Android ListView初始化简单分析

DStream
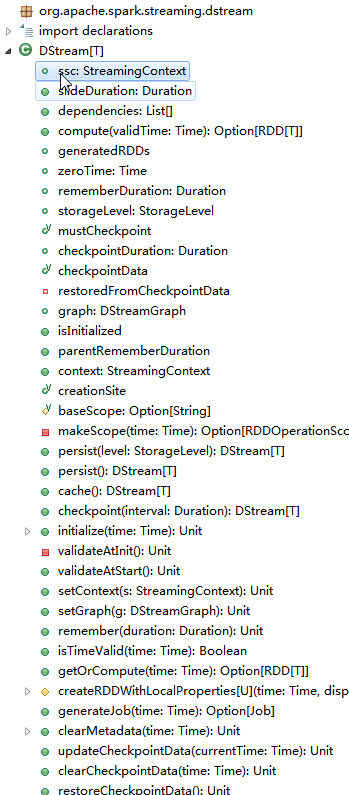
1.1基本说明
1.1.1 Duration
Spark Streaming的时间类型,单位是毫秒;
生成方式如下:
1)new Duration(milli seconds)
输入毫秒数值来生成;
2)seconds(seconds)
输入秒数值来生成;
3)Minutes(minutes)
输入分钟数值来生成;
1.1.2 slideDuration
/** Time interval after which the DStream generates a RDD */
def slideDuration: Duration
slideDuration,时间窗口滑动长度;根据这个时间长度来生成一个RDD;
1.1.3 dependencies
/** List of parent DStreams on which this DStream depends on */
def dependencies: List[DStream[_]]
dependencies,DStreams的依赖关系;
1.1.4 compute
/** Method that generates a RDD for the given time */
def compute(validTime: Time): Option[RDD[T]]
compute,根据给定的时间来生成RDD;
1.1.5 zeroTime
// Time zero for the DStream
private[streaming] var zeroTime: Time = null
zeroTime,DStream的起点时间;
1.1.6 rememberDuration
// Duration for which the DStream will remember each RDD created
private[streaming] var rememberDuration: Duration = null
rememberDuration,记录DStream中每个RDD的产生时间;
1.1 7 storageLevel
// Storage level of the RDDs in the stream
private[streaming] var storageLevel: StorageLevel = StorageLevel.NONE
storageLevel,DStream中每个RDD的存储级别;
1.1.8 parentRememberDuration
// Duration for which the DStream requires its parent DStream to remember each RDD created
private[streaming] def parentRememberDuration = rememberDuration
parentRememberDuration,父DStream记录RDD的生成时间;
1.1.9 persist
/** Persist the RDDs of this DStream with the given storage level */
def persist(level: StorageLevel): DStream[T] = {
if (this.isInitialized) {
throw new UnsupportedOperationException(
"Cannot change storage level of a DStream after streaming context has started")
}
this.storageLevel = level
this
}
Persist,DStream中RDD的存储级别;
1.1.10 checkpoint
/**
* Enable periodic checkpointing of RDDs of this DStream
* @param interval Time interval after which generated RDD will be checkpointed
*/
def checkpoint(interval: Duration): DStream[T] = {
if (isInitialized) {
throw new UnsupportedOperationException(
"Cannot change checkpoint interval of a DStream after streaming context has started")
}
persist()
checkpointDuration = interval
this
}
checkpoint,设置DStream的checkpoint时间间隔;
1.1.11 initialize
/**
* Initialize the DStream by setting the "zero" time, based on which
* the validity of future times is calculated. This method also recursively initializes
* its parent DStreams.
*/
private[streaming] def initialize(time: Time) {
if (zeroTime != null && zeroTime != time) {
throw new SparkException(s"ZeroTime is already initialized to $zeroTime"
+ s", cannot initialize it again to $time")
}
zeroTime = time // Set the checkpoint interval to be slideDuration or 10 seconds, which ever is larger
if (mustCheckpoint && checkpointDuration == null) {
checkpointDuration = slideDuration * math.ceil(Seconds(10) / slideDuration).toInt
logInfo(s"Checkpoint interval automatically set to $checkpointDuration")
} // Set the minimum value of the rememberDuration if not already set
var minRememberDuration = slideDuration
if (checkpointDuration != null && minRememberDuration <= checkpointDuration) {
// times 2 just to be sure that the latest checkpoint is not forgotten (#paranoia)
minRememberDuration = checkpointDuration * 2
}
if (rememberDuration == null || rememberDuration < minRememberDuration) {
rememberDuration = minRememberDuration
} // Initialize the dependencies
dependencies.foreach(_.initialize(zeroTime))
}
initialize,DStream初始化,其初始时间通过"zero" time设置;
1.1.12 getOrCompute
/**
* Get the RDD corresponding to the given time; either retrieve it from cache
* or compute-and-cache it.
