java源码之HashSet
1,HashSet介绍
1)HashSet 是一个没有重复元素的集合。
2)它是由HashMap实现的,不保证元素的顺序,而且HashSet允许使用 null 元素。
3)HashSet是非同步的。如果多个线程同时访问一个哈希 set,而其中至少一个线程修改了该 set,那么它必须 保持外部同步。这通常是通过对自然封装该 set 的对象执行同步操作来完成的。如果不存在这样的对象,则应该使用 Collections.synchronizedSet 方法来“包装” set。最好在创建时完成这一操作,以防止对该 set 进行意外的不同步访问:
- Set s = Collections.synchronizedSet(new HashSet(...));
4)HashSet通过iterator()返回的迭代器是fail-fast的。
HashSet的构造函数
- // 默认构造函数
- public HashSet()
- // 带集合的构造函数
- public HashSet(Collection<? extends E> c)
- // 指定HashSet初始容量和加载因子的构造函数
- public HashSet(int initialCapacity, float loadFactor)
- // 指定HashSet初始容量的构造函数
- public HashSet(int initialCapacity)
- // 指定HashSet初始容量和加载因子的构造函数,dummy没有任何作用
- HashSet(int initialCapacity, float loadFactor, boolean dummy)
HashSet的主要API
- boolean add(E object)
- void clear()
- Object clone()
- boolean contains(Object object)
- boolean isEmpty()
- Iterator<E> iterator()
- boolean remove(Object object)
- int size()
2,HashSet数据结构
HashSet的继承关系如下:
- java.lang.Object
- ↳ java.util.AbstractCollection<E>
- ↳ java.util.AbstractSet<E>
- ↳ java.util.HashSet<E>
- public class HashSet<E>
- extends AbstractSet<E>
- implements Set<E>, Cloneable, java.io.Serializable { }
HashSet与Map关系如下图:
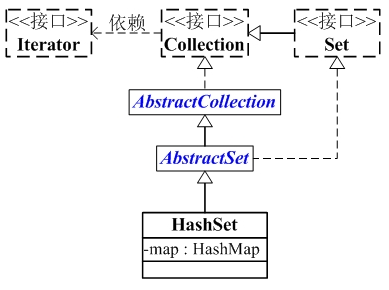
从图中可以看出:
(01) HashSet继承于AbstractSet,并且实现了Set接口。
(02) HashSet的本质是一个"没有重复元素"的集合,它是通过HashMap实现的。HashSet中含有一个"HashMap类型的成员变量"map,HashSet的操作函数,实际上都是通过map实现的。
3,HashSet源码解析
为了更了解HashSet的原理,下面对HashSet源码代码作出分析。
- package java.util;
- public class HashSet<E>
- extends AbstractSet<E>
- implements Set<E>, Cloneable, java.io.Serializable
- {
- static final long serialVersionUID = -5024744406713321676L;
- // HashSet是通过map(HashMap对象)保存内容的
- private transient HashMap<E,Object> map;
- // PRESENT是向map中插入key-value对应的value
- // 因为HashSet中只需要用到key,而HashMap是key-value键值对;
- // 所以,向map中添加键值对时,键值对的值固定是PRESENT
- private static final Object PRESENT = new Object();
- // 默认构造函数
- public HashSet() {
- // 调用HashMap的默认构造函数,创建map
- map = new HashMap<E,Object>();
- }
- // 带集合的构造函数
- public HashSet(Collection<? extends E> c) {
- // 创建map。
- // 为什么要调用Math.max((int) (c.size()/.75f) + 1, 16),从 (c.size()/.75f) + 1 和 16 中选择一个比较大的树呢?
