Codeforces Round #396 (Div. 2) A,B,C,D,E
2 seconds
256 megabytes
standard input
standard output
While Mahmoud and Ehab were practicing for IOI, they found a problem which name was Longest common subsequence. They solved it, and then Ehab challenged Mahmoud with another problem.
Given two strings a and b, find the length of their longest uncommon subsequence, which is the longest string that is a subsequence of one of them and not a subsequence of the other.
A subsequence of some string is a sequence of characters that appears in the same order in the string, The appearances don't have to be consecutive, for example, strings "ac", "bc", "abc" and "a" are subsequences of string "abc" while strings "abbc" and "acb" are not. The empty string is a subsequence of any string. Any string is a subsequence of itself.
The first line contains string a, and the second line — string b. Both of these strings are non-empty and consist of lowercase letters of English alphabet. The length of each string is not bigger than 105 characters.
If there's no uncommon subsequence, print "-1". Otherwise print the length of the longest uncommon subsequence of a and b.
abcd
defgh
5
a
a
-1
In the first example: you can choose "defgh" from string b as it is the longest subsequence of string b that doesn't appear as a subsequence of string a.
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+;
string a,b;
int main()
{
cin>>a>>b;
if(a.size()!=b.size())
{
cout<<max(a.size(),b.size())<<endl;
}
else if(a==b)
printf("-1\n");
else
cout<<a.size()<<endl;
return ;
}
2 seconds
256 megabytes
standard input
standard output
Mahmoud has n line segments, the i-th of them has length ai. Ehab challenged him to use exactly 3 line segments to form a non-degenerate triangle. Mahmoud doesn't accept challenges unless he is sure he can win, so he asked you to tell him if he should accept the challenge. Given the lengths of the line segments, check if he can choose exactly 3 of them to form a non-degenerate triangle.
Mahmoud should use exactly 3 line segments, he can't concatenate two line segments or change any length. A non-degenerate triangle is a triangle with positive area.
The first line contains single integer n (3 ≤ n ≤ 105) — the number of line segments Mahmoud has.
The second line contains n integers a1, a2, ..., an (1 ≤ ai ≤ 109) — the lengths of line segments Mahmoud has.
In the only line print "YES" if he can choose exactly three line segments and form a non-degenerate triangle with them, and "NO" otherwise.
5
1 5 3 2 4
YES
3
4 1 2
NO
For the first example, he can use line segments with lengths 2, 4 and 5 to form a non-degenerate triangle.
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+;
int a[N];
int main()
{
int n;
scanf("%d",&n);
for(int i=;i<=n;i++)
scanf("%d",&a[i]);
sort(a+,a++n);
for(int i=;i<=n-;i++)
{
if(a[i]+a[i+]>a[i+])
return puts("YES");
}
puts("NO");
return ;
}
2 seconds
256 megabytes
standard input
standard output
Mahmoud wrote a message s of length n. He wants to send it as a birthday present to his friend Moaz who likes strings. He wrote it on a magical paper but he was surprised because some characters disappeared while writing the string. That's because this magical paper doesn't allow character number i in the English alphabet to be written on it in a string of length more than ai. For example, if a1 = 2 he can't write character 'a' on this paper in a string of length 3 or more. String "aa" is allowed while string "aaa" is not.
Mahmoud decided to split the message into some non-empty substrings so that he can write every substring on an independent magical paper and fulfill the condition. The sum of their lengths should be n and they shouldn't overlap. For example, if a1 = 2 and he wants to send string "aaa", he can split it into "a" and "aa" and use 2 magical papers, or into "a", "a" and "a" and use 3 magical papers. He can't split it into "aa" and "aa" because the sum of their lengths is greater than n. He can split the message into single string if it fulfills the conditions.
A substring of string s is a string that consists of some consecutive characters from string s, strings "ab", "abc" and "b" are substrings of string "abc", while strings "acb" and "ac" are not. Any string is a substring of itself.
While Mahmoud was thinking of how to split the message, Ehab told him that there are many ways to split it. After that Mahmoud asked you three questions:
- How many ways are there to split the string into substrings such that every substring fulfills the condition of the magical paper, the sum of their lengths is n and they don't overlap? Compute the answer modulo 109 + 7.
- What is the maximum length of a substring that can appear in some valid splitting?
- What is the minimum number of substrings the message can be spit in?