*/
private[streaming] final def getOrCompute(time: Time): Option[RDD[T]] = {
getOrCompute,通过时间参数获取RDD;
1.1.13 generateJob
/**
* Generate a SparkStreaming job for the given time. This is an internal method that
* should not be called directly. This default implementation creates a job
* that materializes the corresponding RDD. Subclasses of DStream may override this
* to generate their own jobs.
*/
private[streaming] def generateJob(time: Time): Option[Job] = {
getOrCompute(time) match {
case Some(rdd) =>
val jobFunc = () => {
val emptyFunc = { (iterator: Iterator[T]) => {} }
context.sparkContext.runJob(rdd, emptyFunc)
}
Some(new Job(time, jobFunc))
case None => None
}
}
generateJob,内部方法,来生成SparkStreaming的作业。
1.1.14 clearMetadata
/**
*Clear metadata that are older than `rememberDuration` of this DStream.
* This is an internal method that should notbe called directly. This default
* implementation clears the old generatedRDDs. Subclasses of DStream may override
* this to clear their own metadata alongwith the generated RDDs.
*/
private[streaming]defclearMetadata(time: Time) {
clearMetadata,内部方法,清除DStream中过期的数据。
1.1.15 updateCheckpointData
/**
* Refresh the list of checkpointed RDDs thatwill be saved along with checkpoint of
* this stream. This is an internal methodthat should not be called directly. This is
* a default implementation that saves onlythe file names of the checkpointed RDDs to
* checkpointData. Subclasses of DStream(especially those of InputDStream) may override
* this method to save custom checkpointdata.
*/
private[streaming]defupdateCheckpointData(currentTime:Time) {
updateCheckpointData,内部方法,更新Checkpoint。
1.2 DStream基本操作
1.2.1 map
/** Return a newDStreamby applying a function toall elements of this DStream. */
defmap[U: ClassTag](mapFunc: T=> U): DStream[U] = {
newMappedDStream(this, context.sparkContext.clean(mapFunc))
}
Map操作,对DStream中所有元素进行Map操作,和RDD中的操作一样。
1.2.2 flatMap
/**
* Return a new DStream by applying afunction to all elements of this DStream,
* and then flattening the results
*/
defflatMap[U:ClassTag](flatMapFunc: T => Traversable[U]): DStream[U] = {
newFlatMappedDStream(this, context.sparkContext.clean(flatMapFunc))
}
flatMap操作,对DStream中所有元素进行flatMap操作,和RDD中的操作一样。
1.2.3filter
/** Return a new DStream containing only the elements that satisfy apredicate. */
def filter(filterFunc: T => Boolean): DStream[T] = newFilteredDStream(this, filterFunc)
filter操作,对DStream中所有元素进行过滤,和RDD中的操作一样。
1.2.4 glom
/**
* Return a new DStream in which each RDD isgenerated by applying glom() to each RDD of
* this DStream. Applying glom() to an RDD coalescesall elements within each partition into
* an array.
*/
defglom(): DStream[Array[T]] =new GlommedDStream(this)
glom操作,对DStream中RDD的所有元素聚合,数组形式返回。
1.2.5 repartition
/**
* Return a new DStream with an increased ordecreased level of parallelism. Each RDD in the
* returned DStream has exactly numPartitionspartitions.
*/
defrepartition(numPartitions: Int):DStream[T] =this.transform(_.repartition(numPartitions))
repartition操作,对DStream中RDD重新分区,和RDD中的操作一样。
1.2.6 mapPartitions
/**
* Return a new DStream in which each RDD isgenerated by applying mapPartitions() to each RDDs
* of this DStream. Applying mapPartitions()to an RDD applies a function to each partition
* of the RDD.
