ChannelPipeline----贯穿io事件处理的大动脉
ChannelPipeline贯穿io事件处理的大动脉
上一篇,我们分析了NioEventLoop及其相关类的主干逻辑代码,我们知道netty采用线程封闭的方式来避免多线程之间的资源竞争,最大限度地减少并发问题,减少锁的使用,因而能够有效减低线程切换的开销,减少cpu的使用时间。此外,我们还简单分析了netty对于线程组的封装EventLoopGroup,目前一般采用roundRobin的方式在多个线程上均匀地分配channel。通过前面几篇文章的分析,我们已经对channel的初始化,注册到EventLoop上,SingleThreadEventLoop的线程启动过程以及线程中运行的代码逻辑有了一些了解,此外我们也分析了用于处理基于TCP协议的io事件的NioEventLoop类的具体的循环逻辑,通过对代码的详细分析,我们了解了对于connect,write,read,accept事件的不同处理逻辑,但是对于write和read事件的处理逻辑我们并没有分析的很详细,因为这些事件的处理涉及到netty中另一个很重要的模块,ChannelPipeline以及一系列相关的类如Channel, ChannelHandler, ChannelhandlerContext等的理解,netty中的事件处理采用了经典的责任链(responsbility chain)的的设计模式,这种设计模式使得netty的io事件处理框架易于扩展,并且为业务逻辑提供了一个很好的抽象模型,大大降低了netty的使用难度,使得io事件的处理变得更符合思维习惯。
好了,废话了那么多,其实主要是想把前面分析的几篇的文章做一个小结和回顾,然后引出本篇的主题--netty的io事件处理链模式。
因为netty的代码结构相对来说还是很规整,它的模块之间的边界划分比较明确,EventLoop作为io事件的“发源地”,与其交互的对象是Channel类,而ChannelPipeline,ChannelhandlerContext, ChannelHandler等几个类则是与Channel交互,他们并不直接与EventLoop交互。
ChannelPipeline的结构图
首先每一个Channel在初始化的时候就会创建一个ChannelPipeline,这点我们在前面分析NioSocketChannel的初始化时也分析到了。目前ChannelPipeline的实现只有DefaultChannelPipeline一种,所以我们也以DefaultChannelPipeline来分析。DefaultChannelPipeline内部有一个双向链表结构,这个链表的每个节点都是一个AbstractChannelHandlerContext类型的节点,DefaultChannelPipeline刚初始化时就会创建两个初始节点,分别是HeadContext和TailContext,这两个节点也并不完全是标记节点,他们都有各自实际的作用,
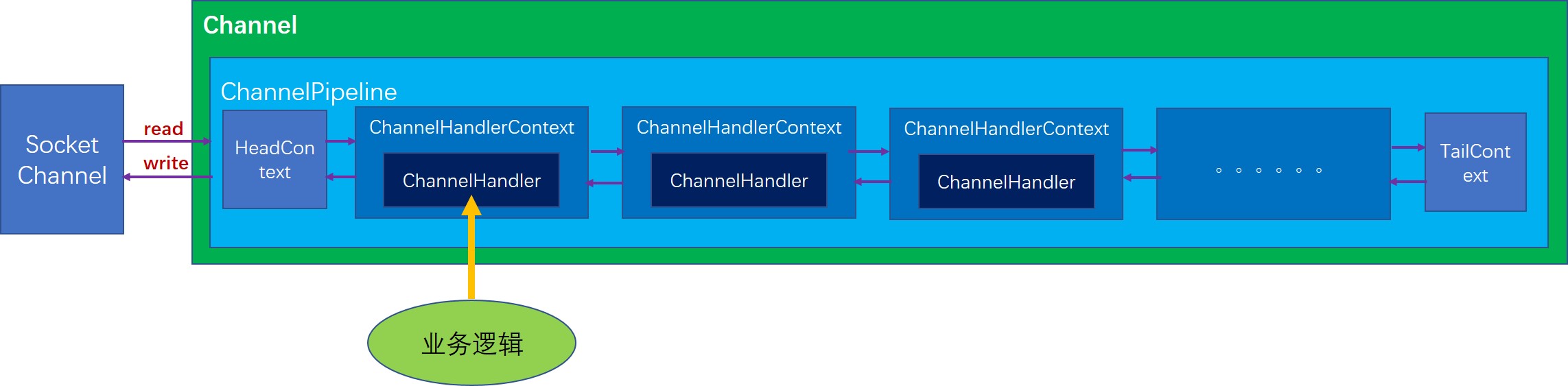
