CentOS 7_64位系统下搭建Hadoop_2.8.0分布式环境
准备条件:
CentOS 7 64位操作系统 | 选择minimal版本即可(不带可视化桌面环境),也可以选择带完整版
Hadoop-2.8.0 | 本文采用的是Hadoop-2.8.0版本。
JDK1.8 | 本文采用jdk-8u131-linux-x64.tar.gz版本。
- 解压并配置JDK并配置Hadoop
1. 将下载好的jdk放入/usr 下并在/usr目录下新建java目录
[root@localhost /]# cd /usr
[root@localhost usr]# mkdir java
[root@localhost usr]# cd /usr/java/jdk1.8
进入该目录,并解压jdk到当前文件夹
tar -xzvf jdk-8.tar.gz解压得到文件夹修改文件夹名为jdk1.8以方便使用。
修改JAVA环境变量:
编辑java环境 vi ~/.bash_profile
添加如下命令:
export JAVA_HOME=/usr/java/jdk1.8.0_121
export PATH=$JAVA_HOME/bin:$PATH
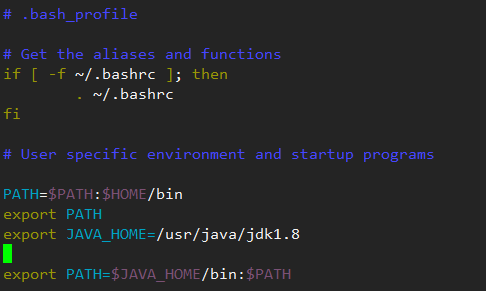
执行source ~/.bash_profile 使变量生效
2. 解压hadoop-2.8.0
将下载好的Hadoop压缩包解压到目标文件夹下,(本文解压目录为:/usr/local)
修改解压后得到Hadoop的文件夹名为:Hadoop-2.8.0 并得到如下文件:

Hadoop不需要安装,下面进行环境配置
下面的修改过程可使用vi命令,或者vim命令,或使用xftp直接对文件进行修改
再次修改
bash_profile添加hadoop的文件路径:
加上之前修改的配置的jdk环境,改该文件整体修改为:
PATH=$PATH:$HOME/bin
export PATH
export JAVA_HOME=/usr/java/jdk1.8
export HADOOP_HOME=/usr/local/hadoop-2.8.0
export PATH=$JAVA_HOME/bin:$PATH:$HOME/bin:$HADOOP_HOME/bin
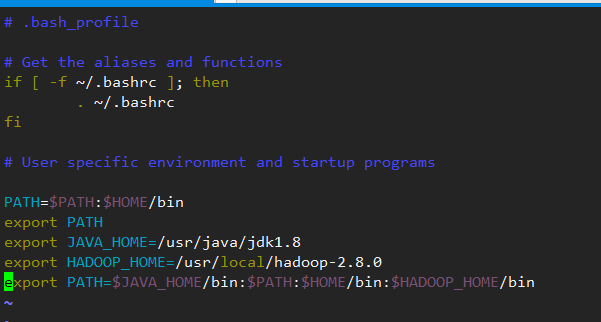
再次执行 source ~/.bash_profile 使得文件立即生效
修改
etc/hadoop/core-site.xml将configurarion标签修改为:注意:192.168.0.181是本文的测试地址,相应的,需要修改成自己虚拟机的ip地址,如果虚拟机不是桥接方式,则可以改为:127.0.0.19000是Hadoop的默认端口,建议先不要修改
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.0.181:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-2.8.0/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
修改
etc/hadoop/hdfs-site.xml<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-2.8.0/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-2.8.0/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.0.181:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>以上,分别配置的是相应的几个节点和安全认证,文件目录会在服务开启时自动创建
dfs.permissions设置为false可以允许完全分布式模式下的多机访问
修改
etc/hadoop/yarn-site.xml<configuration> <!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.0.181:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.0.181:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.0.181:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.0.181:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.0.181:8088</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>6078</value>
</property>
</configuration>
修改