*/
defmapPartitions[U:ClassTag](
mapPartFunc: Iterator[T] => Iterator[U],
preservePartitioning: Boolean = false
): DStream[U] = {
newMapPartitionedDStream(this, context.sparkContext.clean(mapPartFunc), preservePartitioning)
}
mapPartitions操作,对DStream中RDD进行mapPartitions操作,和RDD中的操作一样。
1.2.7 reduce
/**
* Return a new DStream in which each RDD hasa single element generated by reducing each RDD
* of this DStream.
*/
defreduce(reduceFunc:(T, T) => T): DStream[T] =
this.map(x => (null, x)).reduceByKey(reduceFunc, 1).map(_._2)
reduce操作,对DStream中RDD进行reduce操作,和RDD中的操作一样。
1.2.8 count
/**
* Return a new DStream in which each RDD hasa single element generated by counting each RDD
* of this DStream.
*/
defcount(): DStream[Long] = {
this.map(_=> (null,1L))
.transform(_.union(context.sparkContext.makeRDD(Seq((null,0L)),1)))
.reduceByKey(_ + _)
.map(_._2)
}
count操作,对DStream中RDD进行count操作,和RDD中的操作一样。
1.2.9 countByValue
/**
* Return a new DStream in which each RDDcontains the counts of each distinct value in
* each RDD of this DStream. Hashpartitioning is used to generate
* the RDDs with `numPartitions` partitions(Spark's default number of partitions if
* `numPartitions` not specified).
*/
defcountByValue(numPartitions:Int = ssc.sc.defaultParallelism)(implicit ord: Ordering[T] = null)
: DStream[(T, Long)] =
this.map(x => (x, 1L)).reduceByKey((x: Long, y: Long) => x +y, numPartitions)
countByValue操作,对DStream中RDD进行countByValue操作,和RDD中的操作一样。
1.2.10 foreachRDD
/**
* Apply a function to each RDD in thisDStream. This is an output operator, so
* 'this' DStream will be registered as anoutput stream and therefore materialized.
*/
defforeachRDD(foreachFunc:(RDD[T], Time) => Unit) {
// because the DStream is reachable from the outer objecthere, and because
// DStreams can't be serialized with closures, we can'tproactively check
// it for serializability and so we pass the optionalfalse to SparkContext.clean
newForEachDStream(this, context.sparkContext.clean(foreachFunc, false)).register()
}
foreachRDD操作,对DStream中RDD进行函数操作,该操作是一个输出操作。
1.2.11 transform
/**
* Return a new DStream in which each RDD isgenerated by applying a function
* on each RDD of 'this' DStream.
*/
deftransform[U:ClassTag](transformFunc: RDD[T] => RDD[U]): DStream[U] = {
// because the DStream is reachable from the outer objecthere, and because
// DStreams can't be serialized with closures, we can'tproactively check
// it for serializability and so we pass the optionalfalse to SparkContext.clean
transform((r: RDD[T], t: Time) =>context.sparkContext.clean(transformFunc(r),false))
}
transform操作,对DStream中RDD进行transform函数操作。
1.2.12 transformWith
/**
* Return a new DStream in which each RDD isgenerated by applying a function
* on each RDD of 'this' DStream and 'other'DStream.
*/
deftransformWith[U: ClassTag,V: ClassTag](
other: DStream[U], transformFunc:(RDD[T], RDD[U]) => RDD[V]
): DStream[V] = {
// because the DStream is reachable from the outer objecthere, and because
// DStreams can't be serialized with closures, we can'tproactively check
// it for serializability and so we pass the optionalfalse to SparkContext.clean
valcleanedF = ssc.sparkContext.clean(transformFunc, false)
transformWith(other, (rdd1: RDD[T], rdd2:RDD[U], time: Time) => cleanedF(rdd1, rdd2))
}
transformWith操作,对DStream与其它DStream进行transform函数操作。
1.2.13 print
/**
* Print the first ten elements of each RDDgenerated in this DStream. This is an output
* operator, so this DStream will beregistered as an output stream and there materialized.
