人工神经网络 Artificial Neural Network
2017-12-18 23:42:33
一、什么是深度学习
深度学习(deep neural network)是机器学习的分支,是一种试图使用包含复杂结构或由多重非线性变换构成的多个处理层对数据进行高层抽象的算法。 --Wiki
在人工智能领域,有一个方法叫机器学习。在机器学习这个方法里,有一类算法叫神经网络。神经网络如下图所示:
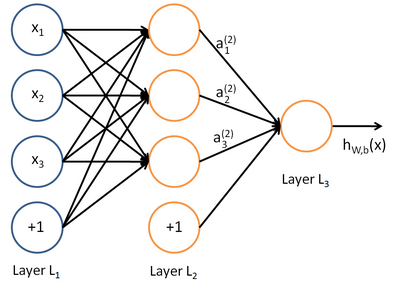
上图中每个圆圈都是一个神经元,每条线表示神经元之间的连接。我们可以看到,上面的神经元被分成了多层,层与层之间的神经元有连接,而层内之间的神经元没有连接。最左边的层叫做输入层,这层负责接收输入数据;最右边的层叫输出层,我们可以从这层获取神经网络输出数据。输入层和输出层之间的层叫做隐藏层。
隐藏层比较多(大于2)的神经网络叫做深度神经网络。而深度学习,就是使用深层架构(比如,深度神经网络)的机器学习方法。
那么深层网络和浅层网络相比有什么优势呢?简单来说深层网络能够表达力更强。事实上,一个仅有一个隐藏层的神经网络就能拟合任何一个函数,但是它需要很多很多的神经元。而深层网络用少得多的神经元就能拟合同样的函数。也就是为了拟合一个函数,要么使用一个浅而宽的网络,要么使用一个深而窄的网络。而后者往往更节约资源。
深层网络也有劣势,就是它不太容易训练。简单的说,你需要大量的数据,很多的技巧才能训练好一个深层网络。这是个手艺活。
二、感知机
人工神经网络(ANN)算法的起源是希望模仿人类的大脑活动来运行程序。人脑的活动是由数量庞大的神经元组成的,神经元的构成图如下:
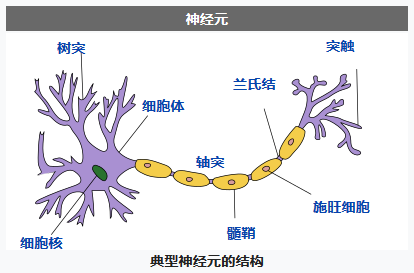
单个神经元在树突上收集其他神经元传递过来的信息,在信息量到达一个阈值之后,便会产生一个脉冲信号,经过轴突传送到突触,进而传递给下一个神经元。
感知机正是模仿这一神经元的运行过程进行的设计。最初的感知机模型也是一种二元表示法,也就是要么有信号产生,要么没有信号产生。
神经元也叫做感知器。感知器算法在上个世纪50-70年代很流行,也成功解决了很多问题。并且,感知器算法也是非常简单的。下图是一个感知器:
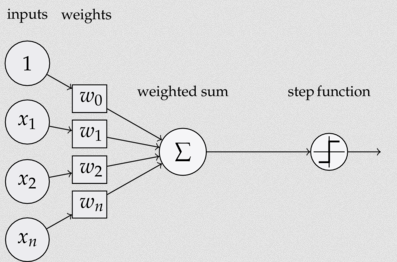
可以看到一个感知机由如下几个部分构成:
- 输入权值:每个输入都有一个权值,另外还有一个W0表示偏置,偏置的作用是让后面的阶跃函数位于原点。
- 激活函数:这里采用阶跃函数作为激活函数,实际应用的还有很多激活函数,诸如Sigmoid函数,Relu等等。

- 输出:该感知器的输出由下面这个公式来计算

举个例子:
使用感知机完成与门和或门。

感知机还能做什么
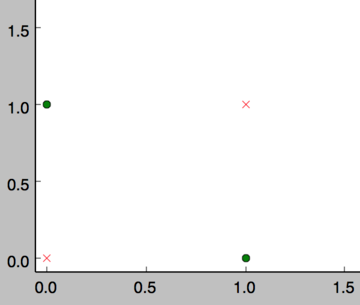
事实上,感知器不仅仅能实现简单的布尔运算。它可以拟合任何的线性函数,任何线性分类或线性回归问题都可以用感知器来解决。前面的布尔运算可以看作是二分类问题,即给定一个输入,输出0(属于分类0)或1(属于分类1)。如下面所示,and运算是一个线性分类问题,即可以用一条直线把分类0(false,红叉表示)和分类1(true,绿点表示)分开。
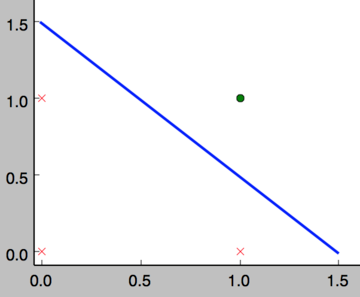
然而,感知器却不能实现异或运算,如下图所示,异或运算不是线性的,你无法用一条直线把分类0和分类1分开。(处理这种非线性问题就需要使用多层感知器了)
感知器的训练
上文中使用感知器来完成And和Or逻辑是直接给出了各个权值的值,那么在实际问题中我们不知道权值的情况下又该如何训练得到这些权值呢。很自然的可以想到使用梯度下降法(Gradient Descent)。
- 批梯度下降(Batch Gradient Descent)