- HeadContext,实现了bind,connect,disconnect,close,write,flush等等几个方法,基本都是通过直接调用unsafe的相关方法实现的。而对于其他的方法基本都是通过调用AbstractChannelHandlerContext的fire方法将事件传给下一个节点。
- TailContext, 主要用于处理写数据几乎没有实现任何逻辑,它的功能几乎全部继承自AbstractChannelHandlerContext,而AbstractChannelHandlerContext对于大部分事件处理的实现都是简单地将事件向下一个节点传递。注意,这里下一个节点不一定是前一个还是后一个,要根据具体事件类型或者具体的操作而定,对于ChannelOutboundInvoker接口中的方法都是从尾节点向首节点传递事件,而对于ChannelInboundInvoker接口中的方法都是从首节点往尾节点传递。我们可以形象地理解为,首节点是最靠近socket的,而尾节点是最原理socket的,所以有数据进来时,产生的读事件最先从首节点开始向后传递,当有写数据的动作时,则会从尾节点向头结点传递。
下面,我们以两个最重要的事件读事件和写事件,来分析netty的这种链式处理结构到底是怎么运转的。
读事件
首先,我们需要找到一个产生读事件并调用相关方法使得读事件开始传递的例子,很自然我们应该想到在EventLoop中会产生读事件。
如下,就是NioEventLoop中对于读事件的处理,通过调用NioUnsafe.read方法
// 处理read和accept事件
if ((readyOps & (SelectionKey.OP_READ | SelectionKey.OP_ACCEPT)) != 0 || readyOps == 0) {
unsafe.read();
}
我们继续看NioByteUnsafe.read方法,这个方法我们之前在分析NioEventLoop事件处理逻辑时提到过,这个方法首先会通过缓冲分配器分配一个缓冲,然后从channel(也就是socket)中将数据读到缓冲中,每读一个缓冲,就会触发一个读事件,我们看具体的触发读事件的调用:
do {
// 分配一个缓冲
byteBuf = allocHandle.allocate(allocator);
// 将通道的数据读取到缓冲中
allocHandle.lastBytesRead(doReadBytes(byteBuf));
// 如果没有读取到数据,说明通道中没有待读取的数据了,
if (allocHandle.lastBytesRead() <= 0) {
// nothing was read. release the buffer.
// 因为没读取到数据,所以应该释放缓冲
byteBuf.release();
byteBuf = null;
// 如果读取到的数据量是负数,说明通道已经关闭了
close = allocHandle.lastBytesRead() < 0;
if (close) {
// There is nothing left to read as we received an EOF.
