lucene 统计单词次数(词频tf)并进行排序
public class WordCount {
static Directory directory;
// 创建分词器
static Analyzer analyzer = new IKAnalyzer();
static IndexWriterConfig config = new IndexWriterConfig(analyzer);
static IndexWriter writer;
static IndexReader reader;
static {
// 指定索引存放目录以及配置参数
try {
directory = FSDirectory.open(Paths.get("F:/luceneIndex"));
writer = new IndexWriter(directory, config);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
indexCreate();
Map<String, Long> map = getTotalFreqMap();
Map<String, Long> sortMap = sortMapByValue(map);
Set<Entry<String, Long>> entrySet = sortMap.entrySet();
Iterator<Entry<String, Long>> iterator = entrySet.iterator();
while (iterator.hasNext()) {
Entry<String, Long> entry = iterator.next();
System.out.println(entry.getKey() + "----" + entry.getValue());
}
}
/**
* 创建索引
*/
public static void indexCreate() {
// 文件夹检测(创建索引前要保证目录是空的)
File file = new File("f:/luceneIndex");
if (!file.exists()) {
file.mkdirs();
} else {
try {
file.delete();
} catch (Exception e) {
e.printStackTrace();
}
}
// 将采集的数据封装到Document中
Document doc = new Document();
FieldType ft = new FieldType();
ft.setIndexOptions(IndexOptions.DOCS_AND_FREQS);
ft.setStored(true);
ft.setStoreTermVectors(true);
ft.setTokenized(true);
// ft.setStoreTermVectorOffsets(true);
// ft.setStoreTermVectorPositions(true);
// 读取文件内容(小文件,readFully)
File content = new File("f:/qz/twitter.txt");
try {
byte[] buffer = new byte[(int) content.length()];
IOUtils.readFully(new FileInputStream(content), buffer);
doc.add(new Field("twitter", new String(buffer), ft));
} catch (Exception e) {
e.printStackTrace();
}
// 生成索引
try {
writer.addDocument(doc);
// 关闭
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 获得词频map
*
* @throws ParseException
*/
public static Map<String, Long> getTotalFreqMap() {
Map<String, Long> map = new HashMap<String, Long>();
try {
reader = DirectoryReader.open(directory);
List<LeafReaderContext> leaves = reader.leaves();
for (LeafReaderContext leafReaderContext : leaves) {
LeafReader leafReader = leafReaderContext.reader();
Terms terms = leafReader.terms("twitter");
TermsEnum iterator = terms.iterator();
BytesRef term = null;
while ((term = iterator.next()) != null) {
String text = term.utf8ToString();
map.put(text, iterator.totalTermFreq());
}
}
reader.close();
return map;
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
/**
* 使用 Map按value进行排序
*
* @param map
* @return
*/
public static Map<String, Long> sortMapByValue(Map<String, Long> oriMap) {
if (oriMap == null || oriMap.isEmpty()) {
return null;
}
Map<String, Long> sortedMap = new LinkedHashMap<String, Long>();
List<Map.Entry<String, Long>> entryList = new ArrayList<Map.Entry<String, Long>>(oriMap.entrySet());
Collections.sort(entryList, new MapValueComparator());
Iterator<Map.Entry<String, Long>> iter = entryList.iterator();
Map.Entry<String, Long> tmpEntry = null;
while (iter.hasNext()) {
tmpEntry = iter.next();
sortedMap.put(tmpEntry.getKey(), tmpEntry.getValue());
}
return sortedMap;
}
}
class MapValueComparator implements Comparator<Map.Entry<String, Long>> {
@Override
public int compare(Entry<String, Long> me1, Entry<String, Long> me2) {
if (me1.getValue() == me2.getValue()) {
return ;
}
return me1.getValue() > me2.getValue() ? - : ;
// return me1.getValue().compareTo(me2.getValue());
}
}
map排序代码https://www.cnblogs.com/zhujiabin/p/6164826.html
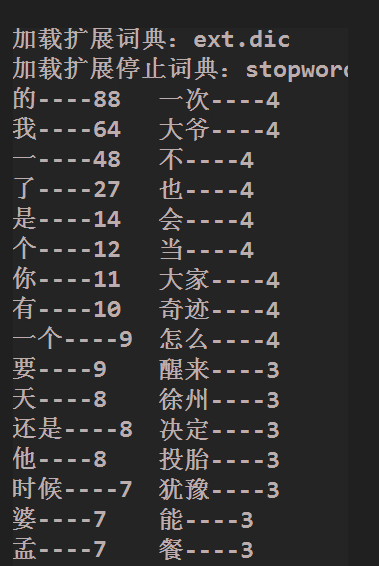
lucene 统计单词次数(词频tf)并进行排序的更多相关文章
- Storm-wordcount实时统计单词次数
一.本地模式 1.WordCountSpout类 package com.demo.wc; import java.util.Map; import org.apache.storm.spout.Sp ...