这里采用的是批处理的方式,也就是对一批数据D进行wi的微调,具体方式就是将这批中的微调量求和,最后再统一进行调整。
随机梯度下降算法(Stochastic Gradient Descent, SGD)
当然也可以进行即时的调整,就是每来一条数据就进行调整,其公式如下:

每次从训练数据中取出一个样本的输入向量,使用感知器计算其输出,再根据上面的规则来调整权重。每处理一个样本就调整一次权重。经过多轮迭代后(即全部的训练数据被反复处理多轮),就可以训练出感知器的权重,使之实现目标函数。
三、神经网络与反向传播算法
本章节,我们将把这些单独的单元按照一定的规则相互连接在一起形成神经网络,从而奇迹般的获得了强大的学习能力。我们还将介绍这种网络的训练算法:反向传播算法。
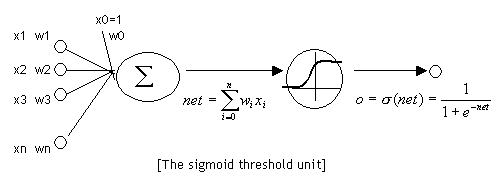
神经元
神经元和感知器本质上是一样的,只不过我们说感知器的时候,它的激活函数是阶跃函数;而当我们说神经元时,激活函数往往选择为sigmoid函数或tanh函数。如下图所示:
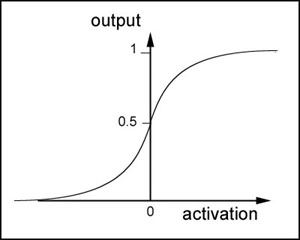
sigmoid函数是一个非线性函数,值域是(0,1)。函数图像如下图所示:
sigmoid函数的导数是:
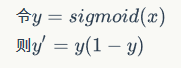
可以看到,sigmoid函数的导数非常有趣,它可以用sigmoid函数自身来表示。这样,一旦计算出sigmoid函数的值,计算它的导数的值就非常方便。
神经网络是啥
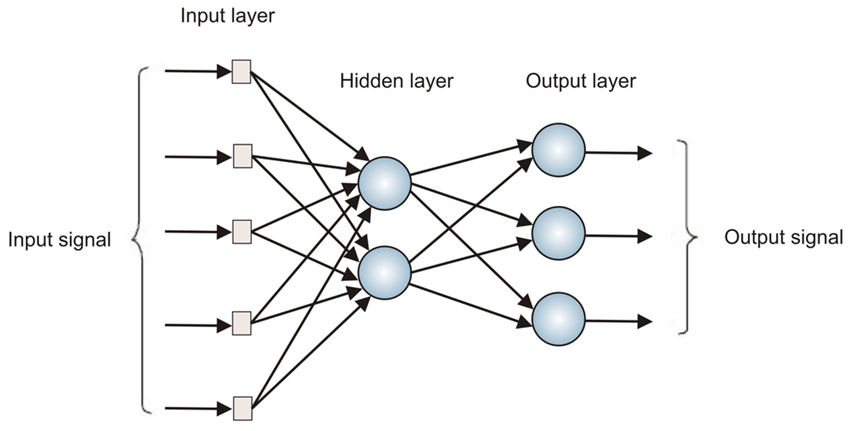
神经网络其实就是按照一定规则连接起来的多个神经元。上图展示了一个全连接(full connected, FC)神经网络,通过观察上面的图,我们可以发现它的规则包括:
- 神经元按照层来布局。最左边的层叫做输入层,负责接收输入数据;最右边的层叫输出层,我们可以从这层获取神经网络输出数据。输入层和输出层之间的层叫做隐藏层,因为它们对于外部来说是不可见的。
- 同一层的神经元之间没有连接。
- 第N层的每个神经元和第N-1层的所有神经元相连(这就是full connected的含义),第N-1层神经元的输出就是第N层神经元的输入。
- 每个连接都有一个权值。
上面这些规则定义了全连接神经网络的结构。事实上还存在很多其它结构的神经网络,比如卷积神经网络(CNN)、循环神经网络(RNN),他们都具有不同的连接规则。
神经网络的训练
现在,我们需要知道一个神经网络的每个连接上的权值是如何得到的。我们可以说神经网络是一个模型,那么这些权值就是模型的参数,也就是模型要学习的东西。然而,一个神经网络的连接方式、网络的层数、每层的节点数这些参数,则不是学习出来的,而是人为事先设置的。对于这些人为设置的参数,我们称之为超参数(Hyper-Parameters)。
接下来,我们将要介绍神经网络的训练算法:反向传播算法。
反向传播算法(Back Propagation)
我们以监督学习为例来解释反向传播算法。
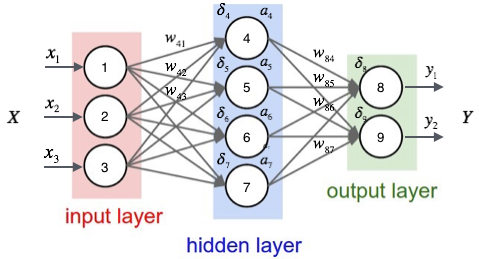
我们可以首先随机初始化各个权重值,有了输入后,就可以分别计算隐藏层的输出ai,以及输出层的输出yi。
然后,我们按照下面的方法计算出每个节点的误差项deltai。
- 对于输出层节点i