readPending = false;
}
break;
}
// 更新Handle内部的簿记量
allocHandle.incMessagesRead(1);
readPending = false;
// 向channel的处理器流水线中触发一个事件,
// 让取到的数据能够被流水线上的各个ChannelHandler处理
pipeline.fireChannelRead(byteBuf);
byteBuf = null;
// 这里根据如下条件判断是否继续读:
// 上一次读取到的数据量大于0,并且读取到的数据量等于分配的缓冲的最大容量,
// 此时说明通道中还有待读取的数据
} while (allocHandle.continueReading());
为了代码逻辑的完整性,我这里把整个循环的代码都贴上来,其实我们要关注的仅仅是pipeline.fireChannelRead(byteBuf)这一句,好了,现在我们找到ChannelPipeline触发读事件的入口方法,我们顺着这个方法,顺藤摸瓜就能一步步理清事件的传递过程了。
DefaultChannelPipeline.fireChannelRead
如果我们看一下ChannelPipeline接口,这里面的方法名都是以fire开头的,实际就是想表达这些方法都是触发了一个事件,然后这个事件就会在内部的处理器链表中传递。
我们看到这里调用了一个静态方法,并且以头结点为参数,也就是说事件传递是从头结点开始的。
public final ChannelPipeline fireChannelRead(Object msg) {
AbstractChannelHandlerContext.invokeChannelRead(head, msg);
return this;
}
AbstractChannelHandlerContext.invokeChannelRead(final AbstractChannelHandlerContext next, Object msg)
可以看到,这个方法中通过调用invokeChannelRead执行处理逻辑
static void invokeChannelRead(final AbstractChannelHandlerContext next, Object msg) {
// 维护引用计数,主要是为了侦测资源泄漏问题
final Object m = next.pipeline.touch(ObjectUtil.checkNotNull(msg, "msg"), next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
// 调用invokeChannelRead执行处理逻辑
next.invokeChannelRead(m);
} else {
executor.execute(new Runnable() {
@Override
public void run() {
next.invokeChannelRead(m);
}
});
}
}
AbstractChannelHandlerContext.invokeChannelRead(Object msg)
这里可以看到,AbstractChannelHandlerContext通过自己内部的handler对象来实现读数据的逻辑。这也体现了ChannelHandlerContext在整个结构中的作用,其实它是起到了在ChannelPipeline和handler之间的一个中间人的角色,那我们要问:既然ChannelHandlerContext不起什么实质性的作用,那为什么要多这一个中间层呢,这样设计的好处是什么?我认为这样设计其实是为了尽最大可能对使用者屏蔽netty框架的细节,试想如果没有这个context的中间角色,使用者必然要详细地了解ChannelPipeline,并且还要考虑事件传递是找下一个节点,还要考虑下一个节点应该沿着链表的正序找还是沿着链表 倒叙找,所以这里ChannelHandlerContext的角色我认为最大的作用就是封装了链表的逻辑,并且封装了不同类型操作的传播方式。当然也起到了一些引用传递的作用,如channel引用可以简介地传递给用户。
好了,回到正题,从前面的方法中我们知道读事件最先是从HeadContext节点开始的,所以我们看一下HeadContext的channelRead方法(因为HeadContext也实现了handler方法,并且返回的就是自身)
private void invokeChannelRead(Object msg) {
// 如果这个handler已经准备就绪,那么就执行处理逻辑
// 否则将事件传递给下一个处理器节点
if (invokeHandler()) {
try {
// 调用内部的handler的channelRead方法
((ChannelInboundHandler) handler()).channelRead(this, msg);
} catch (Throwable t) {
notifyHandlerException(t);
}
} else {
fireChannelRead(msg);
}
}
HeadContext.channelRead
这里的调用也是一个重要的注意点,这里调用了ChannelHandlerContext.fireChannelRead方法,这正是事件传播的方法,fire开头的方法的作用就是将当前的操作(或者叫事件)从当前处理节点传递给下一个处理节点。这样就实现了事件在链表中的传播。
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ctx.fireChannelRead(msg);
}
小结
到这里我们先暂停一下,总结一下读事件(或者是读操作)在ChannelPipeline内部的传播机制,其实很简单,
