的控制副本个数、ReplicaSet和Pod的状态、滚动升级等。Deployment的强大真的需要很长的一篇文章来介绍,后续的博客再介绍吧。
HPA
HPA全称Horizontal Pod Autoscaling,即Pod的水平自动扩展,我觉得这个简直就是Kubernetes的黑科技。因为它可以根据当前系统的负载来自动水平扩容,如果系统负载超过预定值,就开始增加Pod的个数,如果低于某个值,就自动减少Pod的个数。因为被以前的系统扩容缩容深深的折磨过,所以我觉得这个功能是多么的强大。当然,目前Kubernetes的HPA只能根据CPU和内存去度量系统的负载,而且目前还依赖heapster去收集CPU的使用情况,所以功能还不是很强大,但是其完善也只是时间的问题了。让我们期待吧。
Namespace
Kubernetes提供了Namespace来从逻辑上支持多租户的功能,默认有两个Namespace:
default。用户默认的namespace。
kube-system。系统创建的对象都在这个namespace下。
当然我们可以自己创建新的namespace。
Daemon Set
有时我们可能有这样的需求,需要在所有Pod上面(包括将来新创建的)都运行某个容器,比如用于监控、日志收集等。那我们就可以使用DaemonSet,它可以保证所有容器上面都运行一份我们指定的容器的实例。而且,通过Labels和Selector,我们可以实现只在某些Pod上面部署,非常的灵活。
但是现在也有一些局限,比如如果我们无法更改已经部署的Daemon Set。如果需要更改,只能删除重建。当然,更改的功能也已经在开发中了。
其他
当然,Kubernetes还有很多其他的资源/对象,比如执行一次任务的Job,存储相关的Volume等,这些我觉得都没法简单的说清楚其功能。后续再介绍。
写到这里,感觉本文已经和开始的说的简明、简短有些渐行渐远了...Oops
转载自:http://time-track.cn/Kubernetes-resources-summaries.html
Kubernetes(二)架构及资源关系简单总结的更多相关文章
- 了解Kubernetes主体架构(二十八)
前言 Kubernetes的教程一直在编写,目前已经初步完成了以下内容: 1)基础理论 2)使用Minikube部署本地Kubernetes集群 3)使用Kubeadm创建集群 接下来还会逐步完善本教 ...
- Kubernetes系列02—Kubernetes设计架构和设计理念
本文收录在容器技术学习系列文章总目录 1.Kubernetes设计架构 Kubernetes集群包含有节点代理kubelet和Master组件(APIs, scheduler, etc),一切都基于分 ...
- 从零开始入门 K8s | Kubernetes 存储架构及插件使用
本文整理自<CNCF x Alibaba 云原生技术公开课>第 21 讲. 导读:容器存储是 Kubernetes 系统中提供数据持久化的基础组件,是实现有状态服务的重要保证.Kubern ...
- 【HELLO WAKA】WAKA iOS客户端 之二 架构设计与实现篇
上一篇主要做了MAKA APP的需求分析,功能结构分解,架构分析,API分析,API数据结构分析. 这篇主要讲如何从零做iOS应用架构. 全系列 [HELLO WAKA]WAKA iOS客户端 之一 ...
- [原]CentOS7安装Rancher2.1并部署kubernetes (二)---部署kubernetes
################## Rancher v2.1.7 + Kubernetes 1.13.4 ################ ##################### ...
- Kubernetes生产架构浅谈
注意 本文,只是笔者针对Kubernetes生产环境运行的一些关于架构设计介绍. 介绍 基于 Kubernetes 系统构建的统一开发运维管控平台.在 Kubernetes 基础上,围绕 微服务系统的 ...
- Kubernetes 原理架构介绍(一)
目录 一.Kubernetes 是什么 二.Kubernetes 设计架构 三.Kubernetes的核心技术概念和API对象 Cluster Master Node Pod Controller D ...
- (转)Kubernetes设计架构
转:https://www.kubernetes.org.cn/kubernetes设计架构 Kubernetes集群包含有节点代理kubelet和Master组件(APIs, scheduler, ...
- 3、flink架构,资源和资源组
一.flink架构 1.1.集群模型和角色 如上图所示:当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager.由 Client 提交任务给 JobMa ...
随机推荐
- Android设计中的.9.png图片
.9.png是一种能够自己定义拉伸特定区域的图片格式. 简书:Android设计中的.9.png图片 在Android的UI设计开发中,非常多控件须要适配不同的手机分辨率进行拉伸或者压缩,这样就出现了 ...
- C#判断窗体是否存在重复打开
foreach (Form f in Application.OpenForms) { f.Name //是打开窗体的Text //以下判断....... } Form2 F2 ; if(F2 == ...
- Sql Server数据库自增长字段标识列的插入或更新修改操作办法
写在前面的话:在日常的Sql server开发中,经常会用到Identity类型的标识列作为一个表结构的自增长编号.比如文章编号.记录编号等等.自增长的标识很大程度上方便了数据库程序的开发,但有时候这 ...
- ajaxupload 异步上传工具
基于jquery库异步上传的jquery插件 $.ajaxFileUpload({ url:(baseURL+'/common/fileUploadAct!fileUpload.action?clas ...
- c++之——抽象基类
在一个虚函数的声明语句的分号前加上 =0:就可以将一个虚函数变成纯虚函数,其中,=0只能出现在类内部的虚函数声明语句处.纯虚函数只用声明,而不用定义,其存在就是为了提供接口,含有纯虚函数的类是抽象基类 ...
- C#类的修饰符
## C#类的修饰符------------------------- public 任何地方可以调用- internal 同一应用程序集内使用- partial 部分类,一个类分成几部分写在不同文件 ...
- 百度BAE 平台PHP对Mongodb的连接
<?php /*请替换为你自己的数据库名(可从管理中心查看到)*/ $dbname = 'XgmsRXDEYIDGmQFCjaZl'; /*从环境变量里取host,port,user,pwd*/ ...
- VC6.0启动File-open和Project-add file to project崩溃的解决方法
最近由于装了Office2010,VC6.0被整残了,file->open 和 Project->add file to project不能用,一用VC6.0就崩溃,查到是由于office ...
- html5 canvas实现图片玻璃碎片特效
今天要为大家带来一款html5 canvas实现的图片玻璃碎片特效.图片以玻璃碎片的形式出现到界面中,然后似玻璃被打碎的效果渐消息.效果图如下: 在线预览 源码下载 实现代码: html代码: & ...
- android开发中用到的px、dp、sp
先介绍一下这几个单位: px : pixels(像素),相应屏幕上的实际像素点. dip :device independent pixels,与密度无关的像素,基于屏幕密度的抽象单位. 在每英寸16 ...