Two ways are considered different, if the sets of split positions differ. For example, splitting "aa|a" and "a|aa" are considered different splittings of message "aaa".
The first line contains an integer n (1 ≤ n ≤ 103) denoting the length of the message.
The second line contains the message s of length n that consists of lowercase English letters.
The third line contains 26 integers a1, a2, ..., a26 (1 ≤ ax ≤ 103) — the maximum lengths of substring each letter can appear in.
Print three lines.
In the first line print the number of ways to split the message into substrings and fulfill the conditions mentioned in the problem modulo109 + 7.
In the second line print the length of the longest substring over all the ways.
In the third line print the minimum number of substrings over all the ways.
3
aab
2 3 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
3
2
2
10
abcdeabcde
5 5 5 5 4 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
401
4
3
In the first example the three ways to split the message are:
- a|a|b
- aa|b
- a|ab
The longest substrings are "aa" and "ab" of length 2.
The minimum number of substrings is 2 in "a|ab" or "aa|b".
Notice that "aab" is not a possible splitting because the letter 'a' appears in a substring of length 3, while a1 = 2.
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define pi (4*atan(1.0))
#define eps 1e-14
#define bug(x,y) cout<<"bug"<<x<<" "<<y<<endl;
const int N=1e3+,M=1e6+,inf=1e8+,mod=1e9+;
const ll INF=1e18+;
char a[N];
int s[N];
int dp[][N];
void solve1(int n)
{
int ans2=;
dp[][]=;
for(int i=;i<=n;i++)
dp[][i]=inf;
for(int i=;i<=n;i++)
{
int st=max(,i-s[a[i]-'a'+]+);
for(int j=i;j>=;j--)
{
st=max(st,i-s[a[j]-'a'+]+);
if(st>j)break;
ans2=max(ans2,i-j+);
dp[][i]=(dp[][i]+dp[][j-])%mod;
dp[][i]=min(dp[][i],dp[][j-]+);
} //cout<<dp[1][i]<<" xxx"<<endl;
}
printf("%d\n%d\n%d\n",dp[][n],ans2,dp[][n]);
}
int main()
{
int n;
scanf("%d",&n);
scanf("%s",a+);
for(int i=;i<=;i++)
scanf("%d",&s[i]);
solve1(n);
return ;
}
4 seconds
256 megabytes
standard input
standard output
Mahmoud wants to write a new dictionary that contains n words and relations between them. There are two types of relations: synonymy (i. e. the two words mean the same) and antonymy (i. e. the two words mean the opposite). From time to time he discovers a new relation between two words.
He know that if two words have a relation between them, then each of them has relations with the words that has relations with the other. For example, if like means love and love is the opposite of hate, then like is also the opposite of hate. One more example: iflove is the opposite of hate and hate is the opposite of like, then love means like, and so on.
Sometimes Mahmoud discovers a wrong relation. A wrong relation is a relation that makes two words equal and opposite at the same time. For example if he knows that love means like and like is the opposite of hate, and then he figures out that hate meanslike, the last relation is absolutely wrong because it makes hate and like opposite and have the same meaning at the same time.
After Mahmoud figured out many relations, he was worried that some of them were wrong so that they will make other relations also wrong, so he decided to tell every relation he figured out to his coder friend Ehab and for every relation he wanted to know is it correct or wrong, basing on the previously discovered relations. If it is wrong he ignores it, and doesn't check with following relations.
After adding all relations, Mahmoud asked Ehab about relations between some words based on the information he had given to him. Ehab is busy making a Codeforces round so he asked you for help.
The first line of input contains three integers n, m and q (2 ≤ n ≤ 105, 1 ≤ m, q ≤ 105) where n is the number of words in the dictionary,m is the number of relations Mahmoud figured out and q is the number of questions Mahmoud asked after telling all relations.
The second line contains n distinct words a1, a2, ..., an consisting of small English letters with length not exceeding 20, which are the words in the dictionary.
Then m lines follow, each of them contains an integer t (1 ≤ t ≤ 2) followed by two different words xi and yi which has appeared in the dictionary words. If t = 1, that means xi has a synonymy relation with yi, otherwise xi has an antonymy relation with yi.
Then q lines follow, each of them contains two different words which has appeared in the dictionary. That are the pairs of words Mahmoud wants to know the relation between basing on the relations he had discovered.