- 首先外部调用者会通过unsafe最终调用ChannelPipeline.fireChannelRead方法,并将从channel中读取到的数据作为参数传进来
- 以头结点作为参数调用静态方法AbstractChannelHandlerContext.fireChannelRead
- 然后头结点HeadContext开始调用节点的invokeChannelRead方法(即ChannelHandlerContext的invokeChannelRead方法),
- invokeChannelRead方法会调用当前节点的handler对象的channelRead方法执行处理逻辑
- handler对象的channelRead方法中可以调用AbstractChannelHandlerContext.fireChannelRead将这个事件传递到下一个节点
- 这样事件就能够沿着链条不断传递下去,当然如果业务处理需要,完全可以在某个节点将事件的传递终止,也就是在这个节点不调用ChannelHandlerContext.fireChannelRead
写事件
此外,我们分析一下写数据的操作是怎么传播的。分析写数据操作的入口并不想读事件那么好找,在netty中用户的代码中写数据最终都是被放到内部的缓冲中,当NioEventLoop中监听到底层的socket可以写数据的事件时,实际上是吧当前缓冲中的数据发送到socket中,而对于用户来讲,是接触不到socketChannel这一层的。
根据前面的分析,我们知道,用户一般都会与Channel,ChannelHandler, ChannelhandlerContext这几种类打交道,写数据的操作也是通过Channel的write和writeAndFlush触发的,这两个方法区别在于writeAndFlush在写完数据后还会触发一次刷写操作,将缓冲中的数据实际写入到socket中。
AbstractChannel.write
仍然是将操作交给内部的ChannelPipeline,触发流水线操作
public ChannelFuture write(Object msg, ChannelPromise promise) {
return pipeline.write(msg, promise);
}
DefaultChannelPipeline.write
这里可以很清楚地看出来,写数据的操作从为节点开始,但是TailContext并未重写write方法,所以最终调用的还是AbstractChannelHandlerContext中的相应方法。
我们沿着调用链往下走,发现write系列的方法其实是将写操作传递给了下一个ChannelOutboundHandler类型的处理节点,注意这里是从尾节点向前找,遍历链表的顺序和读数据正好相反。
真正调用
public final ChannelFuture write(Object msg, ChannelPromise promise) {
return tail.write(msg, promise);
}
AbstractChannelHandlerContext.write
从这个方法可以明显地看出来,write方法将写操作交给了下一个ChannelOutboundHandler类型的处理器节点。
private void write(Object msg, boolean flush, ChannelPromise promise) {
ObjectUtil.checkNotNull(msg, "msg");
try {
if (isNotValidPromise(promise, true)) {
ReferenceCountUtil.release(msg);
// cancelled
return;
}
} catch (RuntimeException e) {
ReferenceCountUtil.release(msg);
throw e;
}
// 沿着链表向前遍历,找到下一个ChannelOutboundHandler类型的处理器节点
final AbstractChannelHandlerContext next = findContextOutbound(flush ?
(MASK_WRITE | MASK_FLUSH) : MASK_WRITE);
final Object m = pipeline.touch(msg, next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
if (flush) {
// 调用AbstractChannelHandlerContext.invokeWriteAndFlush方法执行真正的写入逻辑
next.invokeWriteAndFlush(m, promise);
} else {
next.invokeWrite(m, promise);
}
} else {
// 如果当前是异步地写入数据,那么需要将写入的逻辑封装成一个任务添加到EventLoop的任务对队列中
final AbstractWriteTask task;
if (flush) {
task = WriteAndFlushTask.newInstance(next, m, promise);
} else {
task = WriteTask.newInstance(next, m, promise);
}
if (!safeExecute(executor, task, promise, m)) {
// We failed to submit the AbstractWriteTask. We need to cancel it so we decrement the pending bytes
// and put it back in the Recycler for re-use later.