- // 首先,说明(c.size()/.75f) + 1
- // 因为从HashMap的效率(时间成本和空间成本)考虑,HashMap的加载因子是0.75。
- // 当HashMap的“阈值”(阈值=HashMap总的大小*加载因子) < “HashMap实际大小”时,
- // 就需要将HashMap的容量翻倍。
- // 所以,(c.size()/.75f) + 1 计算出来的正好是总的空间大小。
- // 接下来,说明为什么是 16 。
- // HashMap的总的大小,必须是2的指数倍。若创建HashMap时,指定的大小不是2的指数倍;
- // HashMap的构造函数中也会重新计算,找出比“指定大小”大的最小的2的指数倍的数。
- // 所以,这里指定为16是从性能考虑。避免重复计算。
- map = new HashMap<E,Object>(Math.max((int) (c.size()/.75f) + 1, 16));
- // 将集合(c)中的全部元素添加到HashSet中
- addAll(c);
- }
- // 指定HashSet初始容量和加载因子的构造函数
- public HashSet(int initialCapacity, float loadFactor) {
- map = new HashMap<E,Object>(initialCapacity, loadFactor);
- }
- // 指定HashSet初始容量的构造函数
- public HashSet(int initialCapacity) {
- map = new HashMap<E,Object>(initialCapacity);
- }
- HashSet(int initialCapacity, float loadFactor, boolean dummy) {
- map = new LinkedHashMap<E,Object>(initialCapacity, loadFactor);
- }
- // 返回HashSet的迭代器
- public Iterator<E> iterator() {
- // 实际上返回的是HashMap的“key集合的迭代器”
- return map.keySet().iterator();
- }
- public int size() {
- return map.size();
- }
- public boolean isEmpty() {
- return map.isEmpty();
- }
- public boolean contains(Object o) {
- return map.containsKey(o);
- }
- // 将元素(e)添加到HashSet中
- public boolean add(E e) {
- return map.put(e, PRESENT)==null;
- }
- // 删除HashSet中的元素(o)
- public boolean remove(Object o) {
- return map.remove(o)==PRESENT;
- }
- public void clear() {
- map.clear();
- }
- // 克隆一个HashSet,并返回Object对象
- public Object clone() {
- try {
- HashSet<E> newSet = (HashSet<E>) super.clone();
- newSet.map = (HashMap<E, Object>) map.clone();
- return newSet;
- } catch (CloneNotSupportedException e) {
- throw new InternalError();
- }
- }
- // java.io.Serializable的写入函数
- // 将HashSet的“总的容量,加载因子,实际容量,所有的元素”都写入到输出流中
- private void writeObject(java.io.ObjectOutputStream s)
- throws java.io.IOException {
- // Write out any hidden serialization magic
- s.defaultWriteObject();
- // Write out HashMap capacity and load factor
- s.writeInt(map.capacity());
- s.writeFloat(map.loadFactor());
- // Write out size
- s.writeInt(map.size());
- // Write out all elements in the proper order.
- for (Iterator i=map.keySet().iterator(); i.hasNext(); )
- s.writeObject(i.next());
- }
- // java.io.Serializable的读取函数
- // 将HashSet的“总的容量,加载因子,实际容量,所有的元素”依次读出
- private void readObject(java.io.ObjectInputStream s)
- throws java.io.IOException, ClassNotFoundException {
- // Read in any hidden serialization magic
- s.defaultReadObject();
- // Read in HashMap capacity and load factor and create backing HashMap
- int capacity = s.readInt();
- float loadFactor = s.readFloat();
- map = (((HashSet)this) instanceof LinkedHashSet ?
- new LinkedHashMap<E,Object>(capacity, loadFactor) :
- new HashMap<E,Object>(capacity, loadFactor));
- // Read in size
- int size = s.readInt();
- // Read in all elements in the proper order.