etc/hadoop/hadoop-env.sh# The java implementation to use.exportJAVA_HOME=/usr/java/jdk1.8以上修改JAVA_HOME为绝对路径
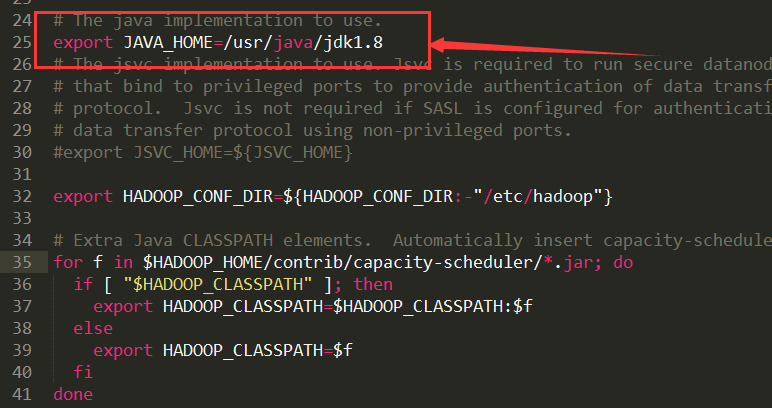
修改
etc/hadoop/mapred-site.xml注意:etc/hadoop/目录下并没有这个xml文件,仔细查找,有个mapred-site.xml.template把这个文件复制,重命名为mapred-site.xml并修改为:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.0.181:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.0.181:19888</value>
</property>
</configuration>
修改
etc/hadoop/yarn-env.sh
在其中找到export JAVA_HOME并去掉注释,编辑java地址export JAVA_HOME=/usr/java/jdk1.8

修改
etc/hadoop/slaves
添加当前主机ip
至此,基本配置已经完毕
3. 列表项目
hadoop目录下执行如下指令,进行编译
./bin/hdfs namenode –format
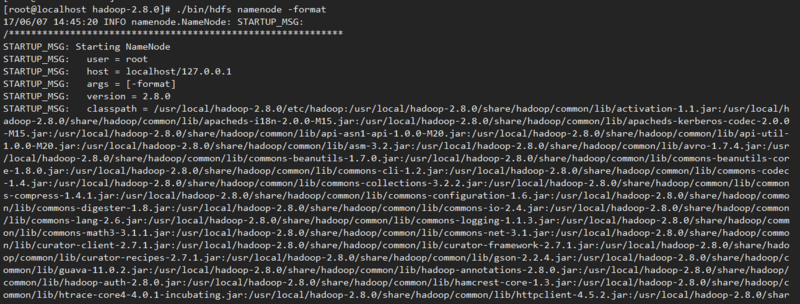
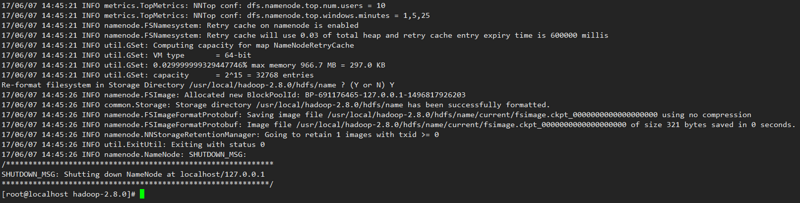
出现如上图,表示编译成功。
4. 关闭防火墙:
关闭防火墙服务:systemctl stop firewalld.service
使防火墙服务不随机器启动:systemctl disable firewalld.service
开启Hadoop服务
./sbin/start-all.sh
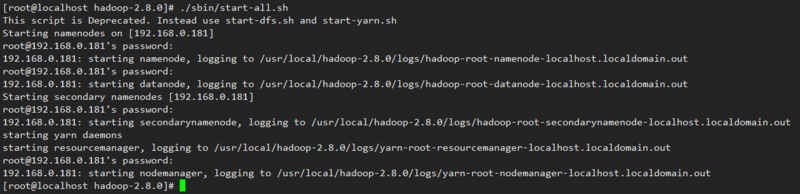
输入jps查看相关节点是否开启
打开浏览器:地址栏输入http://192.168.0.181:8088
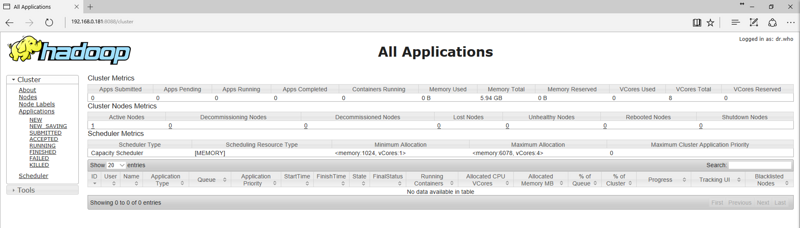
使用过程中遇到的问题:
问题一:nameNode节点无法启动,jps目录缺少相应活动程序
在第一次格式化dfs后启动并使用了Hadoop,后来又重新执行了格式化命令hdfs namenode –format
这时namenode的clusterID会重新生成,而datanode的clusterID保持不变。
从而导致两者的id不一致,出现一系列错误。
解决办法:
到hadoop/hdfs目录下分别查看data/current下的VERSION和name/current下的VERSION文件对比两文件中的clusterID是否相同,若不同,使用name/current下的VERSION中的clusterID覆盖data/current下的clusterID. 修改后重新启动Hadoop即可问题二:如何配置单机互信?
每次启动和关闭Hadoop的时候,都需要频繁输入多次密码,通过配置单机互信或者多机互信来简化操作:
解决办法:
使用指令:ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
随后:cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
并执行:chmod 600 .ssh/authorized_keys
即可。问题三:在完全分布式模式下运行失败,无法登陆或没有访问权限
解决办法:
修改etc/hadoop/hdfs-site.xml
添加<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
---------------------------------------------------------------------------------------------------------------
//系统环境的java+hadoop路径配置
vi /etc/profile
source /etc/profile
//当前目录环境的java+hadoop路径配置
vi ~/.bash_profile
source ~/.bash_profile
//关闭防火墙服务
systemctl stop firewalld.service
//使防火墙服务不随机器启动
systemctl disable firewalld.service
//数据格式化
./bin/hdfs namenode -format
//启动hadoop系统
./sbin/start-all.sh
//关闭hadoop系统
./sbin/stop-all.sh
CentOS 7_64位系统下搭建Hadoop_2.8.0分布式环境的更多相关文章
- Linux下搭建gtk+2.0开发环境
安装gtk2.0 sudo apt-get install libgtk2.0-dev 查看 2.x 版本 pkg-config --modversion gtk+-2.0 #有可能需要sudo ap ...