//
// See https://github.com/netty/netty/issues/8343.
task.cancel();
}
}
}
AbstractChannelHandlerContext.invokeWrite
我们接着看invokeWrite0方法
private void invokeWrite(Object msg, ChannelPromise promise) {
if (invokeHandler()) {
invokeWrite0(msg, promise);
} else {
write(msg, promise);
}
}
AbstractChannelHandlerContext.invokeWrite0
这里可以清楚地看到,最终是调用了handler的write方法执行真正的写入逻辑,这个逻辑实际上就是有用户自己实现的。
private void invokeWrite0(Object msg, ChannelPromise promise) {
try {
// 调用当前节点的handler的write方法执行真正的写入逻辑
((ChannelOutboundHandler) handler()).write(this, msg, promise);
} catch (Throwable t) {
notifyOutboundHandlerException(t, promise);
}
}
到这里,我们已经知道写入的操作是怎么从尾节点开始,也知道了通过调用当前处理节点的AbstractChannelHandlerContext.write方法可以将写入操作传递给下一个节点,那么数据经过层层传递后,最终是怎么写到socket中的呢?回答这个问题,我们需要看一下HeadContext的代码!我们知道写入的操作是从尾节点向前传递的,那么头节点HeadContext就是传递的最后一个节点。
HeadContext.write
最终调用了unsafe.write方法。
在AbstractChannel.AbstractUnsafe的实现中,write方法将经过前面一系列处理器处理过的数据存放到内部的缓冲中。
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) {
unsafe.write(msg, promise);
}
刷写操作的传递
前面我们提到,写数据的操作除了write还有writeAndFlush,这个操作除了写数据,还会紧接着执行一次刷写操作。刷写操作也会从尾节点向前传递,最终传递到头结点HeadContext,其中的flush方法如下:
public void flush(ChannelHandlerContext ctx) {
unsafe.flush();
}
在AbstractChannel.AbstractUnsafe的实现中,flush操作会将前面存储在内部缓冲区中的数据吸入到socket中,从而完成刷写。
总结
本节,我们主要通过io事件处理中最重要的两种事件,即读事件和写事件为切入点 详细分析了netty中对于这两种事件的处理方法。其中写数据的事件与我们之前在jdk nio中建立起的印象差别还是不大的,都是对从socket中读取的数据进行处理,但是写事件跟jdk nio中的概念就有较大差别了,因为netty对数据的写入做了很大的改变和优化,用户代码中通过channel调用相关的写数据的方法,这个方法会触发处理器链条上的所有相关的处理器对待写入的数据进行加工,最后在头结点HeadCOntext中被写入channel内部的缓冲区,通过flush操作将缓冲的数据写入socket中。
这里面最重要的也是最值得我们学习的一点就是责任链模式,显然,这又是一次对责任链模式的成功运用,是的框架的扩展性大大增强,而且面向用户的接口更加容易理解,简单易用,向用户屏蔽了大部分框架实现细节。
ChannelPipeline----贯穿io事件处理的大动脉的更多相关文章
- QEMU IO事件处理框架
Qemu IO事件处理框架 qemu是基于事件驱动的,在基于KVM的qemu模型中,每一个VCPU对应一个qemu线程,且qemu主线程负责各种事件的监听,这里有一个小的IO监听框架,本节对此进行介绍 ...
- 责任链模式的使用-Netty ChannelPipeline和Mina IoFilterChain分析
本文来自网易云社区 作者:乔安然 1. Chain of Responsiblity 定义: 使多个对象都有机会处理请求,从而避免请求的发送者和接受者之间的耦合关系.将这个对象连成一条链,并沿着这条链 ...
- 【Java】浅谈Java IO
注意 本文的代码,为了学习方便,简化代码复杂度,未考虑拆包.粘包等情况的处理.所以仅供学习使用,不能用于实际环境. 阻塞IO,BIO Java1.1发布的IO是BIO.阻塞地连接之后,通过流进行同步阻 ...
- 异步IO原理及相应函数
何为异步IO? (1)几乎可以认为:异步IO就是操作系统用软件实现的一套中断响应系统.(2)异步IO的工作方法是:我们当前进程注册一个异步IO事件(使用signal注册一个信号 SIGIO的处理函数) ...