- for (int i=0; i<size; i++) {
- E e = (E) s.readObject();
- map.put(e, PRESENT);
- }
- }
- }
说明: HashSet的代码实际上非常简单,通过上面的注释应该很能够看懂。它是通过HashMap实现的,若对HashSet的理解有困难,建议先学习以下HashMap;学完HashMap之后,在学习HashSet就非常容易了。
4,HashSet遍历方式
4.1 通过Iterator遍历HashSet
第一步:根据iterator()获取HashSet的迭代器。
第二步:遍历迭代器获取各个元素。
- // 假设set是HashSet对象
- for(Iterator iterator = set.iterator();
- iterator.hasNext(); ) {
- iterator.next();
- }
4.2 通过for-each遍历HashSet
第一步:根据toArray()获取HashSet的元素集合对应的数组。
第二步:遍历数组,获取各个元素。
- // 假设set是HashSet对象,并且set中元素是String类型
- String[] arr = (String[])set.toArray(new String[0]);
- for (String str:arr)
- System.out.printf("for each : %s\n", str);
HashSet的遍历测试程序如下:
- import java.util.Random;
- import java.util.Iterator;
- import java.util.HashSet;
- /*
- * @desc 介绍HashSet遍历方法
- *
- * @author skywang
- */
- public class HashSetIteratorTest {
- public static void main(String[] args) {
- // 新建HashSet
- HashSet set = new HashSet();
- // 添加元素 到HashSet中
- for (int i=0; i<5; i++)
- set.add(""+i);
- // 通过Iterator遍历HashSet
- iteratorHashSet(set) ;
- // 通过for-each遍历HashSet
- foreachHashSet(set);
- }
- /*
- * 通过Iterator遍历HashSet。推荐方式
- */
- private static void iteratorHashSet(HashSet set) {
- for(Iterator iterator = set.iterator();
- iterator.hasNext(); ) {
- System.out.printf("iterator : %s\n", iterator.next());
- }
- }
- /*
- * 通过for-each遍历HashSet。不推荐!此方法需要先将Set转换为数组
- */
- private static void foreachHashSet(HashSet set) {
- String[] arr = (String[])set.toArray(new String[0]);
- for (String str:arr)
- System.out.printf("for each : %s\n", str);
- }
- }
运行结果:
- iterator : 3
- iterator : 2
- iterator : 1
- iterator : 0
- iterator : 4
- for each : 3
- for each : 2
- for each : 1
- for each : 0
- for each : 4
5,HashSet示例
- import java.util.Iterator;
- import java.util.HashSet;
- /*
- * @desc HashSet常用API的使用。
- *
- * @author skywang
- */
- public class HashSetTest {
- public static void main(String[] args) {
- // HashSet常用API
- testHashSetAPIs() ;
- }
- /*
- * HashSet除了iterator()和add()之外的其它常用API
- */
- private static void testHashSetAPIs() {
- // 新建HashSet
- HashSet set = new HashSet();
- // 将元素添加到Set中
- set.add("a");
- set.add("b");
- set.add("c");
- set.add("d");
- set.add("e");
- // 打印HashSet的实际大小
- System.out.printf("size : %d\n", set.size());
- // 判断HashSet是否包含某个值
- System.out.printf("HashSet contains a :%s\n", set.contains("a"));
- System.out.printf("HashSet contains g :%s\n", set.contains("g"));
- // 删除HashSet中的“e”
- set.remove("e");
- // 将Set转换为数组
- String[] arr = (String[])set.toArray(new String[0]);
- for (String str:arr)
- System.out.printf("for each : %s\n", str);
- // 新建一个包含b、c、f的HashSet
- HashSet otherset = new HashSet();
- otherset.add("b");
- otherset.add("c");
- otherset.add("f");
- // 克隆一个removeset,内容和set一模一样
- HashSet removeset = (HashSet)set.clone();
- // 删除“removeset中,属于otherSet的元素”
- removeset.removeAll(otherset);
- // 打印removeset
- System.out.printf("removeset : %s\n", removeset);
- // 克隆一个retainset,内容和set一模一样
- HashSet retainset = (HashSet)set.clone();
- // 保留“retainset中,属于otherSet的元素”
- retainset.retainAll(otherset);
- // 打印retainset
- System.out.printf("retainset : %s\n", retainset);
- // 遍历HashSet
- for(Iterator iterator = set.iterator();
- iterator.hasNext(); )
- System.out.printf("iterator : %s\n", iterator.next());
- // 清空HashSet
- set.clear();
- // 输出HashSet是否为空
- System.out.printf("%s\n", set.isEmpty()?"set is empty":"set is not empty");
- }
- }
运行结果:
- size : 5
- HashSet contains a :true
- HashSet contains g :false
- for each : d
- for each : b
- for each : c
- for each : a
- removeset : [d, a]
- retainset : [b, c]
- iterator : d
- iterator : b
- iterator : c
- iterator : a
- set is empty
转自:http://www.cnblogs.com/skywang12345/p/3311252.html
java源码之HashSet的更多相关文章
- java源码阅读HashSet
1类签名与注解 public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneabl ...
- 【java集合框架源码剖析系列】java源码剖析之HashSet
注:博主java集合框架源码剖析系列的源码全部基于JDK1.8.0版本.本博客将从源码角度带领大家学习关于HashSet的知识. 一HashSet的定义: public class HashSet&l ...
