spark读取mongodb数据写入hive表中
一 环境:
spark-2.2.; hive-1.1.; scala-2.11.; hadoop-2.6.-cdh-5.15.; jdk-1.8; mongodb-2.4.10;
二.数据情况:
MongoDB数据格式
{
"_id" : ObjectId("5ba0569cafc9ec432bd310a3"),
"id" : 7,
"name" : "7mongoDBi am using mongodb now",
"location" : "shanghai",
"sex" : "male",
"position" : "big data platform engineer"
}
Hive普通表 create table mgtohive_2(
id string,
name string,
age string,
deptno string
)row format delimited fields terminated by '\t'; create table mgtohive_2(
id int,
name string,
location string,
sex string,
position string
)
row format delimited fields terminated by '\t';
Hive分区表 create table mg_hive_external(
id int,
name string,
location string,
position string
)
PARTITIONED BY(sex string)
row format delimited fields terminated by '\t';
三.Eclipse+Maven+Java
3.1 依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.</artifactId>
<version>2.2.</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.</artifactId>
<version>2.2.</version>
</dependency>
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongo-java-driver</artifactId>
<version>3.6.</version>
</dependency>
<dependency>
<groupId>org.mongodb.spark</groupId>
<artifactId>mongo-spark-connector_2.</artifactId>
<version>2.2.</version>
</dependency>
3.2 代码:
package com.mobanker.mongo2hive.Mongo2Hive; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.hive.HiveContext;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import org.bson.Document; import com.mongodb.spark.MongoSpark; import java.io.File;
import java.util.ArrayList;
import java.util.List; public class Mongo2Hive {
public static void main(String[] args) {
//spark 2.x
String warehouseLocation = new File("spark-warehouse").getAbsolutePath();
SparkSession spark = SparkSession.builder()
.master("local[2]")
.appName("SparkReadMgToHive")
.config("spark.sql.warehouse.dir", warehouseLocation)
.config("spark.mongodb.input.uri", "mongodb://10.40.20.47:27017/test_db.test_table")
.enableHiveSupport()
.getOrCreate();
JavaSparkContext sc = new JavaSparkContext(spark.sparkContext()); // spark 1.x
// JavaSparkContext sc = new JavaSparkContext(conf);
// sc.addJar("/Users/mac/zhangchun/jar/mongo-spark-connector_2.11-2.2.2.jar");
// sc.addJar("/Users/mac/zhangchun/jar/mongo-java-driver-3.6.3.jar");
// SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("SparkReadMgToHive");
// conf.set("spark.mongodb.input.uri", "mongodb://127.0.0.1:27017/test.mgtest");
// conf.set("spark. serializer","org.apache.spark.serializer.KryoSerialzier");
// HiveContext sqlContext = new HiveContext(sc);
// //create df from mongo
// Dataset<Row> df = MongoSpark.read(sqlContext).load().toDF();
// df.select("id","name","name").show(); String querysql= "select id,name,location,sex,position from mgtohive_2 b";
String opType ="P"; SQLUtils sqlUtils = new SQLUtils();
List<String> column = sqlUtils.getColumns(querysql); //create rdd from mongo
JavaRDD<Document> rdd = MongoSpark.load(sc);
//将Document转成Object
JavaRDD<Object> Ordd = rdd.map(new Function<Document, Object>() {