- 【Python基础学习一】在OSX系统下搭建Python语言集成开发环境 附激活码
Python是一门简单易学,功能强大的编程语言.它具有高效的高级数据结构和简单而有效的面向对象编程方法.Python优雅的语法和动态类型以及其解释性的性质,使它在许多领域和大多数平台成为编写脚本和快速 ...
- Centos 6.5系统下搭建Git服务器--失败历程
参考博客 http://www.51hei.com/bbs/dpj-28077-1.html http://www.linuxidc.com/Linux/2014-06/103885p2.htm ht ...
- Centos7 系统下搭建.NET Core2.0+Nginx+Supervisor+Mysql环境
好记性不如烂笔头! 一.简介 一直以来,微软只对自家平台提供.NET支持,这样等于让这个“理论上”可以跨平台的框架在Linux和macOS上的支持只能由第三方项目提供(比如Mono .NET).直到微 ...
- Windows下搭建Eclipse+Android4.0开发环境
官方搭建步骤: http://developer.android.com/index.html 搭建好开发环境之前须要下载以下几个文件包: 一.安装Java执行环境JRE(没这个Eclipse执行不起 ...
- Eclipse下搭建Hadoop2.4.0开发环境
一.安装Eclipse 下载Eclipse,解压安装,例如安装到/usr/local,即/usr/local/eclipse 4.3.1版本下载地址:http://pan.baidu.com/s/1e ...
- Linux下搭建gtk+2.0开发环境
1.执行如下命令,检查系统是否已安装gtk+ pkg-config --list-all |grep gtk 若命令提示如下,则系统已安装gtk+,否则未安装. 2.若未安装,则执行如下命令进行安装 ...
- CentOS和Ubuntu系统下安装 HttpFS (助推Hue部署搭建)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- linux CentOs 7.4 64位 系统下 nuxt部署 、nginx 安装、node环境及软连接,pm2软连接
一.nginx安装 1.安装依赖包 //一键安装上面四个依赖 yum -y install gcc zlib zlib-devel pcre-devel openssl openssl-devel 2 ...
随机推荐
- [51单片机] nRF24L01 无线模块 串口法命令 通过无线控制另一个的灯
>_<!概述: 这是在上一个的基础上通过按键发送4种不同命令来控制接收端的LED灯亮的改进版(上一个:http://www.cnblogs.com/zjutlitao/p/3840013. ...
- 常用脚本--归档ERRORLOG
SQL Server error log 7组日志文件默认情况下不会自动切换到下一个文件, 一般在SQL Server 重新启动后才会切换error log,如果SQL Server长期未重启或因为 ...
- Solr特性:Schemaless Mode(自动往Schema中添加field)
WiKi:https://cwiki.apache.org/confluence/display/solr/Schemaless+Mode 介绍: Schemaless Mode is a set o ...
- CentOS将普通用户加入管理员组
将用户username加入wheel组: usermod -aG wheel username 将普通用户username加入root组: usermod -aG sudo username 永久生效 ...
- Eclipse中Tomcat的配置及简单例子
Eclipse中Tomcat的配置及简单例子 Eclipse中Tomcat的配置是很简单的一个工作 一. 工具下载 Eclipse,最新版的eclipse为Mars版本.下载地址为: http://w ...
- SQL集合运算
注:UserInfo一共29条记录 select * from UserInfo union --并集(29条记录)(相同的只出现一次) select * from UserInfo select * ...
- 记录一下显示Map<String, ArrayList<String>>中的ArrayList里的数据的操作
1.有以下数据: ArrayList<Employee> emp = new ArrayList<>(); emp.add(new Employee("zhang&q ...
- pageadmin CMS网站建设教程:网页设计的常用参数
由于网络速度问题,我们需要考虑图片大小对传输速度的影响,如果图片太大就会影响浏览速度,访问者很快就会对这个网站失去了兴趣,只有充分了解图片质量与下载速度的关系,并了解不同的文件格式,才能更有效的表达内 ...
- [USACO17FEB]Why Did the Cow Cross the Road III P(CDQ分治)
题意 两列$n$的排列,相同的数连边,如果一对数有交叉且差的绝对值$>k$,则$++ans$,求$ans$ 题解 可以把每一个数字看成一个三元组$(x,y,z)$,其中$x$表示在第一列的位置, ...
- Nginx采用yum安装-Carr
(1)使用yum安装nginx需要包括Nginx的库,安装Nginx的库 #rpm -Uvh http://nginx.org/packages/centos/7/noarch/RPMS/nginx- ...