- 对于隐藏层节点
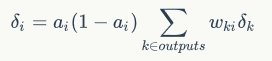
其中ai是第i个结点的输出项,Wki是第i个结点的所有下游,deltak是下游各个误差项。
- 统一的权值的更新方法
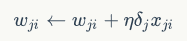
我们已经介绍了神经网络每个节点误差项的计算和权重更新方法。显然,计算一个节点的误差项,需要先计算每个与其相连的下一层节点的误差项。这就要求误差项的计算顺序必须是从输出层开始,然后反向依次计算每个隐藏层的误差项,直到与输入层相连的那个隐藏层。这就是反向传播算法的名字的含义。当所有节点的误差项计算完毕后,我们就可以根据上式来更新所有的权重。
数学推导:
按照机器学习的通用套路,我们先确定神经网络的目标函数,然后用随机梯度下降优化算法去求目标函数最小值时的参数值。
我们取网络所有输出层节点的误差平方和作为目标函数:
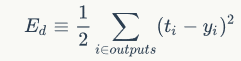
Ed表示样本d的误差。
使用随机梯度下降算法对目标函数进行优化:
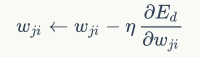
随机梯度下降算法也就是需要计算多个偏导值。
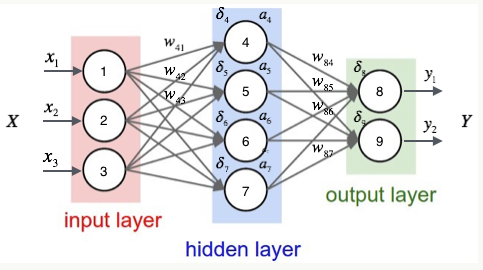
观察上图,我们发现权重wji仅能通过影响节点j的输入来影响整个网络,设netj是结点j的加权输入。
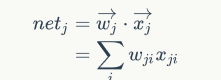
Ed是netj的函数,netj又是wji的函数,应用链式法则:
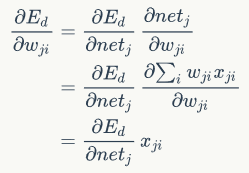
上式中的xji是第i个结点传给第j个结点的值,也就是第i个结点的输出值。
对于前面的偏导式,需要分为输出层和隐藏层分别计算。
输出层权值训练


隐藏层权值训练

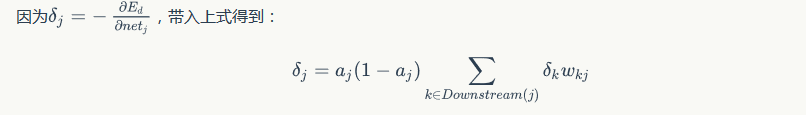
算法框架:

微小的改进:
考虑到平板情况的存在,在使用梯度下降算法的时候可以引入冲量的概念,也就是在修改权重的时候,同时考虑上一次权重的值。

举个例子:
使用神经网络就可以和方便的解决上面提到的线性不可分问题,比如异或问题。


人工神经网络 Artificial Neural Network的更多相关文章
- 吴恩达深度学习第1课第4周-任意层人工神经网络(Artificial Neural Network,即ANN)(向量化)手写推导过程(我觉得已经很详细了)
学习了吴恩达老师深度学习工程师第一门课,受益匪浅,尤其是吴老师所用的符号系统,准确且易区分. 遵循吴老师的符号系统,我对任意层神经网络模型进行了详细的推导,形成笔记. 有人说推导任意层MLP很容易,我 ...
- 人工神经网络(Artificial Neural Networks)
人工神经网络的产生一定程度上受生物学的启发,因为生物的学习系统是由相互连接的神经元相互连接的神经元组成的复杂网络.而人工神经网络跟这个差不多,它是一系列简单的单元相互密集连接而成的.其中每个单元有一定 ...
- 递归神经网络(Recursive Neural Network, RNN)
信息往往还存在着诸如树结构.图结构等更复杂的结构.这就需要用到递归神经网络 (Recursive Neural Network, RNN),巧合的是递归神经网络的缩写和循环神经网络一样,也是RNN,递 ...
- 卷积神经网络(Convolutional Neural Network, CNN)简析
目录 1 神经网络 2 卷积神经网络 2.1 局部感知 2.2 参数共享 2.3 多卷积核 2.4 Down-pooling 2.5 多层卷积 3 ImageNet-2010网络结构 4 DeepID ...
- 深度学习FPGA实现基础知识10(Deep Learning(深度学习)卷积神经网络(Convolutional Neural Network,CNN))
需求说明:深度学习FPGA实现知识储备 来自:http://blog.csdn.net/stdcoutzyx/article/details/41596663 说明:图文并茂,言简意赅. 自今年七月份 ...
- [C4] 前馈神经网络(Feedforward Neural Network)
前馈神经网络(Feedforward Neural Network - BP) 常见的前馈神经网络 感知器网络 感知器(又叫感知机)是最简单的前馈网络,它主要用于模式分类,也可用在基于模式分类的学习控 ...
- 脉冲神经网络Spiking neural network
(原文地址:维基百科) 简单介绍: 脉冲神经网络Spiking neuralnetworks (SNNs)是第三代神经网络模型,其模拟神经元更加接近实际,除此之外,把时间信息的影响也考虑当中.思路是这 ...
- 详解循环神经网络(Recurrent Neural Network)
本文结构: 模型 训练算法 基于 RNN 的语言模型例子 代码实现 1. 模型 和全连接网络的区别 更细致到向量级的连接图 为什么循环神经网络可以往前看任意多个输入值 循环神经网络种类繁多,今天只看最 ...
- 【原创】深度神经网络(Deep Neural Network, DNN)
线性模型通过特征间的现行组合来表达“结果-特征集合”之间的对应关系.由于线性模型的表达能力有限,在实践中,只能通过增加“特征计算”的复杂度来优化模型.比如,在广告CTR预估应用中,除了“标题长度.描述 ...
随机推荐
- nginx集群配置
一.nginx集群目标 以nginx作为代理服务器,分别在两台部署web站点的机器上面轮询访问. 3台机器IP地址分别为: 1)192.168.189.133 (nginx代理服务器) 2)192 ...
- javascript飞机大战-----006创建敌机
先写一个敌机类 /* 创建敌机: */ function Enemy(blood,speed,imgs){ //敌机left this.left = 0; //敌机top this.top = 0; ...
- Asp.net底层机制
Asp.net底层就是用户通过输入网址,然后请求IIs服务器的流程,在这个过程中有一个重要的部件就是ISAPI,这是一个底层的win32API,在扩展方面比较困难,多用于接口之间的桥接,.net和II ...
- vue.js(四)
由于组件内容太多又特别关键,我决定在官网教程的基础上,加上自己的理解,针对每个内容详细记录一下 1.注册组件 ①全局注册 //首先创建组件 Vue.component('blog-post', { ...
- 站点默认访问https
需求简介 现在网站都是https访问了,再用http会显得很low,所以我要把网站设置为默认的https访问. 1nginx的rewrite方法 这应该是大家最容易想到的方法,将所有的http请求通过 ...
- R语言编程
R中的帮助文档非常有用,其中有四种类型的帮助 help(functionname) 对已经加载包所含的函数显示其帮助文档,用?号也是一样的. help.search('keyword') 对已经安装的 ...
- java基础语法this关键字
未经允许,禁止转载!!!!!!!! this关键词在java里面很重要,想了解清楚this就必须对 类:对象:this:成员变量:方法:构造方法 都了解清楚. 一.使用this调用本类中的成员变量( ...
- python16_day35【算法】
一.BTree class BinTreeNode: def __init__(self, data): self.data = data self.lchild = None self.rchild ...
- VS2010/MFC编程入门之十(对话框:设置对话框控件的Tab顺序)
前面几节鸡啄米为大家演示了加法计算器程序完整的编写过程,本节主要讲对话框上控件的Tab顺序如何调整. 上一讲为“计算”按钮添加了消息处理函数后,加法计算器已经能够进行浮点数的加法运算.但是还有个遗留的 ...
- WebApi_返回Post格式数据
[HttpPost] public HttpResponseMessage Post([FromBody] DingTalkCallBack bodyMsg, string signature, st ...