public Object call(Document document){
List list = new ArrayList();
for (int i = ; i < column.size(); i++) {
list.add(String.valueOf(document.get(column.get(i))));
}
return list; // return list.toString().replace("[","").replace("]","");
}
});
System.out.println(Ordd.first());
//通过编程方式将RDD转成DF
List ls= new ArrayList();
for (int i = ; i < column.size(); i++) {
ls.add(column.get(i));
}
String schemaString = ls.toString().replace("[","").replace("]","").replace(" ","");
System.out.println(schemaString); List<StructField> fields = new ArrayList<StructField>();
for (String fieldName : schemaString.split(",")) {
StructField field = DataTypes.createStructField(fieldName, DataTypes.StringType, true);
fields.add(field);
}
StructType schema = DataTypes.createStructType(fields); JavaRDD<Row> rowRDD = Ordd.map((Function<Object, Row>) record -> {
List fileds = (List) record;
// String[] attributes = record.toString().split(",");
return RowFactory.create(fileds.toArray());
}); Dataset<Row> df = spark.createDataFrame(rowRDD,schema); //将DF写入到Hive中
//选择Hive数据库
spark.sql("use datalake");
//注册临时表
df.registerTempTable("mgtable"); if ("O".equals(opType.trim())) {
System.out.println("数据插入到Hive ordinary table");
Long t1 = System.currentTimeMillis();
spark.sql("insert into mgtohive_2 " + querysql + " " + "where b.id not in (select id from mgtohive_2)"); System.out.println("insert into mgtohive_2 " + querysql + " "); Long t2 = System.currentTimeMillis();
System.out.println("共耗时:" + (t2 - t1) / + "分钟");
}else if ("P".equals(opType.trim())) { System.out.println("数据插入到Hive dynamic partition table");
Long t3 = System.currentTimeMillis();
//必须设置以下参数 否则报错
spark.sql("set hive.exec.dynamic.partition.mode=nonstrict");
//sex为分区字段 select语句最后一个字段必须是sex
spark.sql("insert into mg_hive_external partition(sex) select id,name,location,position,sex from mgtable b where b.id not in (select id from mg_hive_external)");
Long t4 = System.currentTimeMillis();
System.out.println("共耗时:"+(t4 -t3)/+ "分钟");
}
spark.stop();
}
}
工具类:
package com.mobanker.mongo2hive.Mongo2Hive; import java.util.ArrayList;
import java.util.List; public class SQLUtils {
public List<String> getColumns(String querysql){
List<String> column = new ArrayList<String>();
String tmp = querysql.substring(querysql.indexOf("select") + ,
querysql.indexOf("from")).trim();
if (tmp.indexOf("*") == -){
String cols[] = tmp.split(",");
for (String c:cols){
column.add(c);
}
}
return column;
} public String getTBname(String querysql){
String tmp = querysql.substring(querysql.indexOf("from")+).trim();
int sx = tmp.indexOf(" ");
if(sx == -){
return tmp;
}else {
return tmp.substring(,sx);
}
}
}
四 错误解决办法:
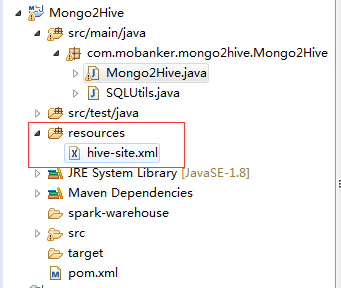
下载cdh集群Hive的hive-site.xml文件,在项目中新建resources文件夹,讲hive-site.xml配置文件放入其中:
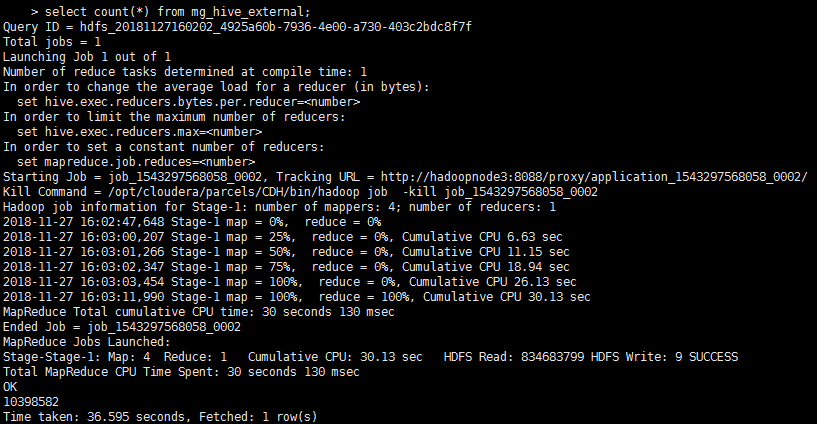
五 执行情况:
耗时14mins,写入hive表10398582条数据:
spark读取mongodb数据写入hive表中的更多相关文章
- spark 将dataframe数据写入Hive分区表
从spark1.2 到spark1.3,spark SQL中的SchemaRDD变为了DataFrame,DataFrame相对于SchemaRDD有了较大改变,同时提供了更多好用且方便的API.Da ...