*/
defprint() {
defforeachFunc = (rdd: RDD[T], time: Time) => {
valfirst11 = rdd.take(11)
println ("-------------------------------------------")
println ("Time: " + time)
println ("-------------------------------------------")
first11.take(10).foreach(println)
if(first11.size > 10) println("...")
println()
}
newForEachDStream(this, context.sparkContext.clean(foreachFunc)).register()
}
print操作,对DStream进行打印输出,这是一个输出操作。
1.2.14 window
/**
* Return a new DStream in which each RDDcontains all the elements in seen in a
* sliding window of time over this DStream.The new DStream generates RDDs with
* the same interval as this DStream.
* @param windowDuration width of thewindow; must be a multiple of this DStream's interval.
*/
defwindow(windowDuration:Duration): DStream[T] = window(windowDuration,this.slideDuration)
/**
* Return a new DStreaminwhich each RDD contains all the elements in seen in a
* sliding window of time over this DStream.
* @param windowDuration width of thewindow; must be a multiple of this DStream's
* batching interval
* @param slideDuration sliding interval of the window (i.e., theinterval after which
* the new DStream willgenerate RDDs); must be a multiple of this
* DStream's batchinginterval
*/
def window(windowDuration:Duration, slideDuration: Duration): DStream[T] = {
newWindowedDStream(this, windowDuration, slideDuration)
}
window操作,设置窗口时长、滑动时长,生成一个窗口的DStream。
1.2.15 reduceByWindow
/**
* Return a new DStream in which each RDD hasa single element generated by reducing all
* elements in a sliding window over thisDStream.
* @param reduceFunc associativereduce function
* @param windowDuration width of thewindow; must be a multiple of this DStream's
* batching interval
* @paramslideDuration sliding interval of thewindow (i.e., the interval after which
* the new DStream willgenerate RDDs); must be a multiple of this
* DStream's batchinginterval
*/
def reduceByWindow(
reduceFunc: (T, T) => T,
windowDuration: Duration,
slideDuration: Duration
): DStream[T] = {
this.reduce(reduceFunc).window(windowDuration,slideDuration).reduce(reduceFunc)
}
/**
* Return a new DStream in which each RDD hasa single element generated by reducing all
* elements in a sliding window over thisDStream. However, the reduction is done incrementally
* using the old window's reduced value :
* 1.reduce the new values that entered the window (e.g., adding new counts)
* 2."inverse reduce" the old values that left the window (e.g.,subtracting old counts)
* This is more efficient than reduceByWindow without "inversereduce" function.
* However, it is applicable to only "invertible reduce functions".
* @param reduceFunc associativereduce function
* @param invReduceFunc inverse reducefunction
* @param windowDuration width of thewindow; must be a multiple of this DStream's
* batching interval
* @param slideDuration sliding interval of the window (i.e., theinterval after which
* the new DStream willgenerate RDDs); must be a multiple of this
* DStream's batchinginterval
*/
defreduceByWindow(
reduceFunc:(T, T) => T,
invReduceFunc: (T, T) => T,
windowDuration: Duration,
slideDuration: Duration
): DStream[T] = {
this.map(x=> (1, x))
.reduceByKeyAndWindow(reduceFunc,invReduceFunc, windowDuration, slideDuration,1)
.map(_._2)
}
reduceByWindow操作,对窗口进行reduceFunc操作。
1.2.16 countByWindow
/**
* Return a new DStream in which each RDD hasa single element generated by counting the number
* of elements in a sliding window over thisDStream. Hash partitioning is used to generate
* the RDDs with Spark's default number ofpartitions.
* @param windowDuration width of thewindow; must be a multiple of this DStream's
* batching interval
* @param slideDuration sliding interval of the window (i.e., theinterval after which
* the new DStream willgenerate RDDs); must be a multiple of this
* DStream's batchinginterval
*/
defcountByWindow(windowDuration:Duration, slideDuration: Duration): DStream[Long] = {
this.map(_=>1L).reduceByWindow(_ + _, _ - _, windowDuration, slideDuration)
}
countByWindow操作,对窗口进行count操作。
1.2.17countByValueAndWindow
/**
* Return a new DStream in which each RDDcontains the count of distinct elements in
* RDDs in a sliding window over thisDStream. Hash partitioning is used to generate
* the RDDs with `numPartitions` partitions(Spark's default number of partitions if
* `numPartitions` not specified).