All words in input contain only lowercase English letters and their lengths don't exceed 20 characters. In all relations and in all questions the two words are different.
First, print m lines, one per each relation. If some relation is wrong (makes two words opposite and have the same meaning at the same time) you should print "NO" (without quotes) and ignore it, otherwise print "YES" (without quotes).
After that print q lines, one per each question. If the two words have the same meaning, output 1. If they are opposites, output 2. If there is no relation between them, output 3.
See the samples for better understanding.
3 3 4
hate love like
1 love like
2 love hate
1 hate like
love like
love hate
like hate
hate like
YES
YES
NO
1
2
2
2
8 6 5
hi welcome hello ihateyou goaway dog cat rat
1 hi welcome
1 ihateyou goaway
2 hello ihateyou
2 hi goaway
2 hi hello
1 hi hello
dog cat
dog hi
hi hello
ihateyou goaway
welcome ihateyou
YES
YES
YES
YES
NO
YES
3
3
1
1
2
题意:n个单词,1表示两个单词同义,2表示反义;
思路:再开一倍的点,表示那个单词的反义,并查集一下;
#pragma comment(linker, "/STACK:1024000000,1024000000")
#include<iostream>
#include<cstdio>
#include<cmath>
#include<string>
#include<queue>
#include<algorithm>
#include<stack>
#include<cstring>
#include<vector>
#include<list>
#include<set>
#include<map>
using namespace std;
#define ll long long
#define pi (4*atan(1.0))
#define eps 1e-14
#define bug(x) cout<<"bug"<<x<<endl;
const int N=2e5+,M=1e6+;
const ll INF=1e18+,mod=;
int si;
int fa[N];
map<string,int>mp;
int Find(int x)
{
return x==fa[x]?x:fa[x]=Find(fa[x]);
}
int update(int u,int v)
{
int x=Find(u);
int y=Find(v);
if(x!=y)
{
fa[x]=y;
return ;
}
else return ;
}
int main()
{
int n,m,q;
scanf("%d%d%d",&n,&m,&q);
for(int i=; i<=*n; i++)
fa[i]=i;
for(int i=; i<=n; i++)
{
string a;
cin>>a;
mp[a]=i;
}
for(int i=; i<=m; i++)
{
int flag;
scanf("%d",&flag);
string a,b;
cin>>a>>b;
int u=mp[a];
int v=mp[b];
int x=Find(u);
int y=Find(v);
int h=Find(u+n);
if(flag==)
{
if(y==h)
puts("NO");
else
{
update(u,v);
update(u+n,v+n);
puts("YES");
}
}
else
{
if(x==y)
puts("NO");
else
{
update(u+n,v);
update(u,v+n);
puts("YES");
}
}
}
while(q--)
{
string a,b;
cin>>a>>b;
int x=Find(mp[a]);
int y=Find(mp[b]);
int h=Find(mp[a]+n);
if(x==y)
puts("");
else if(y==h)
puts("");
else
puts("");
}
return ;
}
2 seconds
256 megabytes
standard input
standard output
Mahmoud and Ehab live in a country with n cities numbered from 1 to n and connected by n - 1 undirected roads. It's guaranteed that you can reach any city from any other using these roads. Each city has a number ai attached to it.
We define the distance from city x to city y as the xor of numbers attached to the cities on the path from x to y (including both x andy). In other words if values attached to the cities on the path from x to y form an array p of length l then the distance between them is  , where
, where  is bitwise xor operation.
is bitwise xor operation.
Mahmoud and Ehab want to choose two cities and make a journey from one to another. The index of the start city is always less than or equal to the index of the finish city (they may start and finish in the same city and in this case the distance equals the number attached to that city). They can't determine the two cities so they try every city as a start and every city with greater index as a finish. They want to know the total distance between all pairs of cities.
The first line contains integer n (1 ≤ n ≤ 105) — the number of cities in Mahmoud and Ehab's country.
Then the second line contains n integers a1, a2, ..., an (0 ≤ ai ≤ 106) which represent the numbers attached to the cities. Integer ai is attached to the city i.
Each of the next n - 1 lines contains two integers u and v (1 ≤ u, v ≤ n, u ≠ v), denoting that there is an undirected road between cities u and v. It's guaranteed that you can reach any city from any other using these roads.
Output one number denoting the total distance between all pairs of cities.