- 通过js获取前台数据向一般处理程序传递Json数据,并解析Json数据,将前台传来的Json数据写入数据库表中
摘自:http://blog.csdn.net/mazhaojuan/article/details/8592015 通过js获取前台数据向一般处理程序传递Json数据,并解析Json数据,将前台传来 ...
- 《项目经验》--通过js获取前台数据向一般处理程序传递Json数据,并解析Json数据,将前台传来的Json数据写入数据库表中
先看一下我要实现的功能界面: 这个界面的功能在图中已有展现,课程分配(教师教授哪门课程)在之前的页面中已做好.这个页面主要实现的是授课,即给老师教授的课程分配学生.此页面实现功能的步骤已在页面 ...
- sqoop导入数据到hive表中的相关操作
1.使用sqoop创建表并且指定对应的hive表中的字段的数据类型,同时指定该表的分区字段名称 sqoop create-hive-table --connect "jdbc:oracle: ...
- 将python的字典格式数据写入excei表中
上面的为最终结果 import requests import re import xlwt import json # 导入必须的包: xlwt,json,requests,re. headers ...
- 读取Excel数据到Table表中
方法一: try { List<DBUtility.CommandInfo> list = new List<DBUtility.CommandInfo>(); string ...
- 批量导入数据到hive表中:假设我有60张主子表如何批量创建导入数据
背景:根据业务需要需要把60张主子表批量入库到hive表. 创建测试数据: def createBatchTestFile(): Unit = { to ) { val sWriter = new P ...
- Hive 将本地数据导入hive表中
# 导入 load data local inpath '/root/mr/The_Man_of_Property.txt' insert into table article; # 提示 FAILE ...
- 将DataFrame数据如何写入到Hive表中
1.将DataFrame数据如何写入到Hive表中?2.通过那个API实现创建spark临时表?3.如何将DataFrame数据写入hive指定数据表的分区中? 从spark1.2 到spark1.3 ...
随机推荐
- Functional Reactive Programming
Functional Reactive Programming (FRP) integrates time flow and compositional events into functional ...
- Guava包学习---Sets
Sets包的内容和上一篇中的Lists没有什么大的区别,里面有些细节可以看一下: 开始的创建newHashSet()的各个重载方法.newConcurrentHashSet()的重载方法.newTre ...
- [HNOI2003]多边形
嘟嘟嘟 也是一道半平面相交板子题. 比较好的处理方法是先把原图形全部加入答案,然后在一条边一条边切. 然而第一个点全网(当然包括我)都没过,我最后也只能固输了-- #include<cstdio ...
- 线性回归 Python实现
import numpy as np import pylab def plot_data(data, b, m): x = data[:, 0] y = data[:, 1] y_predict = ...
- 8、Web Service-IDEA-jaxws规范下的 spring整合CXF
前提:开发和之前eclipse的开发有很大的不同! 1.服务端的实现 1.新建项目 此时创建的是web项目 2.此时创建的项目是不完整的需要开发人员手动补充完整 3.对文件夹的设置(满满的软件使用方法 ...
- 把dataTable数据转换为Html
using System;using System.Collections.Generic;using System.Data;using System.Linq;using System.Text; ...
- Linux内存管理-高端内存(一)
高端内存是指物理地址大于 896M 的内存.对于这样的内存,无法在“内核直接映射空间”进行映射. 为什么? 因为“内核直接映射空间”最多只能从 3G 到 4G,只能直接映射 1G 物理内存,对于大于 ...
- Oracle锁处理、解锁方法
1.查询锁情况 select sid,serial#,event,BLOCKING_SESSION from v$session where event like '%TX%'; 2.根据SID查询具 ...
- Xcode引入了第三方的类库之后真机调试提示莫名其妙的错误
其中的解决方法就是修改Build Setting里面的Build Active Architecture Only(仅仅编译动态代码),将这个里面的值修改为YES即可.
- js身份证校验
通过js实现对15位或者18位身份证格式校验: 通过调用idCardNoUtil.checkeIdCardNo(idCardNo)传入身份证号码,实现校验. var idCardNoUtil = { ...