* @param windowDuration width of thewindow; must be a multiple of this DStream's
* batching interval
* @param slideDuration sliding interval of the window (i.e., theinterval after which
* the new DStream willgenerate RDDs); must be a multiple of this
* DStream's batchinginterval
* @param numPartitions number of partitions of each RDD in the newDStream.
*/
defcountByValueAndWindow(
windowDuration: Duration,
slideDuration: Duration,
numPartitions: Int =ssc.sc.defaultParallelism)
(implicitord: Ordering[T] = null)
: DStream[(T, Long)] =
{
this.map(x=> (x, 1L)).reduceByKeyAndWindow(
(x: Long, y: Long) => x + y,
(x: Long, y: Long) => x - y,
windowDuration,
slideDuration,
numPartitions,
(x: (T, Long)) => x._2 != 0L
)
}
countByValueAndWindow操作,对窗口进行countByValue操作。
1.2.18 union
/**
* Return a new DStream by unifying data ofanother DStream with this DStream.
* @paramthat Another DStream having the same slideDuration as this DStream.
*/
defunion(that:DStream[T]): DStream[T] =new UnionDStream[T](Array(this, that))
/**
* Return all the RDDs defined by theInterval object (both end times included)
*/
def slice(interval:Interval): Seq[RDD[T]] = {
slice(interval.beginTime, interval.endTime)
}
union操作,对DStream和其它DStream进行合并操作。
1.2.19 slice
/**
* Return all the RDDs between 'fromTime' to'toTime' (both included)
*/
defslice(fromTime:Time, toTime: Time): Seq[RDD[T]] = {
if(!isInitialized) {
thrownew SparkException(this + " has not beeninitialized")
}
if(!(fromTime - zeroTime).isMultipleOf(slideDuration)) {
logWarning("fromTime (" + fromTime + ") is not amultiple of slideDuration ("
+ slideDuration + ")")
}
if(!(toTime - zeroTime).isMultipleOf(slideDuration)) {
logWarning("toTime (" + fromTime + ") is not amultiple of slideDuration ("
+ slideDuration + ")")
}
valalignedToTime = toTime.floor(slideDuration)
valalignedFromTime = fromTime.floor(slideDuration)
logInfo("Slicing from " + fromTime + " to " + toTime +
" (aligned to " + alignedFromTime + " and " + alignedToTime + ")")
alignedFromTime.to(alignedToTime,slideDuration).flatMap(time => {
if(time >= zeroTime) getOrCompute(time) elseNone
})
}
slice操作,根据时间间隔,取DStream中的每个RDD序列,生成一个RDD。
1.2.20saveAsObjectFiles
/**
* Save each RDD in this DStream as aSequence file of serialized objects.
* The file name at each batch interval isgenerated based on `prefix` and
* `suffix`:"prefix-TIME_IN_MS.suffix".
*/
defsaveAsObjectFiles(prefix: String, suffix: String = ""){
valsaveFunc = (rdd: RDD[T], time: Time) => {
valfile = rddToFileName(prefix, suffix, time)
rdd.saveAsObjectFile(file)
}
this.foreachRDD(saveFunc)
}
saveAsObjectFiles操作,输出操作,对DStream中的每个RDD输出为序列化文件格式。
1.2.21 saveAsTextFiles
/**
* Save each RDD in this DStreamasat text file, using string representation
* of elements. The file name at each batchinterval is generated based on
* `prefix` and `suffix`:"prefix-TIME_IN_MS.suffix".
*/
defsaveAsTextFiles(prefix:String, suffix: String ="") {
valsaveFunc = (rdd: RDD[T], time: Time) => {
valfile = rddToFileName(prefix, suffix, time)
rdd.saveAsTextFile(file)
}
this.foreachRDD(saveFunc)
}
/**
* Register this streaming as an outputstream. This would ensure that RDDs of this
* DStream will be generated.
*/
private[streaming]defregister(): DStream[T] = {
ssc.graph.addOutputStream(this)
this
}
}
saveAsTextFiles操作,输出操作,对DStream中的每个RDD输出为文本格式。
转载请注明出处:
http://blog.csdn.net/sunbow0/article/details/43091247
Android ListView初始化简单分析的更多相关文章
- Android.mk文件简单分析
Android.mk文件简单分析 一个Android.mk文件用来向编译系统描写叙述须要编译的源码.详细来说:该文件是GNUMakefile的一小部分.会被编译系统解析一次或多次. 能够在每个Andr ...