3
1 2 3
1 2
2 3
10
5
1 2 3 4 5
1 2
2 3
3 4
3 5
52
5
10 9 8 7 6
1 2
2 3
3 4
3 5
131
A bitwise xor takes two bit integers of equal length and performs the logical xor operation on each pair of corresponding bits. The result in each position is 1 if only the first bit is 1 or only the second bit is 1, but will be 0 if both are 0 or both are 1. You can read more about bitwise xor operation here: https://en.wikipedia.org/wiki/Bitwise_operation#XOR.
In the first sample the available paths are:
- city 1 to itself with a distance of 1,
- city 2 to itself with a distance of 2,
- city 3 to itself with a distance of 3,
- city 1 to city 2 with a distance of
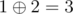 ,
, - city 1 to city 3 with a distance of
 ,
, - city 2 to city 3 with a distance of
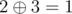 .
.
The total distance between all pairs of cities equals 1 + 2 + 3 + 3 + 0 + 1 = 10.
#pragma comment(linker, "/STACK:1024000000,1024000000")
#include<iostream>
#include<cstdio>
#include<cmath>
#include<string>
#include<queue>
#include<algorithm>
#include<stack>
#include<cstring>
#include<vector>
#include<list>
#include<set>
#include<map>
using namespace std;
#define ll long long
#define pi (4*atan(1.0))
#define eps 1e-14
#define bug(x) cout<<"bug"<<x<<endl;
const int N=2e5+,M=1e6+;
const ll INF=1e18+,mod=;
struct is
{
int v,next;
}edge[N<<];
int head[N],edg,n;
int a[N];
ll num[N][][];
ll ans,sum;
void init()
{
memset(head,-,sizeof(head));
edg=;
}
void add(int u,int v)
{
edg++;
edge[edg].v=v;
edge[edg].next=head[u];
head[u]=edg;
}
void dfs(int u,int fa,int x)
{
int q=(a[u]&(<<x))?:;
num[u][x][q]++;
ll flag0=,flag1=;
for(int i=head[u];i!=-;i=edge[i].next)
{
int v=edge[i].v;
if(v==fa)continue;
dfs(v,u,x);
num[u][x][]+=num[v][x][q^];
num[u][x][]+=num[v][x][q^];
flag0+=num[v][x][];
flag1+=num[v][x][];
}
for(int i=head[u];i!=-;i=edge[i].next)
{
int v=edge[i].v;
if(v==fa)continue;
if(q)
{
ans+=num[v][x][]*(flag0-num[v][x][])*(1LL<<x);
ans+=num[v][x][]*(flag1-num[v][x][])*(1LL<<x);
}
else
{
ans+=num[v][x][]*(flag1-num[v][x][])*(1LL<<x);
ans+=num[v][x][]*(flag0-num[v][x][])*(1LL<<x);
}
sum+=num[v][x][q^]*(1LL<<x);
}
}
int main()
{
init();
scanf("%d",&n);
for(int i=;i<=n;i++)
scanf("%d",&a[i]),sum+=a[i];
for(int i=;i<n;i++)
{
int u,v;
scanf("%d%d",&u,&v);
add(u,v);
add(v,u);
}
for(int i=;i<;i++)
dfs(,-,i);
/*for(int i=1;i<=n;i++)
{
printf("%lld %lld\n",num[i][0][0],num[i][0][1]);
printf("%lld %lld\n\n",num[i][1][0],num[i][1][1]);
}*/
printf("%lld\n",ans/+sum);
return ;
}
2 seconds
256 megabytes
standard input
standard output
While Mahmoud and Ehab were practicing for IOI, they found a problem which name was Longest common subsequence. They solved it, and then Ehab challenged Mahmoud with another problem.
Given two strings a and b, find the length of their longest uncommon subsequence, which is the longest string that is a subsequence of one of them and not a subsequence of the other.
A subsequence of some string is a sequence of characters that appears in the same order in the string, The appearances don't have to be consecutive, for example, strings "ac", "bc", "abc" and "a" are subsequences of string "abc" while strings "abbc" and "acb" are not. The empty string is a subsequence of any string. Any string is a subsequence of itself.
The first line contains string a, and the second line — string b. Both of these strings are non-empty and consist of lowercase letters of English alphabet. The length of each string is not bigger than 105 characters.