- Java IO学习笔记八:Netty入门
作者:Grey 原文地址:Java IO学习笔记八:Netty入门 多路复用多线程方式还是有点麻烦,Netty帮我们做了封装,大大简化了编码的复杂度,接下来熟悉一下netty的基本使用. Netty+ ...
- 聊聊Netty那些事儿之从内核角度看IO模型
从今天开始我们来聊聊Netty的那些事儿,我们都知道Netty是一个高性能异步事件驱动的网络框架. 它的设计异常优雅简洁,扩展性高,稳定性强.拥有非常详细完整的用户文档. 同时内置了很多非常有用的模块 ...
- 史诗级最强教科书式“NIO与Netty编程”
史诗级最强教科书式“NIO与Netty编程” 1.1 概述 1.2 文件IO 1.2.1 概述和核心API 1.2.2 案例 1.3 网络IO 1.3.1 概述和核心API 3.4 AIO编程 3.5 ...
- Netty学习笔记(二)——netty组件及其用法
1.Netty是 一个异步事件驱动的网络应用程序框架,用于快速开发可维护的高性能协议服务器和客户端. 原生NIO存在的问题 1) NIO的类库和API繁杂,使用麻烦:需要熟练掌握Selector.Se ...
- 序列化在Netty中的使用
Java序列化的缺点 1.无法跨语言 对于Java序列化后的字节数组,别的语言无法进行反序列化 2.序列化后的码流过大 3.序列化性能低 使用JDK自带的序列化进行对象的传输 被传输的,实现了序列化接 ...
随机推荐
- C++中的模板编程
一,函数模板 1.函数模板的概念 C++中提供了函数模板,所谓函数模板,实际上是建立一个通用函数,其函数的返回值类型和函数的参数类型不具体指定,用一个虚拟的类型来表示.这个通用函数就被称为函数的模板. ...
- 零元学Expression Design 4 - Chapter 1 入门界面简介
原文:零元学Expression Design 4 - Chapter 1 入门界面简介 Expression Design 是Expression系列里面的一员,更是Blend跟Web的好帮手 而在 ...
- Codeforces Round #160 (Div. 2)---A. Roma and Lucky Numbers
Roma and Lucky Numbers time limit per test 1 second memory limit per test 256 megabytes input standa ...
- crossplatform----文本编辑器工具Atom安装
1.简介 Atom 是 Github 专门为程序员推出的一个跨平台文本编辑器.具有简洁和直观的图形用户界面,并有很多有趣的特点:支持CSS,HTML,JavaScript等网页编程语言.它支持宏,自动 ...
- 如何构造请求处理对象链(Pipeline)
在开发中,我们经常会遇到这样一个场景:传入一个对象,经过不同的节点对这个对象做不同的操作,比如ASP.NET Core 中的pipeline,IIS中的HTTPpipeline等.在这类问题中,往往我 ...
- React HOC
在React官网文档学习React HOC,整个看了一遍还是云里雾里的,于是按照官网文档,自己动手实践一下.官网地址:React 高阶组件 定义:高阶组件就是一个函数,且该函数接受一个组件作为参数,并 ...
- pip 9.0 离线安装Python3的环境库
到客户现场实施,很多情况下是没有网络的,我们需要在办公室准备好离线安装包. 假设现有已联网的客户机A,一台无网络的客户机B 客户机A 1.生成本地环境的包清单 pip3 freeze > req ...
- WPF 使用Propereties:Resources.resx里面的资源
<Window x:Class="Wpf180706.Window7" xmlns="http://schemas.microsoft.com/win ...
- swift4.0 Http 请求
// // HttpHelper.swift // NavigateDemo // // Created by yixin ran on 07/08/2017. // Copyright © 2017 ...
- DateTime格式转换结果
Console.WriteLine(string.Format("ToLongDateString:{0}", DateTime.Now.ToLongDateString())); ...