- 【java集合框架源码剖析系列】java源码剖析之TreeSet
本博客将从源码的角度带领大家学习TreeSet相关的知识. 一TreeSet类的定义: public class TreeSet<E> extends AbstractSet<E&g ...
- jdk1.8.0_45源码解读——HashSet的实现
jdk1.8.0_45源码解读——HashSet的实现 一.HashSet概述 HashSet实现Set接口,由哈希表(实际上是一个HashMap实例)支持.主要具有以下的特点: 不保证set的迭代顺 ...
- 如何阅读Java源码 阅读java的真实体会
刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动. 源码阅读,我觉得最核心有三点:技术基础+强烈的求知欲+耐心. 说到技术基础,我打个比 ...
- Android反编译(一)之反编译JAVA源码
Android反编译(一) 之反编译JAVA源码 [目录] 1.工具 2.反编译步骤 3.实例 4.装X技巧 1.工具 1).dex反编译JAR工具 dex2jar http://code.go ...
- 如何阅读Java源码
刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动.源码阅读,我觉得最核心有三点:技术基础+强烈的求知欲+耐心. 说到技术基础,我打个比方吧, ...
- Java 源码学习线路————_先JDK工具包集合_再core包,也就是String、StringBuffer等_Java IO类库
http://www.iteye.com/topic/1113732 原则网址 Java源码初接触 如果你进行过一年左右的开发,喜欢用eclipse的debug功能.好了,你现在就有阅读源码的技术基础 ...
- Programming a Spider in Java 源码帖
Programming a Spider in Java 源码帖 Listing 1: Finding the bad links (CheckLinks.java) import java.awt. ...
随机推荐
- ASP.NET学习笔记01
ASP.NET初级工程师的核心要求:能够实现一个基本的网站. ASP.NET初级工程师面试主要要求: 1.基础的数据结构和算法 2.C#编程语言基础 3.网站基础(HTML,CSS,Javascrip ...
- [SharePoint][SharePoint Designer 入门经典]Chapter13 客户端JavaScript编程
1.创建客户对象模型的页面 2.使用CAML从SPS中取得数据 3.创建更新删除列表项目 4.为ribbon添加项目
- C++ 嵌入汇编程序提高计算效率
因为汇编语言比C++更接近硬件底层,所以在性能要求高的程序中往往能够採取在C++代码中嵌入汇编的方式来给程序提速. 在VC中能够简单的通过 __asm { //在这里加入汇编代码 } 来实现. 以下通 ...
- 交叉编译faac共享库
作者:咕唧咕唧liukun321 来自:http://blog.csdn.net/liukun321 Advanced Audio Coding.一种专为声音数据设计的文件压缩格式,与Mp3不同,它採 ...
- 关于static的使用
在我们写类写方法的时候,通常会看到有的时候是静态的方法,有的则是动态的,那么问题来了,什么时候该加static什么时候不加static?这里的区别有多大那?那么加不加static取决与这个方法的特征与 ...
- 在 Eclipse 中使用 C++
安装 安装Eclipse Eclipse下载页 能够选择Eclipse IDE for C/C++ Developers(内置CDT插件) 也能够选择安装其它版本号之后再安装CDT插件. 安装CDT插 ...
- 从乐视和小米“最火电视”之战 看PR传播策略
今年的双11够热闹.一方面,阿里.京东.国美.苏宁等电商巨头卯足了劲儿.试图在双11期间斗个你死我活,剑拔弩张的气势超过了以往不论什么一场双11:还有一方面.不少硬件厂商.家电企业也来凑双11 ...
- swift-判断是否已获得相机、相册权限
// 相机权限 func isRightCamera() -> Bool { let authStatus = AVCaptureDevice.authorizationStatus(forMe ...
- DatabaseMetaData开发实务
1.总论 在企业开发实务中,数据迁移是经常会遇到的事情,此时,需要搞清楚,源数据库与目的数据库之间表以及表内部各列之间的异同.而有些时候,我们拿到的项目文 档,未必能准确表述各个表的准确结构,即使应用 ...
- C#中网络通信
一.服务端代码 using System; using System.Collections.Generic; using System.Linq; using System.Net; using S ...