If there's no uncommon subsequence, print "-1". Otherwise print the length of the longest uncommon subsequence of a and b.
abcd
defgh
5
a
a
-1
In the first example: you can choose "defgh" from string b as it is the longest subsequence of string b that doesn't appear as a subsequence of string a.
Codeforces Round #396 (Div. 2) A,B,C,D,E的更多相关文章
- Codeforces Round #396 (Div. 2) D. Mahmoud and a Dictionary 并查集
D. Mahmoud and a Dictionary 题目连接: http://codeforces.com/contest/766/problem/D Description Mahmoud wa ...
- Codeforces Round #396 (Div. 2) A B C D 水 trick dp 并查集
A. Mahmoud and Longest Uncommon Subsequence time limit per test 2 seconds memory limit per test 256 ...
- Codeforces Round #396 (Div. 2) D. Mahmoud and a Dictionary
地址:http://codeforces.com/contest/766/problem/D 题目: D. Mahmoud and a Dictionary time limit per test 4 ...
- Codeforces Round #396 (Div. 2) D
Mahmoud wants to write a new dictionary that contains n words and relations between them. There are ...
- Codeforces Round #396 (Div. 2) E. Mahmoud and a xor trip dfs 按位考虑
E. Mahmoud and a xor trip 题目连接: http://codeforces.com/contest/766/problem/E Description Mahmoud and ...
- Codeforces Round #396 (Div. 2) C. Mahmoud and a Message dp
C. Mahmoud and a Message 题目连接: http://codeforces.com/contest/766/problem/C Description Mahmoud wrote ...
- Codeforces Round #396 (Div. 2) B. Mahmoud and a Triangle 贪心
B. Mahmoud and a Triangle 题目连接: http://codeforces.com/contest/766/problem/B Description Mahmoud has ...
- Codeforces Round #396 (Div. 2) A. Mahmoud and Longest Uncommon Subsequence 水题
A. Mahmoud and Longest Uncommon Subsequence 题目连接: http://codeforces.com/contest/766/problem/A Descri ...
- Codeforces Round #396 (Div. 2) E. Mahmoud and a xor trip
地址:http://codeforces.com/contest/766/problem/E 题目: E. Mahmoud and a xor trip time limit per test 2 s ...
随机推荐
- 【BZOJ4196】[Noi2015]软件包管理器 树链剖分
[Noi2015]软件包管理器 树链剖分 Description Linux用户和OSX用户一定对软件包管理器不会陌生.通过软件包管理器,你可以通过一行命令安装某一个软件包,然后软件包管理器会帮助你从 ...
- for update 和 t.rowid的区别
select * from table_name for update; 和 select t.*, t.rowid from table_name t 的区别 前者会对你查询出来的结果加上锁,而后者 ...
- 模拟退火算法(西安网选赛hdu5017)
Ellipsoid Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others) Total ...
- postgresql----数据库表约束----NOT NULL,DEFAULT,CHECK
数据库表有NOT NULL,DEFAULT,CHECK,UNIQUE,PRIMARY KEY,FOREIGN KEY六种约束. 一.NOT NULL ---- 非空约束 NULL表示没有数据,不表示具 ...
- WebSocket学习记录
参考资料: Java后端WebSocket的Tomcat实现 基于Java的WebSocket推送 java WebSocket的实现以及Spring WebSocket 利用spring-webso ...
- EF批量添加,删除,修改的扩展
在EF各版本中,没有相应批量的添加,删除,修改,在用ORM 处理数据时直有个尴尬.在网上,也接到了很多网友的询问这方面的情况,特此今天把这方面的相关扩展分享一下,(这里只做批量删除的例子,添加和修改的 ...
- Create an Index
db.collection.createIndex( { name: -1 } ) Indexes — MongoDB Manual https://docs.mongodb.com/manual/i ...
- ES6基础教程(整理自阮一峰)
------------------------ECMAScript 6 简介------------------------ECMAScript 和 JavaScript 的关系是,前者是后者的规格 ...
- python redis基本概念简单操作
转自:http://www.cnblogs.com/melonjiang/p/5342383.html 一.redis redis是一个key-value存储系统.和Memcached类似,它支持存储 ...
- (2.3)DDL增强功能-流程化控制与动态sql
1.流程控制 在T-SQL中,与流程控制语句相关的关键字有8个: BEGIN...END BREAK GOTO CONTINUE IF...ELSE WHILE RETURN WAITFOR 其实还可 ...