- C++读取文件统计单词个数及频率
1.Github链接 GitHub链接地址https://github.com/Zzwenm/PersonProject-C2 2.PSP表格 PSP2.1 Personal Software Pro ...
- python 统计单词个数
根据一篇英文文章统计其中单词出现最多的10个单词. # -*- coding: utf-8 -*-import urllib2import refrom collections import Coun ...
- 洛谷 P1308 统计单词数【字符串+模拟】
P1308 统计单词数 题目描述 一般的文本编辑器都有查找单词的功能,该功能可以快速定位特定单词在文章中的位置,有的还能统计出特定单词在文章中出现的次数. 现在,请你编程实现这一功能,具体要求是:给定 ...
- 统计单词Java
功能0:输出某个英文文本文件中 26 字母出现的频率,由高到低排列,并显示字母出现的百分比,精确到小数点后面两位. 功能1:输出文件中所有不重复的单词,按照出现次数由多到少排列,出现次数同样多的,以字 ...
- [luogu]P1026 统计单词个数[DP][字符串]
[luogu]P1026 统计单词个数 题目描述 给出一个长度不超过200的由小写英文字母组成的字母串(约定;该字串以每行20个字母的方式输入,且保证每行一定为20个).要求将此字母串分成k份(1&l ...
- 第六章 第一个Linux驱动程序:统计单词个数
现在进入了实战阶段,使用统计单词个数的实例让我们了解开发和测试Linux驱动程序的完整过程.第一个Linux驱动程序是统计单词个数. 这个Linux驱动程序没有访问硬件,而是利用设备文件作为介质与应用 ...
- 第六章第一个linux个程序:统计单词个数
第六章第一个linux个程序:统计单词个数 从本章就开始激动人心的时刻——实战,去慢慢揭开linux神秘的面纱.本章的实例是统计一片文章或者一段文字中的单词个数. 第 1 步:建立 Linu x 驱 ...
- Java web--Filter过滤器分IP统计访问次数
分IP统计访问次数即网站统计每个IP地址访问本网站的次数. 分析 因为一个网站可能有多个页面,无论哪个页面被访问,都要统计访问次数,所以使用过滤器最为方便. 因为需要分IP统计,所以可以在过滤器中创建 ...
随机推荐
- 洛谷—— P1118 [USACO06FEB]数字三角形Backward Digit Su…
https://www.luogu.org/problem/show?pid=1118#sub 题目描述 FJ and his cows enjoy playing a mental game. Th ...
- Dcloud开发webApp踩过的坑
Dcloud开发webApp踩过的坑 一.总结 一句话总结:HTML5+扩展了JavaScript对象plus,使得js可以调用各种浏览器无法实现或实现不佳的系统能力,设备能力如摄像头.陀螺仪.文件系 ...
- Altium Designer规则的制定,一般规则
资源来源于网上: 1,线间距6~10个mil 2,铺铜间距 20mil 实心 3,焊盘对焊盘间距10mil 4,测量电压的位置要到引脚附近. 敷铜:
- struts2笔记---struts2的执行过程
1.服务器启动: 加载项目web.xml 创建struts核心过滤器对象,执行filter-->init() struts-default.xml 核心功能的初始化 struts-plu ...
- vue项目实现导出数据到excel
实现导出功能分两种,一种是客户端拿到数据做导出,第二种是服务器端处理好,返回一个数据流实现导出 第一种网上很容易找到,也很好用,本文要说的是第二种. fetchExport({ id: this.so ...
- 【z04】计算系数
[题目链接]:http://noi.qz5z.com/viewtask.asp?id=z04 [题解] 用二项式定理可以写出下列通式 组合数可以用杨辉三角搞出来; a的x次方直接乘就好了;指数也不大. ...
- 9、基于Linux的v4l2视频架构应用编写
Linux系统中,视频设备被当作一个设备文件来看待,设备文件存放在 /dev目录下,完整路径的设备文件名为: /dev/video0 . 视频采集基本步骤流程如下: 打开视频设备,设置视频设备属性及采 ...
- HDU1248 寒冰王座 【数学题】or【全然背包】
寒冰王座 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Submi ...
- [Docker] Run Short-Lived Docker Containers
Learn the benefits of running one-off, short-lived Docker containers. Short-Lived containers are use ...
- 简单的Java多线程的使用
前几天做一个功能.就是在前台更改信息后会自己主动发邮件给其它的人,相关信息已更改,刚開始是直接在更改信息代码后面增加发送邮件的代码,但发现这样会使界面特别慢,而慢的主要原因是因为发送邮件有时会耗时非常 ...