- Android—— ListView 的简单用法及定制ListView界面
一.ListView的简单用法 2. 训练目标 1) 掌握 ListView 控件的使用 2) 掌握 Adapter 桥梁的作用 实现步骤: 1)首先新建一个项目, 并让ADT 自动帮我们创建好活动. ...
- android:ListView 的简单用法
首 先新 建 一个 ListViewTest 项 目, 并 让 ADT 自 动帮 我 们创 建 好 活动 . 然后 修 改 activity_main.xml 中的代码,如下所示: <Linea ...
- android#ListView的简单用法
新建项目,并修改项目生产的主文件activity_main.xml <LinearLayout xmlns:android="http://schemas.android.com/ap ...
- Android Launcher 3 简单分析
最近在学习Android Launcher的相关知识,在github上找到可以在Android studio上编译的Launcher 3代码,地址:https://github.com/rydanli ...
- android ListView 九大重要属性详细分析、
android ListView 九大重要属性详细分析. 1.android ListView 一些重要属性详解,兄弟朋友可以参考一下. 首先是stackFromBottom属性,这只该属性之后你做好 ...
- Android SQLite与ListView的简单使用
2017-04-25 初写博客有很多地方都有不足,希望各位大神给点建议. 回归主题,这次简单的给大家介绍一下Android SQLite与ListView的简单使用sqlite在上节中有介绍,所以在这 ...
- Android实现录屏直播(一)ScreenRecorder的简单分析
http://blog.csdn.net/zxccxzzxz/article/details/54150396 Android实现录屏直播(一)ScreenRecorder的简单分析 Android实 ...
- Android ListView异步载入图片乱序问题,原因分析及解决方式
转载请注明出处:http://blog.csdn.net/guolin_blog/article/details/45586553 在Android全部系统自带的控件其中,ListView这个控件算是 ...
随机推荐
- JS函数的参数对象arguments在严格模式下的限制
在JS中,传入的函数的参数个数可以与定义函数的个数不一致,那么对于传入的实参的引用,则是arguments对象.然而改对象在严格模式和非严格模式下是由区分的: 1 在严格模式下arguments作为了 ...
- Openstack安装
作者:陈沙克 Openstack发展很猛,很多朋友都很认同,2013年,会很好的解决OpenStack部署的问题,让安装,配置变得更加简单易用. 很多公司都投入人力去做这个,新浪也计划做一个Opens ...
- SQL技巧之分组求和
这是CSDN问答里面有人提出的一道问题,题目如下. 表格如下: 得出结果如下: 求精简的SQL语句. SQL查询语句: with a as( select rank() over (partition ...
- Sublime Text3快捷键一览表
选择类 Ctrl+D 选中光标所占的文本,继续操作则会选中下一个相同的文本. Alt+F3 选中文本按下快捷键,即可一次性选择全部的相同文本进行同时编辑.举个栗子:快速选中并更改所有相同的变量名.函数 ...
- 响应式布局中重要的meta标签设置.适用于手机浏览器兼容性设置
<!-- #手机浏览器兼容性设置 --> <meta content="application/xhtml+xml;charset=UTF-8" http- ...
- Quartz Sheduler 入门
Quartz Sheduler 入门 原文地址:http://www.quartz-scheduler.org/generated/2.2.2/html/qtz-all/ 下载地址:http://qu ...
- 图片上传iOS
//图片上传 - (void)upLoadImage{ if(self.frontImage && self.backImage){ //性别 NSString *sexStr; if ...
- hdu 1403 Longest Common Substring(最长公共子字符串)(后缀数组)
http://acm.hdu.edu.cn/showproblem.php?pid=1403 Longest Common Substring Time Limit: 8000/4000 MS (Ja ...
- Angular js总结
之前看过一些angular js的相关技术文档,今天在浏览技术论坛的时候发现有问angular js是做什么用的? 于是有了一个想法,对于自己对angular js 的认知做一个总结. 总结: ang ...
- C# 发送邮件实例代码
1.构造附件 static List<Attachment> BuildAttachments(List<EmailFile> files) { ) { return null ...